逻辑执行图
-
明确逻辑计划的边界
在 Action 调用之前,会生成一系列的RDD,这些RDD之间的关系,其实就是整个逻辑计划
val conf= new SparkConf().setMaster("local[6]").setAppName("wordCount_source") val sc= new SparkContext(conf) val textRDD=sc.parallelize(Seq("Hadoop Spark", "Hadoop Flume", "Spark Sqoop")) val splitRDD=textRDD.flatMap(_.split(" ")) val tupleRDD=splitRDD.map((_, 1)) val reduceRDD=tupleRDD.reduceByKey(_ + _) val strRDD=reduceRDD.map(item => s"${item._1},${item._2}") println(strRDD.toDebugString) strRDD.collect.foreach(item =>println(item))例如上述代码,如果生成逻辑计划的,会生成效如下一些RDD,这些RDD是相互关联的,这些RDD之间,其实本质上生成的就是一个 计算链

接下来, 采用迭代渐进式的方式, 一步一步的查看一下整体上的生成过程
-
RDD 如何生成
-
**textFile算子的背后**研究
RDD的功能或者表现的时候, 其实本质上研究的就是RDD中的五大属性, 因为RDD透过五大属性来提供功能和表现, 所以如果要研究textFile这个算子, 应该从五大属性着手, 那么第一步就要看看生成的RDD是什么类型的RDD-
**textFile生成的是HadoopRDD**
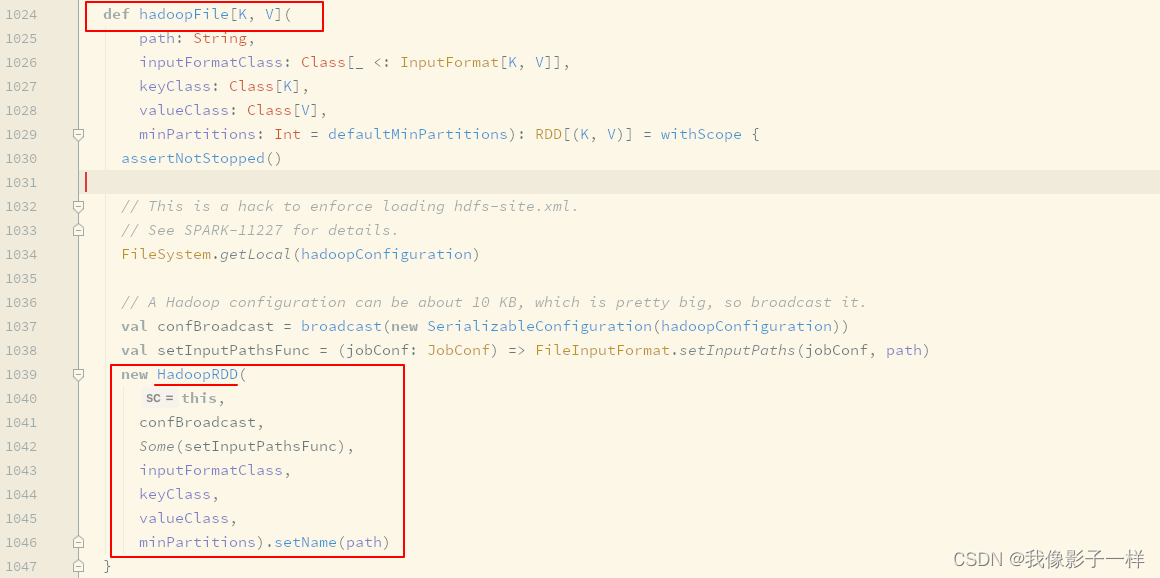

-
**HadoopRDD的Partitions对应了HDFS的Blocks**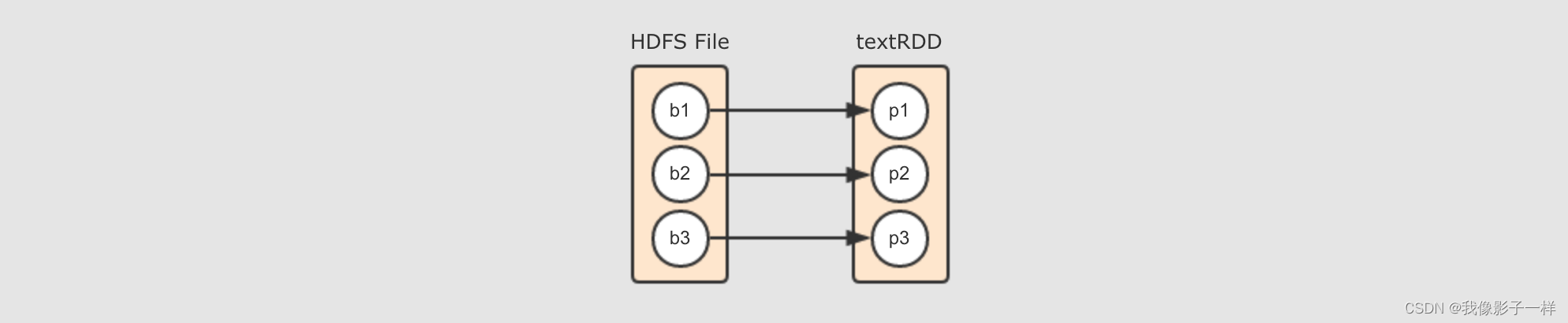
其实本质上每个
