英文原文地址:https://medium.com/nerd-for-tech/enhancing-faq-search-engines-harnessing-the-power-of-knn-in-elasticsearch-76076f670580
增强FAQ搜索引擎:发挥Elasticsearch中KNN的威力
2023 年 10 月 21 日
在一个快速准确的信息检索至关重要的时代,开发强大的搜索引擎是至关重要的。随着大型语言模型(LLM)和信息检索体系结构(如RAG)的出现,在现代软件系统中利用文本转向量(Embeddings)和向量数据库已经变得非常流行。我们深入研究了如何利用Elasticsearch的k近邻(KNN)搜索和来自强大语言模型的文本Embedding的细节,这是一个强有力的组合,有望彻底改变我们访问常见问题(FAQ)的方式。通过对Elasticsearch的KNN功能的全面探索,我们将揭示这种集成如何使我们能够创建一个前沿的FAQ搜索引擎,通过理解查询的语义上下文,以闪电般的延迟增强用户体验。
在开始设计解决方案之前,让我们先了解信息检索系统中的一些基本概念。
文本转向量(Embeddings)
The best way to describe an embedding is explained in this article.
Embedding是一条信息的数字表示,例如,文本、文档、图像、音频等。它的特点在于我们不需要完全通过字面值(通俗一点就是关键字)来检索内容,而是可以通过相近的意思来检索。
语义检索
传统的搜索系统使用词法匹配来检索给定查询的文档。语义搜索旨在使用文本表示(Embedding)来理解查询的上下文,以提高搜索准确性。
语义搜索的类型
对称语义搜索:查询和搜索文本长度相似的搜索用例。例如,在数据集中找到类似的问题。
不对称语义搜索:查询和搜索文本长度不同的搜索用例。例如,为给定查询查找相关段落。
译注:如果你用的chunking基于句向量,那么可以认为就是对称的。
向量搜索引擎(向量数据库)
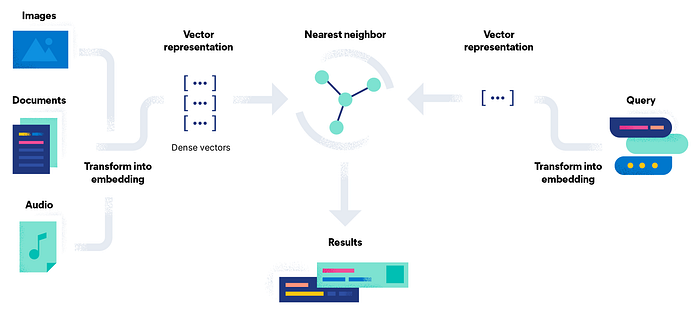
向量搜索引擎是专门的数据库,可用于存储非结构化信息,如图像、文本、音频或视频经过Embedding之后的向量。在这里,我们将使用Elasticsearch的向量搜索功能。现在我们先来了解搜索系统的构建流程,让我们深入了elasticsearch的体系结构和实现。
解决方案架构
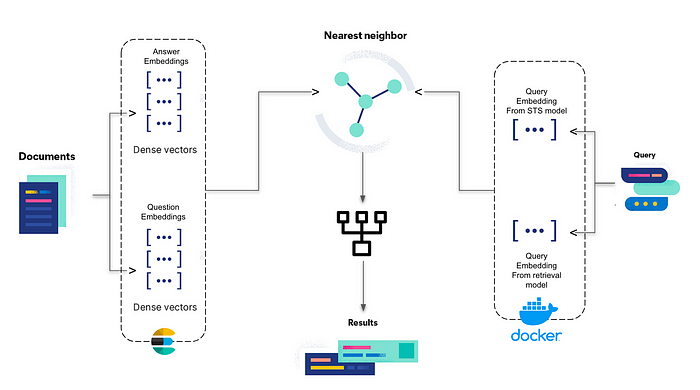
- 搜索解决方案的第一步是将问答对索引到Elasticsearch中。我们将创建一个索引,并将问题和答案Embedding存储在同一个索引中。我们将根据检索的特征使用2个独立的模型来Embedding问题和答案。
- 我们将使用步骤1中使用的相同模型嵌入查询,并形成搜索查询(3部分,即问题,答案,词汇搜索),将查询Embedding映射到各自的问题和答案Embedding。
- 我们还将为查询的每个部分提供一个boost值,以表示它们在组合中的重要性。返回的最终结果基于分数的总和乘以各自的boost值进行排序。
环境设置
设置索引。您可以使用以下映射作为起点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"Question": { "type": "text" },
"Answer": { "type": "text" },
"question_emb": {
"type": "dense_vector",
"dims": 768,
"index": true,
"similarity": "dot_product"
},
"answer_emb": {
"type": "dense_vector",
"dims": 1024,
"index": true,
"similarity": "dot_product"
}
}
}
}
|
模型选择
由于我们使用一种相当常见的语言处理数据,因此为了进行这个实验,我从Retrieval(用于答案)和STS(用于问题)部分的MTEB排行榜中选择了表现最好的模型。
选择模式:
- 答案(Retrieval):BAAI/big -large-en-v1.5(您可以使用quantized版本进行更快的推理)
- 提问(STS):thenlper/gte-base
如果您有特定于领域的常见问题解答,并且想要检查哪个模型表现最好,您可以使用Beir:https://github.com/beir-cellar/beir。查看https://github.com/beir-cellar/beir/wiki/Load-your-custom-dataset,该部分描述了如何加载您的自定义数据集进行评估。
实现
为了这个实验的目的,我将使用Kaggle的一个心理健康常见问题解答(https://www.kaggle.com/datasets/narendrageek/mental-health-faq-for-chatbot/)数据集。
- 加载数据集
1 2 | import pandas as pd
data = pd.read_csv('Mental_Health_FAQ.csv')
|
- 生成Embedding
1 2 3 4 | from sentence_transformers import SentenceTransformer
question_emb_model = SentenceTransformer('thenlper/gte-base')
data['question_emb'] = data['Questions'].apply(lambda x: question_emb_model.encode(x, normalize_embeddings=True))
|
