目录
什么是日志呢 ? 日志有什么作用呢?
什么是日志呢 ?
日志的作用是什么呢 ?
我们需要学会日志的什么 ?
自定义输出日志
日志持久化
为什么要将日志持久化呢?
如何进行日志的持久化
设置日志级别
日志级别有什么用呢 ?
日志都有哪些级别呢 ?
如何设置日志级别?
多种环境下日志级别设置
使用注解自定义输出日志
lombox实现原理
什么是日志呢 ? 日志有什么作用呢?
什么是日志呢 ?
就像我们平时写的代码,运行结果输出到控制台上,控制台显示的其实就是日志.比如下面的
虽然这是日志,但是并不能替代我们项目中的日志. 如下就是我们项目中的日志

这就是我们项目中的日志,日志中包含许多信息,可以帮助我们排查和定位问题.
日志的作用是什么呢 ?
我们通过日志可以帮助我们定位和排查问题,这是非常重要的,在日常开发中,有的时候只看代码并不能看出问题,看下日志,与我们的需求是否出现差异,在程序运行的时候是否出现异常等等...
处理定位和排查问题之外,还可以实现一些功能 :
- 可以记录用户的登陆日志; 可以发现用户是否是正常登录状态的,如果有人尝试暴力破解该用户密码就可以被发现,程序猿也可以及时去处理(方便分析用户是正常登录还是恶意破解用户)
- 可以记录系统的操作日志, 可以看数据恢复情况 以及 定位具体是谁操作的.(方便数据恢复和定位操作人)
- 记录程序的执行时间,; 比如这次程序执行了5min,但正常只需3分钟,程序猿就可以根据程序执行时间做出优化和调整.(方便为以后优化程序提供数据支持)
我们需要学会日志的什么 ?

我们再来看一下我们spring boot 的项目日志. 我分别介绍一下日志都包含哪些内容.
2022-12-26T08:54:20.859+08:00 INFO 6200 --- [ main] o.s.b.d.f.s.MyApplication : Starting MyApplication using Java 17 with PID 6200 (/opt/apps/myapp.jar started by myuser in /opt/apps/) 2022-12-26T08:54:20.872+08:00 INFO 6200 --- [ main] o.s.b.d.f.s.MyApplication : No active profile set, falling back to 1 default profile: "default" 2022-12-26T08:54:22.892+08:00 INFO 6200 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 8080 (http) 2022-12-26T08:54:22.917+08:00 INFO 6200 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat] 2022-12-26T08:54:22.917+08:00 INFO 6200 --- [ main] o.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/10.1.4] 2022-12-26T08:54:23.189+08:00 INFO 6200 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext 2022-12-26T08:54:23.192+08:00 INFO 6200 --- [ main] w.s.c.ServletWebServerApplicationContext : Root WebApplicationContext: initialization completed in 2200 ms 2022-12-26T08:54:23.797+08:00 INFO 6200 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path '' 2022-12-26T08:54:23.810+08:00 INFO 6200 --- [ main] o.s.b.d.f.s.MyApplication : Started MyApplication in 4.539 seconds (process running for 5.555)
- Date和时Time:精确到毫秒,易于排序。
- 日志级别: ERROR, WARN, INFO, DEBUG, 或 TRACE.
- 进程ID。
- 一个 --- 分隔符,以区分实际日志信息的开始。
- 线程名称:包含在方括号中(对于控制台输出可能会被截断)。
- 记录器名称:这通常是源类的名称(通常是缩写)。
- 日志消息。
我们springboot 项目日志包含很多内容,所以我们也说那种System.out.println()是替代不了我们springboot项目的日志. 同时System.out.println() 也无法替代不同环境下的日志筛选
在日常开发中我们要学会
- 输出自定义日志信息
我们也可以在日志信息中根据我们的需求输出我们自己定义的内容,方便排查出问题.
- 将日志持久化
有些时候,开发人员,测试人员.. 不能一直盯着机器看哪里出现了问题,需要将日志打印出来,进行排查问题,因为输出在控制台上的日志,一关闭项目就没有了.