HadoopRDD的Partition都是对应了一个Hadoop的Block, 通过InputFormat来确定Hadoop中的Block的位置和边界, 从而可以供一些算子使用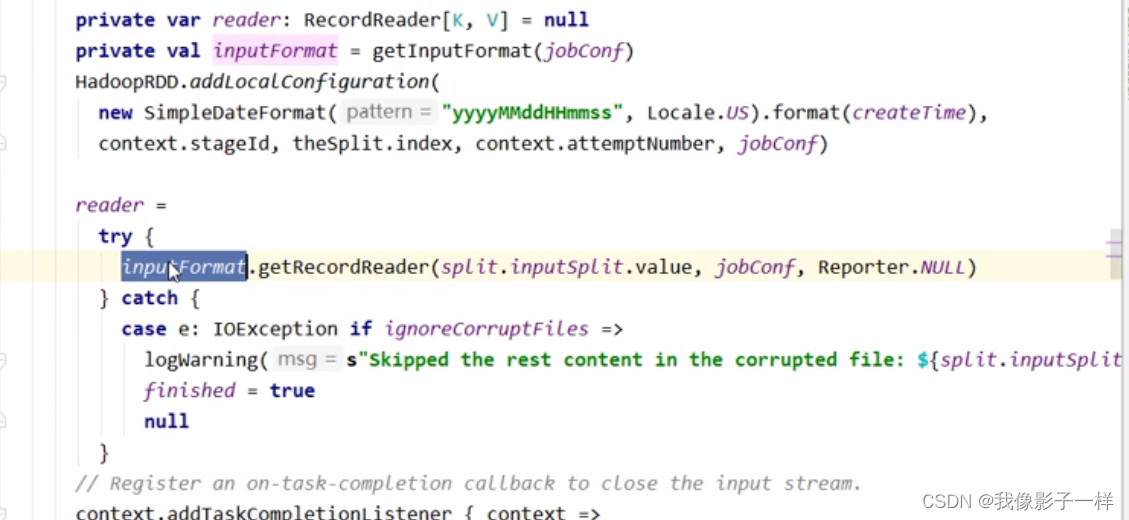
-
**HadoopRDD的compute函数就是在读取HDFS中的Block**本质上,
compute还是依然使用InputFormat来读取HDFS中对应分区的Block -
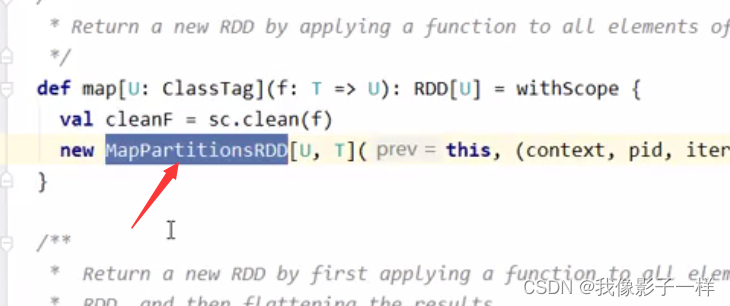
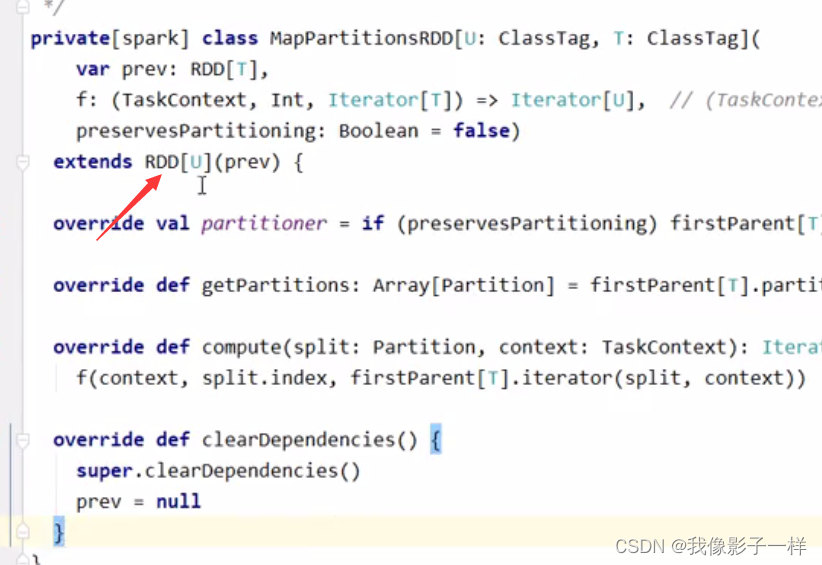
**textFile这个算子生成的其实是一个MapPartitionsRDD**textFile这个算子的作用是读取HDFS上的文件, 但是HadoopRDD中存放是一个元组, 其Key是行号, 其Value是Hadoop中定义的Text对象, 这一点和MapReduce程序中的行为是一致的但是并不适合
Spark的场景, 所以最终会通过一个map算子, 将(LineNum, Text)转为String形式的一行一行的数据, 所以最终textFile这个算子生成的RDD并不是HadoopRDD, 而是一个MapPartitionsRDD
-
-
**map算子的背后**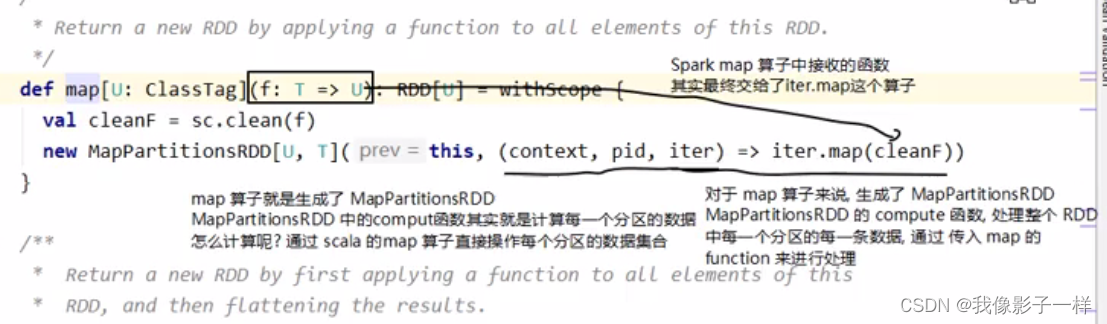
-
**map算子生成了MapPartitionsRDD**val conf= new SparkConf().setMaster("local[6]").setAppName("wordCount_source") val sc= new SparkContext(conf) val rdd=sc.parallelize(Seq("Hadoop Spark", "Hadoop Flume", "Spark Sqoop")) val rdd1=rdd.flatMap(_.split(" ")) val rdd2=rdd1.map((_, 1))由源码可知, 当 val rdd2 = rdd1.map() 的时候, 其实生成的新 RDD 是 rdd2, rdd2 的类型是 MapPartitionsRDD, 每个 RDD 中的五大属性都会有一些不同, 由 map 算子生成的 RDD 中的计算函数, 本质上就是遍历对应分区的数据, 将每一个数据转成另外的形式
-
