文章目录
- 一:torchvision概述
- 二:torchvision.datasets
- (1)官方数据集
- (2)自定义数据集类
- (3)ImageFolder手动实现
- 三:torchvision.transforms
- 四:torchvision.models
一:torchvision概述
torchvision:torchvision是Pytorch的一个图形库,主要用来构建计算机视觉模型,torchvision由以下四个部分构成
torchvision.datasets:包括一些加载数据的函数和常用的数据集接口torchvision.models:包含常用的模型结构(含预训练模型),例如AlexNet、ResNet等等torchvision.transforms:包含一些常见的图片变换,例如裁剪、旋转等等torchvision.utils:其他用法
二:torchvision.datasets
torchvision.datasets:该模块下既有官方提供的数据集,也有自定义数据集的类,两者都是torch.utils.data.Dataset的子类,因此可以直接输入到torch.utils.data.DataLoader中去
(1)官方数据集
torchvision.datasets中提供的官方数据如下,这些数据集详细介绍见此文:数据集介绍
MNIST
Fashion-MNIST
KMNIST
EMNIST
FakeData
COCO
Captions
Detection
LSUN
ImageFolder
DatasetFolder
Imagenet-12
CIFAR
STL10
SVHN
PhotoTour
SBU
Flickr
VOC
Cityscapes
...
这里我们以MNIST数据集为例,演示一下这些官方数据集如何加载,其余数据集的加载和MNIST一致
如下,使用torchvision.datasets.MNIST加载MNIST数据集
train_data = dataset.MNIST(root='./mnist/',
train=True,
transform=transforms.ToTensor(),
download=True)
test_data = dataset.MNIST(root='./mnist/',
train=False,
transform=transforms.ToTensor(),
download=False)
root:表示数据集待存放的目录train:如果为true将会使用训练集的数据集(training.pt),如果为false将会使用测试集数据集(test.pt)download:如果为true将会从网络上下载并放入root中,如果数据集已下载则不会再次下载transform:接受PIL图片并返回转换后的图片,常用的就是转换为tensor(这里便会调用torchvision.transform)
数据集加载成功后,文件布局如下
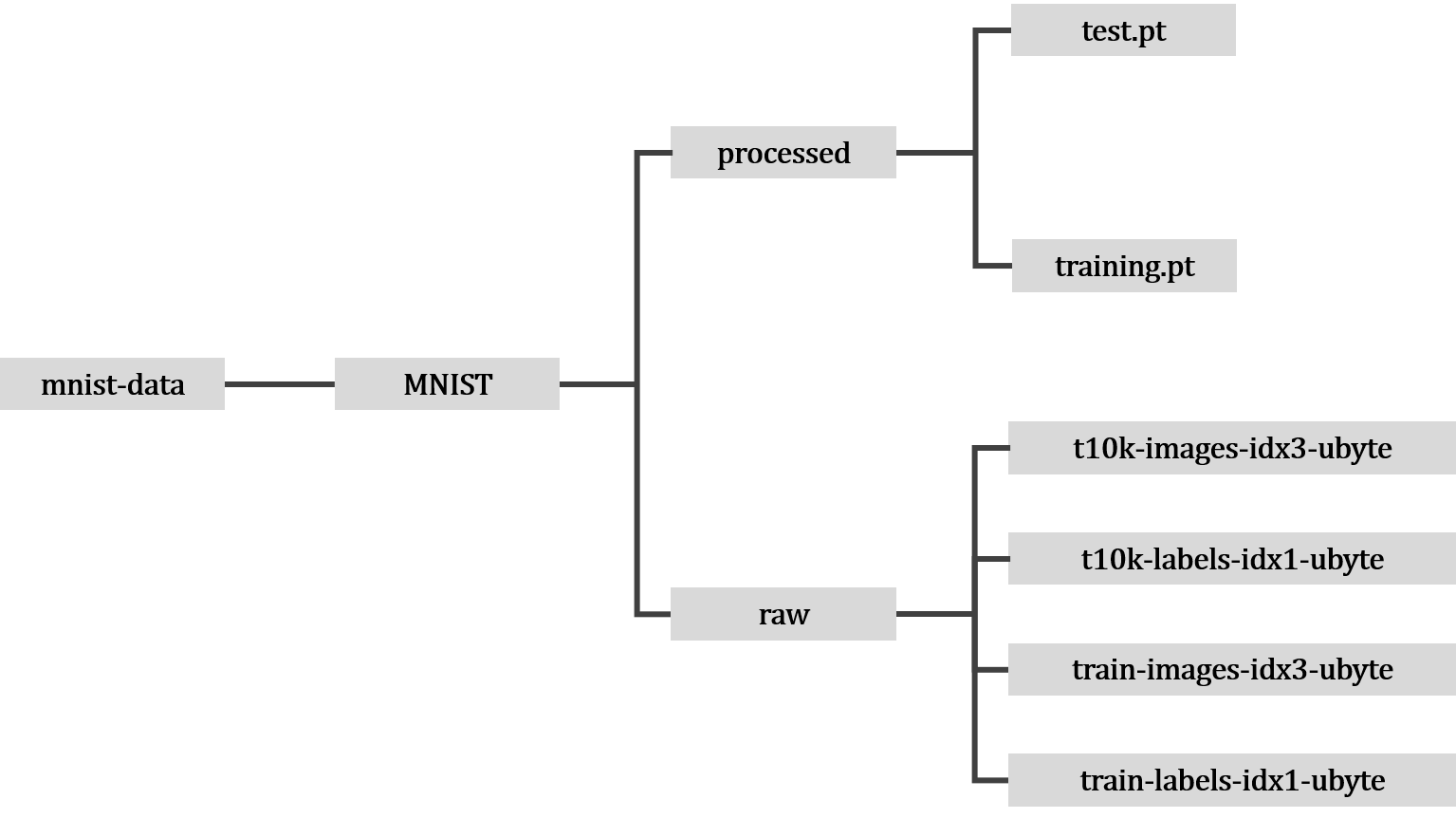
(2)自定义数据集类
这里的自定义数据集类指的主要是torchvision.datasets.ImageFolder(),它继承自 torchvision.datasets.DatasetFolder(),后者又继承自 torchvision.datasets.VisionDataset(),而VisionDataset 则是 torch.utils.data.Dataset 的子类
以torchvision.datasets.CIFAR数据集为例说明如何使用torchvision.datasets.ImageFolder(),这里的torchvision.datasets.CIFAR我已经将其转换为png格式存储
- 下载链接
- CIFAR10有60000张图片,共分为10个类别,其中50000张为训练图片(每个类别5000张),10000张为测试图片(每个类别1000张)
图片文件布局如下,torchvision.datasets.ImageFolder()要求你的图片数据必须按照以下方式进行组织
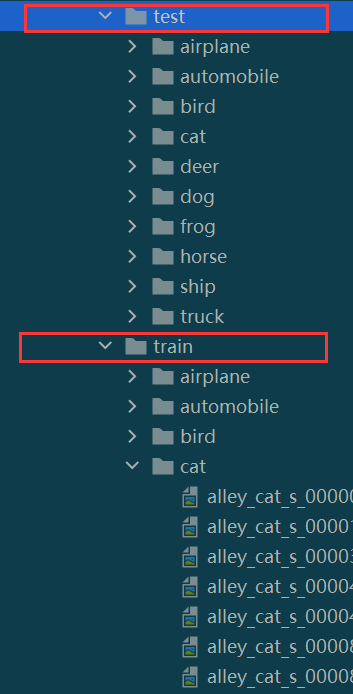
torchvision.datasets.ImageFoler参数说明
root:图片存储的根目录,即各类别文件夹所在目录的上一级目录transform:对图片进行预处理的操作(函数),原始图片作为输入,返回一个转换后的图片target_transform:对图片类别进行预处理的操作,输入为target,输出对其的转换。如果不传该参数,即对target不做任何转换,返回的顺序索引 0,1, 2…loader:表示数据集加载方式,通常默认加载方式即可
torchvision.datasets.ImageFolder(root,transform,target_transform,loader)
如下,使用torchvision.datasets.ImageFoler对前面的图片进行加载
- 注意:
transforms部分可暂时忽略
train_transforms = transforms.Compose([
transforms.RandomResizedCrop((28, 28)),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomRotation(90),