- 通过设置日志的级别来筛选和控制日志的内容
由于日志的需求不同,我们需要通过设置日志的级别来控制日志的输出,比如开发环境我们需要很详细的信息进行排查问题,而对于生产环境下,为了保证产品的性能和安全性就会输入尽量少的日志,通过日志的级别就可以筛选日志,完成我们对不同环境下的需求.
自定义输出日志
我们自定义输出日志需要2步
- 得到日志对象
- 调用日志对象对应方法,输出日志自定义内容
1.得到日志对象
//得到日志对象-->使用slf4j private static Logger log = LoggerFactory.getLogger(TestLogging.class);
2..调用日志对象对应方法,输出日志自定义内容
@RestController
public class TestLogging {
//得到日志对象-->使用slf4j
private static Logger log = LoggerFactory.getLogger(TestLogging.class);
@RequestMapping("/logging")
public void sayHi(){
log.trace("hi trace~~~");
log.debug("hi debug~~~");
log.info ("hi info ~~~");
log.warn ("hi warn ~~~");
log.error("hi error~~~");
}
}


日志持久化
我们知道控制台输出的内容,当我们重新打开项目,内容就消失了.所谓日志持久化,就是将程序输出的日志保存到我们电脑的硬盘中就可以了.
为什么要将日志持久化呢?
你想啊,开发人员,测试人员.. 不能一直盯着项目看哪里出现了异常,于是我们就可以把日志进行保存起来,当出现了问题,我们在去排查保存的日志,看哪里出现了问题,再去调整.
如何进行日志的持久化
我们需要在配置文件进行配置, 我们配置保存的文件的名称就可以将其日志保存到文件中
| logging.file.name | logging.file.path | Example | Description |
| (none) | (none) | 只在控制台进行记录。 | |
| 指定文件 | (none) | my.log | 写入指定的日志文件。 名称可以是一个确切的位置,也可以是与当前目录的相对位置。 |
| (none) | 指定目录 | /var/log | 将 spring.log 写到指定目录。 名称可以是一个确切的位置,也可以是与当前目录的相对位置。 |
比如我们配置 文件名称为springboot.log(根据名称配置)
# 进行日志持久化 将日志内容保存到 spring-boot.log文件下
logging:
file:
name: spring-boot.log

还可以根据路径进行配置
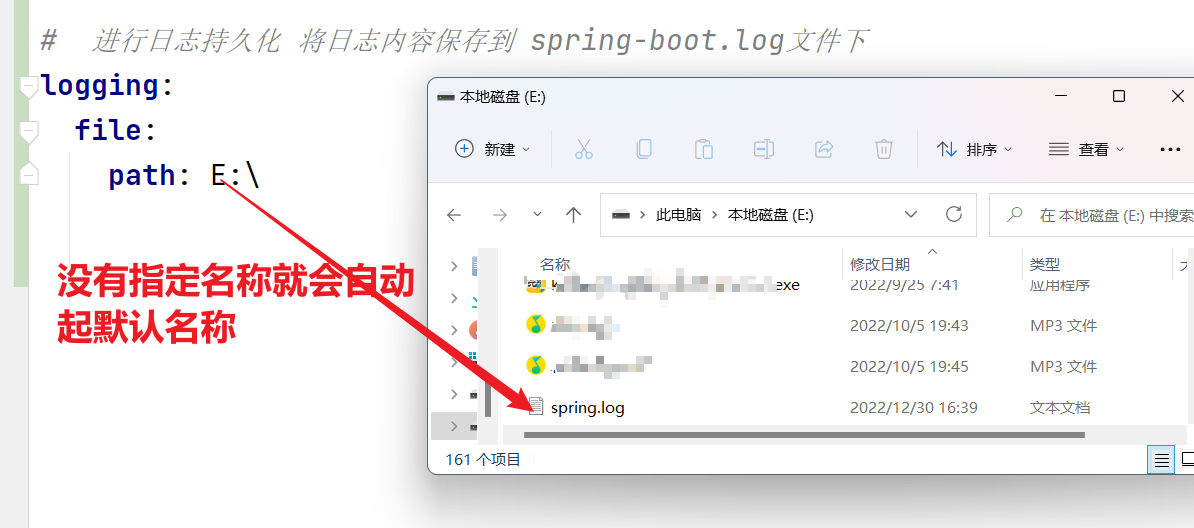
当配置了就会在idea显示出相应配置的文件.