**MapPartitionsRDD的计算函数是collection.map( function )**真正运行的集群中的处理单元是 Task, 每个 Task 对应一个 RDD 的分区, 所以 collection 对应一个 RDD 分区的所有数据, 而这个计算的含义就是将一个 RDD 的分区上所有数据当作一个集合, 通过这个 Scala 集合的 map 算子, 来执行一个转换操作, 其转换操作的函数就是传入 map 算子的 function
-
传入
map算子的函数会被清理
这个清理主要是处理闭包中的依赖, 使得这个闭包可以被序列化发往不同的集群节点运行
-
-
**flatMap算子的背后**
flatMap和map算子其实本质上是一样的, 其步骤和生成的RDD都是一样, 只是对于传入函数的处理不同,map是collect.map( function )而flatMap是collect.flatMap( function )从侧面印证了, 其实
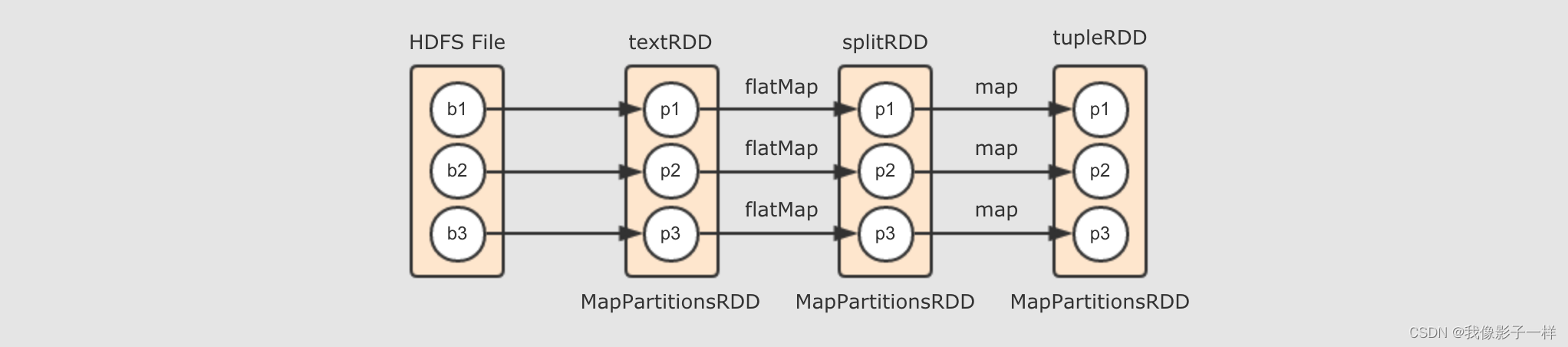
Spark中的flatMap和Scala基础中的flatMap其实是一样的val conf= new SparkConf().setMaster("local[6]").setAppName("wordCount_source") val sc= new SparkContext(conf) val textRDD=sc.parallelize(Seq("Hadoop Spark", "Hadoop Flume", "Spark Sqoop")) val splitRDD=textRDD.flatMap(_.split(" ")) val tupleRDD=splitRDD.map((_, 1)) val reduceRDD=tupleRDD.reduceByKey(_ + _) val