背景
这是张小帅失业之后的第三场面试。
面试官:“实际开发中用过多线程吧,那聊聊线程池吧”。
“有CachedThreadPool:可缓存线程池,FixedThreadPool:定长线程池.......balabala”。小帅暗暗窃喜,还好把这几种线程池背下来了,看来这次可以上岸了。
面试官点点头,继续问到“那线程池底层是如何实现复用的?”
“额,这个....”
寒风中,那个男人的背影在暮色中显得孤寂而凄凉,仿佛与世隔绝,独自面对着无尽的寂寞......
概要
如果问到线程池的话,不好好剖析过底层代码,恐怕真的会像小帅那样被问翻吧。
那么在此我们就来好好剖析一下线程池的底层吧。我们大概从如下几个方面着手:
什么是线程池
说到线程池,其实我们要先聊到池化技术。
池化技术:我们将资源或者任务放入池子,使用时从池中取,用完之后交给池子管理。通过优化资源分配的效率,达到性能的调优。
池化技术优点:
-
资源被重复使用,减少了资源在分配销毁过程中的系统的调度消耗。比如,在IO密集型的服务器上,并发处理过程中的子线程或子进程的创建和销毁过程,带来的系统开销将是难以接受的。所以在业务实现上,通常把一些资源预先分配好,如线程池,数据库连接池,Redis连接池,HTTP连接池等,来减少系统消耗,提升系统性能。
-
池化技术分配资源,会集中分配,这样有效避免了碎片化的问题。
-
可以对资源的整体使用做限制,相关资源预分配且只在预分配是生成,后续不再动态添加,从而限制了整个系统对资源的使用上限。
所以我们说线程池是提升线程可重复利用率、可控性的池化技术的一种。
线程池的使用
多线程发送邮件案例
现在我们有这样一个场景,上层有业务系统批量调用底层进行发送邮件,废话不多,直接上代码:
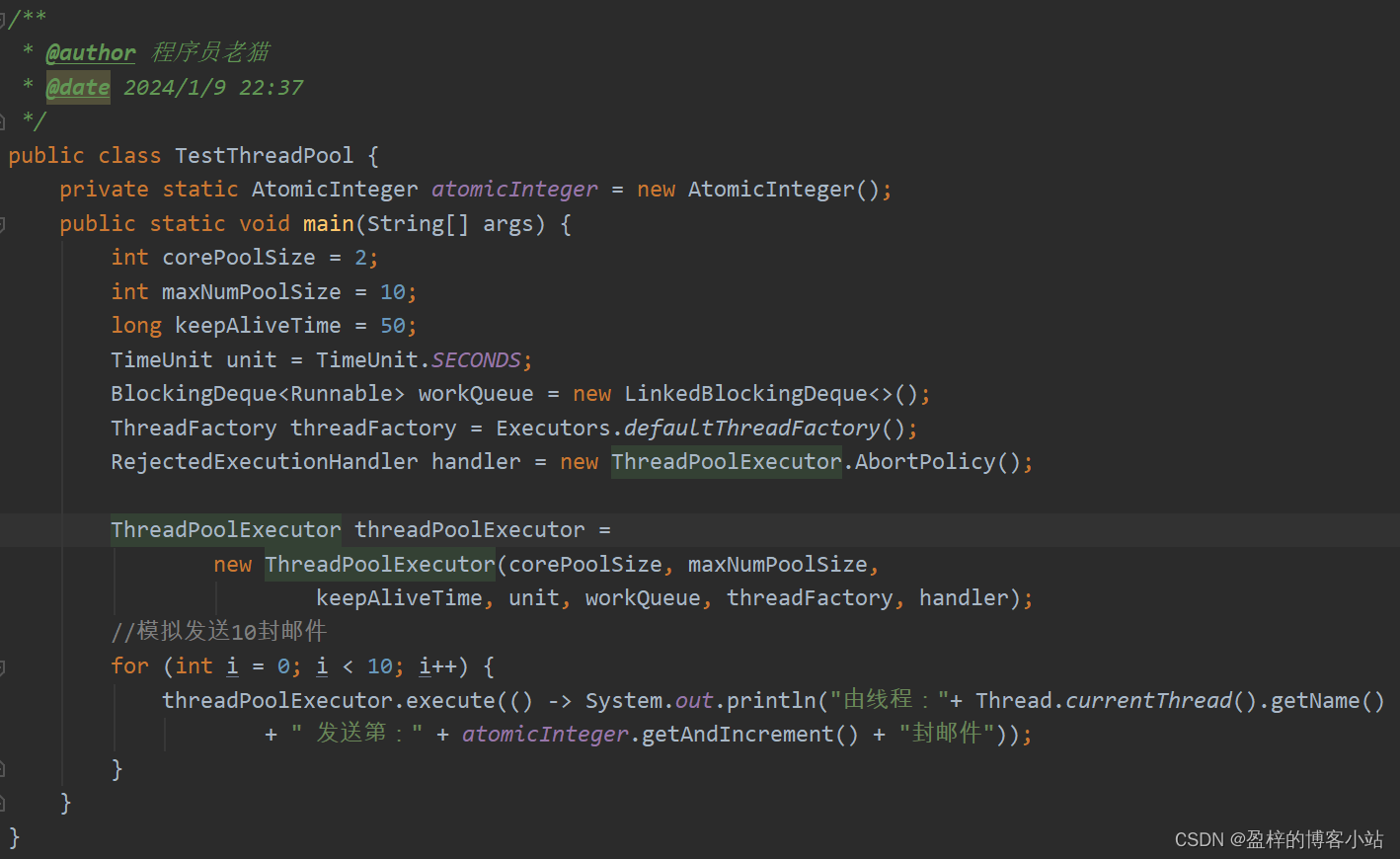
最终运行输出结果为:
由线程:pool-1-thread-1 发送第:0封邮件 | |
由线程:pool-1-thread-2 发送第:1封邮件 | |
由线程:pool-1-thread-1 发送第:2封邮件 | |
由线程:pool-1-thread-2 发送第:3封邮件 | |
由线程:pool-1-thread-1 发送第:4封邮件 | |
由线程:pool-1-thread-1 发送第:6封邮件 | |
由线程:pool-1-thread-2 发送第:5封邮件 | |
由线程:pool-1-thread-1 发送第:7封邮件 | |
由线程:pool-1-thread-2 发送第:8封邮件 | |
由线程:pool-1-thread-1 发送第:9封邮件 |
上面的例子中从结果来看是10封邮件分别由两条线程发送出去了,上图可见,我们给ThreadPoolExecutor这个执行器分别指定了七个参数。那么参数的含义到底是什么呢?接下来咱们层层抽丝剥茧。
构造函数说明
大家估计会有疑问,线程池的种类那么多,案例中为什么要用TheadPoolExecutor类呢,其他的种类是由TheadPoolExecutor通过不同的入参定义出来的,所以我们直接拿ThreadPoolExecutor来看。
我们先来看一下ThreadPoolExecutor的继承关系,有个宏观印象: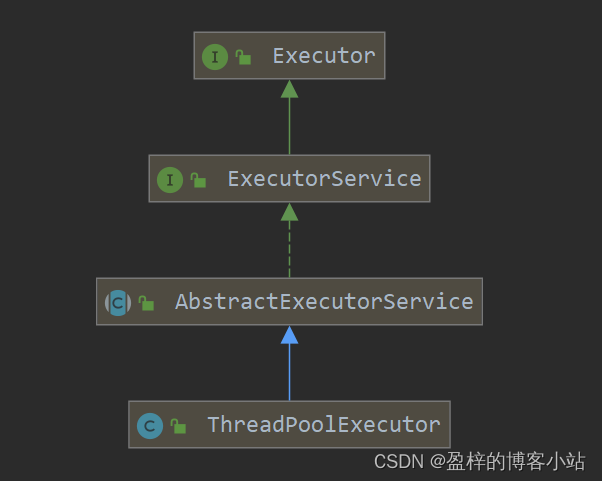
