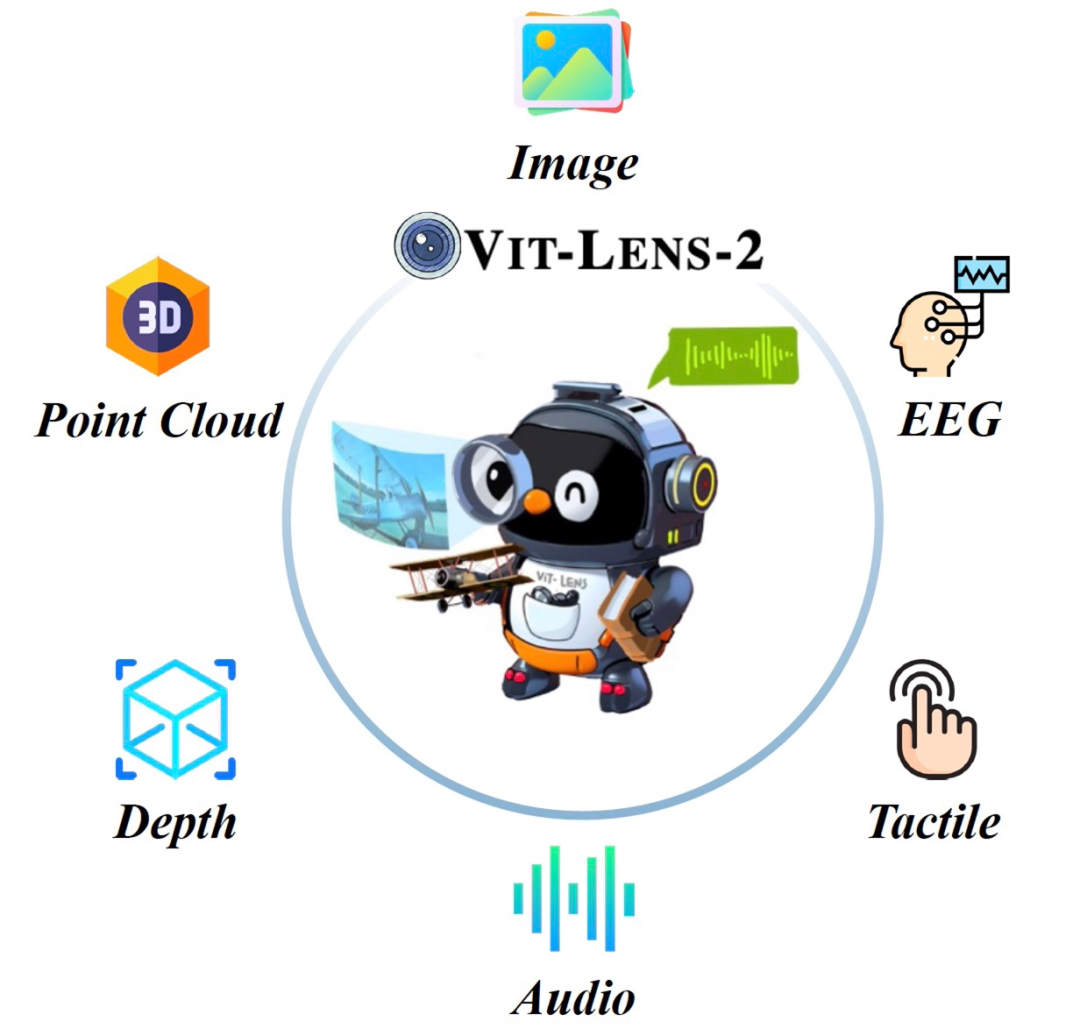
多模态感知一直是通用人工智能发展的关键领域。理想中的智能体能像人类一样感知多种模态信息,如视觉、听觉、嗅觉、触觉等,并与用户进行自然交互。然而,现有的大型模型虽然在图像和文字上表现出色,但对其他模态(如3D点云、触觉数据等)的泛化能力有限。
在本文中,NUS和腾讯的研究人员合作推出ViT-Lens-2,借助预训练的ViT提取各种模态表征,支持3D点云、深度、音频、触觉和EEG脑电,在各种表征任务中取得了SOTA结果。通过模态对齐和共享ViT参数实现了新兴下游功能,以零样本方式实现了任何模态生成文本和图像的能力。

论文题目:
ViT-Lens-2: Gateway to Omni-modal Intelligence
论文链接:
https://arxiv.org/abs/2311.16081
开源代码:
