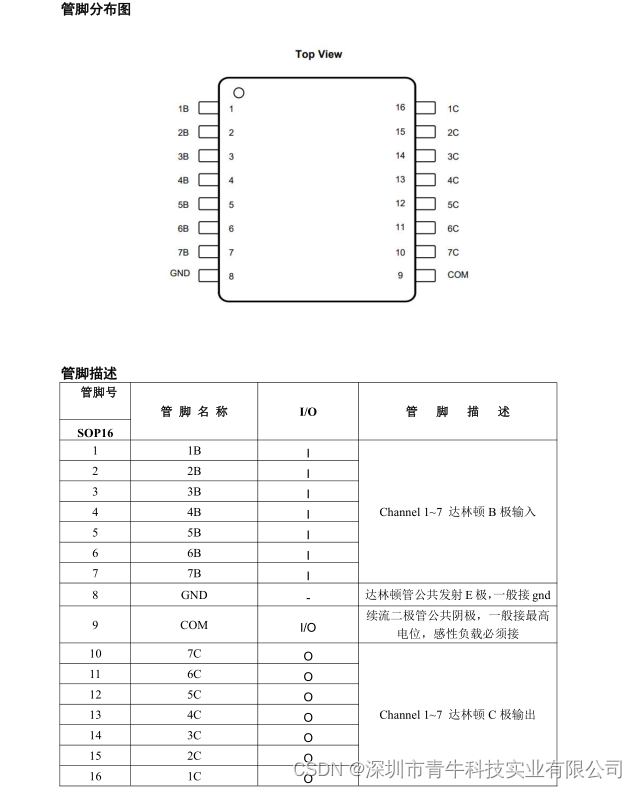
逻辑回归的损失函数
线性回归的损失函数是平方损失。逻辑回归的损失函数是对数损失,定义如下:
L o g L o s s = ∑ ( x , y ) ∈ D − y log ( y ′ ) − ( 1 − y ) log ( 1 − y ′ ) LogLoss=\sum_{(x,y)\in D}-y\log(y')-(1-y)\log(1-y') LogLoss=(x,y)∈D∑−ylog(y′)−(1−y)log(1−y′)
其中:
- ( x , y ) ∈ D (x,y)\in D (x,y)∈D 是包含许多有标签样本(即成对数据集)的数据集。 ( x , y ) ∈ D (x,y)\in D (x,y)∈D
-
y
y
y是有标签样本中的标签。由于这是逻辑回归,因此
的每个 y y y值都必须是 0 或 1。 - y ′ y' y′是针对 x x x中的一组特征的预测值(介于 0 和 1 之间)。
逻辑回归中的正则化
正则化在逻辑回归建模中极其重要。如果不进行正则化,高逻辑维度下的逻辑回归的渐近性会不断促使损失接近 0。因此,大多数逻辑回归模型都使用以下两种策略之一来降低模型复杂性:
- L2 正则化。
- 早停法,即限制训练步数或学习速率。
(我们将在后续中讨论第三个策略,即 L1 正则化。)
假设您为每个示例分配一个唯一 ID,并将每个 ID 映射到其自己的特征。如果您不指定正则化函数,模型将完全过拟合。这是因为模型会尝试在所有样本上将损失降低为零,并且永远无法实现,从而将每个指示器特征的权重提高至 +无穷大或-无穷大。当有大量罕见的交叉时,仅在一个样本上发生,就会出现包含特征组合的高维度数据。
幸运的是,使用 L 2 L_2 L2或早停法可以防止此问题出现。
AI插图

这是对逻辑回归中对数损失函数的可视化。图中展示了两条曲线:一条表示当预测值接近实际值时的损失,另一条表示当预测值远离实际值时的损失。X轴代表预测概率,Y轴代表损失。不同颜色的曲线和图例有助于区分这两种情况。
接下来,我将生成展示正则化效果的图像。