我们再来看一下ThreadPoolExecutor的构造方法: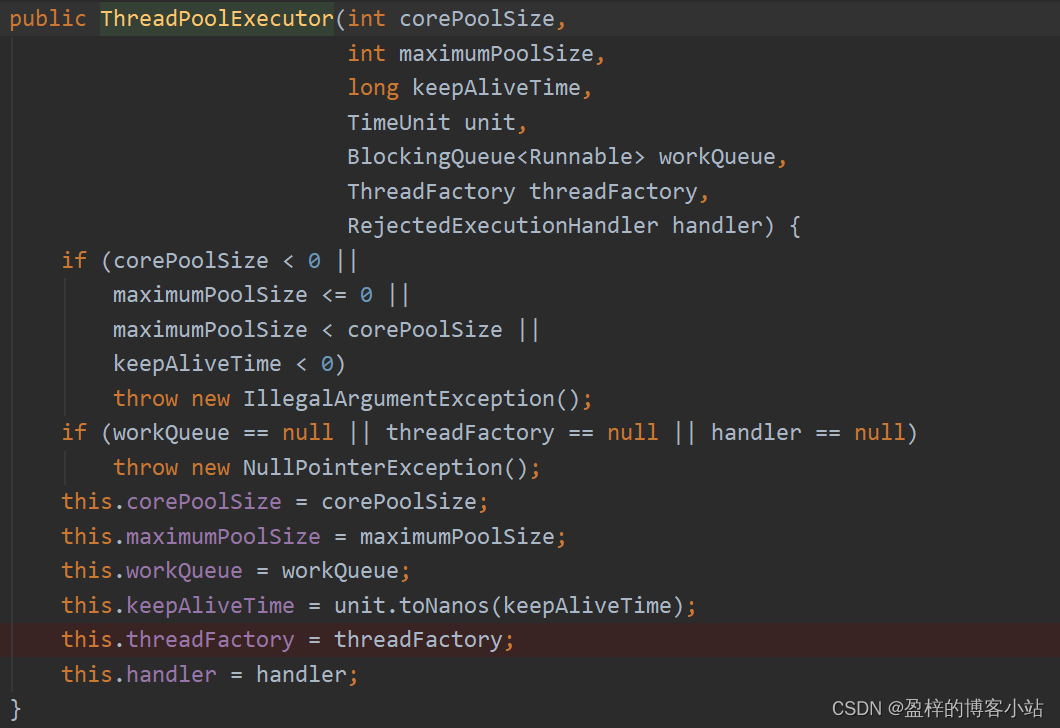
下面我们来解释一下几个参数的含义:
-
corePoolSize: 核心线程数。
-
maximumPoolSize: 最大线程数。
-
keepAliveTime: 线程池中线程的最大闲置生命周期。
-
unit: 针对keepAliveTime的时间单位。
-
workQueue: 阻塞队列。
-
threadFactory: 创建线程的线程工厂。
-
handler: 拒绝策略。
大家对上述的含义初步有个概念。
工作流程概述
看了上面的构造函数字段大家估计也还是优点懵的,尤其是从来没有接触过商品池的小伙伴。所以小编又撸了一张商品池的大概的工作流程图,方便大家把这些概念串起来。
上图中标记了四条线,简单介绍一下(当然上图若有问题,也希望大家能够指出来)。
- 当发起任务时候,会计算线程池中存在的线程数量与核心线程数量(corePoolSize)进行比较,如果小于,则在线程池中创建线程,否则,进行下一步判断。
- 如果不满足条件1,则会将任务添加到阻塞队列中。等待线程池中的线程空闲下来后,获取队列中的任务进行执行。
- 但是条件2中如果阻塞队列满了之后,此时又会重新获取当前线程的数量和最大线程数(maximumPoolSize)进行比较,如果发现小于最大线程数,那么继续添加到线程池中即可。
- 如果都不满足上述条件,那么此时会放到拒绝策略中。
execute核心流程剖析
接下来我们来看一下执行theadPoolExecutor.execute()的时候到底发生了什么。先来看一下源码:
public void execute(Runnable command) { | |
if (command == null) | |
throw new NullPointerException(); | |
int c = ctl.get(); | |
if (workerCountOf(c) < corePoolSize) { | |
if (addWorker(command, true)) | |
return; | |
c = ctl.get(); | |
} | |
if (isRunning(c) && workQueue.offer(command)) { | |
int recheck = ctl.get(); | |
if (! isRunning(recheck) && remove(command)) | |
reject(command); | |
else if (workerCountOf(recheck) == 0) | |
addWorker(null, false); | |
} | |
else if (!addWorker(command, false)) | |
reject(command); | |
} |
ctl变量
进入执行源码之后我们首先看到的是ctl,只知道ctl中拿到了一个int数据至于这个数值有什么用,目前不知道,接着看涉及的相关代码,并且将相关的代码解读放到源码中进行注释。
//通过ctl获取线程池的状态以及包含的线程数量 | |
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); | |
private static final int COUNT_BITS = Integer.SIZE - 3; // COUNT_BITS = 32-3 = 29 | |
