### 知识点1:读取网络数据
- 客户端发送给服务器的通信数据通过封装的bufferSocketRead函数读取
- 读取的数据存储在struct Buffer结构体实例中,可将该实例作为参数传递给解析函数
回顾Buffer.c中的bufferSocketRead函数
// 写内存 2.接收套接字数据
int bufferSocketRead(struct Buffer* buf,int fd) {
struct iovec vec[2]; // 根据自己的实际需求
// 初始化数组元素
int writeableSize = bufferWriteableSize(buf); // 得到剩余的可写的内存容量
// 0号数组里的指针指向buf里边的数组,记得 要加writePos,防止覆盖数据
vec[0].iov_base = buf->data + buf->writePos;
vec[0].iov_len = writeableSize;
char* tmpbuf = (char*)malloc(40960); // 申请40k堆内存
vec[1].iov_base = buf->data + buf->writePos;
vec[1].iov_len = 40960;
// 至此,结构体vec的两个元素分别初始化完之后就可以调用接收数据的函数了
int result = readv(fd, vec, 2);// 表示通过调用readv函数一共接收了多少个字节
if(result == -1) {
return -1;// 失败了
}
else if (result <= writeableSize) {
buf->writePos += result;
}
else {
buf->writePos = buf->capacity; // 需要先更新buf->writePos
bufferAppendData(buf, tmpbuf, result - writeableSize);
}
free(tmpbuf);
return result;
}### 知识点2:从Buffer中读取请求行
- 需要编写一个操作函数,根据换行符(\r\n)从buffer中提取一行数据
- memem函数应返回找到的子数据块在内存中的起始位置----注意数据块的大小,并在函数中指定
一、解析请求行(通过指针方式解析非 sscanf 方式)
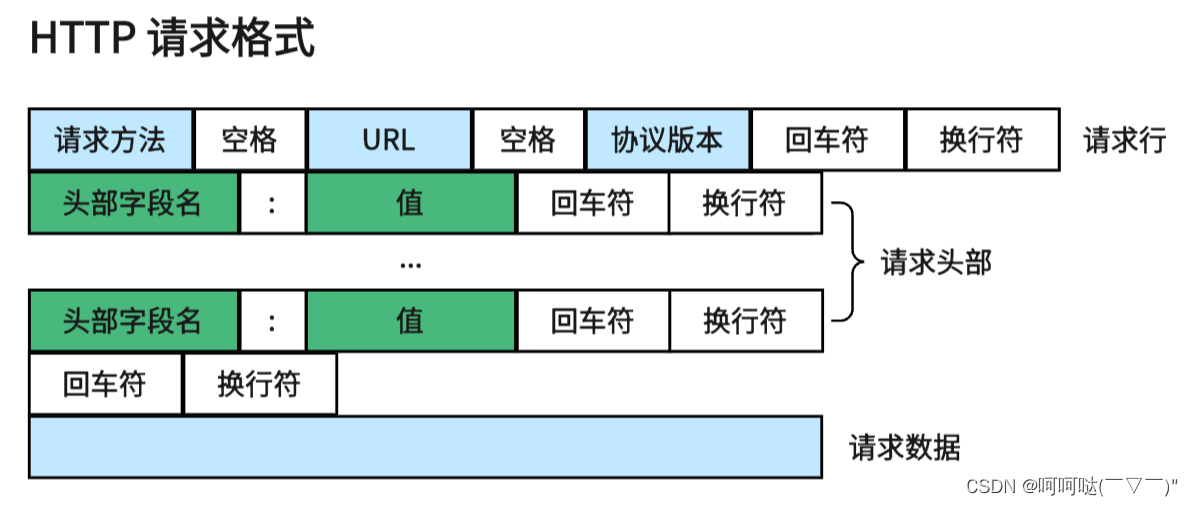
GET / HTTP/1.1
Host: www.baidu.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:86.0) Gecko/20100101 Firefox/86.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,/;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Cookie: BAIDUID=6729CB682DADC2CF738F533E35162D98:FG=1;
BIDUPSID=6729CB682DADC2CFE015A8099199557E; PSTM=1614320692; BD_UPN=13314752;
BDORZ=FFFB88E999055A3F8A630C64834BD6D0;
__yjs_duid=1_d05d52b14af4a339210722080a668ec21614320694782; BD_HOME=1;
H_PS_PSSID=33514_33257_33273_31660_33570_26350;
BA_HECTOR=8h2001alag0lag85nk1g3hcm60q
Upgrade-Insecure-Requests: 1
Cache-Control: max-age=0
空行
请求数据为空>>http get请求报文的格式
请求行\r\n
请求头\r\n
空行(\r\n)
提示: 每项信息之间都需要一个\r\n,是由http协议规定
************************************************
************************************************
>>http post请求报文的格式
请求行\r\n
请求头\r\n
空行(\r\n)
请求体
提示: 请求体就是浏览器发送给服务器的数据>>提取请求行
(1)在Buffer.h新增一个函数,叫 bufferFindCRLF函数,其功能是:根据\r\n取出一行,找到其在数据块中的位置,返回该位置
// 根据\r\n取出一行,找到其在数据块中的位置,返回该位置
char* bufferFindCRLF(struct Buffer* buf);// CRLF表示\r\n
char* bufferFindCRLF(struct Buffer* buf) {
// strstr --> 从大字符串中去匹配子字符串(遇到\0结束)
// memmem --> 从大数据块中去匹配子数据块(需要指定数据块大小)
char* ptr = memmem(buf->data + buf->readPos,bufferReadableSize(buf),"\r\n",2);
return ptr;
}(2)HttpRequest.h 新增一个函数,叫 parseHttpRequestLine函数,用于解析请求行

// 解析请求行
bool parseHttpRequestLine(struct HttpRequest* req,struct Buffer* readBuf);// 解析请求行
