之前我们介绍了LlamaIndex的从小到大的检索 的检索方法,今天我们再来介绍llamaindex的另外一种高级检索方法: 句子-窗口检索(Sentence Window Retrieval),在开始介绍之前让我们先回顾一下基本的RAG检索的流程,如下图所示:
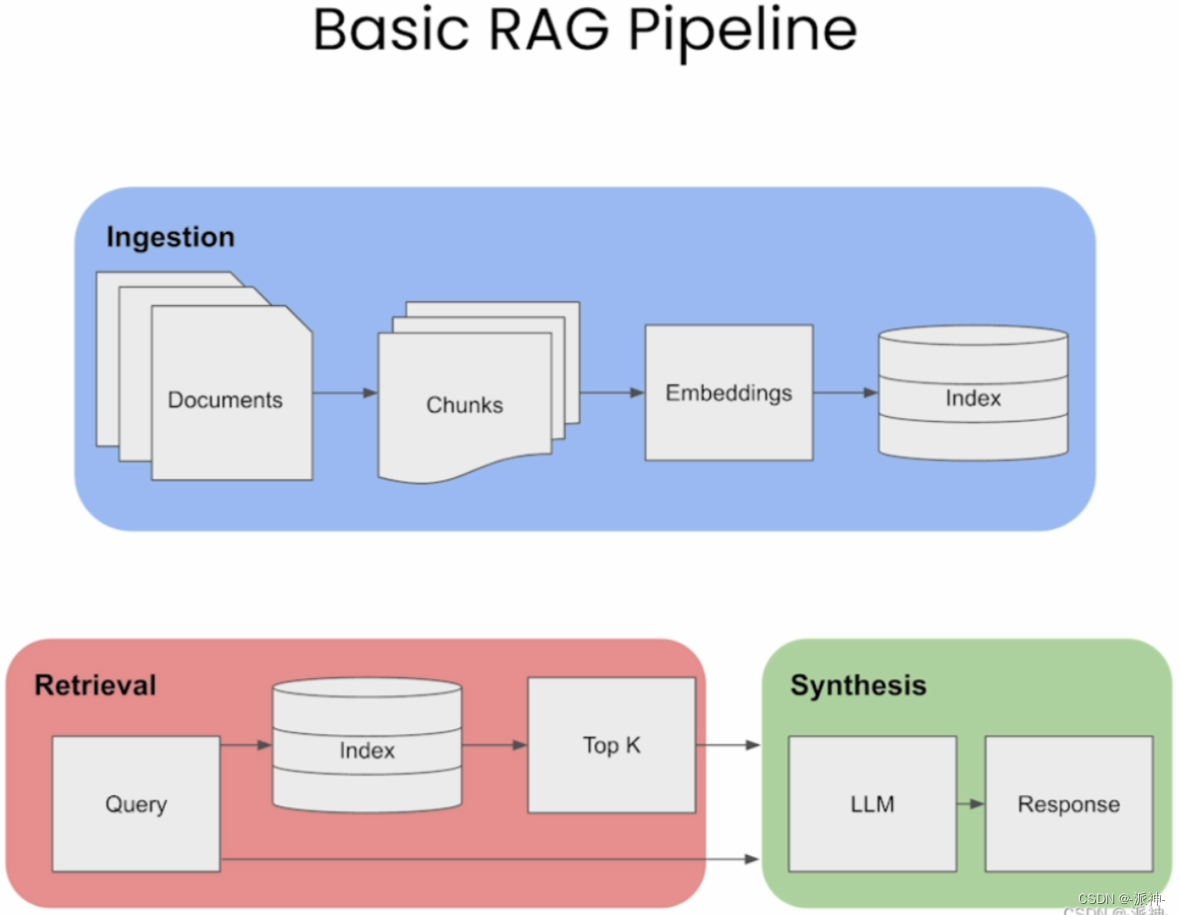
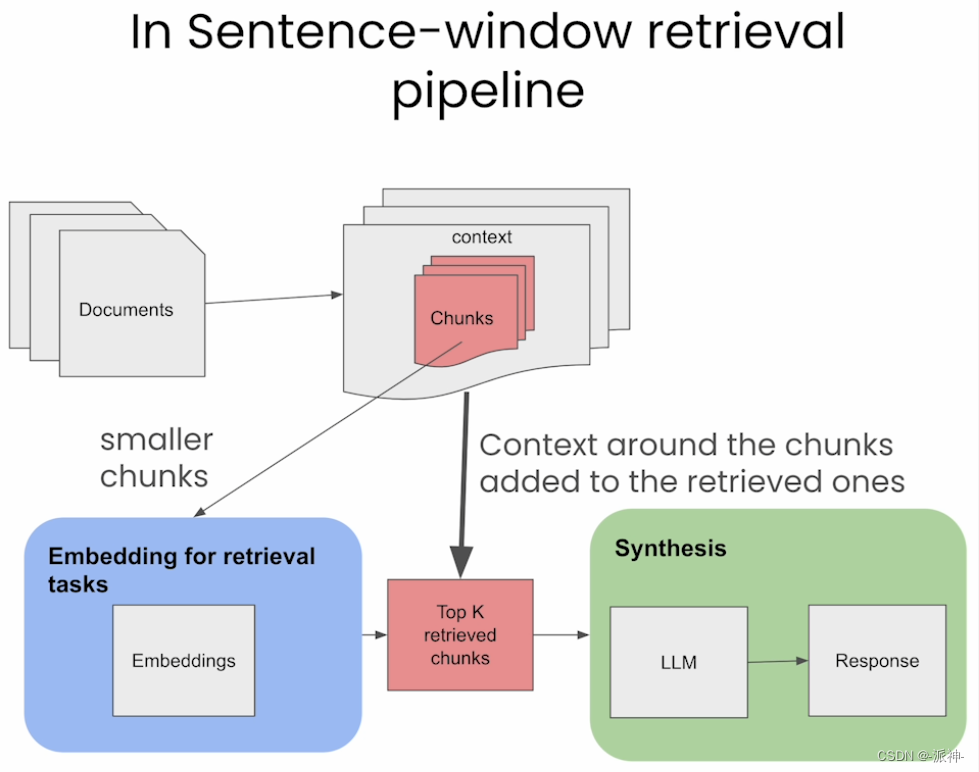
在执行基本RAG检索时我们会将文档按指定的块大小(chunk_size)进行切割,然后进行embedding的向量化处理后存入向量数据库中,在检索时我们会计算用户问题(question) 与文档块的相似度,并选取K个最相似的文档(context),并将其和用户问题一起发送给LLM, 并最终由LLM来生成最终的回复(response)。那么context的质量将直接影响到response的质量,然而context的质量往往取决于文档块的大小即chunk_size, 当chunk_size较小时它与question的匹配度越高,但此时context的信息量就会相对较少,这样也会导致最终的response质量变差,而当chunk_size较大时虽然context的信息量较大,但是context与question的匹配度就会降低,这也会导致最终的response质量变差,这就是基本RAG架构的弊端所在,不过之前我们已经介绍过的langchain的父文档检索器和LlamaIndex的从小到大的检索这两篇博客就是针对基本RAG架构的弊端的两种解决方法,接下来我们来介绍一种在LlamaIndex中更为强大的高级RAG方法:句子-窗口检索, 该方法的主要思想是首先将文档切割成更小的文档块, 当匹配到问题后,将该文档块周围的文档内容作为context输出,如下图所示:
一、环境配置
在介绍句子-窗口检索方法前我们首先需要对环境进行配置,我们需要安装如下python包:
pip install llama_hub
pip install llama_index
pip install trulens-eval
pip install trafilatura
pip install torch sentence-transformers接下来我们需要做一些初始化的工作,比如导入openai或者gemini等大模型的api_key:
import os
from dotenv import load_dotenv, find_dotenv