/**001左移29位 | |
* 00100000 00000000 00000000 00000000 | |
* 操作减1 | |
* 00011111 11111111 11111111 11111111(表示初始化的时候线程情况,1表示均有空闲线程) | |
* 换成十进制:COUNT_MASK = 536870911 | |
*/ | |
private static final int COUNT_MASK = (1 << COUNT_BITS) - 1; | |
/** | |
* 运行中状态 | |
* 1的原码 | |
* 00000000 00000000 00000000 00000001 | |
* 取反+1 | |
* 11111111 11111111 11111111 11111111 | |
* 左移29位 | |
* 11100000 00000000 00000000 00000000 | |
**/ | |
// runState is stored in the high-order bits | |
private static final int RUNNING = -1 << COUNT_BITS; //运行中状态 11100000 00000000 00000000 00000000 | |
private static final int SHUTDOWN = 0 << COUNT_BITS; //终止状态 00000000 00000000 00000000 00000000 | |
private static final int STOP = 1 << COUNT_BITS; //停止 00100000 00000000 00000000 00000000 | |
private static final int TIDYING = 2 << COUNT_BITS; // 01000000 00000000 00000000 00000000 | |
private static final int TERMINATED = 3 << COUNT_BITS; // 01100000 00000000 00000000 00000000 | |
//取高3位表示获取运行状态 | |
private static int runStateOf(int c) { return c & ~COUNT_MASK; } //~COUNT_MASK表示取反码:11100000 00000000 00000000 00000000 | |
//取出低位29位的值,当前活跃的线程数 | |
private static int workerCountOf(int c) { return c & COUNT_MASK; } //COUNT_MASK:00011111 11111111 11111111 11111111 | |
//计算ctl的值,ctl=[3位]线程池状态 + [29位]线程池中线程数量。 | |
private static int ctlOf(int rs, int wc) { return rs | wc; } //进行或运算 |
上面我们针对各个状态以及那么多的二级制表示符有点懵,当然如果不会二进制运算的,大家可以先自己去了解一下二进制的运算逻辑。
