数据库期末复习重点总结
本文为总结,如有不对的地方请指针
第2章 关系模型的介绍
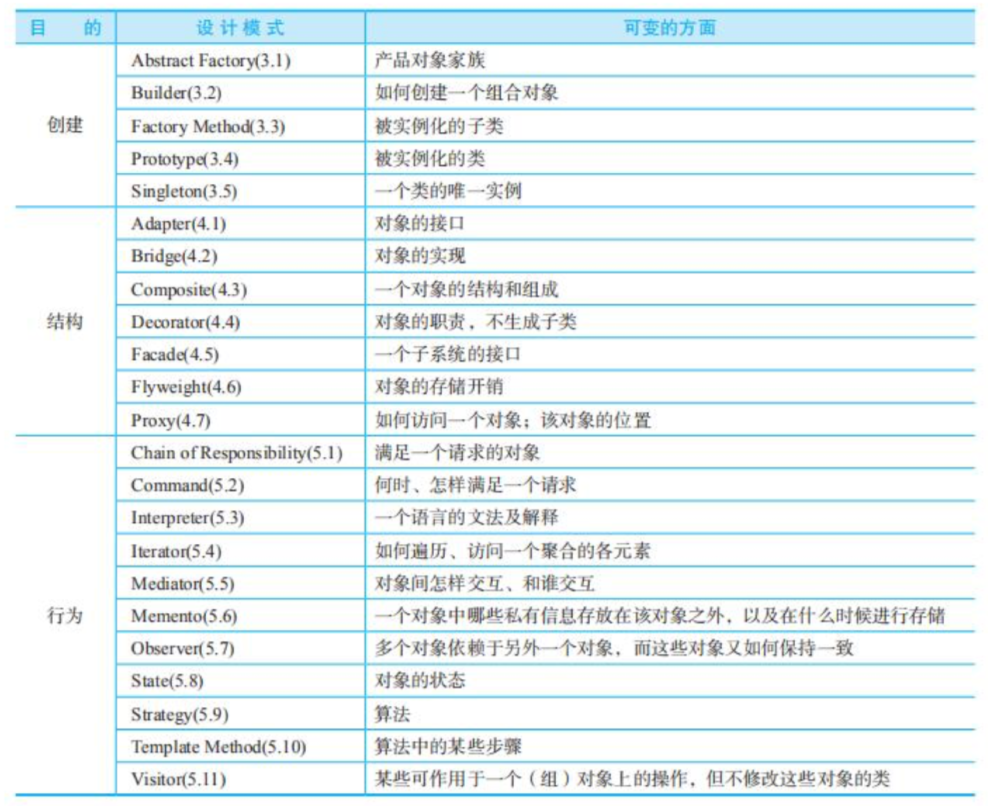
| 名称 | 符号 |
|---|---|
| 选择 | σ |
| 投影 | ∏ |
| 笛卡儿积 | × |
| 连接 |  |
| 并 | ∪ |
| 集差 | - |
| 交 | ∩ |
| 赋值 | <- |
| 更名 | ρ |
除操作
设R和S除运算的结果为T,则T包含所有在R中但不在S中的属性和值,且T的元组与S的元组经过组合均能出现在R中

R÷S的结果只能有A,然后T中的A的元素与S中的BC组合之后全部能在 R中出现,在R中a2虽然出现了b2c3,但是a2b1c2并没有在R中出现,其他同理。
除运算(求满足某属性全部值的其他属性)
这种题是指求是满足B表中某属性全部值的在A表上的其他属性。这是除运算的特性,因此再出现“全部”时,需要用除运算完成。通常分别对A和B做投影,再对生成的子表进行除运算。
例如A表为学生选课表(属性包括学号和所选的课程),B表为课程信息表(属性包括课程),求选了全部课程的学生学号。全部课程只在B表出现,学号只在A表出现。所以选了全部课程的学生学号的结果为Π学号、课程(A) ÷ Π课程(B)
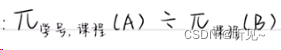
相当于:全选的人=全部人-未全选的人 ,未全选的人=(所有选课的可能-已选课程)提出人名。
第3章 SQL介绍
union 并
intersect 交
except 用于再两个查询结果之间取差集
distinct 去除重复的行
约束
--主码约束 constraint 约束名字 primary key (作为主码的属性) --外码约束 constraint 约束名 foreign key (约束的列) references 目标表(目标表的属性)
all
ALL 是一个用于比较的关键字,通常用在子查询中。ALL 用于与比较运算符一起使用,例如 =ALL、<ALL、>ALL 等。
ALL 关键字的一般语法如下:
sqlCopy codeSELECT column1, column2 FROM table_name WHERE column_name comparison_operator ALL (SELECT column_name FROM another_table WHERE condition);
这里是一个简单的例子:
sqlCopy codeSELECT employee_id, salary FROM employees WHERE salary > ALL (SELECT salary FROM employees WHERE department_id = 10);
上述查询返回了在部门 10 中工资高于该部门所有其他员工的员工信息。在这个例子中,> ALL 表示比较左侧的值是否大于子查询中所有的值。
需要注意的是,ALL 关键字的使用需要谨慎,因为它要求比较的值要满足条件与子查询中的所有值都比较为真。如果子查询返回空集,那么 ALL 将始终返回 TRUE。
EXISTS:
-
EXISTS用于检查子查询是否返回任何行。如果子查询返回至少一行记录,则EXISTS返回TRUE,否则返回FALSE。 -
语法:
sqlCopy codeSELECT column1, column2, ... FROM table1 WHERE EXISTS (SELECT column_name FROM table2 WHERE condition);
-
示例:选择所有有订单的客户。
sqlCopy codeSELECT customer_id, customer_name FROM customers WHERE EXISTS (SELECT 1 FROM orders WHERE orders.customer_id = customers.customer_id);
NOT EXISTS:
-
NOT EXISTS是EXISTS的反义词,它检查子查询是否不返回任何行。如果子查询返回零行,则NOT EXISTS返回TRUE,否则返回FALSE。 -
语法:
sqlCopy codeSELECT column1, column2, ... FROM table1 WHERE NOT EXISTS (SELECT column_name FROM table2 WHERE condition);
-
示例:选择所有没有订单的客户。
sqlCopy codeSELECT customer_id, customer_name FROM customers WHERE NOT EXISTS (SELECT 1 FROM orders WHERE orders.customer_id = customers.cust
第4章 中级SQL
自然连接
匹配多个表列名相同的列
natural join
内连接
根据某个属性连接,没有匹配的不显示
inner join 表名 on 属性1=属性2
外连接
--左连接,左边的表没有匹配的也显示,那一行右边表的属性显示为空 left outer join 表名 on 属性1=属性2 --右连接,右边的表没有匹配的也显示,那一行左边表的属性显示为空 right outer join 表名 on 属性1=属性2 --全连接,没有匹配的也显示,没有匹配的属性显示空 full outer join 表名 on 属性1=属性2
第5章 高级SQL
SQL函数:
-
定义: SQL函数是一种返回单一值的数据库对象,它接受零个或多个参数作为输入,并根据这些参数执行某种操作并返回结果。
-
用途: SQL函数通常用于执行特定的计算或操作,如字符串处理、数学运算等。常见的SQL函数包括SUM、AVG、MAX、MIN等聚合函数,以及字符串函数和日期函数等。
-
调用: SQL函数可以嵌套在查询语句中,也可以通过SELECT语句单独调用。任何具有适当权限的用户都可以调用SQL函数。
例
用SQL定义一个函数并调用
-- 定义函数 create function dept_count(dept_name varchar(20)) return integer begin declare d_count integer; select count(*) into d_count from instructor where instructor.dept_name = dept_name return d_count; end -- 调用函数 select dept_name, budget from department where dept_count(dept_name)>12表函数:以表作为返回结果,引用函数的参数时要加上函数名作为前缀(instructor_of.dept_name)