#导入.env配置文件
_ = load_dotenv(find_dotenv()) 下面我们需要导入在后续实验中所需要使用到的所有python包:
import os
from llama_index.readers.web import TrafilaturaWebReader
from llama_index import Document
from llama_index import VectorStoreIndex, StorageContext, load_index_from_storage
from llama_index import load_index_from_storage
from llama_index.readers.web import TrafilaturaWebReader
from llama_index.text_splitter import SentenceSplitter
from llama_index import VectorStoreIndex, ServiceContext
from llama_index.embeddings import resolve_embed_model
from llama_index.node_parser import SentenceWindowNodeParser
from llama_index.indices.postprocessor import MetadataReplacementPostProcessor
from llama_index.indices.postprocessor import SentenceTransformerRerank
from llama_index.llms import OpenAI
from llama_index.llms import Gemini二、加载数据
这里我们仍然使用前几篇博客中使用的数据即从百度百科的网页中抓取一篇关于恐龙的文章:
url="https://baike.baidu.com/item/恐龙/139019"
docs = TrafilaturaWebReader().load_data([url])
#将全角标点符号转换成半角标点符号+空格
for d in docs:
d.text=d.text.replace('。','. ')
d.text=d.text.replace('!','! ')
d.text=d.text.replace('?','? ')
#查看文档集
docs
这里我们采样LlamaIndex提供的网页爬虫工具TrafilaturaWebReader来爬取百度百科上的这篇文章,然后我们会将文章中全角标点符号如句号、感叹号、问号全部转换成半角标点符号+空格,至于为什么要将全角的标点符号替换成半角标点符号,我们后续会进行说明。
三、句子-窗口检索(Sentence Window Retrieval)
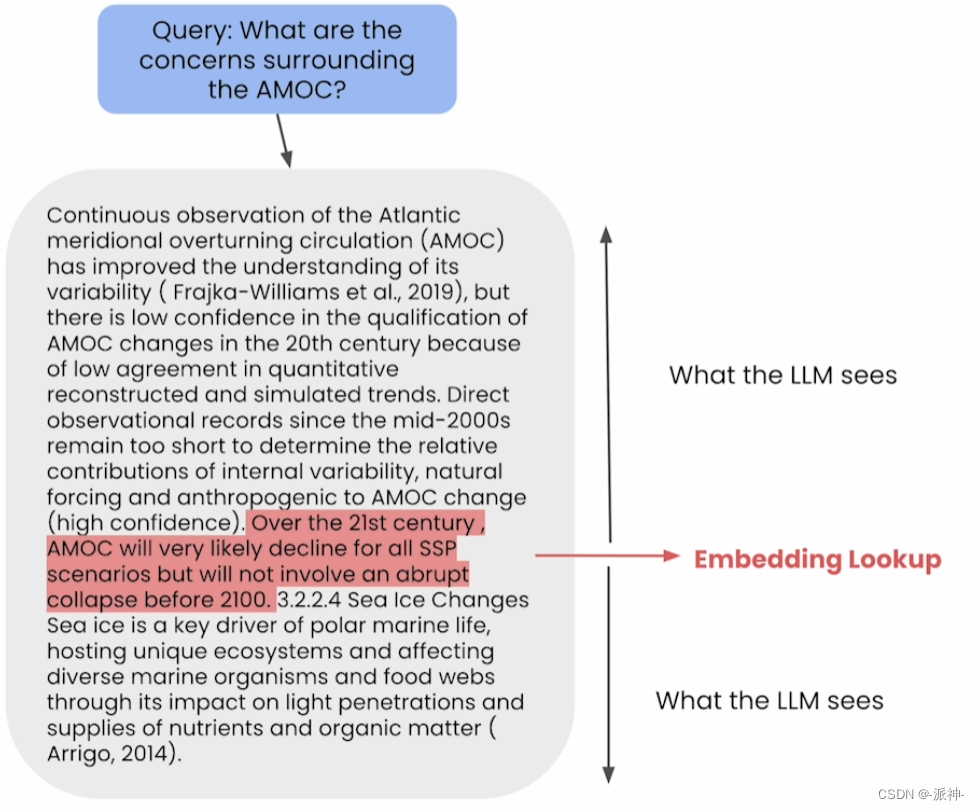
句子-窗口检索主要思想是将文档按句子来切割即每个句子成为一个文档,在检索时候将问题和所有的句子向量进行匹配,当匹配到较高相似度的句子后,将该句子周围(前,后)的若干条句子作为context,当前句子的前后句子数量由参数window_size来确定,如下图所示:
1.1 句子的识别
在之前介绍的基本RAG架构,还有langchain的父文档检索器,以及LlamaIndex的从小到大的检索中我们都是按指定的块大小(chunk_size)来对文档进行切割的,然而“句子-窗口检索”方法中我们将不再按chunk_size来切割文档,而是按完整的句子来切割文档即每一个句子切割成一个文档,然而如何识别出文本中的句子呢?在LlamaIndx中采样的是通过句尾的标点符号如句号(.), 问号(?), 感叹号(!)等来识别句子,下面我们来创建一个句子解析器并尝试让它将按句子来切割文档:
from llama_index.node_parser import SentenceWindowNodeParser
#定义句子解析器
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
node_parser
这里我们定义了一个句子解析器node_parser,它包含了一个关键的参数window_size,该参数表示context的大小即当前句子及其周围包含多少条其他句子,比如当window_size=3时,那么context将由当前句子之前的3条句子,当前句子,当前句子之后的2条句子一共6条句子组成的窗口(window)数据来表示。而window_metadata_key和original_text_metadata_key为我们自定义的在元数据中表示窗口数据和当前句子的关键字(key),我们来看下面的例子:
from llama_index import Document