bool parseHttpRequestLine(struct HttpRequest* req,struct Buffer* readBuf) {
// 读取请求行
char* end = bufferFindCRLF(readBuf);
// 保存字符串起始位置
char* start = readBuf->data + readBuf->readPos;
// 保存字符串结束地址
int lineSize = end - start;
if(lineSize>0) {
// get /xxx/xx.txt http/1.1
// 请求方式
char* space = memmem(start,lineSize," ",1);
assert(space!=NULL);
int methodSize = space - start;
req->method = (char*)malloc(methodSize + 1);
strncpy(req->method,start,methodSize);
req->method[methodSize] = '\0';
// 请求静态资源
start = space + 1;
space = memmem(start,end-start," ",1);
assert(space!=NULL);
int urlSize = space - start;
req->url = (char*)malloc(urlSize + 1);
strncpy(req->url,start,urlSize);
req->url[urlSize] = '\0';
// http 版本
start = space + 1;
req->version = (char*)malloc(end-start + 1);
strncpy(req->version,start,end-start);
req->version[end-start] = '\0';
// 解析请求行完毕,为解析请求头做准备
readBuf->readPos += lineSize;
readBuf->readPos += 2;
// 修改状态 解析请求头
req->curState = ParseReqHeaders;
return true;
}
retrun false;
}二、优化解析请求行代码
如果想要在一个函数里边给外部的一级指针分配一块内存,那么需要把外部的一级指针的地址传递给函数。外部的一级指针的地址也就是二级指针,把二级指针传进来之后,对它进行解引用,让其指向我们申请的一块堆内存,就可以实现外部的一级指针被初始化了,也就分配到了一块内存
- 注意:传入指针的地址(二级指针),这个函数涉及给指针分配一块内存,指针在作为参数的时候会产生一个副本
- 而把指针的地址作为参数传入不会产生副本
char* splitRequestLine(const char* start,const char* end,const char* sub,char** ptr) {
char* space = (char*)end;
if(sub != NULL) {
space = memmem(start,end-start,sub,strlen(sub));
assert(space!=NULL);
}
int length = space - start;
char* tmp = (char*)malloc(length+1);
strncpy(tmp,start,length);
tmp[length] = '\0';
*ptr = tmp;// 对ptr进行解引用=>*ptr(一级指针),让其指向tmp指针指向的地址
return space+1;
}// 解析请求行
bool parseHttpRequestLine(struct HttpRequest* req,struct Buffer* readBuf) {
// 读取请求行
char* end = bufferFindCRLF(readBuf);
// 保存字符串起始位置
char* start = readBuf->data + readBuf->readPos;
// 保存字符串结束地址
int lineSize = end - start;
if(lineSize>0) {
start = splitRequestLine(start,end," ",&req->method);// 请求方式
start = splitRequestLine(start,end," ",&req->url);// url资源
splitRequestLine(start,end,NULL,&req->version);// 版本
#if 0
// get /xxx/xx.txt http/1.1
// 请求方式
char* space = memmem(start,lineSize," ",1);
assert(space!=NULL);
int methodSize = space - start;
req->method = (char*)malloc(methodSize + 1);
strncpy(req->method,start,methodSize);
req->method[methodSize] = '\0';
// 请求静态资源
start = space + 1;
space = memmem(start,end-start," ",1);
assert(space!=NULL);
int urlSize = space - start;
req->url = (char*)malloc(urlSize + 1);
