文章目录
- 前言
- 0、论文摘要
- 一、Introduction
- 1.1目标问题
- 1.2相关的尝试
- 1.3本文贡献
- 二.相关工作
- 2.1. Seq2seq 模型
- 2.2.强化学习和序列生成
- 2.3.自动文本摘要
- 三.本文方法
- 四 实验效果
- 4.1数据集
- 4.2 对比模型
- 4.3实施细节
- 4.4评估指标
- 4.5 实验结果
- 4.6 细粒度分析
- 五 总结
- 思考
前言

Automatic Text Summarization Using Deep Reinforcement Learning and Beyond(2103)
0、论文摘要
大数据时代,信息过载问题日益突出。利用人工智能技术来理解、压缩和过滤海量文本信息对机器来说是一个挑战。自动文本摘要的出现主要是为了解决信息过载的问题,可以分为抽取式和抽象式两种。前者从原文中找出一些关键的句子或短语,组合成摘要;后者需要计算机理解原文的内容,然后用人类可读的语言概括原文的关键信息。本文提出了一种结合抽象摘要和提取摘要的两阶段自动文本摘要优化方法。首先,训练具有注意力机制的序列到序列模型作为基线模型以生成初始摘要。其次,它通过使用深度强化学习(DRL)直接在 ROUGE 指标上进行更新和优化。实验结果表明,与基线模型相比,Rouge-1、Rouge-2、Rouge-L在LCSTS数据集和CNN/DailyMail数据集上都有所增加。
一、Introduction
人工智能技术正处于快速发展时期,其在各行业的应用日益普遍。从医疗诊断到社交网络,从智能教育到新闻媒体,人工智能的具体应用案例随处可见。在人们的日常生活中,我们面临着信息过载,如何在有限的时间内处理海量的数据信息成为了一个问题。利用计算机理解自然语言可以过滤掉无用和冗余的信息,只保留反馈给用户的关键信息。这种特定的应用称为自动文本摘要。它利用计算机对全文进行概括,帮助用户通过阅读摘要直接理解原文的核心语义。因此,自动提取摘要的机器学习模型可以快速从海量文本中提取关键信息,节省用户宝贵的时间。自动文本摘要的出现不仅减少了信息过载,还节省了人工文本摘要的高昂成本。
自动文本摘要主要分为两类方法。提取摘要技术从原文中提取几个关键句子,然后形成一个摘要。抽象摘要技术理解原文的语义,用人类可读的语言概括和归纳主题。目前,抽取式摘要相对容易实现,因此应用较为广泛。抽象概括需要计算机具有理解原文的能力,因此对技术要求较高。
传统的提取摘要技术有两种类型:基于图的排序方法和基于人工特征的方法。基于图排序方法,将文档中的每个句子作为图的节点,计算句子之间的相似度,并将相似度的值作为边的权重构建图模型。然后,使用PageRank算法[36]求解每个句子的得分;最后,输出最高分作为总结。代表性算法是 TextRank [30] 和 LexRank [11]。基于人工特征的方法通常基于每个句子的长度,句子是否包含标题词。代表算法是TextTeaser。随着深度学习的兴起及其强大的特征表示能力,越来越多的提取摘要技术被提出,并取得了优异的结果。提取摘要技术不需要考虑提取摘要的语法和语义问题。然而,由于提取的摘要只是原始句子的组合,因此常常存在不一致、信息冗余等问题。相对而言,抽象概括更便于人类理解。基于深度学习的序列生成模型[2]的出现使得抽象概括成为研究热点。 seq2seq模型[5]作为基准模型应用于抽象摘要任务中,许多深度学习模型正在涌现。在相应的数据集上取得了最好的结果。
针对以往文本摘要算法中上下文语义信息利用不足、注意力机制语义理解不足以及文本摘要准确率低等问题,提出一种自动摘要优化算法,该算法首先采用seq2seq模型,注意力机制[45]作为初始摘要生成的基本模型,然后使用深度增强学习直接通过ROUGE评估标准[23]优化初始摘要。基础模型生成的摘要是抽象摘要,所提出的优化算法选择基础模型在解码阶段的词输出分布以及构成原词注意力分布的top-k个最高概率分布的词作为增强学习的行动空间。通过增强学习技术优化初始摘要。
1.1目标问题
1.2相关的尝试
1.3本文贡献
总之,我们的贡献如下:
本文首次提出了一种将抽象摘要和抽取式摘要相结合的两阶段自动文本摘要优化方法。
2 首先,训练具有注意力机制的序列到序列模型作为基线模型以生成初始摘要。其次,它通过使用深度强化学习(DRL)直接在 ROUGE 指标上进行更新和优化。 3 与基本模型相比,在LCSTS数据集和CNN/DailyMail数据集上增加了Rouge-1、Rouge-2和Rouge-L。因此,优化方法的效果有所提高。
二.相关工作
2.1. Seq2seq 模型
