池化类似压缩
最大池化-上采样


例如给一个3的话就会生成一个3×3的窗口(生成相同的高和宽),给一个tuple就会给出一个相同的池化核。stride默认值就是核的大小
dilation

在卷积dialation设置之后每一个会和另外的差一个,空洞卷积
ceil floor 模式(天花板、地板)

floor就是向下取整。
按下面的方法走,走的步数默认为核的大小

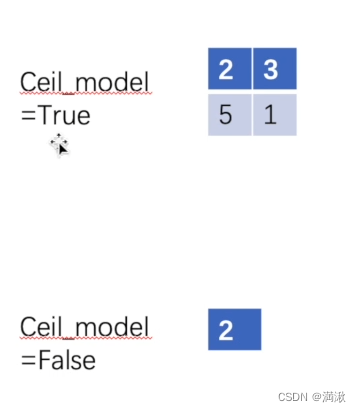

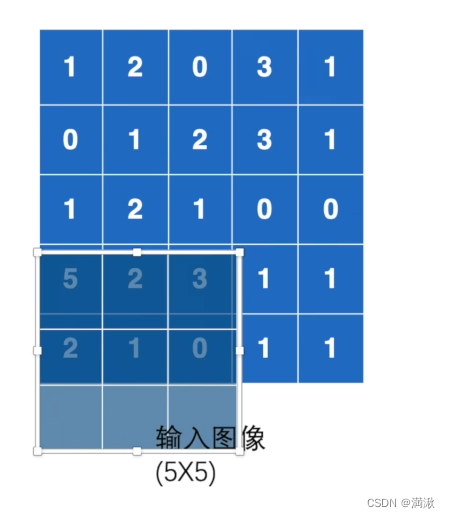

取9个里面的最大值,走到右一图,这种情况只能覆盖6个,其他没有数字,在这种情况下要不要取6个数的最大值,还是直接放弃这6个数,就看ceil mode模式了!如果是ceil下,就要保留这6个数。
非线性激活
ReLu、sigmoid
以ReLu、sigmoid为例
注意输入输入的batch_size后面不做一个限制




1.数据预处理,定义输入,并变换输入形状。
首先,套路先引入torch,然后定义一个input,如下
input = torch.tensor([[1, -0.5],
[-1, 3]])
#“-1”表示batchsize任意电脑给,1代表一维的,
output = torch.reshape(input, (-1, 1, 2, 2))
input = torch.tensor([[1, -0.5],
[-1, 3]])
#“-1”表示batchsize任意电脑给,1代表一维的,
output = torch.reshape(input, (-1, 1, 2, 2))这边要解释一下reshape之后的目标形状,经过reshape之后,输入的形状会变成(2, 1, 2, 2),这是这是为了适应卷积神经网络的输入格式[batch_size, channels, height, width]
2.搭建神经网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
#什么叫inplace
self.relu1 = ReLU()
这边要先暂停注意一下ReLU的输入中的inplace:替换,在不在原来的地方进行替换
引用传递和值传递的区别
例如当:
对原来的变量直接进行变换,结果的替换
Input = -1
ReLU(input, inplace=True)
Input = 0
不替换,新的变换值会返回成一个Output,一般情况下采用下面这种方式,防止原始数据的丢失
Input = -1
ReLU(input, inplace=Flase)
Input = -1
Output = 0
紧接神经网络完整的代码如下:
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
#什么叫inplace
self.relu1 = ReLU()
def forward(self,input):
output = self.relu1(input)
return output
tudui = Tudui()
output = tudui(input)
print(output)
紧接着看sigmoid对图像的影响
归一化层,Recurrent层,Transformer 层,线性层
1.normalization是归一化,regularization是正则化


2.线性层

3.dropout层(主要是防止过拟合用的)
按p的概率将一些输入元素随机变成0
4.Embedding层(稀疏层)

重点学习一下线性层


X1到g1会有一个映射管线K1*x1+b(偏置权重)
学习一下VGG16网络
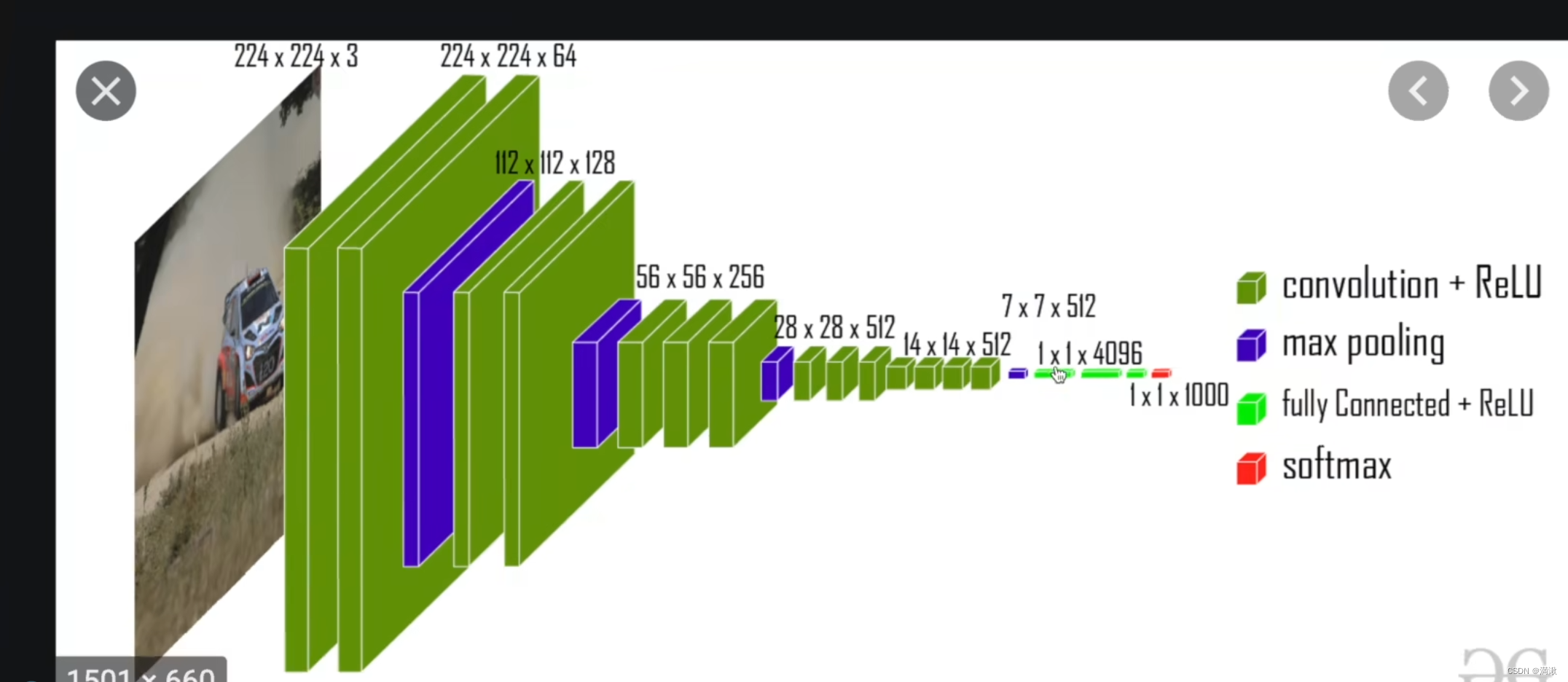
1*1*4090 -1*1*1000
任务

引入展平函数