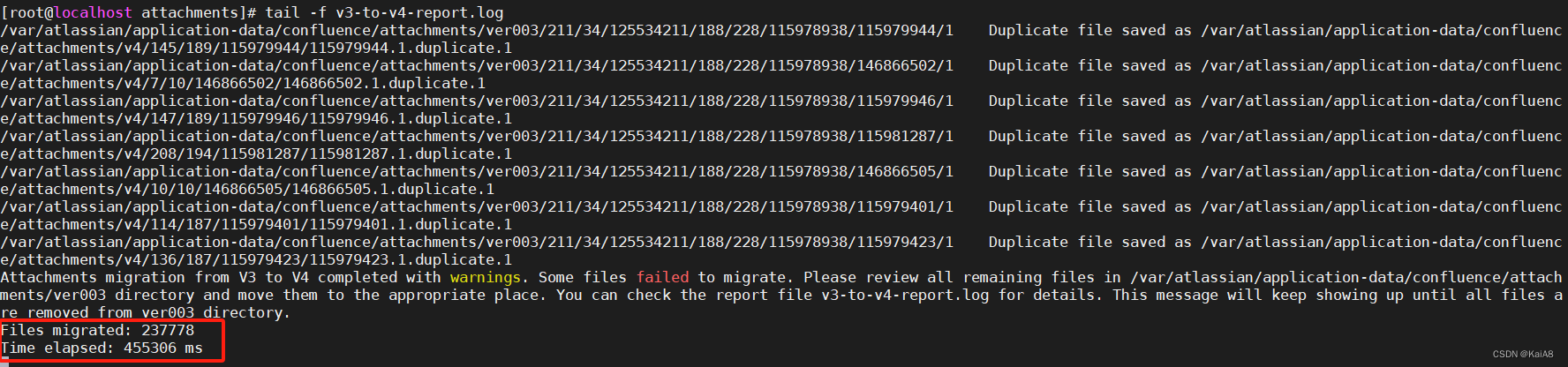
一、原理解析
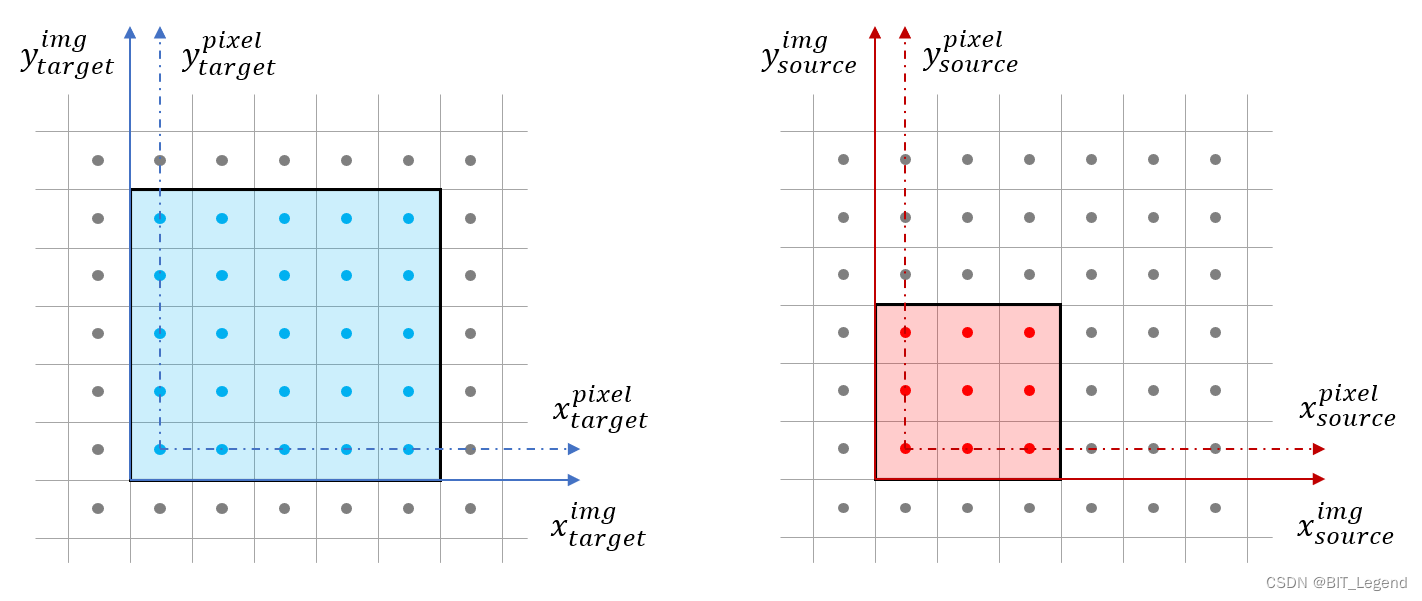
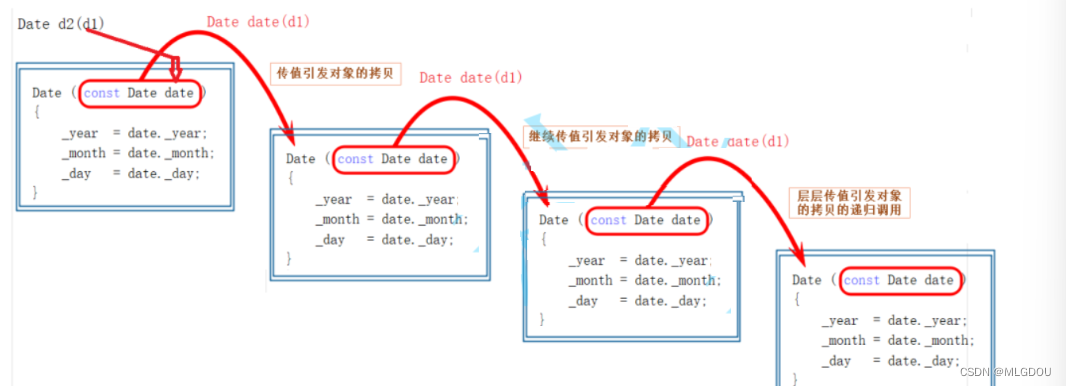
图片插值是图片操作中最常用的操作之一。为了详细解析其原理,本文以 3×3 图片插值到 5×5 图片为例进行解析。如上图左边蓝色方框是 5×5 的目标图片,右边红色方框是 3×3 的源图片。上图中,蓝/红色方框是图片,图片中的蓝/红色小圆点是图片中的像素,蓝/红色实线箭头是图片坐标系,蓝/红色虚线箭头是图片像素坐标系,从中可以发现图片框是要比最外圈像素所围成的像素框大一圈。图片插值指的是将右边红色方框放大到与左边蓝色方框同大,然后通过右边放大后的 3×3 的红色像素值计算得到左边的 5×5 的蓝色像素值。通常意义下所说的图片缩放或插值指的是两幅图片的图片框之间的关系而不是像素框之间的关系。基于图片框缩放,3×3 的图片要插值搭到 5×5 的图片,指的是红色方框从上图放大到下图的样子。
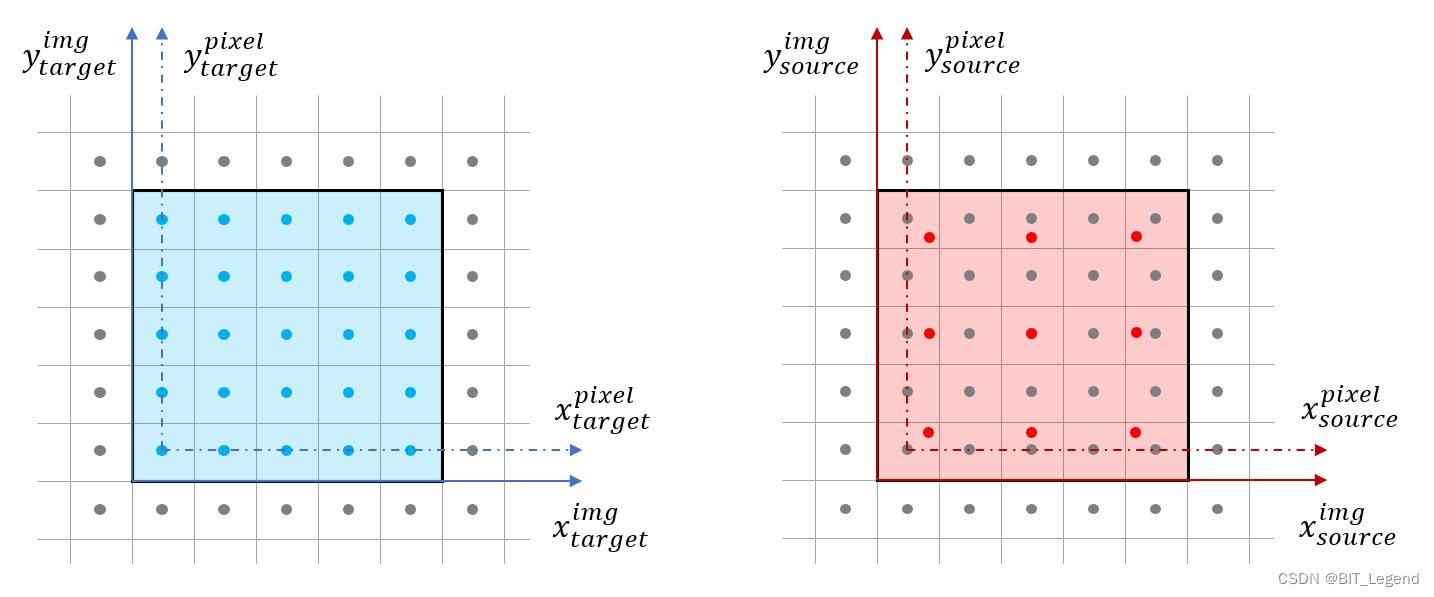
如果采用像素框缩放,那红色方框放大后,需要保证 3×3 的像素的四个角的像素位置与蓝色方框的 5×5 像素的四个角的像素位置完全重合,那放大后的红色方框要比上图的红色方框再大一小圈。基于图片框缩放,从上图中可以发现,当 3×3 的红色图片被插值到 5×5 的图片后,原本 3×3 的像素位置也会相应的发生缩放。
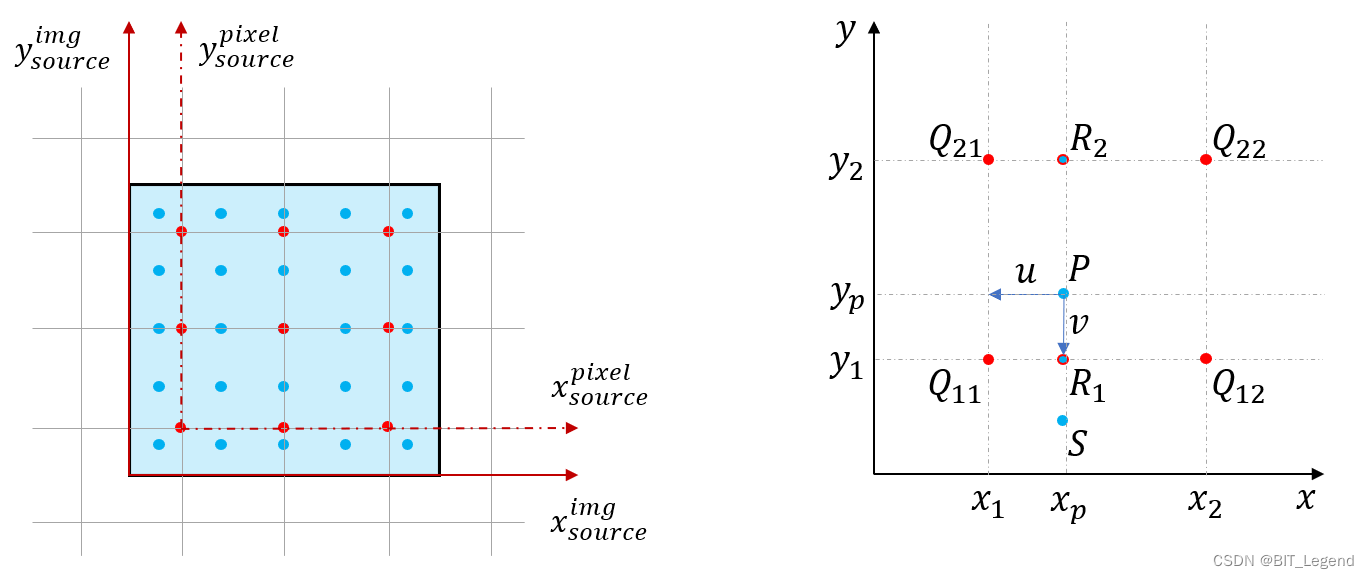
