1.什么是分包?为什么要分包?
默认情况下,Webpack 会将所有代码构建成一个单独的包,这在小型项目通常不会有明显的性能问题,但伴随着项目的推进,包体积逐步增长可能会导致应用的响应耗时越来越长。归根结底这种将所有资源打包成一个文件的方式存在两个弊端:
- 「资源冗余」:客户端必须等待整个应用的代码包都加载完毕才能启动运行,但可能用户当下访问的内容只需要使用其中一部分代码
- 「缓存失效」:将所有资源达成一个包后,所有改动 —— 即使只是修改了一个字符,客户端都需要重新下载整个代码包,缓存命中率极低
这些问题都可以通过代码分离解决,例如 node_modules 中的资源通常变动较少,可以抽成一个独立的包,那么业务代码的频繁变动不会导致这部分第三方库资源被无意义地重复加载。
- 它主要的目的是将代码分离到不同的bundle中,之后我们可以按需加载,或者并行加载这些文件; 比如默认情况下,所有的JavaScript代码(业务代码、第三方依赖、暂时没有用到的模块)在首页全部都加载, 就会影响首页的加载速度;
- 代码分离可以分出出更小的bundle,以及控制资源加载优先级,提供代码的加载性能;
- 入口起点:使用entry配置手动分离代码;
- 防止重复:使用Entry Dependencies或者SplitChunksPlugin去重和分离代码;
- 动态导入:通过模块的内联函数调用来分离代码;
2.配置多入口
- 比如配置一个index.js和main.js的入口;
- 他们分别有自己的代码逻辑;
const path = require('path');
module.exports = {
entry: {
main: './src/main.js', // 第一个入口起点
app: './src/app.js' // 第二个入口起点
},
output: {
filename: '[name].bundle.js', // 使用[name]占位符将生成的文件名与入口起点名称对应
path: path.resolve(__dirname, 'build')
} ,
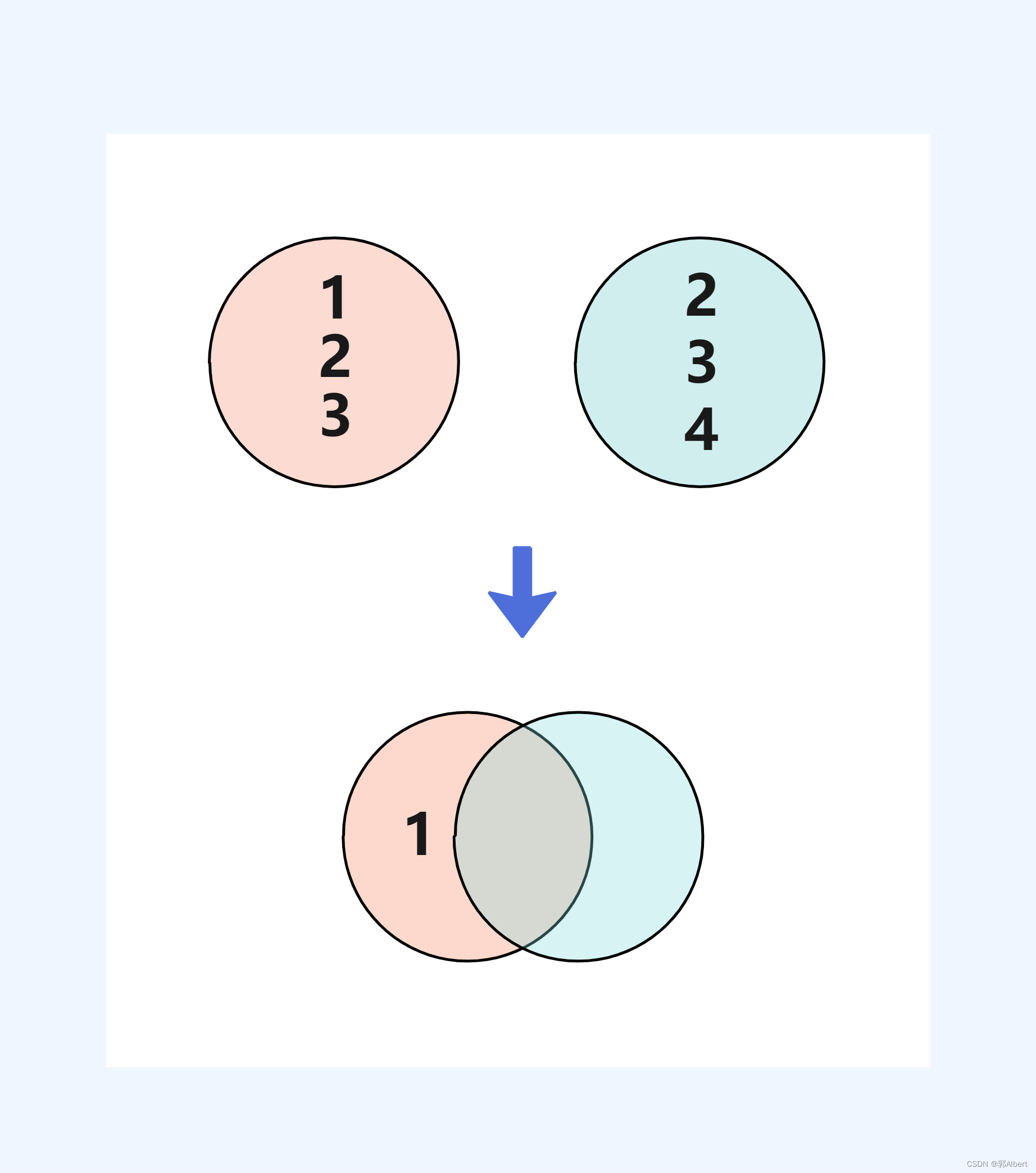
};- 假如我们的index.js和main.js都依赖两个库:lodash、dayjs
- 如果我们单纯的进行入口分离,那么打包后的两个bunlde都有会有一份lodash和dayjs;
const path = require('path');
module.exports = {
entry: {
main: { import: './src/main.js', dependOn: 'shared' }, // 第一个入口起点
app: { import: './src/app.js', dependOn: 'shared' }, // 第二个入口起点
shared: ['dayjs', 'lodash'] // 共享的库
},
output: {
filename: '[name].bundle.js', // 使用[name]占位符将生成的文件名与入口起点名称对应
path: path.resolve(__dirname, 'dist') }
};3.SplitChunks
Webpack 提供了 SplitChunkPlugin 进行分包优化。SplitChunksPlugin 插件可以将应用程序中共享的代码拆分成单独的块,以便将其从应用程序代码中分离出来,从而提高性能和加载速度。 该插件webpack已经默认安装和集成,所以我们并不需要单独安装和直接使用该插件,只需要提供SplitChunksPlugin 相关的配置信息即可。
- Webpack提供了SplitChunksPlugin默认的配置,我们也可以手动来修改它的配置:
- 比如默认配置中,chunks仅仅针对于异步(async)请求,我们可以设置为initial或者all;
SplitChunksPlugin默认的配置
const { resolve } = require('path');
module.exports = {