transforms.RandomGrayscale(0.1),
transforms.ColorJitter(0.3, 0.3, 0.3, 0.3),
transforms.ToTensor()
])
train_dataset = torchvision.datasets.ImageFolder(root='./data/train', transform=train_transforms)
test_dataset = torchvision.datasets.ImageFolder(root='./data/test', transform=transforms.ToTensor)
print(len(train_dataset))
print(len(test_dataset))

同时,通过torchvision.datasets.ImageFolder生成的train_dataset和test_dataset还有如下3个成员变量
self.classes:使用一个list保存类别名称self.class_to_idx:类别对应的索引self.imgs:是一个list,每个元素是一个tuple,每个tuple保存的是(img-path, class)
print(train_dataset.classes[: 5])
print("-"*30)
print(train_dataset.class_to_idx)
print("-"*30)
print(train_dataset.imgs[: 5])

(3)ImageFolder手动实现
仍然以上述CIFAR10数据集为例,我们手动实现一下ImageFolder,这对你理解它大有帮助
import torchvision.datasets
from torchvision import transforms
from torch.utils.data import DataLoader, Dataset
import os
from PIL import Image
import numpy as np
import glob
# 类别名字
label_name = [
"airplane",
"automobile",
"bird",
"cat",
"deer",
"dog",
"frog",
"horse",
"ship",
"truck"
]
# 类比名字映射索引
label_dict = {}
for idx, name in enumerate(label_name):
label_dict[name] = idx
def default_loader(path):
return Image.open(path).convert("RGB")
train_transforms = transforms.Compose([
transforms.RandomResizedCrop((28, 28)),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomRotation(90),
transforms.RandomGrayscale(0.1),
transforms.ColorJitter(0.3, 0.3, 0.3, 0.3),
transforms.ToTensor()
])
class MyDataset(Dataset):
"""
im_list:是一个列表,每一个元素是图片路径
transform:对图片进行增强
loader:使用PIL对图片进行加载
"""
def __init__(self, im_list, transform=None, loader=default_loader):
super(MyDataset, self).__init__()
# imgs为二维列表,每一个子列表中第一个元素存储im_list,第二个通过label_dict映射为索引
imgs = []
for im_item in im_list:
# 路径'./data/test/airplane/aeroplane_s_000002.png'中倒数第二个是标签名
im_label_name = im_item.split("\\")[-2]
imgs.append([im_item, label_dict[im_label_name]])
self.imgs = imgs
self.transform = transform
self.loader = loader
def __getitem__(self, index):
im__path, im_label = self.imgs[index]
# 会调用PIL加载图片数据
im_data = self.loader(im__path)
# 如果给了transoform那么就对图片进行增强
if self.transform is not None:
im_data = self.transform(im_data)
return im_data, im_label
def __len__(self):
return len(self.imgs)
if __name__ == '__main__':
im_train_list = glob.glob(r'./data/train/*/*.png')
im_test_list = glob.glob(r'./data/test/*/*.png')