GitHub - TencentARC/ViT-Lens: [Preprint] ViT-Lens: Towards Omni-modal Representations
开源模型:
https://huggingface.co/TencentARC/ViT-Lens/tree/main
项目主页:
ViT-Lens
当海浪声在脑海中回响时,你是否想象过置身于金色沙滩和碧蓝大海交织的奇妙景象?当你触摸家居商店的沙发时,是否幻想过它如何放置在家中与新年的装饰相得益彰?这种像人类或其他动物一样感知各种模态并生成视觉画面的能力,出现在最近公布的智能模型中:01. TL;DR
ViT-Lens革新了多模态表征学习!这个方法不仅在多种模态的基准测试中取得了sota成绩,更可以无需额外训练,直接插入图文多模态大模型,激发全新功能。
ViT-Lens: 任意模态生成图片
01. TL;DR
ViT-Lens革新了多模态表征学习!这个方法不仅在多种模态的基准测试中取得了sota成绩,更可以无需额外训练,直接插入图文多模态大模型,激发全新功能。
02. 介绍
多模态感知一直是通用人工智能发展的关键领域。理想中的智能体能像人类一样感知多种模态信息,如视觉、听觉、嗅觉、触觉等,并与用户进行自然交互。
然而,现有的大型模型如LLaVA、InstructBLIP和SEED LLaMA等虽然在图像和文字上表现出色,但对其他模态(如3D点云、触觉数据等)的泛化能力有限,因为这些模态的训练数据相对稀缺。
有没有一种方法,不需要额外的海量数据,就能轻松提升模型在多种模态上的表现?NUS和腾讯的研究人员合作推出ViT-Lens,设计并采用Lens结构,借助预训练的ViT提取多模态数据特征,实现了多模态对齐学习。这种新方法不仅提升了模型性能,还能直接嵌入多模态大模型,开启一系列神奇功能:从任意模态信号进行问答交互,根据任意模态的数据生成“想象中”的图片(如根据沙发材料的触感生成沙发图片),甚至根据用户的编辑指令和模态输入数据生成符合条件的图片。
