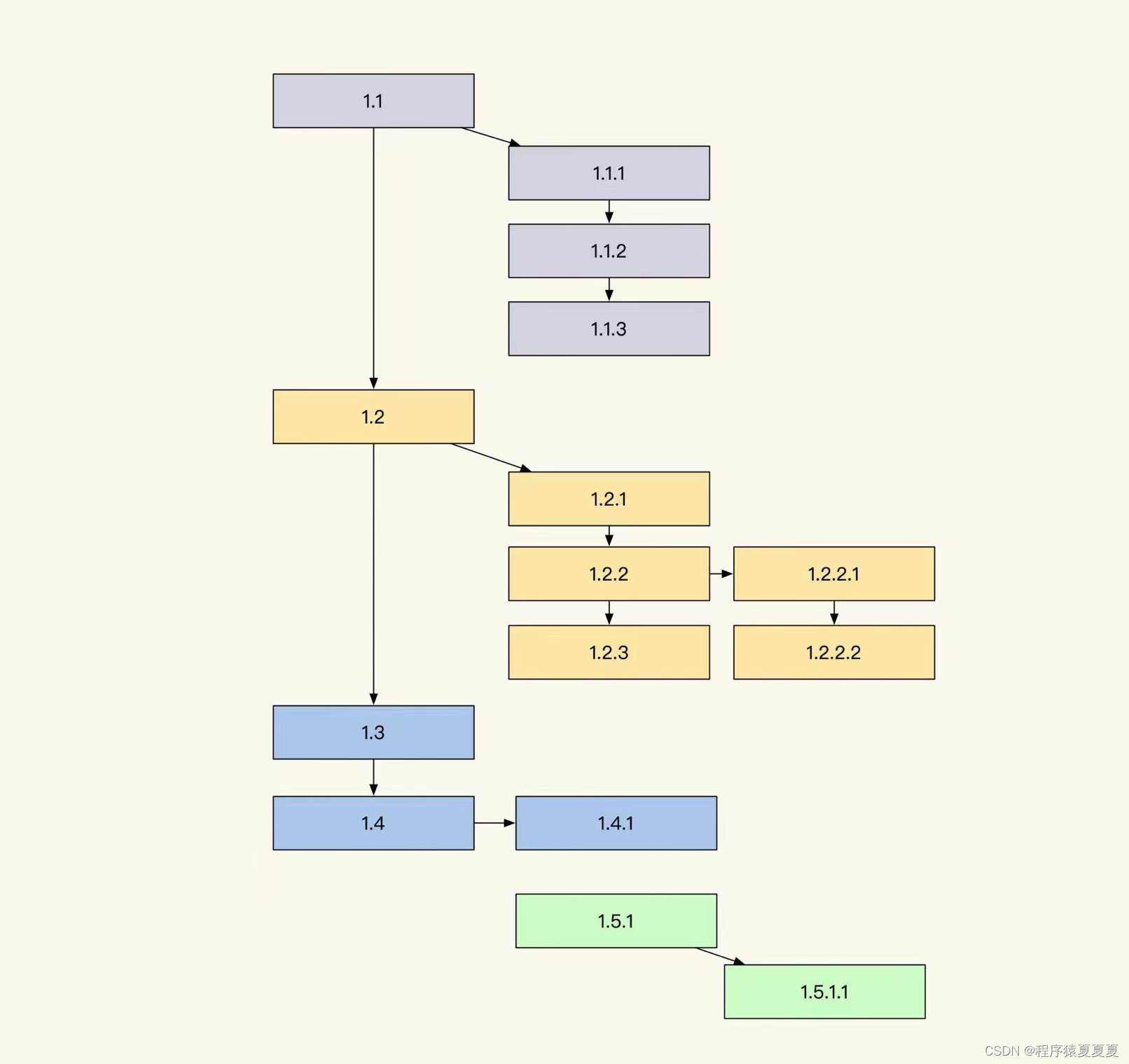
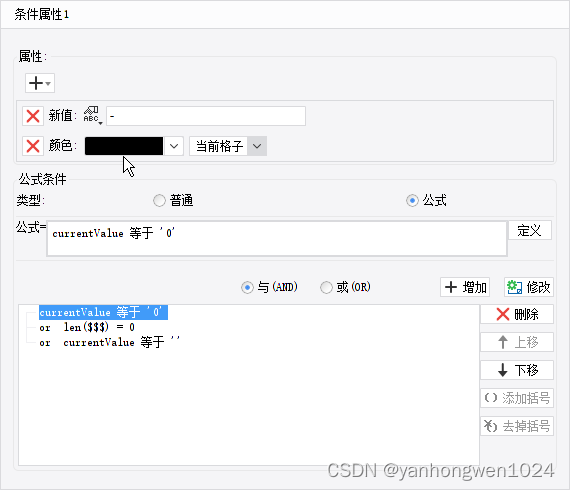
计算机擅长处理数字,但不擅长处理文本数据,TF-IDF是处理文本数据最广泛使用的技术之一,本文对它的工作原理以及它的特性进行介绍。
根据直觉,我们认为在文本数据分析中出现频率更高的单词应该具有更大的权重,但事实并非总是如此。诸如“the”、“will”和“you”等被称为停顿词的词在语料库中出现得最多,但意义不大。相反,那些罕见的词实际上是那些有助于区分数据的词,而且更有分量。
TF-IDF简介
TF-IDF代表“Term Frequency — Inverse Data Frequency(词频-逆文档频次)”,其数学含义如下:
Term Frequency (tf, 词频):给出语料库中每个文档中单词出现的频率。它是单词在文档中出现的次数与该文档中单词总数的比率,随着该单词在文档中出现次数的增加而增加,每个文档都有自己的词频:
t f i , j = n i , j ∑ k n i , j {tf}_{i,j}=\frac{n_{i,j}}{\sum_k{n_{i,j}}} tfi,j=∑kni,jni,j
Inverse Data Frequency(idf, 逆数据频率):用于计算语料库中所有文档中罕见词的权重,语料库中很少出现的词具有较高的IDF分数,它由下面的方程给出:
i d f ( ω ) = l o g ( N d f t ) idf(\omega)=log(\frac{N}{{df}_t}) idf(ω)=log(dftN)
结合这两者,我们得出了语料库中文档中单词的TF-IDF分数( ω \omega ω)。它是tf和idf的乘积:
t
f
i
,
j
×
l
o
g
(
N
d
f
i
)
{tf}_{i,j} \times log(\frac{N}{{df}_i})
tfi,j×log(dfiN)
其中:
- t f i , j {tf}_{i,j} tfi,j: j j j中 i i i出现的次数;
- d f i {df}_i dfi:包含 i i i的文件数;
- N N N:文件总数。
让我们举一个例子来更清楚地理解。
句子1:The car is driven on the road.
句子2:The truck is driven on the highway.
在本例中,每个句子都是一个单独的文档,现在我们将计算上述两个代表语料库的文档的TF-IDF。

由上表可知,常用词的TF-IDF为零,说明常用词不显著。另一方面,“car”、“truck”、“road”、“highway”的TF-IDF是非零的,这些词更有意义。
基于python计算TF-IDF
- 从
sklearn.feature_extraction.text导入TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
- 初始化矢量器,然后调用fit并对其进行变换,以计算文本的TF-IDF分数。
vectorizer = TfidfVectorizer()
response = vectorizer.fit_transform([s1, s2])
s1 = "The car is driven on the road"
s2 = "The truck is driven on the highway"
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
response = vectorizer.fit_transform([s1, s2])
这里返回的是csr_matrix稀疏矩阵,可以通过response.todense()转换成numpy形式。
print(response)
(0, 5) 0.42471718586982765
(0, 4) 0.30218977576862155
(0, 1) 0.30218977576862155
(0, 3) 0.30218977576862155
(0, 0) 0.42471718586982765
(0, 6) 0.6043795515372431
(1, 2) 0.42471718586982765
(1, 7) 0.42471718586982765
(1, 4) 0.30218977576862155