strRDD=reduceRDD.map(item => s"${item._1},${item._2}") // println(strRDD.toDebugString) strRDD.collect.foreach(item =>println(item))textRDD→splitRDD→tupleRDD由
textRDD到splitRDD再到tupleRDD的过程, 其实就是调用map和flatMap算子生成新的RDD的过程, 所以如下图所示, 就是这个阶段所生成的逻辑计划
-
-
RDD 之间有哪些依赖关系
-
前置说明
-
什么是RDD之间的依赖关系?
-
什么是关系(依赖关系)?
从算子视角上来看,splitRDD 通过 map 算子得到了 tupleRDD ,所以 splitRDD 和 tupleRDD 之间的关系是 map, 但是仅仅这样说,会不够全面,从细节上来看,RDD只是数据和关于数据的计算,而具体执这种计算得出结果的是一个神秘的其它组件,所以,这两个 RDD 的关系可以表示为 splitRDD 的数据通过 map 操作,被传入 tupleRDD ,这是它们之间更细化的关系
但是 RDD 这个概念本身并不是数据容器,数据真正应该存放的地方是 RDD 的分区,所以如果把视角放在数据这一层面上的话,直接讲这两个 RDD 之间有关系是不科学的,应该从这两个 RDD 的分区之间的关系来讨论它们之间的关系
-
那这些分区之间是什么关系?
如果仅仅说 splitRDD 和 tupleRDD 之间的话,那它们的分区之间就是一对一的关系
但是 tupleRDD 到 reduceRDD 呢?tupleRDD 通过算子 reduceByKey 生成 reduceRDD ,而这个算子是一个 Shuffle 操作,Shuff1e 操作的两个 RDD 的分区之间并不是一对一,reduceByKey 的一个分区对应 tupleRDD 的多个分区
-
-
reduceByKey 算子会生成 ShuffledRDD
reduceByKey 是由算子 combineByKey 来实现的,combineByKey 内部会创建 ShuffledRDD 返回,而整个reduceByKey操作大致如下过程