train_dataset = MyDataset(im_train_list, transform=train_transforms)
test_dataset = MyDataset(im_test_list, transform=transforms.ToTensor())
print(len(train_dataset))
print(len(test_dataset))
train_loader = DataLoader(dataset=train_dataset, batch_size=6, shuffle=True, num_workers=0)
test_loader = DataLoader(dataset=test_dataset, batch_size=6, shuffle=False, num_workers=0)

三:torchvision.transforms
torchvision.transforms:该模块是Pytorch中的图像预处理包,包含了一些常用的图像变换,主要实现对数据集的预处理、数据增强,转化为tensor等操作
使用时如果有很多变换,那么一般会使用Compose将这些步骤给整合到一起
train_transforms = transforms.Compose([
transforms.RandomResizedCrop((28, 28)),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomRotation(90),
transforms.RandomGrayscale(0.1),
transforms.ColorJitter(0.3, 0.3, 0.3, 0.3),
transforms.ToTensor()
])
train_dataset = torchvision.datasets.ImageFolder(root='./data/train', transform=train_transforms
如果变换时只有一种,那么一般会直接给到形参,比如最常使用到的ToTensor
test_dataset = torchvision.datasets.ImageFolder(root='./data/test', transform=transforms.ToTensor)
torchvision.transforms涉及变换主要有以下4类
-
裁剪:
- 中心裁剪:
transforms.CenterCrop - 随机裁剪:
transforms.RandomCrop - 随机长宽比裁剪:
transforms.RandomResizedCrop - 上下左右中心裁剪:
transforms.FiveCrop - 上下左右中心裁剪后翻转:
transforms.TenCrop
- 中心裁剪:
-
翻转和旋转
- 依概率p水平翻转:
transforms.RandomHorizontalFlip(p=0.5) - 依概率p垂直翻转:
transforms.RandomVerticalFlip(p=0.5) - 随机旋转:
transforms.RandomRotation
- 依概率p水平翻转:
-
图像变换和转换
- 变换为某一尺寸:
transforms.Resize - 标准化:
transforms.Normalize - 转化为
tensor并归一化:transforms.ToTensor - 填充:
transforms.Pad - 修改亮度、对比度和饱和度:
transforms.ColorJitter - 转化为灰度图:
transforms.Grayscale - 线性变化:
transforms.LinearTransformation - 仿射变换:
transforms.RandomAffine - 依概率p转化为灰度图:
transforms.RandomGrayscale - 将数据转化为PILImage:
transforms.ToPILImage
- 变换为某一尺寸:
-
其他操作
- 对
transforms操作使数据增强更灵活:transforms.RandomChoice(transforms) - 从给定的一系列
transforms中选定一个操作:transforms.RandomApply(transforms, p=0.5) - 给一个
transform加上概率进行操作:transforms.RandomOrder
- 对
四:torchvision.models
torchvision.models:该模块提供了很多图像处理中的常用模型,并且提供了与训练版本,主要有
- AlexNet: AlexNet variant from the “One weird trick” paper.
- VGG: VGG-11, VGG-13, VGG-16, VGG-19 (with and without batch normalization)
- ResNet: ResNet-18, ResNet-34, ResNet-50, ResNet-101, ResNet-152
- SqueezeNet: SqueezeNet 1.0, and SqueezeNet 1.1









![洛谷千题详解 | P1030 [NOIP2001 普及组] 求先序排列【C/C++、pascal语言】](https://img-blog.csdnimg.cn/c2f8a8b7cc364a59bcc1d6c0bdf676ea.png)