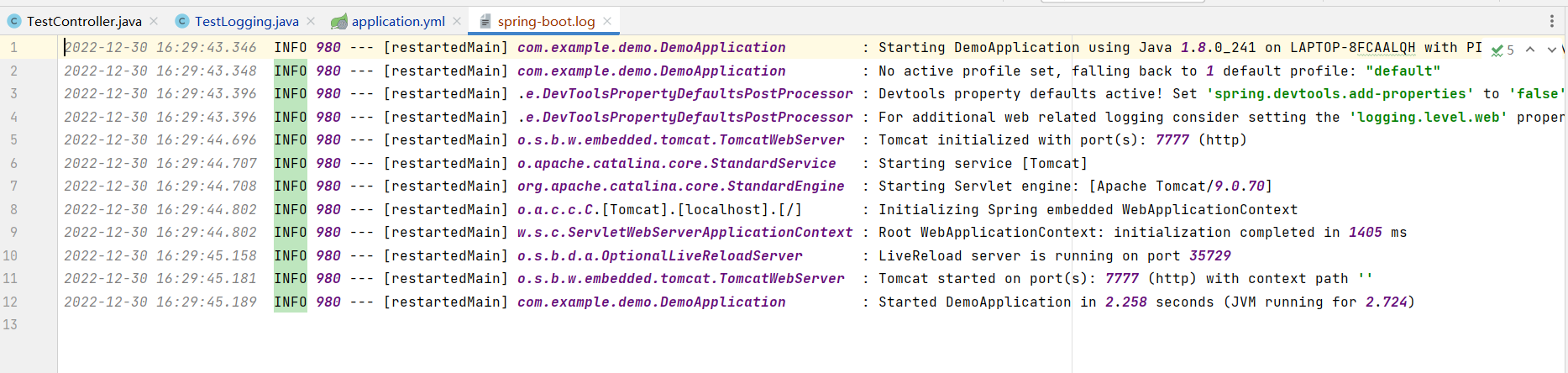
日志内容就会保存该spring-boot.log文件下,如果日志找不到了,就可以在这里查看日志,进行排查问题
但是有的时候,你会发现怎么也不显示出你配置的日志文件,这时候你就可以打开当前项目目录,然后将target目录删除掉,在重新启动项目.->原因是idea可能会做一些优化,发现代码与上次启动的一样,就加载上次的项目.
对于日志这块又有两个问题,
这个日志每次是在上次的基础上是追加还是覆盖呢 ?
我们可以演示一下.

所以说,日志是在上次的基础上,继续追加,不会使得日志丢失/覆盖的情况
日志太大会怎么办 ?
我们再来根据上面继续做演示
当我一直输出日志

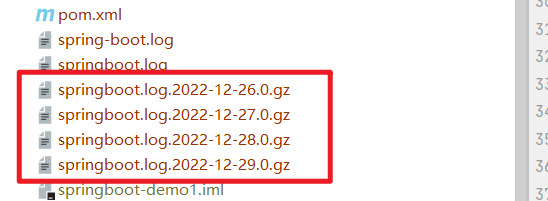
日志文件在达到10MB时就会轮换,与控制台输出一样,默认情况下会记录 ERROR 、WARN 级和 INFO 级别的信息.
当日志比较大的时候会自动分割,分割成多个文件,在原有的文件上,加上时间,分割成多个
设置日志级别
日志级别有什么用呢 ?
- 通过设置日志的级别来筛选和控制日志的内容以及不同环境下需求不一样,开的日志也不一样
由于日志的需求不同,我们需要通过设置日志的级别来控制日志的输出,比如开发环境我们需要很详细的信息进行排查问题,而对于生产环境下,为了保证产品的性能和安全性就会输入尽量少的日志,通过日志的级别就可以筛选日志,完成我们对不同环境下的需求.
日志都有哪些级别呢 ?
- trace : 级别最低
- debug : 需要调试的时候关键信息的打印.