注:我们将Embedding归一化,使用点积代替余弦相似度作为相似度度量。计算速度更快,推荐参考Elasticsearch的Dense Vector Field(https://www.elastic.co/guide/en/elasticsearch/reference/8.8/dense-vector.html)文档。
1 2 3 | answer_emb_model = SentenceTransformer('BAAI/bge-large-en-v1.5')
data['answer_emb'] = data['Answers'].apply(lambda x: answer_emb_model.encode(x, normalize_embeddings=True))
|
- 索引文件
我们将使用Elasticsearch辅助函数。具体来说,我们将使用streaming_bulk API来索引文档。
首先,让我们实例化elasticsearch python客户端。
1 2 3 4 5 6 7 8 9 | from elasticsearch import Elasticsearch
from ssl import create_default_context
context = create_default_context(cafile=r"path\to\certs\http_ca.crt")
es = Elasticsearch('https://localhost:9200',
http_auth=('elastic', 'elastic_generated_password'),
ssl_context=context,
)
|
接下来,我们需要创建一个文档生成器,它可以提供给流批量API。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | index_name="faq-index"
def generate_docs():
for index, row in data.iterrows():
doc = {
"_index": index_name,
"_source": {
"faq_id":row['Question_ID'],
"question":row['Questions'],
"answer":row['Answers'],
"question_emb": row['question_emb'],
"answer_emb": row['answer_emb']
},
}
yield doc
|
最后,我们可以索引文档。
1 2 3 4 5 6 7 8 9 10 | import tqdm
from elasticsearch.helpers import streaming_bulk
number_of_docs=len(data)
progress = tqdm.tqdm(unit="docs", total=number_of_docs)
successes = 0
for ok, action in streaming_bulk(client=es, index=index_name, actions=generate_docs()):
progress.update(1)
successes += ok
print("Indexed %d/%d documents" % (successes, number_of_docs))
|
- 查询文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | def faq_search(query="", k=10, num_candidates=10):
if query is not None and len(query) == 0:
print('Query cannot be empty')
return None
else:
query_question_emb = question_emb_model.encode(query, normalize_embeddings=True)
instruction="Represent this sentence for searching relevant passages: "
query_answer_emb = answer_emb_model.encode(instruction + query, normalize_embeddings=True)
payload = {
"query": {
"match": {
"title": {
"query": query,
"boost": 0.2
}
}
},
"knn": [ {
"field": "question_emb",
"query_vector": query_question_emb,
"k": k,
"num_candidates": num_candidates,
"boost": 0.3
},
{
"field": "answer_emb",
"query_vector": query_answer_emb,
"k": k,
"num_candidates": num_candidates,
"boost": 0.5
}],
"size": 10,
"_source":["faq_id","question", "answer"]
}
response = es.search(index=index_name, body=payload)['hits']['hits']
return response
|
注:正如模型页面上所指示的,在将查询转换为Embedding之前,我们需要将指令附加到查询中。此外,我们使用模型的v1.5版本,因为它具有更好的相似度分布。查看模型页面上的常见问题解答以获取更多详细信息。
评价
为了了解所提出的方法是否有效,将其与传统的KNN搜索系统进行评估是很重要的。让我们试着定义这两个系统并评估提议的系统。
系统1:非对称KNN搜索(查询和回答向量)。