03. 方法
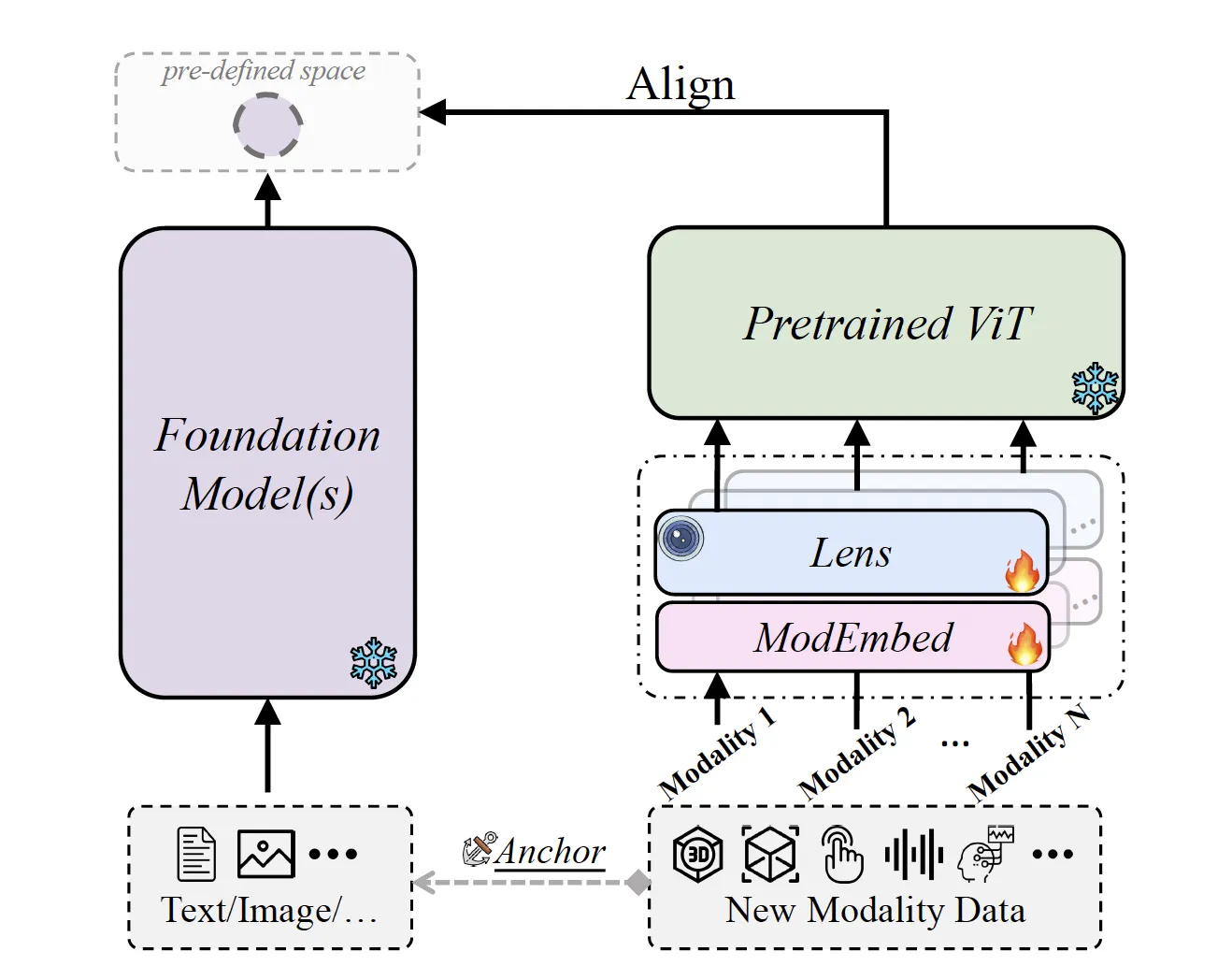
ViT-Lens旨在实现多模态特征对齐,将其作为模型学习的目标。该方法利用匹配的锚数据(一般来源于常见的图片或文字)进行特征对齐。
针对需要学习的新模态数据,该方法引入可训练的ModEmbed和Lens模块,和固定参数的预训练的ViT层,将这些模块级联以学习新模态的特征提取。
对于锚数据,我们利用鲁棒的基础模型(如视觉基础模型、语言基础模型或CLIP)进行特征提取。随后,通过训练得到的新模态数据的特征与锚定数据的特征进行对齐,从而优化网络参数。
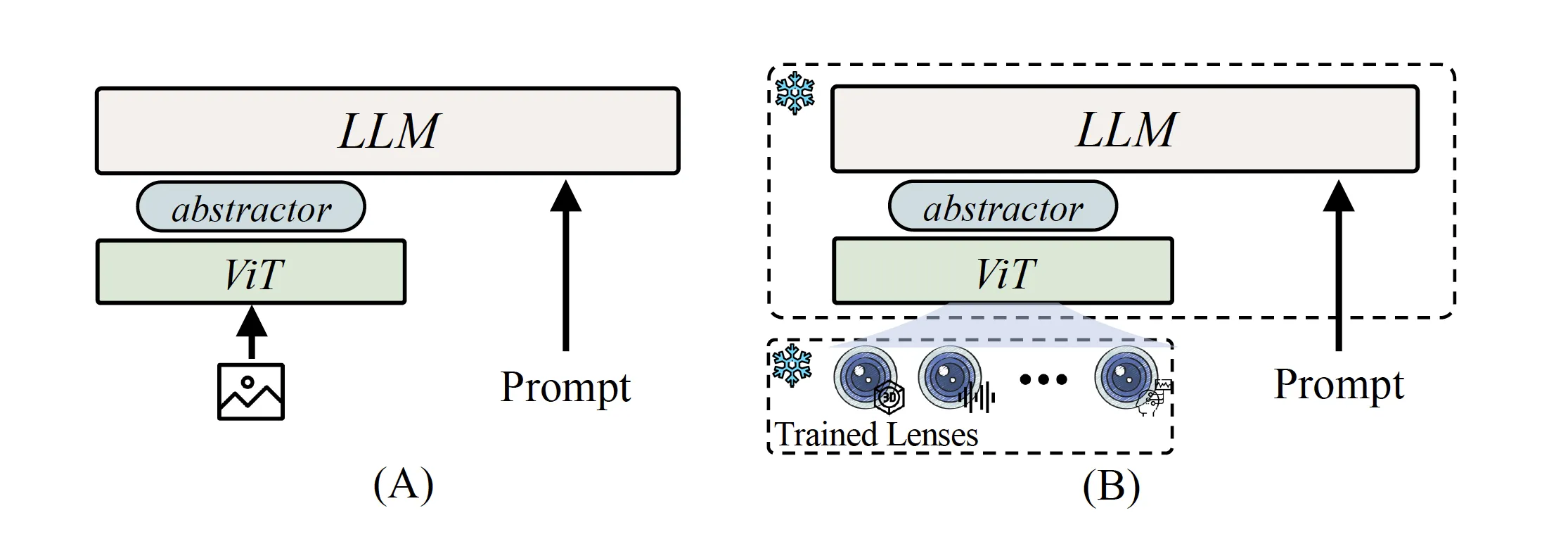
ViT-Lens的另一个优点是,训练好的Lens模块可以轻松地嵌入到图文多模态大模型中。这使得其中的大语言模型(LLM)能够理解新的模态。通常情况下,图文多模态大模型由视觉模型ViT、大语言模型LLM和二者之间连接的参数Abstractor组成。