text = "hello. how are you? I am fine! aaa;ee. bb,cc"
nodes = node_parser.get_nodes_from_documents([Document(text=text)])
print([x.text for x in nodes])![]()
这里我们看到英文字符串 "hello. how are you? I am fine! aaa;ee. bb,cc" 被拆分成了5个句子,这是因为SentenceWindowNodeParser是根据句尾的标点符号如句号(.), 问候(?),感叹号(?)来识别和切割句子的,下面我们来看看节点中的"窗口"数据:
nodes[0].metadata
这里我们需要说明一下的是当文档被切割以后,窗口数据和文档数据都会被存储在节点的元数据中并以自定义的window_metadata_key和original_text_metadata_key来表示。这里由于我们查看的是节点的第一个文档的元数据,那么第一个文档也就是原始文档的第一个句子,因此窗口数据中只包含了当前句子和后续两条句子共3个句子,下面我们查看最后一个文档的元数据:
nodes[4].metadata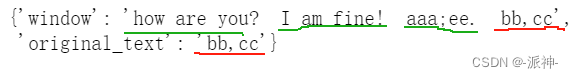
这里我们查看了节点的最后一共文档,因为是最后一共文档因此它的窗口数据中只包含了当前句子的前三条句子和当前句子一共4个句子。
1.2 如何识别中文文档中的句子
经过我的测试,我发现LlamaIndex中的SentenceWindowNodeParser似乎只能识别半角的标点符号,而在中文文档中几乎都是使用全角的标点符号,而SentenceWindowNodeParser却无法识别全角的标点符号如全角的句号(。),全角的问号(?),全角的感叹号(!) 这将会导致SentenceWindowNodeParser无法切割中文的文档,为了解决这个问题,经过我的一番研究,我发现如果将中文文档中的全角句号、问号、感叹号全部替换成对应的半角标点符号并且在半角标点符号后面再多加一共空格,这样就可以让SentenceWindowNodeParser来切割中文文档中的句子了。下面我们来测试一下让SentenceWindowNodeParser切割带有全角的标点符号的中文文档会怎么样:
#带有全角标点符号的中文文本
text = "你好,很高兴认识你。 已经10点了,可我还不想起床!下雪啦!你的作业完成了吗?"