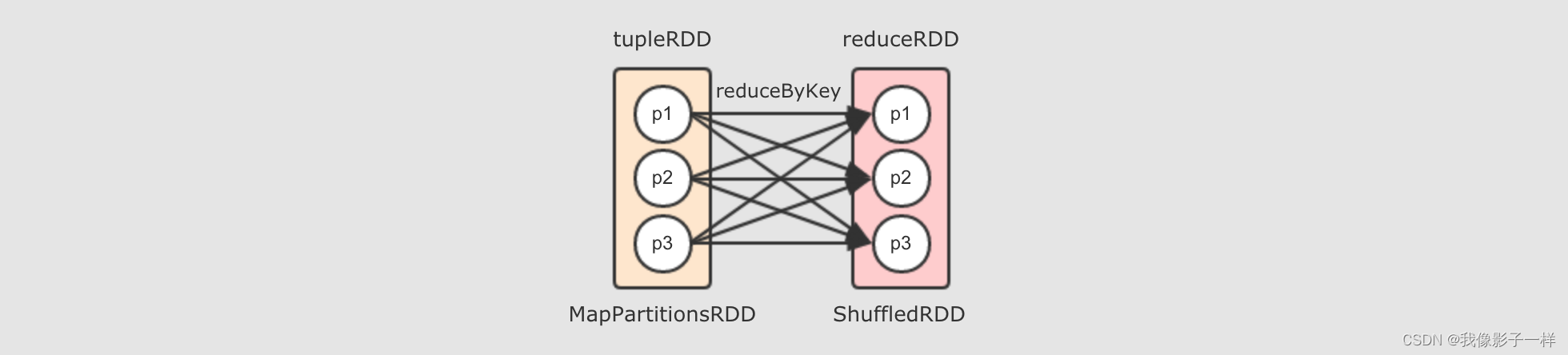
去掉两个 reducer 端分区,只留下一个的话,如下
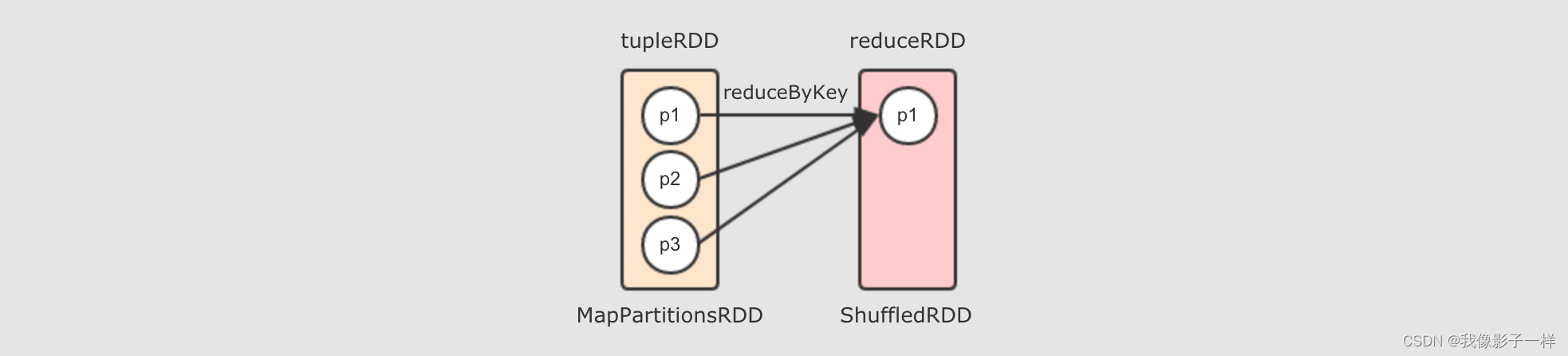
所以, 对于 reduceByKey 这个 Shuffle 操作来说, reducer 端的一个分区, 会从多个 mapper 端的分区拿取数据, 是一个多对一的关系
至此为止, 出现了两种分区见的关系了, 一种是一对一, 一种是多对一
-
-
窄依赖
窄依赖(NarrowDependency)
假如 rddB = rddA.transform(…), 如果 rddB 中一个分区依赖 rddA 也就是其父 RDD 的少量分区, 这种 RDD 之间的依赖关系称之为窄依赖
换句话说, 子 RDD 的每个分区依赖父 RDD 的少量个数的分区, 这种依赖关系称之为窄依赖
@Test def narrowDependency(): Unit = { // 需求:求得两个 RDD 之间的笛卡尔积 // 1. 生成 RDD val conf = new SparkConf().setMaster("local[6]").setAppName("cartesian") val sc = new SparkContext(conf) val rddA = sc.parallelize(Seq(1, 2, 3)) val rddB = sc.parallelize(Seq("a", "b")) // 2. 计算 val rddC = rdd1.cartesian(rdd2) // 3. 结果获取 rddC.collect().foreach(print(_)) sc.stop() } // 运行结果: (1,a) (1,b) (2,a) (2,b) (3,a) (3,b)- 上述代码的 cartesian 是求得两个集合的笛卡尔积
- 上述代码的运行结果是 rddA 中每个元素和 rddB 中的所有元素结合, 最终的结果数量是两个 RDD 数量之和
- rddC 有两个父 RDD, 分别为 rddA 和 rddB