通过源码中的英文,我们知道CTL的值其实分成两部分组成,高三位是状态,其余均为当先线程数。如下的图:
上面的图的描述解释,其实也都是英文注释版的翻译,我们再来看一下有了这些状态,这些状态是怎么流转的,英文注释是这样的:
/*** RUNNING -> SHUTDOWN | |
* On invocation of shutdown() | |
* (RUNNING or SHUTDOWN) -> STOP | |
* On invocation of shutdownNow() | |
* SHUTDOWN -> TIDYING | |
* When both queue and pool are empty | |
* STOP -> TIDYING | |
* When pool is empty | |
* TIDYING -> TERMINATED | |
* When the terminated() hook method has completed | |
* / | |
上面的描述不太直观,小编将流程串了起来,得到了下面的状态机流转图。如下图:
写到这里,其实ctl已经很清楚了,ctl说白了就是状态位和活跃线程数的表示方式。通过ctl咱们可以知道当前是什么状态以及活跃线程数量是多少。
线程池中的线程数小于核心线程数
读完ctl之后,我们来看一下接下来的代码。
if (workerCountOf(c) < corePoolSize) { | |
if (addWorker(command, true)) return; //添加新的线程 | |
c = ctl.get(); //重新获取当前的状态以及线程数量 | |
} |
继上述的workerCountOf,我们知道这个方法可以获取当前活跃的线程数。如果当前线程数小于配置的核心线程数,则会调用addWorker进行添加新的线程。
如果添加失败了,则重新获取ctl的值。
任务添加到队列的相关逻辑
if (isRunning(c) && workQueue.offer(command)) { | |
int recheck = ctl.get(); | |
//再次check一下,当前线程池是否是运行状态,如果不是运行时状态,则把刚刚添加到workQueue中的command移除掉 | |
if (! isRunning(recheck) && remove(command)) | |
reject(command); | |
else if (workerCountOf(recheck) == 0) | |
addWorker(null, false); | |
} |
上述我们知道当添加线程池失败的时候,我们会重新获取ctl的值。
此时咱们的第一步就很清楚了:
- 通过isRunning方法来判断线程池状态是不是运行中状态,如果是,则将command任务放到阻塞队列workQueue中。
- 再次check一下,当前线程池是否是运行状态,如果不是运行时状态,则把刚刚添加到workQueue中的command移除掉,并调用拒绝策略。否则,判断如果当前活动的线程数如果为0,则表明只去创建线程,而此处,并不执行任务(因为,任务已经在上面的offer方法中被添加到了workQueue中了,等待线程池中的线程去消费队列中的任务)
