1、简介
在信息爆炸的时代,有效地检索和处理数据变得至关重要。Langchain 和 Elasticsearch 的结合,为我们提供了一个强大的工具,以更智能的方式进行数据检索和分析。
作为一名拥有多年 Elasticsearch 实战经验的技术博主,我将在本文中详细介绍这两种技术的整合应用。
2、LangChain 简介
Langchain是一个旨在简化自然语言处理任务的库。它允许开发者轻松地集成和使用各种 AI 模型,如 GPT-3,来处理复杂的语言任务。
3、Elasticsearch 简介
Elasticsearch 是一个高度可扩展的开源全文搜索和分析引擎。它允许用户快速、实时地进行和分析大量数据。
4、LangChain 与 Elasticsearch 的整合
结合 Langchain和 Elasticsearch,我们可以利用 AI 模型的强大语言处理能力,与 Elasticsearch 的高效数据检索功能,实现智能化的搜索解决方案。

4.1 案例1:Langchain 连接 Elasticsearch
以下是一个实际的代码示例,展示了如何使用 Langchain与 Elasticsearch 进行数据检索:
python
Copy code
import ssl
import openai
from elasticsearch import Elasticsearch
from langchain_community.vectorstores import ElasticsearchStore
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.document_loaders import TextLoader
# 设置代理访问 API
os.environ["HTTP_PROXY"] = "http://127.0.0.1:33210"
os.environ["HTTPS_PROXY"] = "http://127.0.0.1:33210"
os.environ["ALL_PROXY"] = "socks5://127.0.0.1:33211"
# 加载文档
file_path = 'conf/state_of_the_union.txt'
encoding = 'utf-8'
loader = TextLoader(file_path, encoding=encoding)
documents = loader.load()
# 文档分割
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
# 连接 Elasticsearch
conn = Elasticsearch(
"https://127.0.0.1:9200",
ca_certs = "certs/http_ca.crt",
basic_auth = ("elastic", "changeme"),
verify_certs=False
)
# 创建索引并进行检索
embeddings = OpenAIEmbeddings()
db = ElasticsearchStore.from_documents(docs, embeddings, index_name="test_index", es_connection=conn)
db.client.indices.refresh(index="test_index")
query = "What did the president say about Ketanji Brown Jackson"
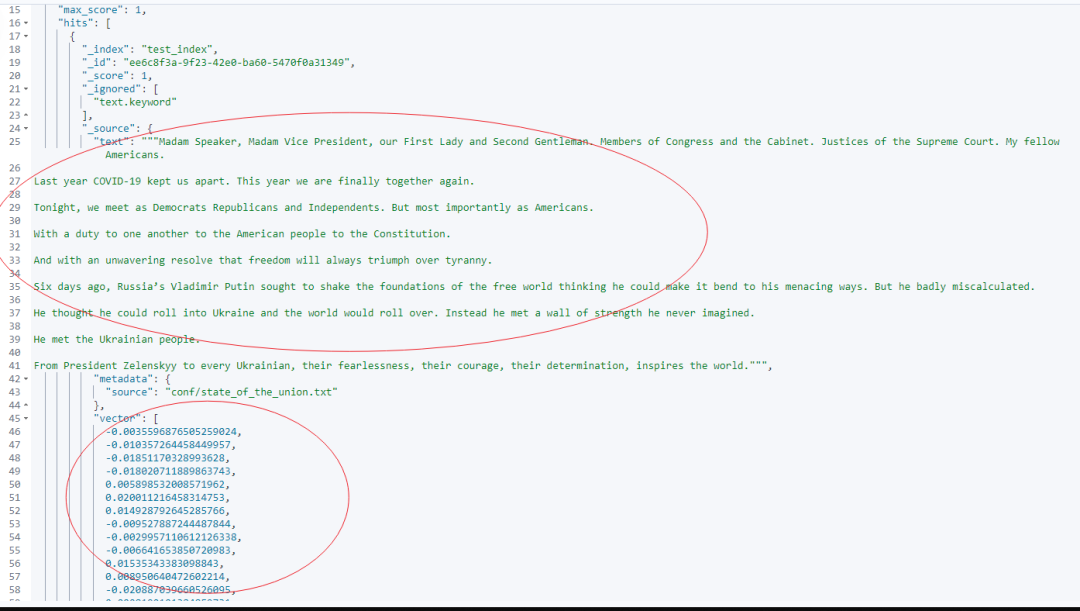
results = db.similarity_search(query)
print(results)这段代码展示了如何加载、处理文档,并通过 Langchain 结合 Elasticsearch 进行智能检索。
执行结果:
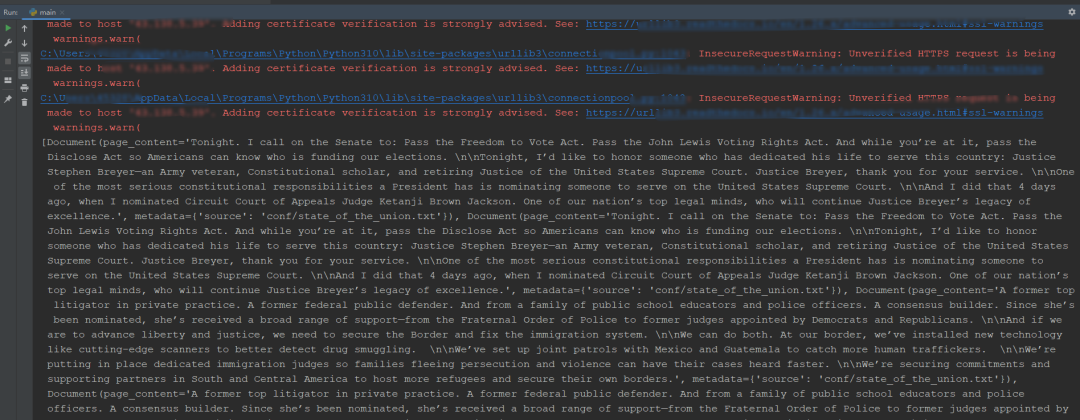
4.2 案例2:精细化处理
进一步,我们可以为文档添加更丰富的元数据,并利用这些元数据进行更精细化的搜索:
# 添加元数据
for i, doc in enumerate(docs):
doc.metadata["date"] = f"{range(2010, 2020)[i % 10]}-01-01"
doc.metadata["rating"] = range(1, 6)[i % 5]
doc.metadata["author"] = ["John Doe", "Jane Doe"][i % 2]
# 再次连接 Elasticsearch
conn = Elasticsearch(
"https://127.0.0.1:9200",
ca_certs = "certs/http_ca.crt",
basic_auth = ("elastic", "changeme"),
verify_certs=False
)
# 创建带有元数据的索引
db = ElasticsearchStore.from_documents(docs, embeddings, index_name="test-metadata", es_connection=conn)
# 执行检索
query = "What did the president say about Ketanji Brown Jackson"
docs = db.similarity_search(query)
print(docs[0].metadata)
# 应用过滤条件
docs = db.similarity_search(query, filter=[{"term": {"metadata.author.keyword": "John Doe"}}])
print(docs[0].metadata)执行结果:
1、写入 Elasticsearch 索引,效果图:

2、执行检索效果:

在这个案例中,我们通过添加元数据来增强文档的描述性,使得检索结果更加精确和有用。
5、问题解决
在实际应用中,我们可能会遇到各种问题,例如网络连接问题、配置错误或代码逻辑问题。
在这种情况下,确保你的环境设置正确,并且仔细检查代码中的每个步骤,以确保所有操作按预期进行。
6、总结
通过结合 Langchain 和 Elasticsearch,我们可以构建一个强大的数据检索系统,不仅能处理大量数据,还能以智能和高效的方式进行搜索和分析。
官网代码都不能跑起来,需要自己摸索好长时间!
这种技术的融合,为处理复杂的信息检索任务提供了新的可能。
希望这篇博客能够帮助读者更好地理解 Langchain和 Elasticsearch 如何结合,以及如何在实际项目中应用这些技术。这种整合为数据检索和自然语言处理的未来发展开辟了新的道路。
7、参考资料
Langchain 官方文档:
https://python.langchain.com/docs/integrations/vectorstores/elasticsearch
推荐阅读
全网首发!从 0 到 1 Elasticsearch 8.X 通关视频
重磅 | 死磕 Elasticsearch 8.X 方法论认知清单
如何系统的学习 Elasticsearch ?
2023,做点事

更短时间更快习得更多干货!
和全球 近2000+ Elastic 爱好者一起精进!