通过ViT-Lens的训练,我们可以直接将训练好的Lens模块整合到多模态大模型中,让新模型能够扩展原有图文多模态大模型的能力到新的模态。最激动人心的是,这样的扩展不需要构建新的数据用于大模型的训练,就能够达到令人满意的效果。
04. 实验
作者在多个模态数据上使用ViT-Lens进行了一系列实验,包括3D点云(3D Point Clouds),深度图(depth),音频(audio),触觉(tactile)和脑电图(EEG)。在多个理解任务中,ViT-Lens的性能均超越了先前的方法。
4.1 理解任务
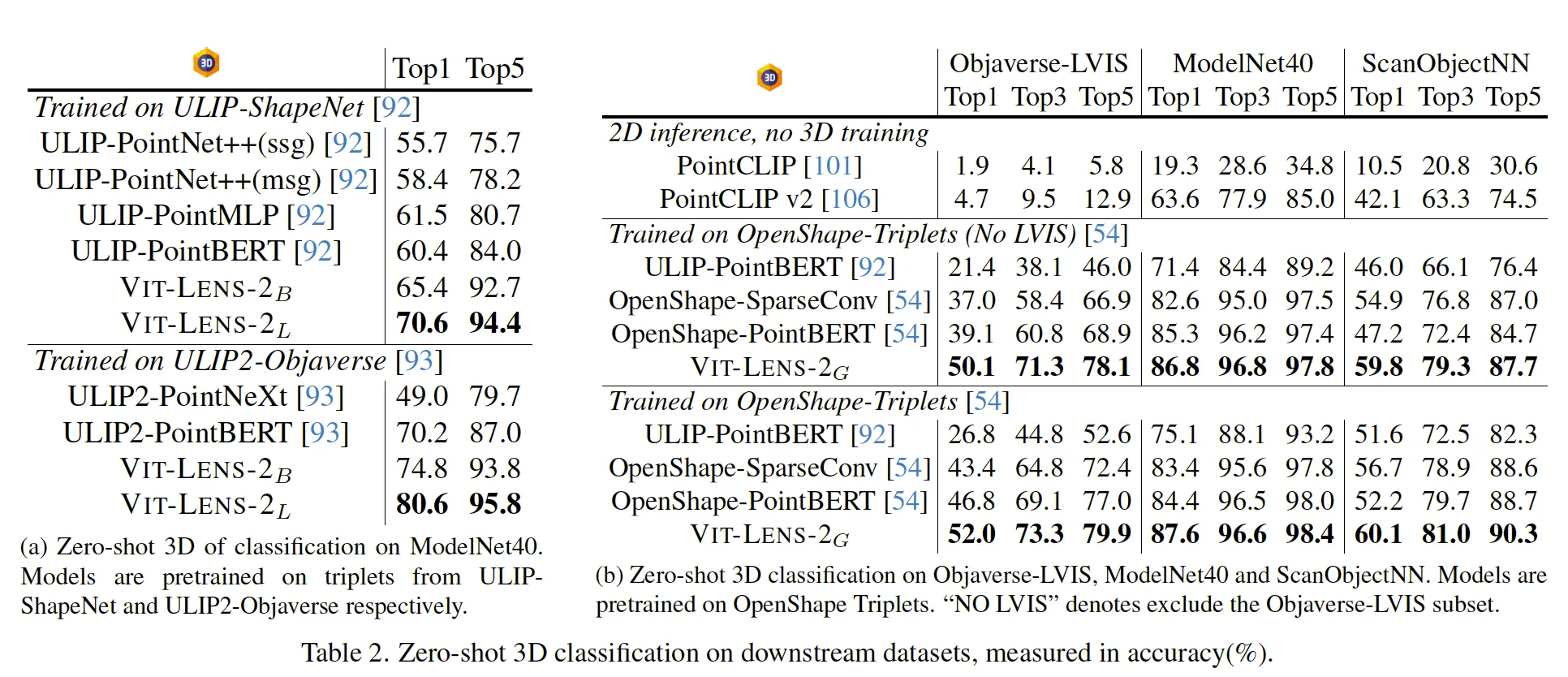
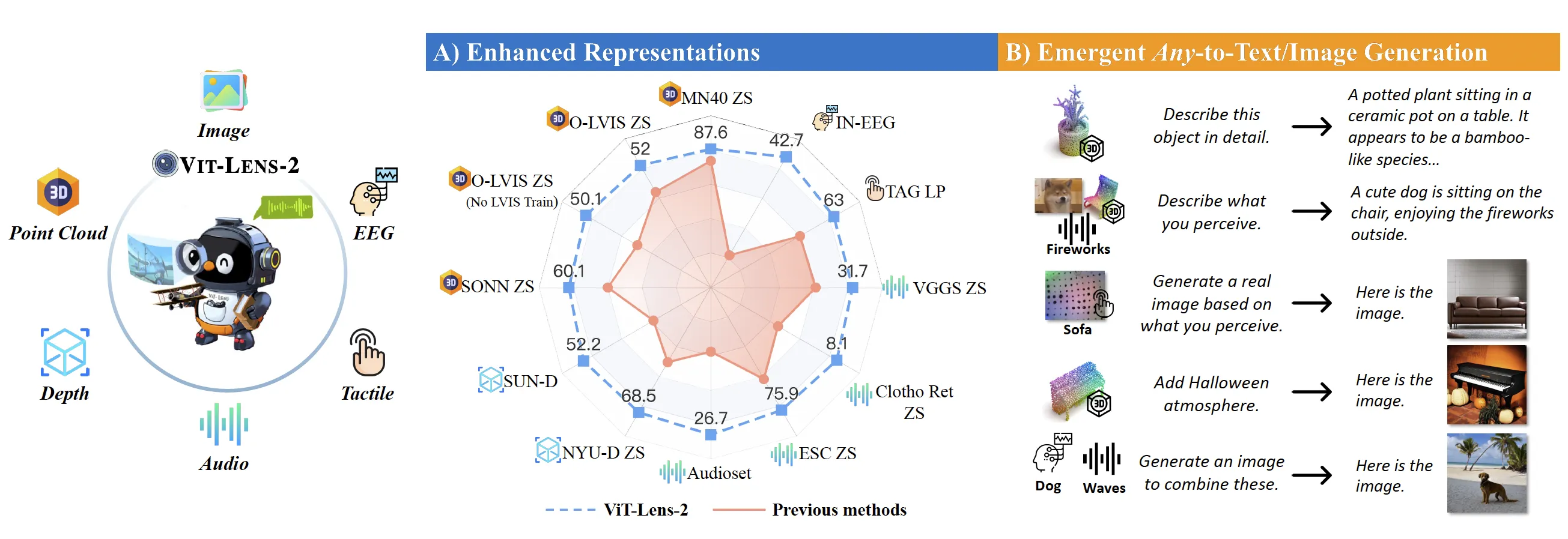