线程池中的线程数量小于最大线程数代码逻辑以及拒绝策略的代码逻辑
接下来,我们看一下最后的一个步骤
/** | |
* 进入第三步骤前提: | |
* 1.线程池不是运行状态,所以isRunning(c)为false | |
* 2.workCount >= corePoolSize的时候于此同时并且添加到queue失败的时候执行 | |
*/ | |
else if (!addWorker(command, false)) | |
reject(command); | |
} |
由于调用addWorker的第二个参数是false,则表示对比的是最大线程数,那么如果往线程池中创建线程依然失败,即addWorker返回false,那么则进入if语句中,直接调用reject方法调用拒绝策略了。
写到这里大家估计会对这个第二个参数是false为什么比较的是最大线程数有疑问。其实这个是addWorker中的方法。我们可以大概看一下:
private boolean addWorker(Runnable firstTask, boolean core) { | |
retry: | |
for (int c = ctl.get();;) { | |
// Check if queue empty only if necessary. | |
if (runStateAtLeast(c, SHUTDOWN) | |
&& (runStateAtLeast(c, STOP) | |
|| firstTask != null | |
|| workQueue.isEmpty())) | |
return false; | |
for (;;) { | |
if (workerCountOf(c) | |
>= ((core ? corePoolSize : maximumPoolSize) & COUNT_MASK)) | |
return false; | |
if (compareAndIncrementWorkerCount(c)) | |
break retry; | |
c = ctl.get(); // Re-read ctl | |
if (runStateAtLeast(c, SHUTDOWN)) | |
continue retry; | |
// else CAS failed due to workerCount change; retry inner loop | |
} | |
} | |
} |
我们很明显地看到当core为flase的时候咱们获取的是maximumPoolSize,也就是最大线程数。
写到这里,其实咱们的核心主流程大概就已经结束了。这里其实也只是写了一个算是比较入门的开头。当然我们还可以在深入去理addWorker的源码。这个其实就交给大家去细看了,篇幅过长,相信大家也会失去阅读的兴趣了,感兴趣的可以自己研究一下。
本人觉得在上述的源码中比较重要的其实就是ctl值的流转顺序以及计算方式,读懂这个的话,后面一切的源码只要树藤摸瓜即可理解。
Executors线程池模板
我们上述主要和大家分享了比较核心的theadPoolExecutor。除此之外,线程池Executors里面包含了很多其他的线程池模板。
当然这也是小猫直接面试的时候说的那些,其实小猫也就仅仅只是背了线程池模板而已,并不知晓其工作原理。
如下几种:
-
newCachedThreadPool