entry: './src/main.js',
output: {
filename: 'bundle.js',
path: resolve(__dirname, 'build')
},
optimization: {
splitChunks: {
chunks: 'async',
minSize: 20000,
minRemainingSize: 0,
minChunks: 1,
maxAsyncRequests: 30,
maxInitialRequests: 30,
enforceSizeThreshold: 50000,
cacheGroups: {
defaultVendors: {
test: /[\\/]node_modules[\\/]/,
priority: -10,
namw:'', // 用在filename中的name占位符
fileName: 'vender_[id]_[name].js', //打包之后的文件名
reuseExistingChunk: true,
},
default: {
minChunks: 2,
priority: -20,
reuseExistingChunk: true,
},
},
},
},
};一些常见的配置项
| 属性名 | 值 |
splitChunks.chunks |
|
splitChunks.minSize | 拆分出来的这个包的最小尺寸为minSize(以 bytes 为单位)
如果一个包拆分出来达不到minSize,那么这个包就不会拆分;
|
splitChunks.maxSize | 将大于maxSize的包, 拆分成不小于minSize的包 |
splitChunks.minChunks |
至少被引入的次数,默认是1;
如果我们写一个2,但是引入了一次,那么不会被单独拆分;
|
splitChunks.maxAsyncRequests | 最大的初始化请求数量 |
splitChunks.cacheGroups | 用于对拆分的包进行分组 |
cacheGroups
- test属性:匹配符合规则的包;
- name属性:拆分包的name属性;
- filename属性:拆分包的名称,可以自己使用placeholder属性;
- priority: 一个模块可以属于多个cacheGroups。优化将优先考虑具有更高
priority(优先级)的cacheGroups。默认组的优先级为负,自定义组的默认值为0; reuseExistingChunk:如果当前 chunk 包含已从主 bundle 中拆分出的模块,则它将被重用,而不是生成新的模块。这可能会影响 chunk 的结果文件名;
更多的配置可以参考:
SplitChunksPlugin | webpack 中文文档 (docschina.org)
4.动态导入
当代码中存在不确定会被使用的模块时,最佳做法是将其分离为一个独立的 JavaScript 文件。
- 这样可以确保在不需要该模块时,浏览器不会加载或处理该文件的 JavaScript 代码。
- 我们平时使用的路由懒加载的就是这个原理,都是为了优化性能而延迟加载资源。
实现动态导入的方式是使用ES6的import()语法来完成。
- 在webpack中,通过动态导入获取到一个对象;
- 真正导出的内容,在该对象的default属性中,所以我们需要做一个简单的解构;
4.1 路由懒加载
动态导入最常见的使用场景就是路由懒加载
// main.js文件中
const homeBtn = document.createElement('button')
const aboutBtn = document.createElement('button')
homeBtn.textContent = '加载home文件'
aboutBtn.textContent = '加载about文件'
document.body.appendChild(homeBtn)
document.body.appendChild(aboutBtn)