将参考辅助线调整后,如上左图所示,在完成缩放后,那图片插值的剩余过程就是通过红色像素值计算蓝色像素值。拿一个最左下角红色方格举例如上右图所示,已知四个红色像素点的位置和像素值,同样已知蓝色像素点 的位置,求
的像素值。
二维线性插值是图片插值中最常用的插值算法。二维线性插值的原理为,首先基于一维线性插值原理,通过 和
计算得到
的像素值,通过
和
计算得到
的像素值,然后通过
和
计算得到
的像素值。
通过 和
计算得到
的像素值的公式为(线性方程):
通过 和
计算得到
的像素值的公式为(线性方程):
通过 和
计算得到
的像素值的公式为(线性方程):
整理得到:
其中
这里需要特别说明的是,边界点的处理方法,如上右图的 点,其位于四个红色像素点以外,但由于其位于图片的最左下角边界上,其下面没有红色像素点,只有上面有两个像素点。但针对
点像素值的计算我们依然使用这四个红色像素点,相当于
点是
与
的直线段的延伸。
二、Python 代码
关于代码实现需要注意 3 个地方:
1. 上面原理讲的是从原图片像素坐标映射到目标图片像素坐标的过程,但实际编程一般采用从目标图片像素坐标映射到源图片像素坐标;
2. 在缩放比计算时注意,图片框缩放计算公式是 src_h/dst_h,但像素框缩放计算公式是 (src_h-1)/(dst_h-1);
3. 在图片边界处的处理为,需要保证所计算的左下角像素点坐标大于等于 0 且小于等于图片尺寸 -2,小于等于图片尺寸 -2 的原因是保证右上角像素点坐标小于等于图片尺寸 -1,边界处的像素点的计算依然需要最近邻的四个点。
import numpy as np
import cv2
def bilinear(src_img, dst_shape):
