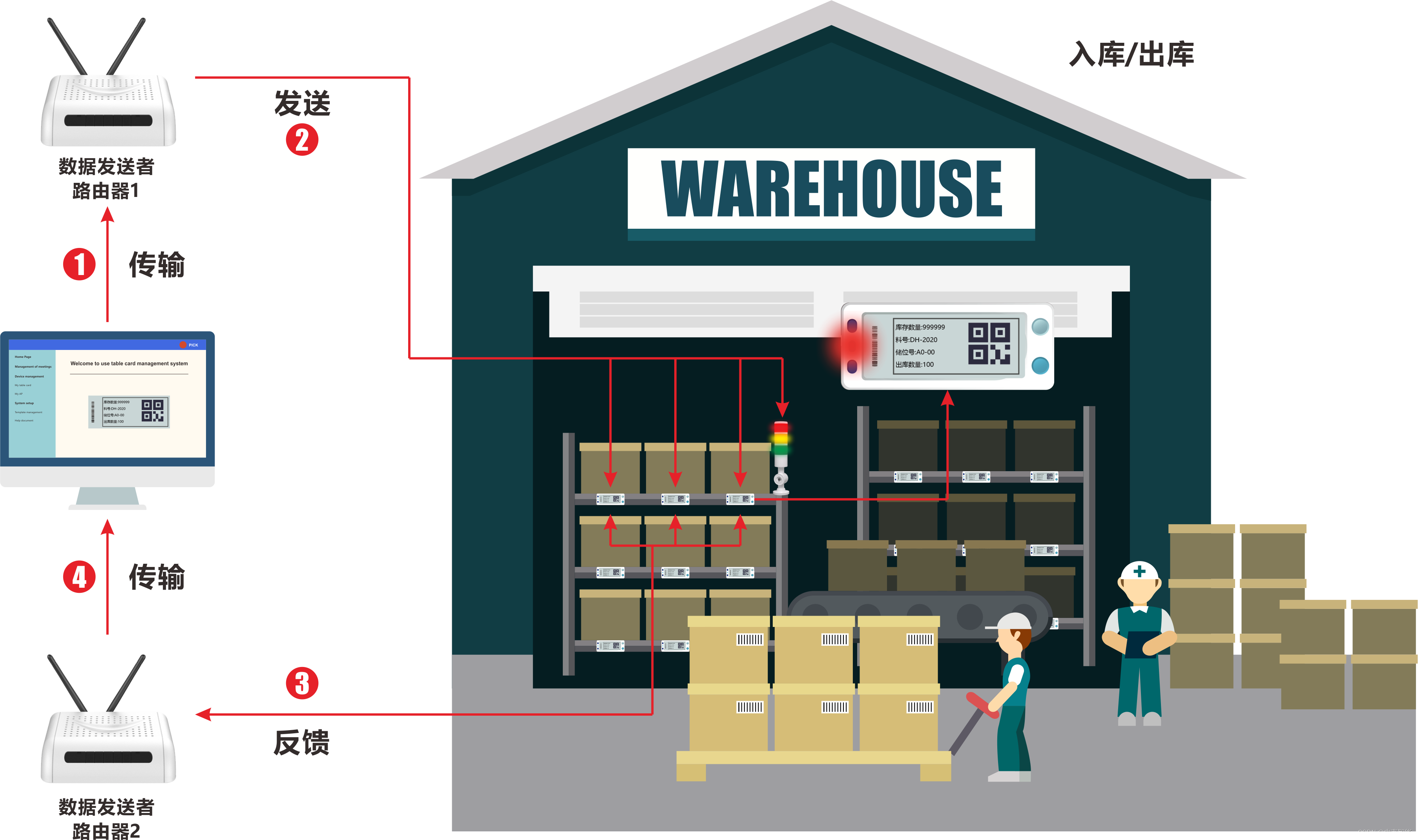
信息抽取
- 信息抽取复习重点:
- 信息抽取概述
- 从任务内容分为:
- 从处理文档类型分为:
- 从发展时间和处理文档分为:
- 实体识别与抽取
- 限定域命名实体识别
- 基于规则或字典的方法 :规则模版(字典)+匹配
- 统计学习方法 :特征工程+算法(PRanking / margin/ SVM/LR……)
- 神经网络的方法:
- 开放域命名实体识别
- 开放式命名实体抽取方法(实例扩展方法):
- 开放式命名实体抽取过程:
- 开放域实体抽取存在的问题:
- 实体消歧
- 实体消歧任务:
- 实体消歧的难点
- 实体消歧方法
- 基于聚类的实体消歧
- 基于实体链接的实体消歧
- 关系抽取(重点)
- 限定域关系抽取
- 规则方法:
- 基于统计的抽取方法
- 基于神经网络的抽取方法
- 非限定域关系抽取(重点)
- 利用知识库(远程监督的方法)
- 远程监督的优势与问题
- 非限定域关系抽取(生成式抽取)
- 无监督开放式中文实体关系抽取
- 事件抽取
- 事件抽取相关概念:
- 传统事件抽取
信息抽取复习重点:
实体关系抽取,和事件抽取
掌握实体关系抽取的基本过程
限定域的抽取方法
非限定域的抽取过程:
【弱监督的抽取过程,无监督的抽取过程,感知监督的抽取过程,远程监督的方法(优势,局限) 基本技术思路,改进后可以解决哪些问题?】
事件抽取: 基本的元概念,基本的过程就可以了。过程包含哪些要素
信息抽取概述
信息抽取:从自然语言文本中抽取指定类型的实体、 关系、 事件等事实信息,并形成结构化数据输出的文本处理技术
从任务内容分为:
- 实体识别和抽取(Named Entity Recognition,NER)
- 实体消歧(entity resolution)
- 关系抽取(Relation Extraction,RE)
- 事件抽取(Event Extraction,EE)
从处理文档类型分为:
- 结构化数据(Structured Data):一般指带有严格格式信息的数据,如:数据库中的表格,以及XML数据等等。
- 半结构化数据(Semi.-structured Data):指带有一定格式信息,但又不
很明确的数据,如网页、论文、邮件等 - 无结构数据(Un-structured Data): 主要指完全没有结构信息的自由文本
(Free Text)
从发展时间和处理文档分为:
- 限定域信息抽取:处理的文档给定(无结构信息的自由文本),抽取
的实体,实体关系,事件类型给定。 - 开放域信息抽取: 针对互联网范围,实体,关系和事件的类型不确定
实体识别与抽取
限定域命名实体识别任务:
- 限定实体类别:限定识别七类命名实体
(人名、 机构名、 地名、 时间、日期、 货币和百分比) - 限定目标文本:封闭文本语料(有标注)
开放域实体抽取任务:
- 不限定实体类别:可以是任何类型的实体。如 维基百科条目等