- info : 普通的打印信息 (默认的日志级别)
- warn : 警告,不影响使用,但需要注意的问题
- error: 错误的信息,级别较高的错误日志信息;
- fatal:致命的,因为代码异常导致程序退出执行的事件
fatal 只会在真正出现异常导致程序退出的时候的时候,fatal日志才会发生,
这些日志自上而下,日志级别越来越高,当设置了一个日志级别,日志只能看见大于等于该日志级别的日志.
比如 : 当你设置日志级别为warn,你就只能看见warn,error日志级别的日志
再比如,当你设置日志级别为info的时候,你就能看见大于等于info级别的日志,info,warn,error
我们可以来打印一下看一下对应的日志
@RestController
public class TestLogging {
//得到日志对象-->使用slf4j
private static Logger log = LoggerFactory.getLogger(TestLogging.class);
@RequestMapping("/logging")
public void sayHi(){
log.trace("hi trace~~~");
log.debug("hi debug~~~");
log.info ("hi info ~~~");
log.warn ("hi warn ~~~");
log.error("hi error~~~");
}
}

从这里能看出来,能够打印3条信息,info,warn,error.
那为啥debug,trace,fatal打印不出来呢 ?
首先debug和trace打印不出来是因为日志级别的问题,因为debug和trace的日志级别比info低所以不会打印,而fatal不会打印,只会在真正出现异常导致程序退出的时候的时候,fatal日志才会发生,
如何设置日志级别?
# 设置日志级别-->设置root目录下的日志级别为warn
logging:
level:
root: warn
这样当我在启动的时候,就只能看见一个图标,因为启动默认没有warn级别的日志.
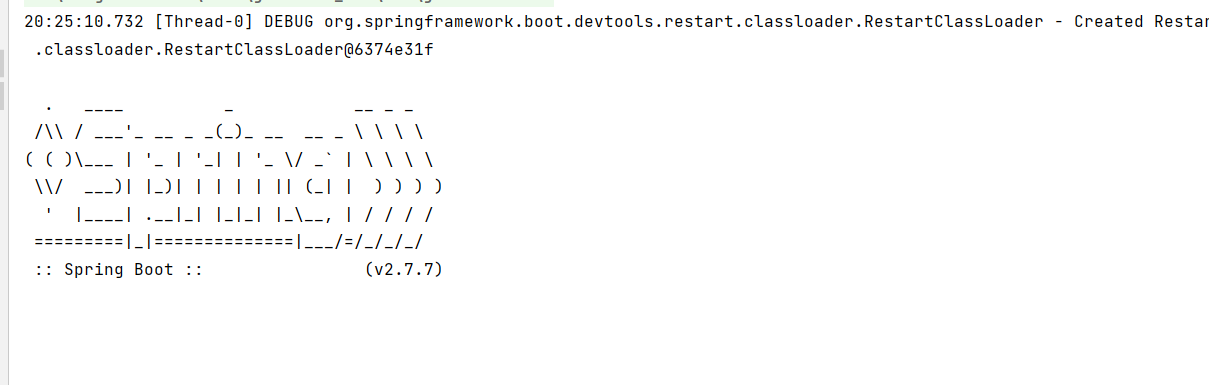
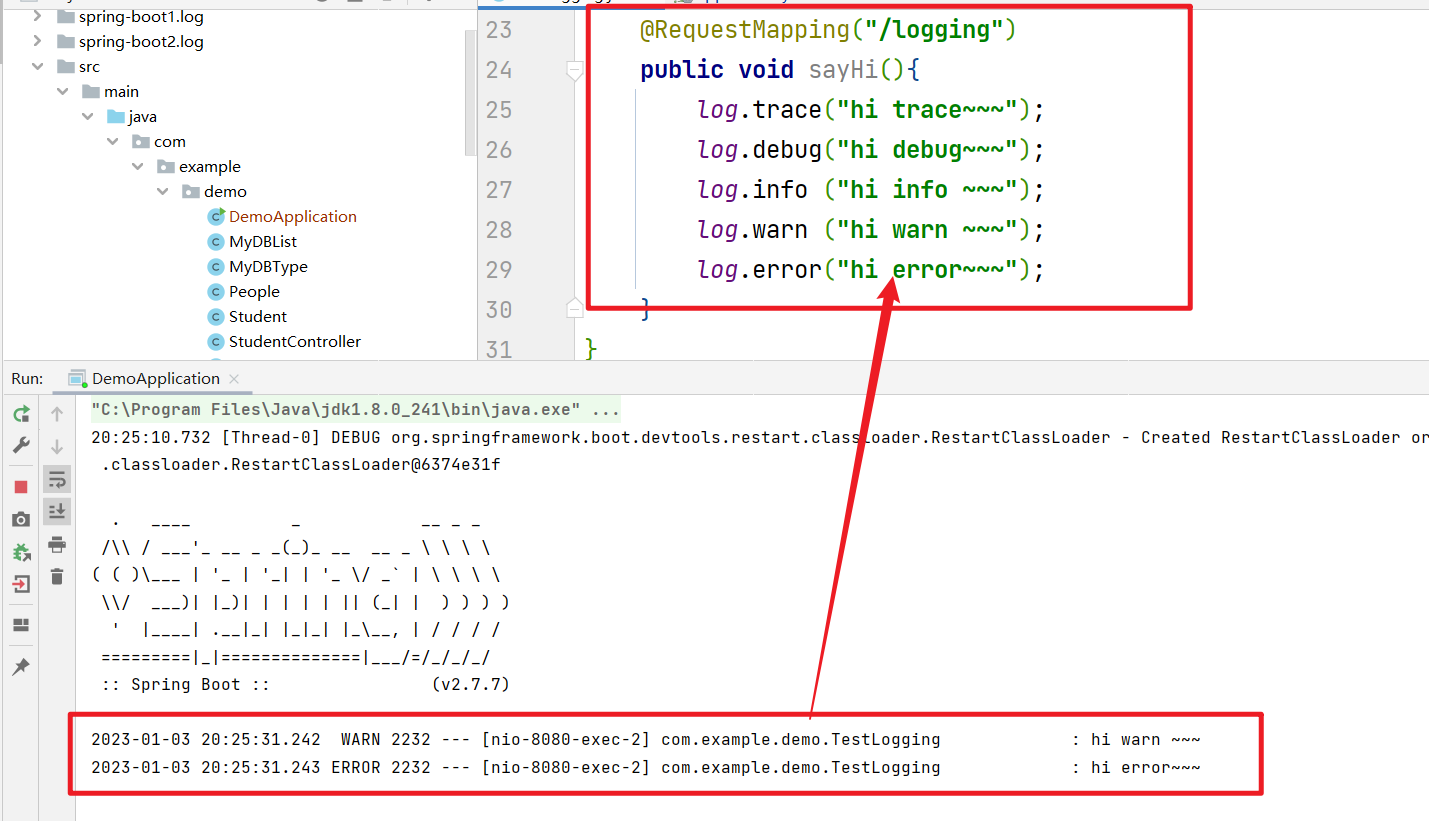
当实现自己打印的时候就会看到大于等于warn的级别,所以就会看到日志级别为warn,error.
我们也可以自定义目录进行设置
logging:
level:
root: warn
com:
example:
demo: debug
比如像上面的配置,我配置了com.example.demo目录下的日志级别为debug,同时root目录(根目录)的日志级别为warn,他们是同时生效的.