nodes = node_parser.get_nodes_from_documents([Document(text=text)])
print([x.text for x in nodes]) ![]()
这里我们看到这个中文的字符串没有被切割,它仍然作为一个整体被输出, 下面我们将文本中的句号,问号,感叹号全部替换成半角的标点符号并且再多加一共空格:
#带有半角标点符号的中文文本
text = "你好,很高兴认识你. 已经10点了,可我还不想起床! 下雪啦! 你的作业完成了吗?"
nodes = node_parser.get_nodes_from_documents([Document(text=text)])
print([x.text for x in nodes])
这里我们看到文本中的全角的句号,问号,感叹号被替换成半角以后整个文本就被切割成了4个文档。 下面我们来看看节点中的"窗口"数据:
nodes[0].metadata
这里我们看到节点的第一个文档也就是文档中的第一个句子,在第一个文档的窗口(window)数据中包含了第一个句子以及后续的两个句子。而在“original_text”中存储着第一个文档即原始文档的第一个句子。接下来我们测试一下对之前我们获取的百度百科的文章进行切割:
sentence_nodes = node_parser.get_nodes_from_documents(docs)
len(sentence_nodes)
这里我们看到原始文档被切割成了334个文档,下面我们再来查看一下其中某个文档的内容:
sentence_nodes[100].metadata
这里我们用黄色标记出了当前文档的句子,我们看到窗口数据(window)中一共包含了6个句子即当前句子之前的3个句子,以及当前句子和之后的两个句子合计6个句子。
1.3 创建向量数据库(index)
接下来我们开始创建句子-创建检索任务所需要组件如LLM、ServiceContext等,因为我们需要检索的是中文文档,因此我们选择的embedding模型是开源的bge-small-zh-v1.5模型,llm选择的是openai的gpt-3.5-turbo模型,当然你也可以选择gemini模型:
#创建OpenAI的llm
llm = OpenAI(model="gpt-3.5-turbo",
api_key='your-opai-api-key',
temperature=0.1)
#创建谷歌gemini的llm
# llm = Gemini()
#创建ServiceContext组件
sentence_context = ServiceContext.from_defaults(
llm=llm,
embed_model="local:BAAI/bge-small-zh-v1.5",
node_parser=node_parser,
)
#创建向量数据库
document = Document(text="\n\n".join([doc.text for doc in docs]))
sentence_index = VectorStoreIndex.from_documents(
[document],
service_context=sentence_context
)这里我们创建了向量数据库sentence_index ,我们可以将这个向量数据库持久化保存在本地,在需要的时候我们可以直接从本地读取向量数据库,从而可以省去重新获取数据和创建llm和ServiceContext等组件的步骤了:
#将向量数据库保存在本地
sentence_index.storage_context.persist(persist_dir="./sentence_index")
#从本地读取向量数据库
if not os.path.exists("./sentence_index"):
sentence_index = VectorStoreIndex.from_documents(
[document], service_context=sentence_context
)
sentence_index.storage_context.persist(persist_dir="./sentence_index")
else:
sentence_index = load_index_from_storage(
StorageContext.from_defaults(persist_dir="./sentence_index"),
service_context=sentence_context
)1.4 创建postprocessor组件
要实现最终的检索我们还需要创建query engine组件,但是在query engine组件中需要设置一个postprocessor组件作为其参数,而postprocessor组件可以由若干个子组件组合在一起,下面我们首先来简单介绍一下postprocessor子组件:Replacement组件,该组件的作用是用来选择(由target_metadata_key参数确定)将哪些context发送给llm, 也就是说Replacement组件会从检索到的context中挑选指定的内容发送给llm,所以它具有选择context的功能.