- 不限定目标文本:大规模开放语料。如 Web页面,真实世界信息(无标注)
限定域命名实体识别
- 限定实体类别:限定识别七类命名实体
(人名、 机构名、 地名、 时间、日期、 货币和百分比) - 限定目标文本:封闭文本语料(有标注)
NER可以分成两个子任务:
- (1)发现命名实体(实体边界识别)
- (2)分类命名实体(确定实体类别 )
基于规则或字典的方法 :规则模版(字典)+匹配
选用特征包括统计信息、标点符号、关键字、指示词和方向词、位置词(如尾字)、中心词等方法
- 如: Email的表现形式通常为 xxxx@xxx.com
- 如: 日期的表现形式通常为xxxx年-xx月- xx日
主要问题:
-(1)规则依赖于具体语言、领域和文本风格,难以涵盖所有的语言现象,泛化性性弱
-(2)规则构造成本高,构建周期长,迁移性差
统计学习方法 :特征工程+算法(PRanking / margin/ SVM/LR……)
转成序列标注问题
NER可以分成两个子任务:
(1)发现命名实体(实体边界识别)
(2)分类命名实体(确定实体类别 )
利用命名实体的内部构成和外部语言环境具有的一些特征采用不同的识别模型
主要问题:特征工程
如:
1、实体边界识别:{B(Begin,实体的起始词)、I(Inside,实体的内部词)、O(非实体)}
2、确定实体类别:{PER(人名实体)、LOC(地点实体)、 ORG(组织实体))}
神经网络的方法:
用序列标注方法解决。
优势 : 神经网络可自动提取特征
模型:CNN+RNN,RNN+CRF ,BERT 等
利用BERT,实验中命名实体识别可达到 96%以上的准确
开放域命名实体识别
特点:
- 不限定实体类别:可以是任何类型的实体。如 维基百科条目等
- 不限定目标文本:大规模开放语料。如 Web页面,真实世界信息(无标注)
任务
给定某一类别的实体实例, 从大规模开放语料中抽取同一类别其他实体实例
抽取思想
种子与目标词有相同类型,所以种子词与目标词在网页中具有相同或者类似的上下文或网页结构
开放式命名实体抽取方法(实例扩展方法):
从种子词出发, 通过分析种子实体在语料中的上下文特征得到模板,根据模板得到更多的候选实体,选置信度高的实体作新种子进行迭代,返回置信度高的候选实体做结果输出。
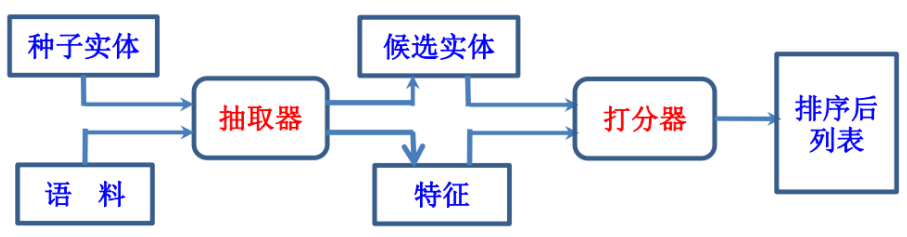
关键:
• 如何选高质量种子
• 如何计算置信度
针对不同数据源的特点设计方法, 其针对性、 灵活性很强
开放式命名实体抽取过程:
- 种子处理
负责选取和处理高质量的种子(如,选“上海”为种子) - 生成模板
根据种子词从日志等语料中归纳出其语境模板 - 实体抽取
按照模板从大规模语料中扩展抽取同语境实体(如,根据上述种子,从新的语料中抽出“长沙”、“青岛”、“南宁”等) - 计算抽取实体的置信度并按置信度排序
- 结果过滤
过滤掉置信度低的实体

开放域实体抽取存在的问题:
- 初始信息少,语义类别难以确定。在没有给定语义类别标签情况下,种子实体可能会同时属于多个语义类,使得目标语义类别的确定非常困难
- 目前模板主要包括自定义的语义模板及简单统计得到的上下文模板。这类模板与特定的数据格式和上下文密切相关对语义类别的描述能力有限
- 目前实体抽取数据源有普通网页、查询日志、维基百科等,这些数据源的质量层次不齐,严重影响了实体抽取的性能;对文档的预处理效果也会影响抽取性能,如,分词问题:未知实体往往在分词过程中被分开等。
- 缺乏公认的评测,造成不同方法之间横向可比性差。
实体消歧
歧义: 一个实体指称项可对应到多个真实世界实体(或实体概念)
同指( coreference) :表示两个或两个以上的词或短语指向相同对象
实体消歧任务:
确定一个实体指称项所指向的真实世界实体(或实体概念)包含实体消歧(Disambiguation)和共指消解(Co-reference Resolution)
实体消歧的难点
- 实体消歧目标不明确
- 指称项的歧义性
- 指称项的多样性
实体消歧方法
对于单语言实体消歧,目前主要有:
- 实体聚类消歧法
- 实体链接消歧法
基于聚类的实体消歧
基本思想:同一指称项具有近似的上下文利用聚类算法进行消歧
把所有实体指称项按其指向的目标实体进行聚类,使每一个实体指称项对应到一个单独的类别
基于实体链接的实体消歧
实体链指的目标是将文本中的指称项正确链接到知识库中正确的目标实体(一个实体名通常会指代知识库中的多个实体。)
实体链接消歧法主要步骤
- 候选实体的发现:给定实体指称项,链接系统根据知识、规则等信息找到实体指称项的所有候选实体
- 候选实体的链接:系统根据指称项和候选实体之间的相似度等特征,选择相似度㘁大的候选实体
关系抽取(重点)
限定域关系抽取
规则方法:
人工编制各种识别关系的规则,利用规则来识别。成本高,覆盖面底。
基本思想:首先构建规则,通常信息为:词汇、句法、语义等分析时,用模式匹配文本片段
优缺点
优点:准确度比较高(一旦匹配,基本正确);
缺点: 召回率与准确率呈跷跷板,准确率高时,覆盖性难以保证规则的构建需要“专家级”人参与,且工作量巨大
基于统计的抽取方法
基本思想:将关系实例转换成高维空间中的特征向量或直接用离散结构来表示,在标注语料库上训练生成分类模型, 然后再识别实体间关系
-
基于特征向量方法:
将各种有效的词法、 句法、 语义等特征集成起来产生描述实体语义关系的各种局部特征和简单的全局特征
关键问题:特征选取,即从自由文本及其句法结构中抽取出各种特征。主要有最大熵模型和支持向量机等模型 -
基于核函数方法:
挖掘反映语义关系的结构化信息及如何有效计算结构化信息之间的相似度
卷积树核方法: 用两个句法树之间的公共子树的数目来衡量它们之间相似度
基于神经网络的抽取方法
设计合理的网络结构, 从而捕捉更多的特征信息, 进而准确的进行关系分类
- 单一关系抽取(流水线):给出实体,抽取出两个实体的关系.