strncpy(req->url,start,urlSize);
req->url[urlSize] = '\0';
// http 版本
start = space + 1;
req->version = (char*)malloc(end-start + 1);
strncpy(req->version,start,end-start);
req->version[end-start] = '\0';
#endif
// 为解析请求头做准备
readBuf->readPos += lineSize;
readBuf->readPos += 2;
// 修改状态
req->curState = ParseReqHeaders;
return true;
}
return false;
}三、解析请求头并存储
### 解析请求头数据
1.数据存储在对应的Buffer结构内存块中。解析时,需要将readPos更新到请求头的起始位置parseHttpRequestLine函数中已经为解析请求头做好了准备。
- 回顾一下parseHttpRequestLine函数:
bool parseHttpRequestLine(struct HttpRequest* request, struct Buffer* readBuf) {
...
if (lineSize>0)
{
start = splitRequestLine(start, end, " ", &request->method);
start = splitRequestLine(start, end, " ", &request->url);
splitRequestLine(start, end, NULL, &request->version);
// 为解析请求头做准备
readBuf->readPos += lineSize;
readBuf->readPos += 2;
// 修改状态
request->curState = ParseReqHeaders;
return true;
}
return false;
}2.请求头的每行为一对键值对,包含一个key值和一个value值
3.将数据行存储到堆内存中,并将堆内存地址传递给httpRequestAddHeader函数
- 回顾一下httpRequestAddHeader函数:
void httpRequestAddHeader(struct HttpRequest* request, const char* key, const char* value) {
request->reqHeaders[request->reqHeadersNum].key = (char*)key;
request->reqHeaders[request->reqHeadersNum].value = (char*)value;
request->reqHeadersNum++;
}### 解析请求头数据 该函数处理请求头中的一行

- 标准HTTP协议中,键值和值之间使用冒号分隔,冒号后有一个空格
- 使用memem函数检查中间指针是否指向冒号
// 解析请求头
bool parseHttpRequestHeader(struct HttpRequest* req,struct Buffer* readBuf);// 该函数处理请求头中的一行
bool parseHttpRequestHeader(struct HttpRequest* req,struct Buffer* readBuf) {
char* end = bufferFindCRLF(readBuf);
if(end!=NULL) {
char* start = readBuf->data + readBuf->readPos;
int lineSize = end - start;
// 基于: 搜索字符串
char* middle = memmem(start,lineSize,": ",2);
if(middle!=NULL) {
// 拿出键值对
char* key = malloc(middle - start + 1);
strncpy(key,start,middle - start);
key[middle - start] = '\0';// 获得key
char* value = malloc(end - middle - 2 + 1);// end-(middle+2) + 1 = end - middle - 2 + 1
strncpy(value,middle+2,end - middle - 2);
value[end - middle - 2] = '\0';// 获得value
httpRequestAddHeader(req,key,value);// 添加键值对
// 移动读数据的位置
readBuf->readPos += lineSize;
readBuf->readPos += 2;
}
else {
// 请求头被解析完了,跳过空行
readBuf->readPos += 2;
// 修改解析状态
// 本项目忽略 post 请求,按照 get 请求处理
req->curState = ParseReqDone;
}
return true;
}
return false;
}## 注意事项
总结提取请求行 和 解析请求行和优化 这篇博客和 本文需要注意的细节如下:
- 在解析请求行和头部时,需要提供相应的解析函数
- 解析函数应返回布尔值,表示解析是否成功
- 在读取网络数据时,需要使用封装的bufferSocketRead函数来读取数据
- 读取的数据存储在struct Buffer结构体实例中,该实例作为参数传递给解析函数