seq2seq 模型广泛应用于自然语言处理 [6, 34, 17]。 seq2seq模型主要由编码器和解码器组成。编码器使用循环神经网络(RNN),例如长短期记忆网络[18](LSTM)将输入序列编码为固定维度的向量,然后解码器使用RNN对该向量进行解码以产生输出序列。将注意力机制[2]应用到seq2seq模型中,可以在序列生成过程中为输入序列的不同部分分配不同的权重。在自然语言任务中,seq2seq模型通常使用固定的输入和输出词汇表,这导致出现在词汇表之外的单词的表示效果很差。通过解码器网络指向输入序列中的一些不寻常的单词或子序列,然后将它们直接复制到输出序列中的方法[47, 24]可以很大程度上解决这个问题。 Gulcehre [13] 和 Merity [29] 将这种指向机制应用到解码过程中;那么,模型不仅可以生成词汇表中的词汇,还可以输出生僻词。
2.2.强化学习和序列生成
Alpha Go 的出现引起了人们对人工智能的极大兴趣。强化学习是Alpha Go中最重要的技术,它是通过计算机算法学习控制策略框架。给定智能体和交互环境[42],智能体可以通过强化学习来训练学习策略,从而获得最大的奖励。比较的与传统的监督学习方法相比,当智能体必须执行离散动作或优化过程未定义时,可以使用强化学习来解决问题。直接通过BELU、ROUGE、METEOR等指标来优化序列生成问题的过程是不可分的,因此强化学习可以应用于序列生成任务。
为了实现任务评估标准的直接优化,与传统的监督学习相比,Ranzato [38] 使用 REINFORCE 算法 [48] 训练基于循环神经网络的序列生成任务模型。强化学习训练方法的结果得到了明显的提升。 Bahdanau[1]提出了一种评估-决策方法来训练神经网络生成序列,使用决策网络来预测输出动作,然后使用评估网络来评估决策网络的值以生成动作,同时也使训练工艺更稳定。 Rennie[39]提出了一种无需额外决策网络的自评估序列生成训练方法,在图片标题生成任务中的评估结果得到显着提升。郭[15]提出了一种基于深度Q网络[32](DQN)训练序列到序列学习任务的迭代解码输出序列。郭的方法[15]模拟了自动文本摘要优化方法,通过具有注意力机制的seq2seq模型生成初始摘要和候选动作空间,并使用DQN直接优化初始摘要评估标准(ROUGE)。
2.3.自动文本摘要
自动化摘要研究主要集中在两个领域:文本 [9, 35, 27] 和语音 [50, 51]。尽管抽象概括研究已经取得了一些进展,但大多数表现出色的概括模型仍然基于提取方法。传统的提取摘要方法主要基于贪婪搜索[3]和图模型方法[11]。 Kageback [21] 通过部署递归自动编码器 [43] 实现文档摘要生成。 Yin[49]使用卷积神经网络根据多样性和重要性最小化目标函数,并选择句子来生成摘要。 Nallapati [34] 调整了一个问题DeepMind [17] 将其和答案数据集转化为摘要数据集 CNN/DailyMail 数据集,并在此数据集上提出了第一个抽象摘要基准模型。在这个数据集上,Cheng 和 Lapata [5] 提出了一种用于摘要提取的面向注意力的编码器-解码器框架。 Nallapati [33]还提出了一种模型,构建层次循环神经网络来选择和提取原始句子。
抽取式文摘方法虽然较为简单,也存在一定误差,但也存在抽取式文摘上下文语义不一致、引用不明确等问题。广义的方法更加自由,更符合人类的写作和思维模式,可以生成新的、多样化的句子。随着基于神经网络的文本生成模型[36]的出现,抽象摘要技术正在成为研究热点。 Rush [40]提出了一种带有卷积编码器的注意力模型。在CNN/DailyMail数据集上,Chen[4]提出了一种新颖的注意力机制并将其应用于摘要生成模型。在 CNN/DailyMail 数据集上,Nallapati [34] 使用分层注意力机制和指针函数构建了分层网络结构模型。在同一数据集上,See [41]提出了一个指针网络,并在其模型的损失函数中另外使用了注意力覆盖机制的损失项。 Patel [37] 研究了抽象和提取内容纲要策略。 Kejun[22]提出了一种改进的词向量生成技术和抽象自动摘要模型。 Minaee [31] 讨论了 150 多种基于深度学习的文本分类模型。
本文提出了自动文本摘要优化方法。首先,通过部署 seq2seq 模型生成初始摘要和强化学习所需的候选动作空间。动作候选空间分为两部分。一部分是由 seq2seq 模型的解码器生成的。这个过程可以看作是一种抽象概括的方法。另一部分是由seq2seq模型的注意力机制生成的,可以看作是一种抽取式摘要方法。其次,使用DQN[32]来学习一种策略,直接优化初始摘要以获得最大奖励(ROUGE分数)
三.本文方法
四 实验效果
4.1数据集
4.2 对比模型
4.3实施细节
4.4评估指标
4.5 实验结果
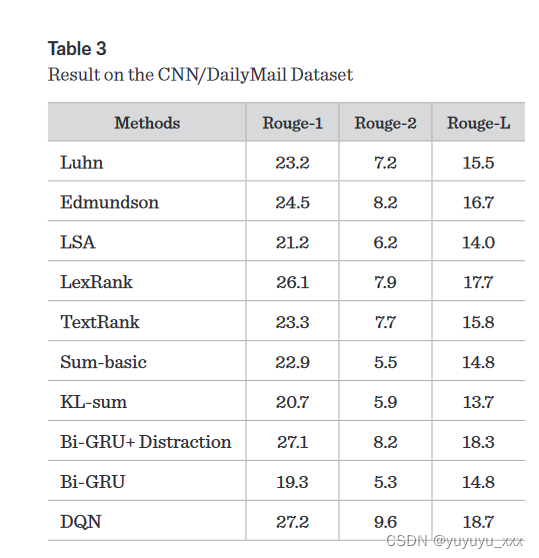
4.6 细粒度分析
五 总结
本文提出一种基于深度增强学习的强化文本摘要优化方法。使用基于注意力机制的seq2seq模型生成强化学习所需的初始摘要和动作候选空间,然后使用深度Q网络在动作候选空间上优化初始摘要。实验结果表明,优化后的方法效果明显提高。由于基础模型生成的结果限制了我们优化方法的最终性能,因此在未来的工作中,我们考虑直接应用强化学习来优化基础模型的参数以获得更好的结果。