- 联合抽取:同时进行实体识别和关系的抽取
单一关系抽取指先对自然语言文本进行进行实体标记给出实体,然后根据标记好实体的句子进行关系的分类
联合关系抽取指同时进行实体识别和关系的抽取
非限定域关系抽取(重点)
限定域的实体关系抽取任务需要预先定义关系类型体系,然而定义一个全面的实体关系类型体系是很困难的。非限定域实体关系抽取技术不先定义关系类别,关系类别自动获取
特点:
- 文本:有噪音、有冗余的海量网络数据(Web Page、Wikipedia、Query Log )
- 不限定关系类别
非限定域关系抽取任务分为 :
- 利用知识库:利用已有知识库中现有实体关系作为辅助信息来进行实体关系抽取
- 特点:实体之间关系不限定,但实体间关系明确,主要根据知识库中的关系定义
- 实现方法: Bootstrapping 和 Distant Supervision(远程监督)
- 开放域抽取
- 特点:实体间关系不明确,根据任务需关系类别自动获取
利用知识库(远程监督的方法)
现有的有监督的关系数据库太小
解决方法:利用知识库中现有实体关系作为辅助信息来进行实体关系抽取
远程监督的优势与问题
- 远程监督的提出使得快速、大规模构建关系抽取数据集变为了可能。
- 远程监督最大的问题在于样本噪声:
- 远程监督强假设引入了许多假正例噪声。(本身不包含关系但被标注了)
- 由于知识库的不完备,造成了很多假负例噪声。(本身包含关系但知识库中没有)
处理噪声的几种思路:
-
隐式处理噪声:在训练过程中,通过对bag中的样本进行软加权等方式来降低标签噪声样本的影响,这类方法一般需要特殊设计的模型,但效果普遍较好
-
显式处理噪声:在进行模型训练前,先通过一定的方式来检测噪声样本并进行处理,得到一个处理后的数据集,并用这个数据集训练一个关系抽取模型。这类方法一般比较难,普遍采用强化学习等方式进行。但这类方法的优点在于应用性比较强,可以将处理好的数据集应用于任何一个模型中,从而提升模型的关系抽取效果。
-
外部信息辅助:可以认为远程监督的标签是一种比较弱的监督信息,在此基础上可以加入一些外部的辅助信息,如将图谱补全任务加入进行联合学习;或者加入一些无监督、弱监督的信息等,来辅助进行关系抽取,消除噪声的影响。
非限定域关系抽取(生成式抽取)
利用bart和t5
无监督开放式中文实体关系抽取
UnCORE的核心思想是从大规模网络文本中获取候选三元组集合,然后对候选集进行挖掘处理,从中提取正确的关系三元组。
- 输入:大规模网页
- 输出:是从网页文本中抽取的关系三元组
基本思想:
将采集的大规模网页文本语料进行预处理(预处理模块);通过分析语料特点制定候选三元组的抽取规则并从语料中抽取候选三元组集合(生成候选三元组模块);由于抽取的候选集包括大量的噪音条目,所以要对候选集做进一步处理以得到正确的三元组。去噪方法主要通过用采集到的关系指示词作为去噪条件;具体方法:①确定关系指示词的去噪条件(生成关系指示词词表模块)② 用该条件去噪并对一些不全的三元组做补全等后处理(后处理模块),最后得到正确的三元组。
事件抽取
事件的定义:事件是发生在某个特定的时间点或时间段、某个特定的地域范围内,由一个或者多个角色参与的一个或者多个动作组成的事情或者状态的改变
事件基本元素:时间,地点,人物,原因,结果
主要研究如何从描述事件信息的文本中抽取出用户感兴趣的事件信息并以结构化的形式呈现出来(从无结构化数据中抽取结构化事件信息
事件抽取相关概念:
- 事件描述(Event Mention):是指对一个客观发生的具体事件进行的自然语言形式的描述,通常是一个句子或者句群
- 事件触发词(Event Trigger):是指一个事件描述中㘁能代表事件发生的词,是决定事件类别的重要特征,往往是动词或者名词
- 事件元素/论元角色(Event Argument):是指事件中的参与者,是组成事件的核心部分,它与事件触发词构成了事件的整个框架
- 元素角色(Argument Role):是指事件元素与事件之间的语义关系, 也就是事件元素在相应的事件中扮演什么角色
- 事件类别(Event Type):事件元素和触发词决定了事件的类别
传统事件抽取
给定事件类型, 给定语料, 抽取指定的事件

![[数据结构基础]栈和队列的结构及接口函数](https://img-blog.csdnimg.cn/1891b6b26f8d4cbc850b93c7d6c6a697.png)