# 计算目标图片到原图片的缩放比,且是图片坐标系的缩放,不是像素坐标系的缩放,像素位于图像像素格的中心
src_h, src_w = src_img.shape[0], src_img.shape[1]
dst_h, dst_w = dst_shape
scale_h, scale_w = src_h/dst_h, src_w/dst_w # 如果是像素坐标系的缩放则应该为 (src_h-1)/(dst_h-1)
# 定义目标图片并向其中填充像素值,遍历目标图片像中的每个像素点
dst_img = np.zeros((dst_h, dst_w, 3), np.uint8)
for i in range(dst_h):
for j in range(dst_w):
# 将 目标像素坐标系下的坐标 --> 目标图像坐标系下的坐标(+0.5) --> 源图像坐标系下的坐标(*scale) --> 源像素坐标系下的坐标(-0.5)
src_x = (j + 0.5) * scale_w - 0.5
src_y = (i + 0.5) * scale_h - 0.5
# 在非边界情况下获取左下角图像像素点坐标,在左/下边界的情况下保证大于等于0,在右/上边界的情况下保证小于等于src-2,以保证计算时所用的右上角像素坐标小于等于src-1
src_x_int = min(max(int(src_x), 0), src_w-2)
src_y_int = min(max(int(src_y), 0), src_h-2)
# 获取所求像素点相比左下角像素点的距离
src_x_float = src_x - src_x_int
src_y_float = src_y - src_y_int
# 计算每个像素值
dst_img[i, j, :] = (1. - src_y_float) * (1. - src_x_float) * src_img[src_y_int, src_x_int, :] + \
(1. - src_y_float) * src_x_float * src_img[src_y_int, src_x_int + 1, :] + \
src_y_float * (1. - src_x_float) * src_img[src_y_int + 1, src_x_int, :] + \
src_y_float * src_x_float * src_img[src_y_int + 1, src_x_int + 1, :]
return dst_img
if __name__ == "__main__":
img_path = "test.jpg"
src_img = cv2.imread(img_path, cv2.IMREAD_COLOR)
dst_shape = (300, 400)
# 图片放缩均采用双线性插值法
# opencv的放缩图片函数
resize_image = cv2.resize(src_img, (400, 300), interpolation=cv2.INTER_LINEAR)
# 自定义的图片放缩函数
dst_img = bilinear(src_img, dst_shape)
cv2.imwrite("new_resize.jpg", resize_image)
cv2.imwrite("new.jpg", dst_img)