-- 定义表函数 create function instructor_of(dept_name varchar(20)) return table( ID varchar(5), name varchar(20), dept_name varchar(20), salary numeric(8,2) ) return table (selct ID, name, dept_name, salary from instructor where instructor.dept_name = instructor_of.dept_name); -- 调用表函数 select * from table(instructor_of('Finance');
存储过程:
-
定义: 存储过程是一组SQL语句的集合,被存储在数据库中以供重复使用。存储过程可以接受输入参数,执行一系列操作,并返回结果,也可以包含控制结构(如条件语句和循环)。
-
用途: 存储过程通常用于执行复杂的业务逻辑,事务管理,以及需要在数据库服务器上运行的一系列操作。
-
调用: 存储过程可以被其他SQL语句调用,也可以通过应用程序或脚本调用。调用存储过程的用户需要有执行该过程的权限。
例
-- 将上面的dept_count写成过程
create procedure dept_count_proc(in dept_name varchar(20), out d_count integer)
begin
select count(*) into d_count
from instructor
where instructor.dept_name = dept_count_proc.dept_name
end
-- 使用call调用过程
declare dept_count integer;
call dept_count_proc('Phtsics', d_count);
关键字in表示待 赋值的参数,out表示未来返回结果而存在过程中设置的参数。
过程可以重名,只要保证参数不一样即可(数量或者类型)
过程和函数的语言结构
-
declare声明变量,变量可以是任意合法的sql数据类型。使用set语句可以进行赋值。
-
begin...end,使用在复合语句,begin和end之间可以包含多条sql语句。
-
循环
-- while循环 while 布尔表达式 do 语句序列; end while -- repeat循环 repeat 语句序列 until 布尔表达式 end repeat -- for循环 declare n integer default 0; for r as select budget from department where dept_name = 'Music' do set n = n-r.budget end for -- leave语句可以用来退出循环(break),iteare用来跳过循环剩余语句(continue) -
条件表达式
if 布尔表达式 then 语句或者复合语句 elseif 布尔表达式 then 语句或者复合语句 else 语句或复合语句 end if
触发器
触发器是作为数据库修改的连带效果而由系统自动执行的一条语句。为了定义一个触发器,我们必须:
-
指明什么时候执行触发器。这被拆分为引起触发器被检测的一个事件和触发器继续执行所必须满足的一个条件。