对于 cartesian 来说, 依赖关系如下
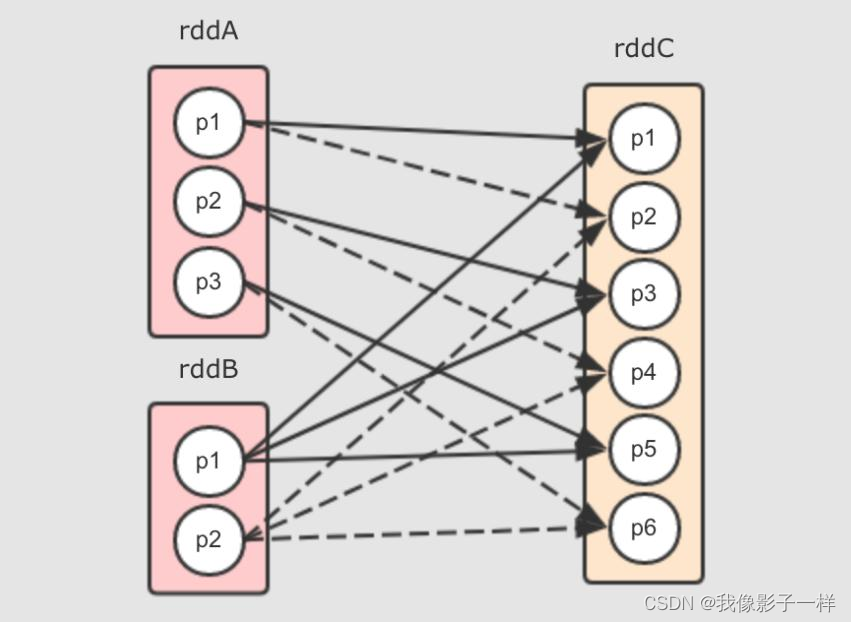
上述图形中清晰展示如下现象
- rddC 中的分区数量是两个父 RDD 的分区数量之乘积
- rddA 中每个分区对应 rddC 中的两个分区 (因为 rddB 中有两个分区), rddB 中的每个分区对应 rddC 中的三个分区 (因为 rddA 有三个分区)
它们之间是窄依赖, 事实上在 cartesian 中也是 NarrowDependency 这个所有窄依赖的父类的唯一一次直接使用, 为什么呢?
因为所有的分区之间是拷贝关系, 并不是 Shuffle 关系
- rddC 中的每个分区并不是依赖多个父 RDD 中的多个分区
- rddC 中每个分区的数量来自一个父 RDD 分区中的所有数据, 是一个 FullDependence, 所以数据可以直接从父 RDD 流动到子 RDD
- 不存在一个父 RDD 中一部分数据分发过去, 另一部分分发给其它的 RDD
-
宽依赖
宽依赖(ShuffleDependency
(并没有所谓的宽依赖, 宽依赖应该称作为 ShuffleDependency)
在 ShuffleDependency 的类声明上如下写到
Represents a dependency on the output of a shuffle stage.上面非常清楚的说道, 宽依赖就是 Shuffle 中的依赖关系, 换句话说, 只有 Shuffle 产生的地方才是宽依赖
那么宽窄依赖的判断依据就非常简单明确了, 是否有 Shuffle ?
举个 reduceByKey 的例子, rddB = rddA.reduceByKey( (curr, agg) ⇒ curr + agg ) 会产生如下的依赖关系

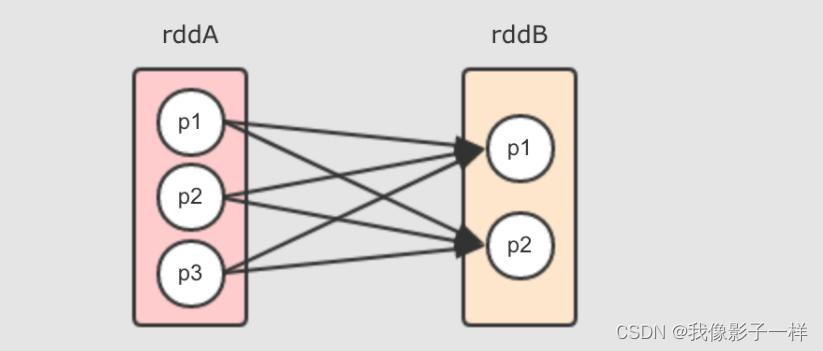
- rddB 的每个分区都几乎依赖 rddA 的所有分区
- 对于 rddA 中的一个分区来说, 其将一部分分发给 rddB 的 p1, 另外一部分分发给 rddB 的 p2, 这不是数据流动, 而是分发
-
如何分辨宽窄依赖 ?