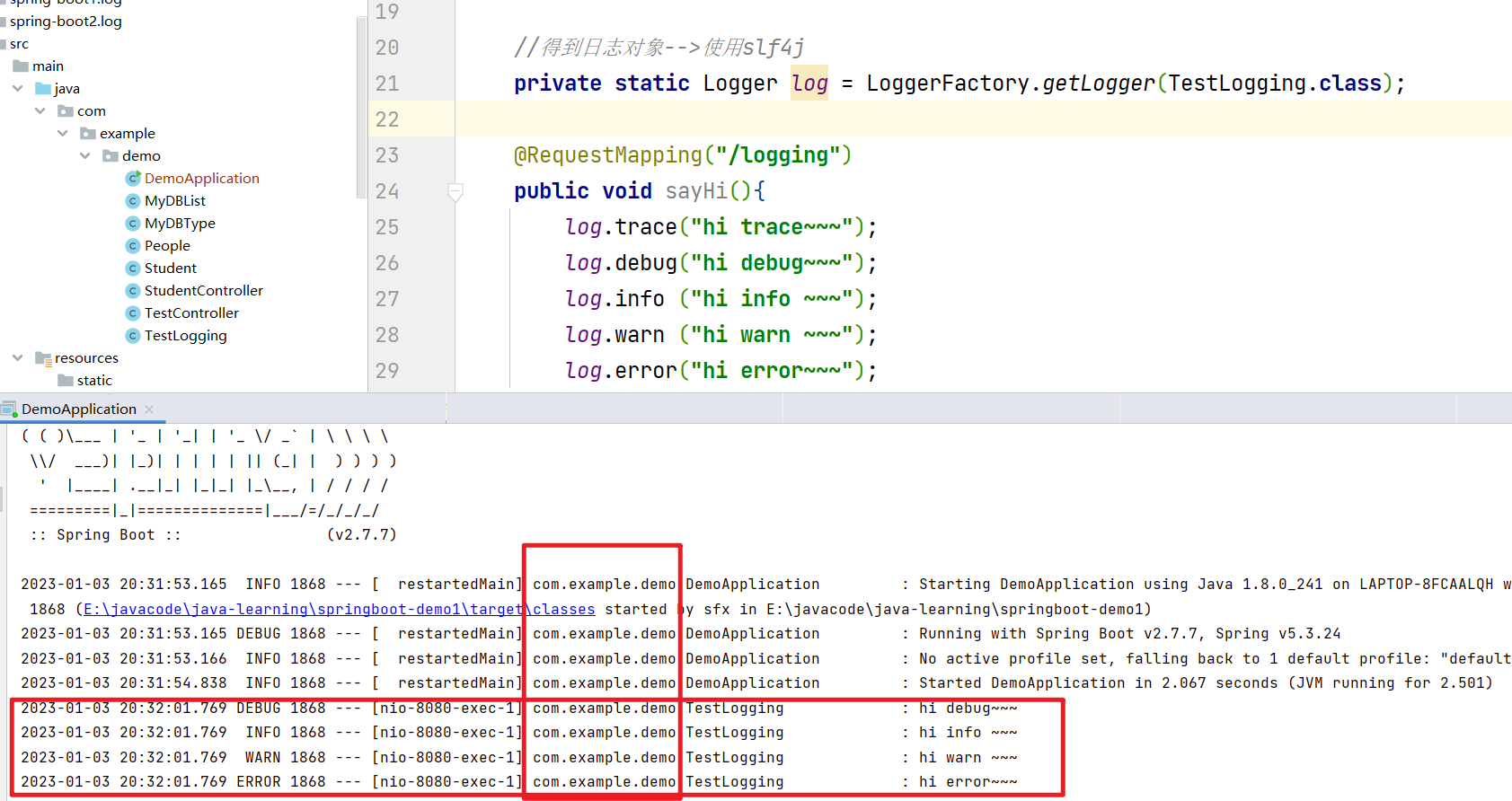
多种环境下日志级别设置
我们同样也可以进行多环境下的日志级别,比如在生产环境下,我就需要程序性能高一些避免一些冗余的日志,就会设置日志级别高一些,而在开发环境下我就需要看一些调试信息来帮助我们排查信息就需要设置日志级别低一些.