homeBtn.addEventListener('click', () => {
import('./views/home.js')
})
aboutBtn.addEventListener('click', () => {
import('./views/about.js')
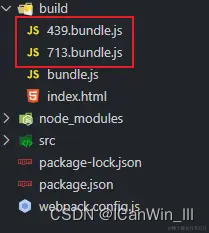
})打包之后的资源:
4.2 配置打包文件的名称
但是我们会发现一个问题,从包名中无法区分是哪个文件构建后的包,我们可以通过以下方式修改打包之后的文件名:
output.chunkFilename
const { resolve } = require('path');
module.exports = {
entry: './src/main.js',
output: {
filename: 'bundle.js',
path: resolve(__dirname, 'build'),
chunkFilename: 'chunk_[name]_[id].js',
},
};默认情况下我们获取到的 [name] 和 [id] 的名称保持一致的,如果我们希望修改name的值,可以通过magic comments(魔法注释)的方式;
- webpackChunkName 魔法注释
// main.js
homeBtn.addEventListener('click', () => {
import(/* webpackChunkName: "home" */'./views/home.js') // 让webpack读取的魔法注释,固定写法
})
aboutBtn.addEventListener('click', () => {
import(/* webpackChunkName: "about" */'./views/about.js')
})
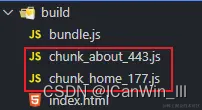
打包之后的资源,可以从名称看出原始文件是哪一个
4.3 prefetch(预获取)
prefetch被用于懒加载策略。它会在浏览器空闲时,即浏览器已经加载主要资源并且有剩余带宽时,开始加载。这意味着它不会影响初始页面加载时间,因为它是在后台加载的。通常用于加载将来可能需要的资源,例如懒加载的代码块或其他不太紧急的资源。
4.4 preload(预加载)
preload用于立即加载重要资源。它会在当前页面加载时立即开始加载,而不管浏览器的空闲状态如何。因此,preload可能会影响初始页面加载性能,因为它可以竞争主要资源的带宽。通常用于加载当前页面渲染所必需的关键资源,如字体、样式表或脚本。
import(/* webpackPrefetch: true */ './view/home');
import(/* webpackPreload: true */ './view/about');5.runtime代码的分包
- runtime相关的代码指的是在运行环境中,对模块进行解析、加载、模块信息相关的代码;
- 比如我们的component、bar两个通过import函数相关的代码加载,就是通过runtime代码完成的;
- 比如我们修改了业务代码(main),那么runtime和component、bar的chunk是不需要重新加载的;
- 比如我们修改了component、bar的代码,那么main中的代码是不需要重新加载的;
const { resolve } = require('path');
module.exports = {
entry: './src/main.js',
output: {
filename: 'bundle.js',
path: resolve(__dirname, 'build')
},
optimization: {
runtimeChunk: 'true/multiple' //针对每个入口打包一个runtime文件
runtimeChunk: 'single' //打包一个runtime文件
runtimeChunk: {