(1, 1) 0.30218977576862155
(1, 3) 0.30218977576862155
(1, 6) 0.6043795515372431
看一下TfidfVectorizer的源码:
在下述代码中需要注意的一点是,sklearn将1添加到n_samples中以计算IDF分数,这确保了IDF分数为0的单词不会被完全抑制。
def fit(self, X, y=None):
"""Learn the idf vector (global term weights)
Parameters
----------
X : sparse matrix, [n_samples, n_features]
a matrix of term/token counts
"""
if not sp.issparse(X):
X = sp.csc_matrix(X)
if self.use_idf:
n_samples, n_features = X.shape
df = _document_frequency(X)
# perform idf smoothing if required
df += int(self.smooth_idf)
n_samples += int(self.smooth_idf)
# log+1 instead of log makes sure terms with zero idf don't get
# suppressed entirely.
idf = np.log(float(n_samples) / df) + 1.0
self._idf_diag = sp.spdiags(idf, diags=0, m=n_features,
n=n_features, format='csr')
return self
def transform(self, X, copy=True):
"""Transform a count matrix to a tf or tf-idf representation
Parameters
----------
X : sparse matrix, [n_samples, n_features]
a matrix of term/token counts
copy : boolean, default True
Whether to copy X and operate on the copy or perform in-place
operations.
Returns
-------
vectors : sparse matrix, [n_samples, n_features]
"""
if hasattr(X, 'dtype') and np.issubdtype(X.dtype, np.floating):
# preserve float family dtype
X = sp.csr_matrix(X, copy=copy)
else:
# convert counts or binary occurrences to floats
X = sp.csr_matrix(X, dtype=np.float64, copy=copy)
n_samples, n_features = X.shape
if self.sublinear_tf:
np.log(X.data, X.data)
X.data += 1
if self.use_idf:
check_is_fitted(self, '_idf_diag', 'idf vector is not fitted')
expected_n_features = self._idf_diag.shape[0]
if n_features != expected_n_features:
raise ValueError("Input has n_features=%d while the model"
" has been trained with n_features=%d" % (
n_features, expected_n_features))
# *= doesn't work
X = X * self._idf_diag
if self.norm:
X = normalize(X, norm=self.norm, copy=False)
return X