举一个例子,我来进行配置:

使用注解自定义输出日志
要想使用注解来输出日志我们要借助lombok,所以我们先要在pom.xml中引入依赖
<dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.20</version> <optional>true</optional> </dependency>
我们也可以使用插件引入
当我们引入完依赖之后就可以使用一个注解 为 @Slf4j
我来演示一下 :


lombox实现原理
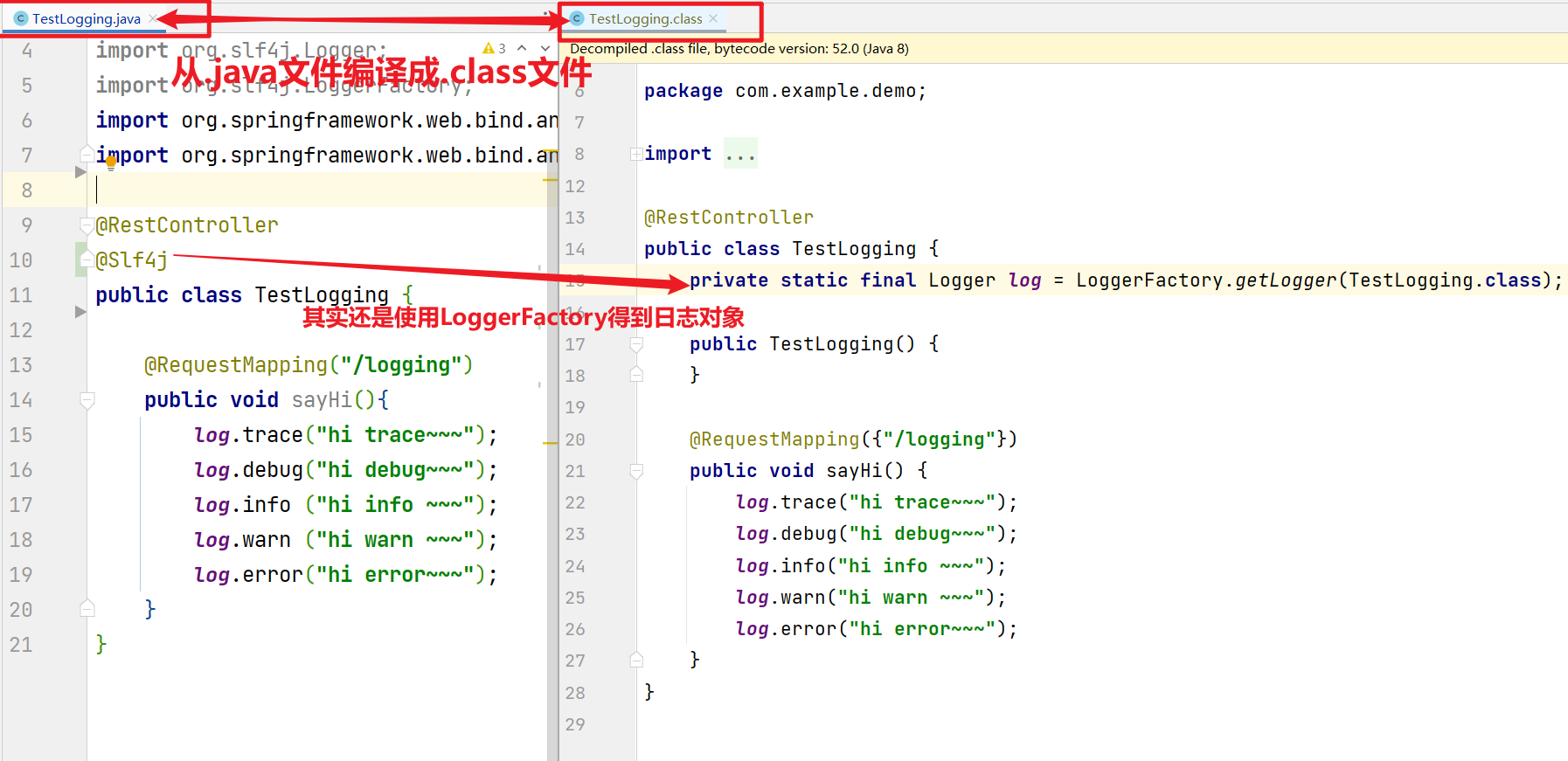
所以我们可以得出@Slf4j是在编译期间生效的,在编译器将.java文件变成.class期间,就把注解变成了功能代码.



![[C语言]三种方法实现n的k次方(递归/调用math库函数/实现pow函数)[含递归图解说明]](https://img-blog.csdnimg.cn/0229ae975bb44cb7a91f5d1f735135ac.png)









![P1046 [NOIP2005 普及组] 陶陶摘苹果————C++](https://img-blog.csdnimg.cn/9bf48241725245859e24bef98b4d4624.png)