系统2:查询(BM25)、非对称KNN搜索(查询和答案向量)和对称KNN搜索(查询和问题向量)的组合。
为了评估系统,我们必须模拟用户如何使用搜索。简而言之,我们需要从源问题中生成与问题复杂性相似的意译问题。我们将使用t5-small-fine-tuned-quora-for-paraphrasing微调模型来解释问题。
让我们定义一个可以生成转述问题的函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 | from transformers import AutoModelWithLMHead, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("mrm8488/t5-small-finetuned-quora-for-paraphrasing")
model = AutoModelWithLMHead.from_pretrained("mrm8488/t5-small-finetuned-quora-for-paraphrasing")
def paraphrase(question, number_of_questions=3, max_length=128):
input_ids = tokenizer.encode(question, return_tensors="pt", add_special_tokens=True)
generated_ids = model.generate(input_ids=input_ids, num_return_sequences=number_of_questions, num_beams=5, max_length=max_length, no_repeat_ngram_size=2, repetition_penalty=3.5, length_penalty=1.0, early_stopping=True)
preds = [tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=True) for g in generated_ids]
return preds
|
现在我们已经准备好了我们的释义函数,让我们创建一个评估数据集,我们将使用它来度量系统的准确性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | temp_data = data[['Question_ID','Questions']]
eval_data = []
for index, row in temp_data.iterrows():
preds = paraphrase("paraphrase: {}".format(row['Questions']))
for pred in preds:
temp={}
temp['Question'] = pred
temp['FAQ_ID'] = row['Question_ID']
eval_data.append(temp)
eval_data = pd.DataFrame(eval_data)
#shuffle the evaluation dataset
eval_data=eval_data.sample(frac=1).reset_index(drop=True)
|
最后,我们将修改faq_search函数以返回相应系统的faq_id。
对于系统1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | def get_faq_id_s1(query="", k=5, num_candidates=10):
if query is not None and len(query) == 0:
print('Query cannot be empty')
return None
else:
instruction="Represent this sentence for searching relevant passages: "
query_answer_emb = answer_emb_model.encode(instruction + query, normalize_embeddings=True)
payload = {
"knn": [
{
"field": "answer_emb",
"query_vector": query_answer_emb,
"k": k,
"num_candidates": num_candidates,
}],
"size": 1,
"_source":["faq_id"]
}
response = es.search(index=index_name, body=payload)['hits']['hits']
return response[0]['_source']['faq_id']
|
对于系统2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | def get_faq_id_s2(query="", k=5, num_candidates=10):
if query is not None and len(query) == 0:
print('Query cannot be empty')
return None
else:
query_question_emb = question_emb_model.encode(query, normalize_embeddings=True)
instruction="Represent this sentence for searching relevant passages: "
query_answer_emb = answer_emb_model.encode(instruction + query, normalize_embeddings=True)