name: function(entrypoint) {
return `my-${entrypoint.name}` // 决定runtimeChunk的名称
}
}
},
};- true/multiple:针对每个入口打包一个runtime文件;
- single:打包一个runtime文件;
- 对象:name属性决定runtimeChunk的名称;
6.将css提取到一个独立的css文件
我们平时在打包css文件时,是通过css-loader和style-loader进行如下配置,最终会把css注入到页面中,
const { resolve } = require('path');
module.exports = {
entry: './src/main.js',
output: {
filename: 'bundle.js',
path: resolve(__dirname, 'build'),
},
module: {
rules: [
{ //通过正则告诉webpack匹配是什么文件
test: /\.css$/,
use: [
// 因为loader的执行顺序是从右向左(或者说从下到上,或者说从后到前 的),所以我们需要将style-loader写到css-loader的前面;
{ loader: 'style-loader' },
{ loader: 'css-loader' }
]
}
]
},
};如果将css单独打包到一个css文件中有如下好处:
- 分离结构和样式:将CSS独立出来可以将网页的结构(HTML)和样式(CSS)分开,使代码更加模块化和易于维护。
- 缓存优化:独立的CSS文件可以被浏览器缓存,当用户再次访问网站时,可以减少加载时间,提高性能。
- 首先,我们需要安装 mini-css-extract-plugin:
npm install mini-css-extract-plugin -D- 配置rules和plugins:
const { resolve } = require('path');
const MiniCssExtractPlugin = require('mini-css-extract-plugin')
module.exports = {
entry: './src/main.js',
output: {
filename: 'bundle.js',
path: resolve(__dirname, 'build'),
},
module: {
rules: [
{
test: /\.css$/,
use: [
// 将CSS样式提取为单独的CSS文件,通过链接方式(link)引入到HTML中
{ loader: MiniCssExtractPlugin.loader },
{ loader: 'css-loader' }
]
}
]
},
plugins: [
new MiniCssExtractPlugin({ // 使用MiniCssExtractPlugin插件
filename: "css/[name]_[id].css", // 打包后的css文件放到css文件夹中
chunkFilename: "css/[name]_[id].css"
}
)
],
};
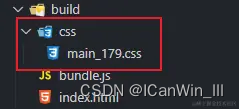
打包之后,css被单独打包到build/css/main_179.css
参考:
Webpack 优化实操(十一):页面分包优化 - 知乎 (zhihu.com)
webpack性能优化(一):分包 - 掘金 (juejin.cn)








![XCTF:Hidden-Message[WriteUP]](https://img-blog.csdnimg.cn/direct/760c4bec007c44828005829c17470f0a.png)
![[python]pyside6安装和在pycharm配置](https://img-blog.csdnimg.cn/direct/877509476c884ab8823593ba7c5c1e58.png)