其实分辨宽窄依赖的本身就是在分辨父子 RDD 之间是否有 Shuffle, 大致有以下的方法
- 如果是 Shuffle, 两个 RDD 的分区之间不是单纯的数据流动, 而是分发和复制
- 一般 Shuffle 的子 RDD 的每个分区会依赖父 RDD 的多个分区
先看是否一对一>是就是窄依赖,如果不是一对一,是多对一>不能确定,再继续判断
但是这样判断其实不准确, 如果想分辨某个算子是否是窄依赖, 或者是否是宽依赖, 则还是要取决于具体的算子, 例如想看 cartesian 生成的是宽依赖还是窄依赖, 可以通过如下步骤
-
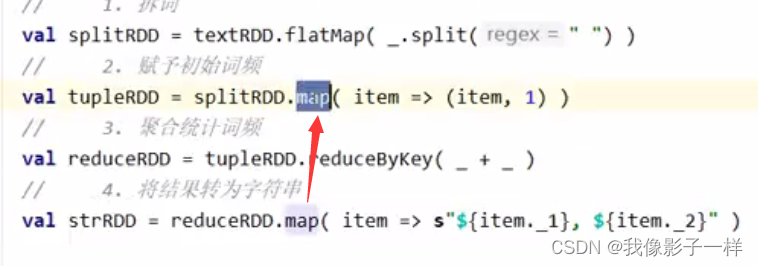
查看 map 算子生成的 RDD
-
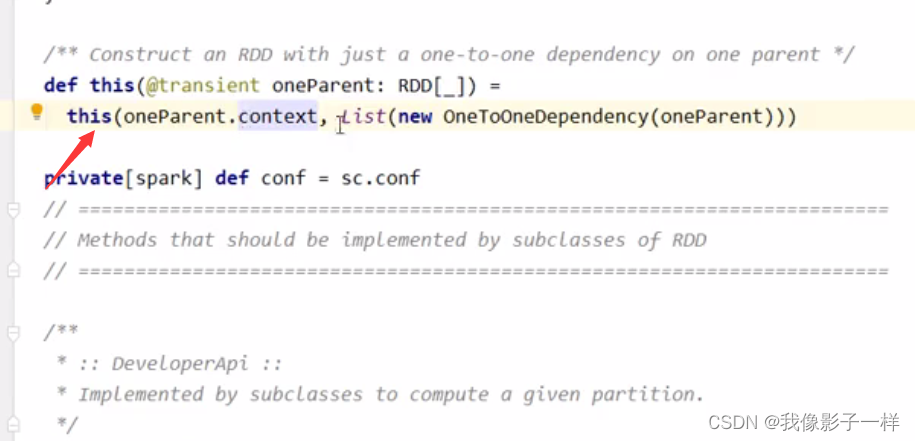
进去 RDD 查看 getDependence 方法
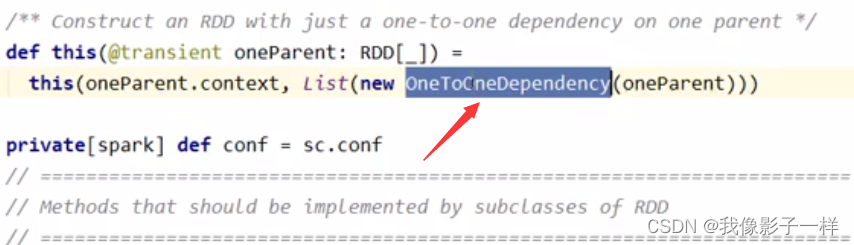

724024159.png?origin_url=Untitled%2520180.png&pos_id=img-mqipe2i4-1704890196048)
-
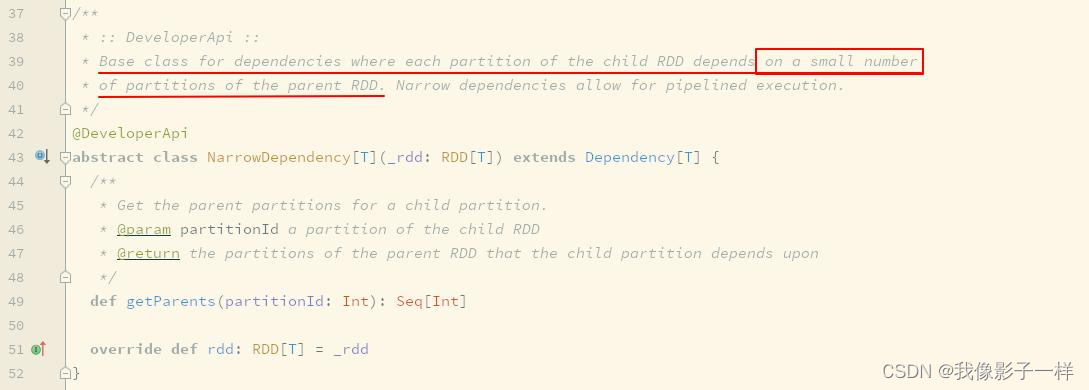
常见的窄依赖类型
Dependency.scala 源码有。
-
一对一窄依赖
其实 RDD 中默认的是 OneToOneDependency, 后被不同的 RDD 子类指定为其它的依赖类型, 常见的一对一依赖是 map 算子所产生的依赖, 例如 rddB = rddA.map(…)