另外postprocessor还有一个叫rerank的子组件,它的作用是对检索到的上下文进行从新排序,从而得到一个精度更高的检索结果,最后Replacement组件会将rerank组件的排序结果发送给llm, 不过这里需要说明一下的是rerank是可选组件,它不是必须的,rerank组件的作用仅仅是为了提高检索的精度。
#创建Replacement组件
postproc = MetadataReplacementPostProcessor(
target_metadata_key="window"
)
#创建rerank组件
# 参考: https://huggingface.co/BAAI/bge-reranker-base
rerank = SentenceTransformerRerank(
top_n=2,
model="BAAI/bge-reranker-base"
)这里创建的Replacement组件中我们设置了target_metadata_key参数为"window", 它的作用是当执行检索操作时会将context中的元数据的“窗口”数据发送给llm。而rerank组件中的top_n=2的作用是对检索到的多个context进行重新排序并选取精度最高前2个context。这里所谓的精度是指相似度计算的精度,因为我们选择embedding模型和rerank模型的都是bge的模型 ,因此它们配合再一起计算出来的相似度精度要比用传统的用向量内积(如np.dot())方式计算出来的相似度要高一些,所以可以认为经过rerank模型的重新排序后会得到和question相关度更高的context。
1.5 创建query engine组件
接下来我们通过将上面创建的组件结合在一起来创建query engine组件:
#创建查询引擎
sentence_window_engine = sentence_index.as_query_engine(
similarity_top_k=6,
node_postprocessors=[postproc, rerank]
)这里我们设置了similarity_top_k=6这表示说每次检索将返回相似度最高的6个文档, 而我们的rerank组件会对这6个文档进行重新排序后选取2个相似度最高的文档,最后Replacement组件会将这2个相似度最高的文档中的“窗口”数据发送给llm。下面我们来测试一下这个query engine:
window_response = sentence_window_engine.query(
"恐龙是冷血动物吗?"
)
print(window_response)
下面我们来看一下针对 "恐龙是冷血动物吗?"这个问题所检索出来的窗口数据及其句子:
window = window_response.source_nodes[0].node.metadata["window"]
sentence = window_response.source_nodes[0].node.metadata["original_text"]
print("------------------")
print(f"Window: {window}")
print("------------------")
print(f"Original Sentence: {sentence}")
这里我们用黄色标记出检索到的句子,从检索结果中我们看到了窗口数据和检索到的句子。因为经过rerank模型重新排序后最后只剩下两个相似度最高的context,下面我们再看一下第二个context中的内容:
window = window_response.source_nodes[1].node.metadata["window"]
sentence = window_response.source_nodes[1].node.metadata["original_text"]
print("------------------")
print(f"Window: {window}")
print("------------------")
print(f"Original Sentence: {sentence}")
这里我们观察到在第二个检索到的窗口数据中包含了“简言之,它们的生理机能在现代社会并不常见.” 这句话,但是这句话没有出现在第一个文档中,最后这句话也出现在了llm的返回结果中,这说明LLM对这两个context的窗口数据进行了总结和归纳,它从这两个窗口数据中分别提取了和question最相关的内容,然后再将它们组织在一起形成最终的response。下面我们再测试一个问题:"恐龙灭绝原因是什么?"
window_response = sentence_window_engine.query(
"恐龙灭绝原因是什么?"
)
print(window_response)
下面我们来看一下针对 "恐龙灭绝原因是什么?"这个问题所检索出来的第一个文档的窗口数据及其句子:
window = window_response.source_nodes[0].node.metadata["window"]
sentence = window_response.source_nodes[0].node.metadata["original_text"]
print("------------------")
print(f"Window: {window}")
print("------------------")
print(f"Original Sentence: {sentence}")
下面我们查看一下检索出来的第二个文档的窗口数据及其句子:
window = window_response.source_nodes[1].node.metadata["window"]
sentence = window_response.source_nodes[1].node.metadata["original_text"]
print("------------------")
print(f"Window: {window}")
print("------------------")
print(f"Original Sentence: {sentence}")
这里很明显我们可以看到LLM给出的response是总结了两个context的窗口数据内容后得到的。
四、评估
未完待续....