-
知名触发器执行时所采取的动作。
一旦我们把出一个触发器输入到数据库中只要发生指定的事件并且满足相应的条件,数据库系统就负责执行它。
create trigger 触发器名字 after/before insert/update/delete on 表明 referencing new row as nrow referencing old row as orow for each row when 判断条件 begin atomic 。。。语句 end;
第6章 数据库-ER图
实体集
-
说明:实体集用分割矩形框,上面是实体名,下面是属性(主键要用下划线标志出来)。
-
解释: 代表数据库中的实体或表。
-
例子: 如果你正在设计一个大学据库,可能会有一个实体表示“学生“;该实体的属性可以包括id、姓名、tot_cred等。

联系集
-
说明:关系用菱形来表示,里面可以写上关系的名
-
解释: 代表实体之间的关系。
-
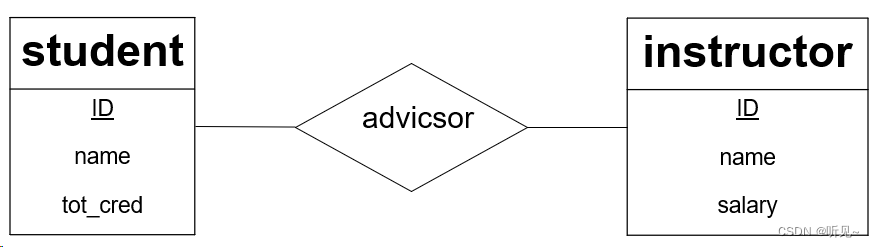
例子: 如果有一个关系表示“指导”,连接两个实体,“学生”和“教师”,那么这个菱形可以表示教师指导学生的关系(advicsor联系集)。
角色
在关系中,每个实体都可以扮演不同的角色。角色定义了实体在特定关系中的功能或地位。例如,在一个"雇佣"关系中,"雇主"和"雇员"是两个实体,分别扮演不同的角色。
在现实中同样的实体集也肯能以不同的角色多次参与这个联系集。例如在大学中开设的所有课程(course)实体集。我们用course实体的有序对来建模联系集prereq(表示一门课程是另一门课程的先修课)。
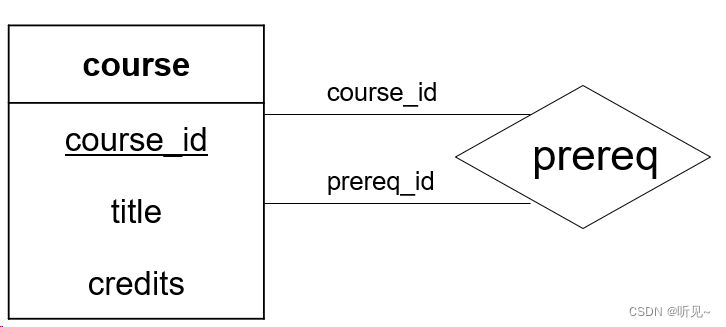
描述属性
-
符号: 未分割的矩形
-
解释: 代表属性,即联系集的特征或信息。
-
例子: section(开课)和student实体集之间的takes(选课)联系集,grade(成绩)作为描述属性附加到takes上
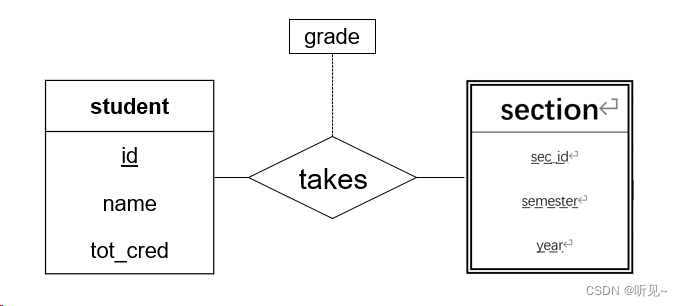
映射基数
联系基数
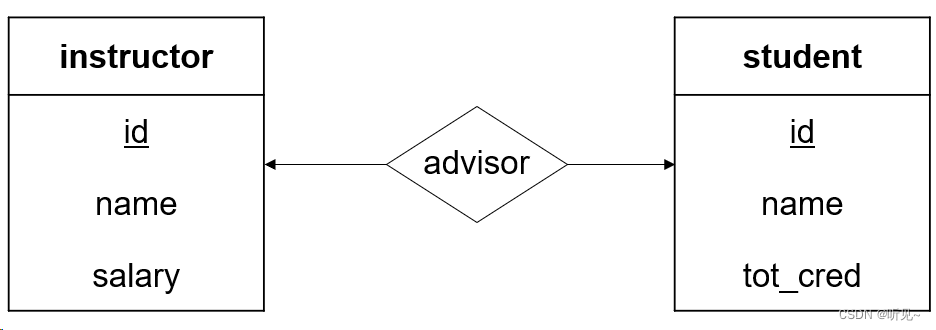
一对一:
一位教师最多指导一位学生,一位学生最多有一位指导教师
一对多:
一位教师可以指导多位学生,一位学生最多有一位指导教师
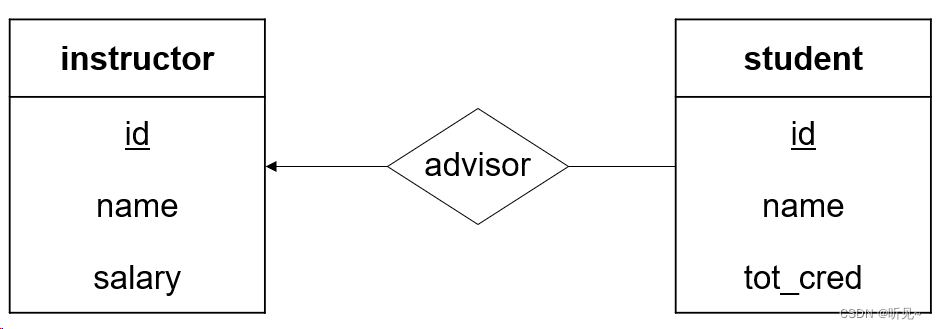
多对一:
一位教师最多指导一位学生,一位学生可以有多位指导教师

多对多
一位教师可以指导多位学生,一位学生可以有多位指导教师
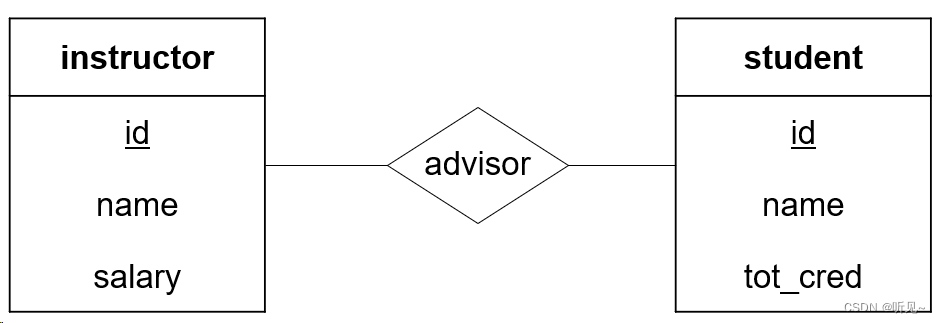
全部参与
用双线来表示,多对一的有箭头的也可以用双线。
例如:一所大学要求每名学生至少有一位导师,这就要求每个student全部参与advisor。

联系集上的基数限制
数量的另一种表示方式,x..y(表示最小是为x,最大值为y,*表示无穷)
例如,教师可以指导任意数量的学生也可以不指导,但是每一名学生必须至少有一名指导教师

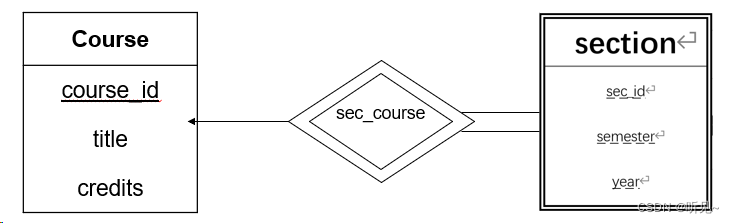
弱实体集
弱实体集的存在依赖另一个实体集。非弱实体集被称为强实体集。
通过双框的矩形描述弱实体集,其分辨符北加上虚的下划线,关联弱实体集和标识性强实体集的联系集以双边框的菱形表示。