payload = {
"query": {
"match": {
"title": {
"query": query,
"boost": 0.2
}
}
},
"knn": [ {
"field": "question_emb",
"query_vector": query_question_emb,
"k": k,
"num_candidates": num_candidates,
"boost": 0.3
},
{
"field": "answer_emb",
"query_vector": query_answer_emb,
"k": k,
"num_candidates": num_candidates,
"boost": 0.5
}],
"size": 1,
"_source":["faq_id"]
}
response = es.search(index=index_name, body=payload)['hits']['hits']
return response[0]['_source']['faq_id']
|
注:Boost值是实验性的。为了这个实验,我根据组合中每个领域的重要性进行了划分。搜索中每个字段的重要性完全是主观的,可能由业务本身定义,但如果没有,系统的一般经验法则是Answer向量 > Question向量 > Query。
我们已经准备好开始评估了。我们将为两个系统生成一个预测列,并将其与原始的faq_id进行比较。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | eval_data['PRED_FAQ_ID_S1'] = eval_data['Question'].apply(get_faq_id_s1)
from sklearn.metrics import accuracy_score
ground_truth = eval_data["FAQ_ID"].values
predictions_s1 = eval_data["PRED_FAQ_ID_S1"].values
s1_accuracy = accuracy_score(ground_truth, predictions_s1)
print('System 1 Accuracy: {}'.format(s1_accuracy))
System 1 Accuracy: 0.7312925170068028
eval_data['PRED_FAQ_ID_S2'] = eval_data['Question'].apply(get_faq_id_s2)
predictions_s2 = eval_data["PRED_FAQ_ID_S2"].values
s2_accuracy = accuracy_score(ground_truth, predictions_s2)
print('System 2 Accuracy: {}'.format(s2_accuracy))
System 2 Accuracy: 0.8401360544217688
|
与非对称KNN搜索相比,我们可以看到准确度提高了7-11% 。
我也尝试过ramsrigouthamg/t5_paraphraser,但这个模型产生的问题有点复杂和冗长(虽然在上下文中)。您还可以使用LLM来生成评估数据集并检查系统的执行情况。
准确性的提高是主观的,取决于查询的质量,即查询的上下文丰富程度、Embedding质量,甚至用户的不同使用场景。为了更好地理解这一点,让我们考虑两种终端用户:
- 一般用户,想要了解你的产品和服务的一些事实:在这种情况下,上述系统会做得很好,因为问题简单,直观,在上下文中足够。
- 专业用户,例如想要了解产品的一些复杂细节以建立系统或解决某些问题的工程师:在这种情况下,查询就其词法组成而言更加特定于领域,因此,开箱即用的模型Embedding将无法捕获所有上下文。那么,我们如何解决这个问题呢?系统的架构将保持不变,但搜索系统的整体准确性可以通过使用特定领域的数据(或预训练的特定领域的模型)微调这些模型来提高。
结论
在本文中,我们提出并实现了使用多种搜索类型组合的FAQ搜索。我们研究了Elasticsearch如何将对称和非对称语义搜索结合起来,从而将搜索系统的性能提高了11%。我们也了解所建议的搜索架构的系统和资源需求,这将是考虑采用此方法的主要决定因素。
本文Github代码:https://github.com/satishsilveri/Semantic-Search/blob/main/FAQ-Search-using-Elastic.ipynb
引用
- k-nearest neighbor (kNN) search | Elasticsearch Guide [8.11] | Elastic
- Semantic Search — Sentence-Transformers documentation
- https://huggingface.co/blog/getting-started-with-embeddings
- Install Elasticsearch with Docker | Elasticsearch Guide [8.11] | Elastic
- Dense vector field type | Elasticsearch Guide [8.8] | Elastic
- Mental Health FAQ for Chatbot | Kaggle
- https://huggingface.co/spaces/mteb/leaderboard
- https://huggingface.co/BAAI/bge-large-en-v1.5
- https://huggingface.co/thenlper/gte-base
- https://huggingface.co/mrm8488/t5-small-finetuned-quora-for-paraphrasing