在3D物体点云零样本分类任务中,ViT-Lens表现出众,在使用不同预训练数据训练时,均超越之前方法的性能。使用OpenShape提供的训练数据训练的ViT-Lens-G在3个数据集上达到了sota的结果。特别值得一提的是,当从训练数据中排除包含LVIS子集的数据时,ViT-Lens在Objaverse-LVIS数据集上仍然保持着出色的表现(50.1%),而其他方法在这个数据集上的性能则大幅下降。这表明了ViT-Lens能够充分利用模型所蕴含的知识,以一定程度上弥补训练数据不足的局面。
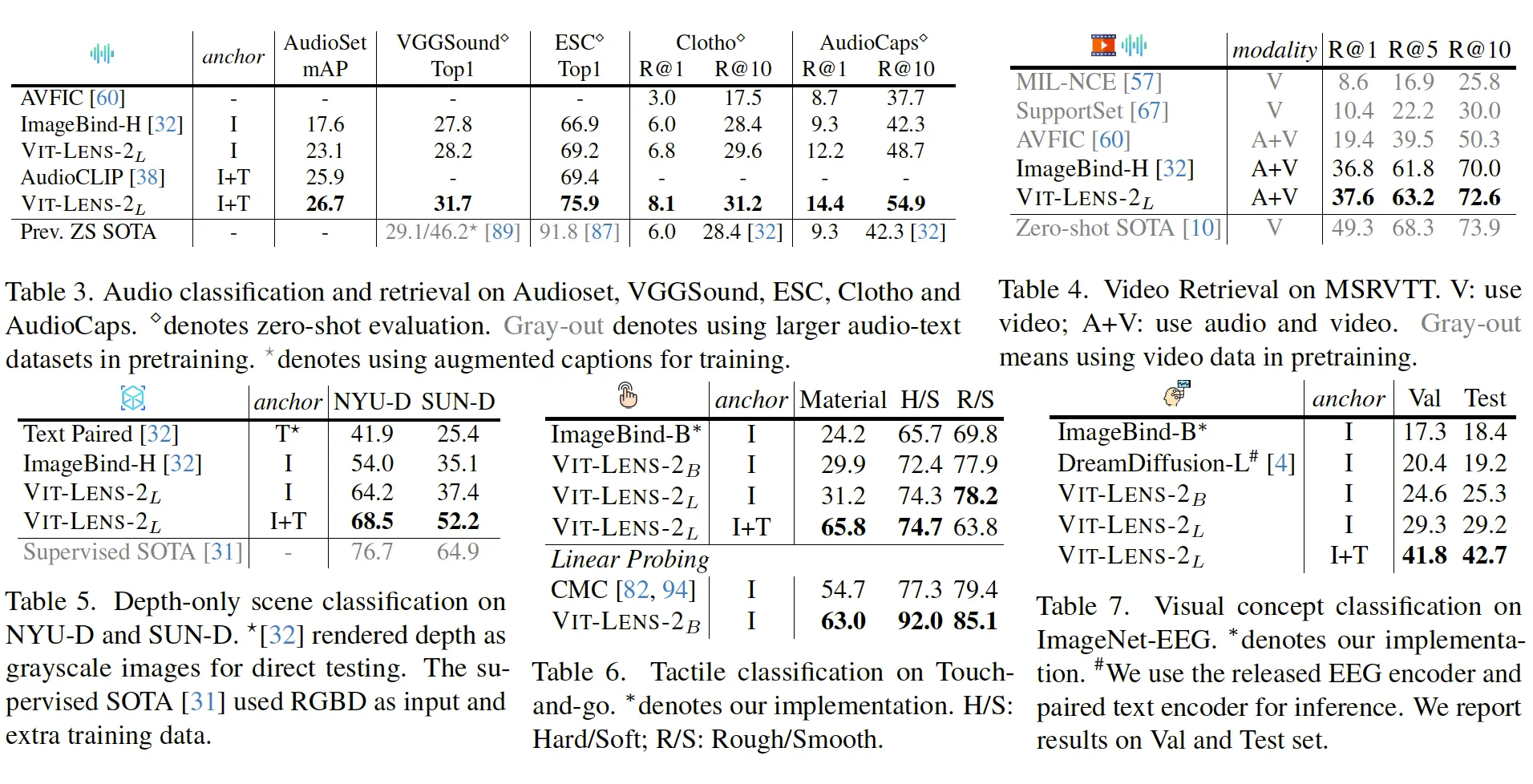
在其他模态的实验中,ViT-Lens的表现同样不俗。在音频、视频和深度理解任务中,使用Large规模的ViT模型,ViT-Lens即超越了ImageBind的Huge版本。在触觉和脑电图理解任务中,ViT-Lens的性能也均超越了先前的方法。
4.2 ViT-Lens应用展示
通过在多个模态上训练得到ViT-Lens模型,这个工作开启了许多有趣的应用。