例如,在大学数据库。section(开课)实体集依赖于course(课程)实体集,则section就是弱实体集。
第7章 关系数据库设计
分解(Decomposition):
分解是指将一个复杂的关系或表拆分成更小、更简单的关系或表的过程。这通常是为了提高数据库设计的规范性、减少冗余、遵循范式等原则。在关系型数据库中,有三种主要的范式,即第一范式(1NF)、第二范式(2NF)和第三范式(3NF)。分解过程有助于满足这些范式的要求。
-
第一范式(1NF)要求每个数据项都是不可再分的原子值。
-
第二范式(2NF)要求表中的非主键属性完全依赖于整个主键。
-
第三范式(3NF)要求表中的非主键属性不传递依赖于主键。
通过分解,可以消除数据中的冗余,提高数据的一致性和可维护性。
无损分解(Lossless Decomposition):
无损分解是指将一个关系模式分解成多个关系模式的过程,然后通过连接(Join)操作将它们重新组合时,能够恢复原始关系模式的过程。在无损分解中,不会丢失任何原始关系中的信息。
无损分解的一个例子是BCNF(Boyce-Codd Normal Form)分解。在BCNF分解中,确保每个关系都符合BCNF,并且通过连接这些关系可以重新构建原始关系。这有助于避免数据的丢失和信息不一致。
判断无损分解:R1∩R2 -> R1 或者 R1∩R2 -> R2 则是无损分解
范式
-
第一范式(1NF):
-
要求每个关系表中的每一列都包含不可再分的原子值。这意味着表中的每个单元格应该只包含一个值,而不是包含多个值的集合或列表。
-
-
第二范式(2NF):
-
在满足第一范式的基础上,第二范式要求每个非主键属性完全依赖于整个主键,而不是仅依赖于主键的一部分。这有助于消除部分依赖。
-
判断2NF:非主属性完全依赖主属性
例(A,B,C){A→C}
候选码为{(A,B)},AB是主属性,A→C部分依赖主属性,所以不满足2nf
-
-
第三范式(3NF):
-
在满足第二范式的基础上,第三范式要求非主键属性之间不能存在传递依赖关系。即,非主键属性不能依赖于其他非主键属性。这有助于进一步减少冗余和提高数据的一致性。
-
判断3NF:依赖必须在候选码中
例(A,B,C){A→B,B→C}
候选码{(A)},依赖B→C,其中依赖的左半部分不在候选码中,所以不满足3NF
-
-
Boyce-Codd范式(BCNF):
-
BCNF是一种更严格的范式,它要求每个非主键属性都完全依赖于候选键,而不仅仅是主键。这意味着在一个关系中,如果存在多个候选键,每个非主键属性都必须完全依赖于每个候选键。
-
判断BCNF:依赖必须是超码(超码是指,能够退出全部属性的码,不是最小的也可以)
例 (ABC){AB → C, C → B}
候选码为{(AB),(AC)}
AB → C,AB在候选码中满足3nf
C → B,C在候选码中满足3nf
AB → C,AB是超码满足bcnf
C → B,C在不是超码不满足bcnf
即该例子满足3nf,但是不满足bcnf。
-
例 考虑一个图书馆数据库,其中有一个包含图书信息的关系表。这个表包含以下列:
-
书籍编号(BookID,主键)
-
书名(Title)
-
作者(Author)
-
出版社(Publisher)
-
类别(Category)
初始表设计:
| BookID | Title | Author | Publisher | Category | |--------|----------------|----------------|--------------|---------------| | 1 | "Book1" | "Author1" | "Publisher1" | "Fiction" | | 2 | "Book2" | "Author2" | "Publisher2" | "Non-Fiction" | | 3 | "Book3" | "Author1" | "Publisher1" | "Fiction" |
问题: 这个表可能存在一些冗余,因为同一作者或同一出版社的信息在多个地方重复出现。现在,我们来看看如何将它规范化到不同的范式。
-
第一范式(1NF): 确保每个单元格只包含一个值。上述表已经满足1NF,因为每个单元格只包含一个原子值。
-
第二范式(2NF): 确保非主键属性完全依赖于整个主键。在这个例子中,主键是BookID。由于所有列都完全依赖于BookID,表已经满足2NF。
-
第三范式(3NF): 确保非主键属性之间没有传递依赖关系。在这个例子中,Category依赖于Title,而Title又依赖于BookID。我们可以将Category移至一个独立的表,其中Category和BookID构成一个新的关系,从而满足3NF。
新的设计:
| BookID | Title | Author | Publisher | |--------|----------------|----------------|--------------| | 1 | "Book1" | "Author1" | "Publisher1" | | 2 | "Book2" | "Author2" | "Publisher2" | | 3 | "Book3" | "Author1" | "Publisher1" |
| BookID | Category | |--------|---------------| | 1 | "Fiction" | | 2 | "Non-Fiction" | | 3 | "Fiction" |
-
Boyce-Codd范式(BCNF): 在这个例子中,BCNF不会引入新的变化,因为每个非主键属性都已经完全依赖于候选键。
第18章 并发控制
锁
共享锁
lock_S(A) 申请对事务A的读权限,一个事务申请对A的共享锁后其他事务可以申请对A的共享锁,不能申请排它锁。
排它锁
lock_X(A) 申请对事物A的读写全写,一个事务申请对A的排它锁后其他事务不能申请对A的任何锁 。
两段锁协议
Growing Phase(增长阶段)和 Shrinking Phase(缩减阶段)。
即申请阶段和释放阶段,完成一个事务在是申请锁在同一个阶段,释放锁在同一个阶段。
所以是释放一个锁以后就不能再申请锁了。
可串行化
即多个并发执行的事务可以转化为一个执行完成再执行下一个的串行化操作。
| T1 | T2 | |-------------------|-------------------| | read(A) | | | | read(B) | | | read(A) | | read(B) | | | if A=0 then B=B+1 | | | write(B) | |
对上面的两个并发执行的事务,进行串行化
首先要是串行化的方案为T1再T2:
未完成待写。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
例题 事务和锁
考虑如下两个事务:
//T31 read(A) read(B) if A=0 then B:=B+1 write(B)
//T32 read(B) read(A) if B=0 then A:=A+1 write(A)
假定A和B的初始状态为0,一致性需求为A=0∪B=0。
(1)请分析T31和T32的串行执行如何保持了数据库的一致性。
(2)请给出T31和T32的一次并发执行,它产生了不可串行化的调度。
(3)为这两个事务加上锁和解锁指令,使两个事务遵从两段锁协议。
(4)这两个事务能产生死锁吗?给出理由。
答:
(1)请分析T31和T32的串行执行如何保持了数据库的一致性。
如果先执行T31再执行T32 结果为:A=0,B=1 满足一致性需求A=0或B=0。
如果先执行T32再执行T31 结果为:A=1,B=0 满足一致性需求A=0或B=0。
(2)请给出T31和T32的一次并发执行,它产生了不可串行化的调度。
| T31 | T32 | |-------------------|-------------------| | read(A) | | | | read(B) | | | read(A) | | read(B) | | | if A=0 then B=B+1 | | | | if B=0 then A=A+1 | | | write(A) | | write(B) | |
上面的并行执行不可串行化。
如果要化成先执行T31再T32 , T32的read(A) 、if B=0 then A=A+1、write(A)都可以放在T31的write(B)后执行 , 但T32的read(B)缺无法放到T31的write(B)的后面,因为读写同一变量交换可能会改变结果。
同理先执行T32再T31也不行
(3)为这两个事务加上锁和解锁指令,使两个事务遵从两段锁协议。
//T31 lock_S(A) read(A) lock_X(B) read(B) if A=0 then B:=B+1 write(B) unlock(A) unlock(B)
//T32 lock_S(B) read(B) lock_X(A) read(A) if B=0 then A:=A+1 write(A) unlock(B) unlock(A)
(4)这两个事务能产生死锁吗?给出理由。
会产生死锁
| T31 | T32 | |-------------|-------------| | lock_S(A) | | | read(A) | | | | lock_S(B) | | | read(B) | | | lock_X(A) | | | read(A) | | lock_X(B) | | | read(B) | |
T31锁定了资源A (lock_S(A)),并且正在读取A (read(A))。
同时,T32锁定了资源B (lock_S(B)),并且正在读取B (read(B))。
接下来,T32请求对资源A的独占锁 (lock_X(A))。
在此时,T31请求对资源B的独占锁 (lock_X(B))。
这里存在死锁情况,因为T31持有资源A的共享锁,同时等待资源B的独占锁,而T32持有资源B的共享锁,同时等待资源A的独占锁。两个事务将相互等待对方释放锁,导致死锁。