创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。 -
newFixedThreadPool
创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。 -
newScheduledThreadPool
创建一个定长线程池,支持定时及周期性任务执行。 -
newSingleThreadScheduleExecutor
创建一个单线程执行程序,它可安排在给定延迟后运行命令或者定期地执行。(注意,如果因为在关闭前的执行期间出现失败而终止了此单个线程,那么如果需要,一个新线程会代替它执行后续的任务)。可保证顺序地执行各个任务,并且在任意给定的时间不会有多个线程是活动的。与其他等效的 newScheduledThreadPool(1) 不同,可保证无需重新配置此方法所返回的执行程序即可使用其他的线程。 -
newSingleThreadExecutor
创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
多样化的blockingQueue
-
PriorityBlockingQueue
它是一个无界的并发队列。无法向这个队列中插入null值。所有插入到这个队列中的元素必须实现Comparable接口。因此该队列中元素的排序就取决于你自己的Comparable实现。 -
SynchronousQueue
它是一个特殊的队列,它的内部同时只能够容纳单个元素。如果该队列已有一个元素的话,那么试图向队列中插入一个新元素的线程将会阻塞,直到另一个新线程将该元素从队列中抽走。同样的,如果队列为空,试图向队列中抽取一个元素的线程将会被阻塞,直到另一个线程向队列中插入了一条新的元素。因此,它其实不太像是一个队列,而更像是一个汇合点。 -
ArrayBlockingQueue
它是一个有界的阻塞队列,其内部实现是将对象放到一个数组里。一但初始化,大小就无法修改 -
LinkedBlockingQueue
它内部以一个链式结构(链接节点)对其元素进行存储。可以指定元素上限,否则,上限则为Integer.MAX_VALUE。 -
DelayQueue
它对元素进行持有直到一个特定的延迟到期。注意:进入其中的元素必须实现Delayed接口。
上述针对这些罗列了一下,其实很多官网上也有相关的介绍,当然感兴趣的小伙伴也可以再去刨一刨里面的源码实现。
拒绝策略
-
AbortPolicy
丢弃任务并抛出RejectedExecutionException异常。 -
DiscardPolicy
丢弃任务,但是不抛出异常。 -
DiscardOldestPolicy
丢弃队列中最前面的任务,然后重新尝试执行任务。 -
CallerRunsPolicy
由调用线程处理该任务。
总结
很多小伙伴在用一些线程池或者第三方中间件的时候可能只停留在如何使用上,一旦出了问题或者被人深入问到其实现原理的时候就比较头大。
所以在日常开发的过程中,我们不仅仅需要知道如何去用,其实更应该知道底层的原理是什么。这样才能长立于不败之地。







![基于博弈树的开源五子棋AI教程[3 极大极小搜索]](https://img-blog.csdnimg.cn/direct/f6b6876dbfc04c6ab5611af858b4704a.png)