图中展示了几个引人注目的例子。在 (A) 和 (B) 中的案例中,通过将训练好的Lens插入到InstructBLIP中,实现了大型语言模型对单一模态数据进行详细描述,并能够处理多种混合模态数据,并以此编写故事。在 (C)、(D) 和 (E) 中的案例中,我们将训练好的Lens嵌入到SEED-LLaMA中,无需额外训练即可生成任意模态到图片的转换。此外,还能够基于模态输入添加编辑属性,如“添加万圣节的节日氛围”或“合理地编排这两个物体到同一张图中”等。值得注意的是,无论是文字生成还是图片生成,ViT-Lens都展现了出色的细节捕捉能力。比如,对于 (A) 中钢琴“large in size”的描述以及在 (C)、(D) 中3D形状和细节的保留。下面给出更多的效果展示。

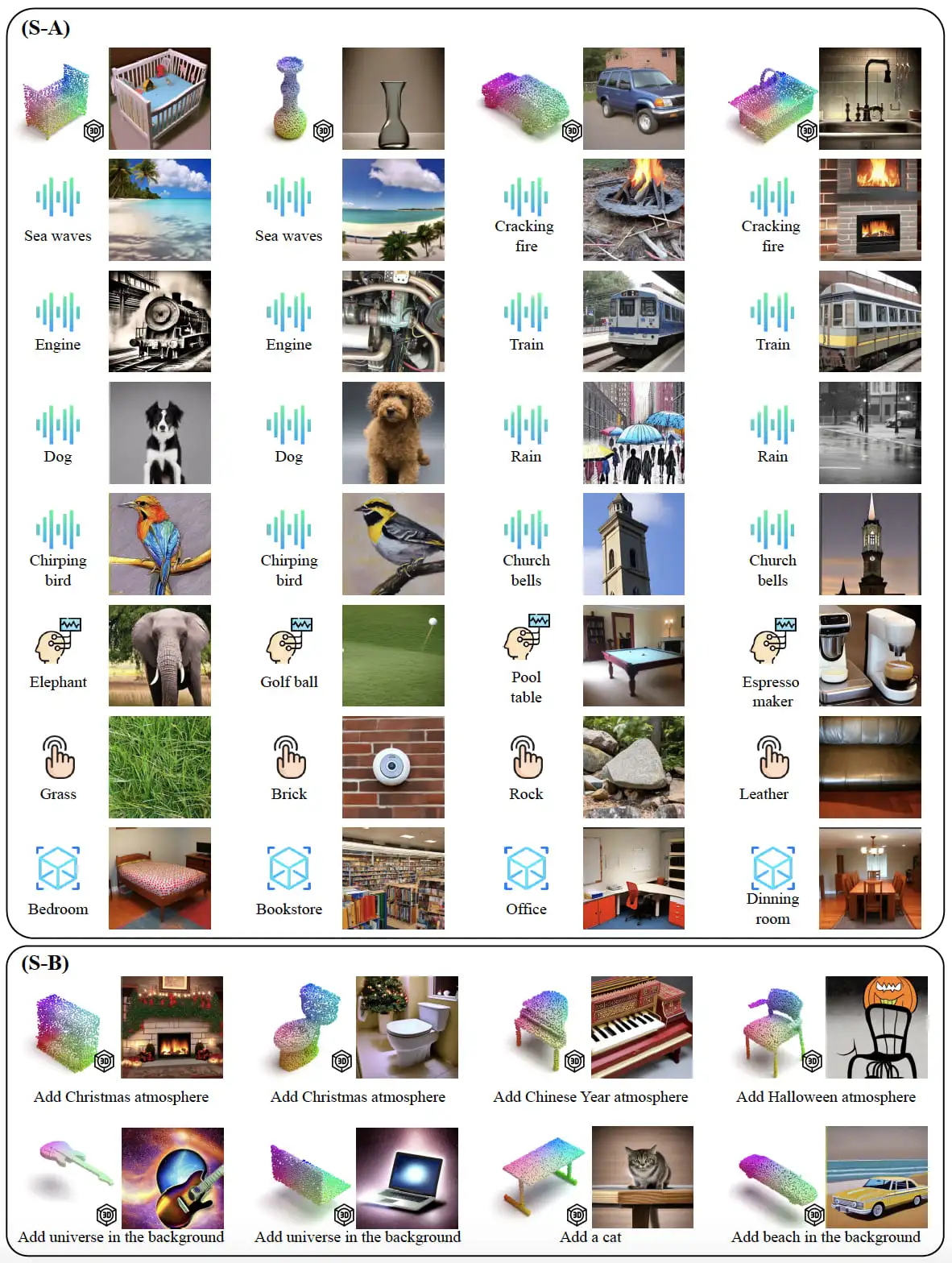

ViT-Lens还能与其他工作联动,为多模态数据在室内场景中的语义搜索提供可能。比如,听到马桶冲水声音信号,系统能迅速定位到马桶位置。
05. 全面开源
ViT-Lens项目已全面开源,包括训练代码、推理代码和模型。我们将持续更新更多模型和在线demo供大家探索。此外,开源的ViT-Lens提供了一键替换ImageBind的接口,感兴趣的小伙伴可以尝试使用!
更多细节请看 GitHub - TencentARC/ViT-Lens: [Preprint] ViT-Lens: Towards Omni-modal Representations
06. 结语
ViT-Lens提出了一种普适的多模态表征学习方法,充分利用预训练模型的丰富知识,提高模型性能。ViT-Lens展示了在多种模态理解任务上的显著提升,并将图文多模态大模型的能力扩展到了各种模态。让我们期待ViT-Lens为全模态智能发展注入新的活力,并启发更多创新研究和应用!
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区