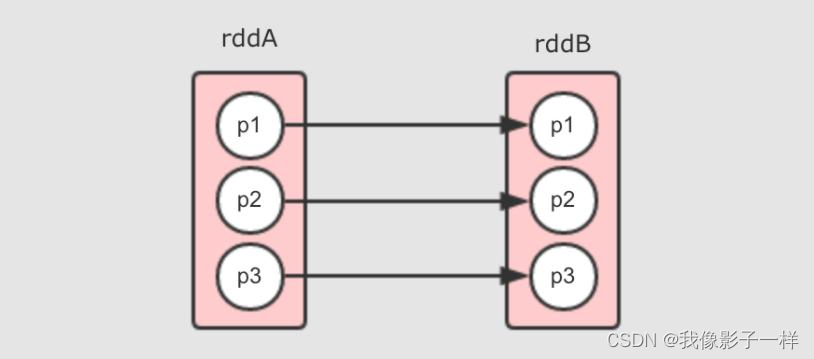
- 每个分区之间一一对应, 所以叫做一对一窄依赖
-
Range 窄依赖
Range 窄依赖其实也是一对一窄依赖, 但是保留了中间的分隔信息, 可以通过某个分区获取其父分区, 目前只有一个算子生成这种窄依赖, 就是 union 算子, 例如 rddC = rddA.union(rddB)
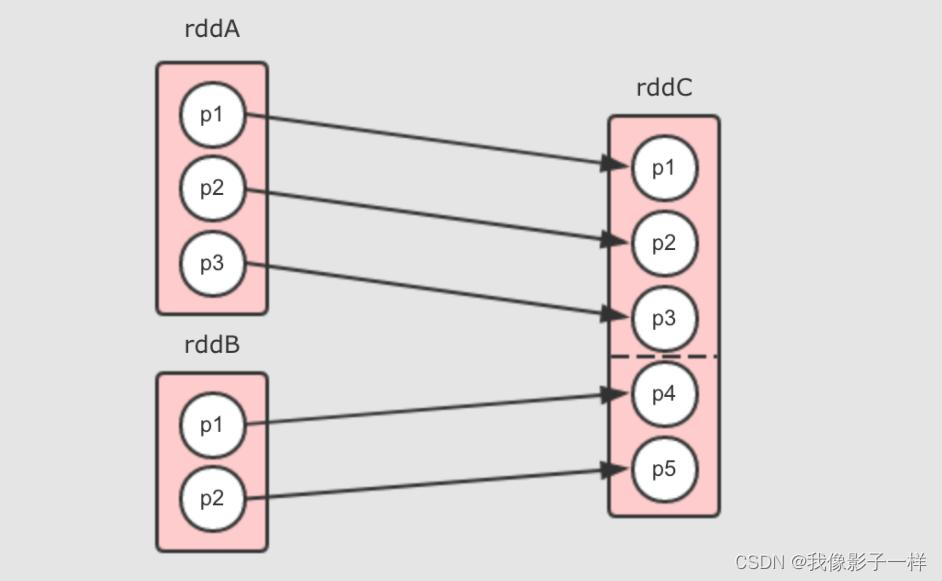
- rddC 其实就是 rddA 拼接 rddB 生成的, 所以 rddC 的 p5 和 p6 就是 rddB 的 p1 和 p2
- 所以需要有方式获取到 rddC 的 p5 其父分区是谁, 于是就需要记录一下边界, 其它部分和一对一窄依赖一样
-
多对一窄依赖
多对一窄依赖其图形和 Shuffle 依赖非常相似, 所以在遇到的时候, 要注意其 RDD 之间是否有 Shuffle 过程, 比较容易让人困惑, 常见的多对一依赖就是重分区算子 coalesce, 例如 rddB = rddA.coalesce(2, shuffle = false), 但同时也要注意, 如果 shuffle = true 那就是完全不同的情况了
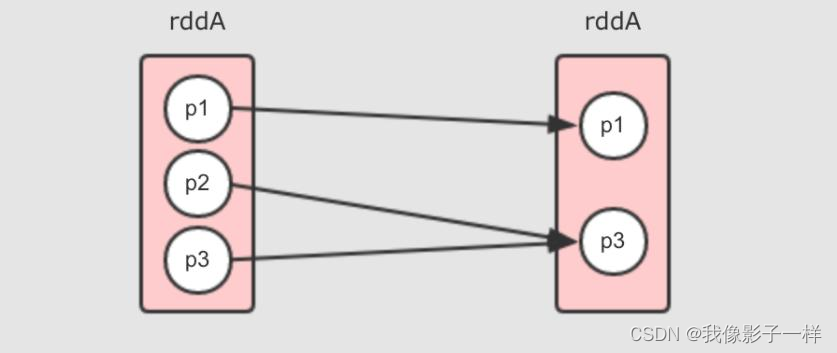
- 因为没有 Shuffle, 所以这是一个窄依赖
-
再谈宽窄依赖的区别
- 宽窄依赖的区别非常重要, 因为涉及了一件非常重要的事情: 如何计算 RDD ?
- 宽窄依赖的核心区别是: 窄依赖的 RDD 可以放在一个 Task 中运行
-
-