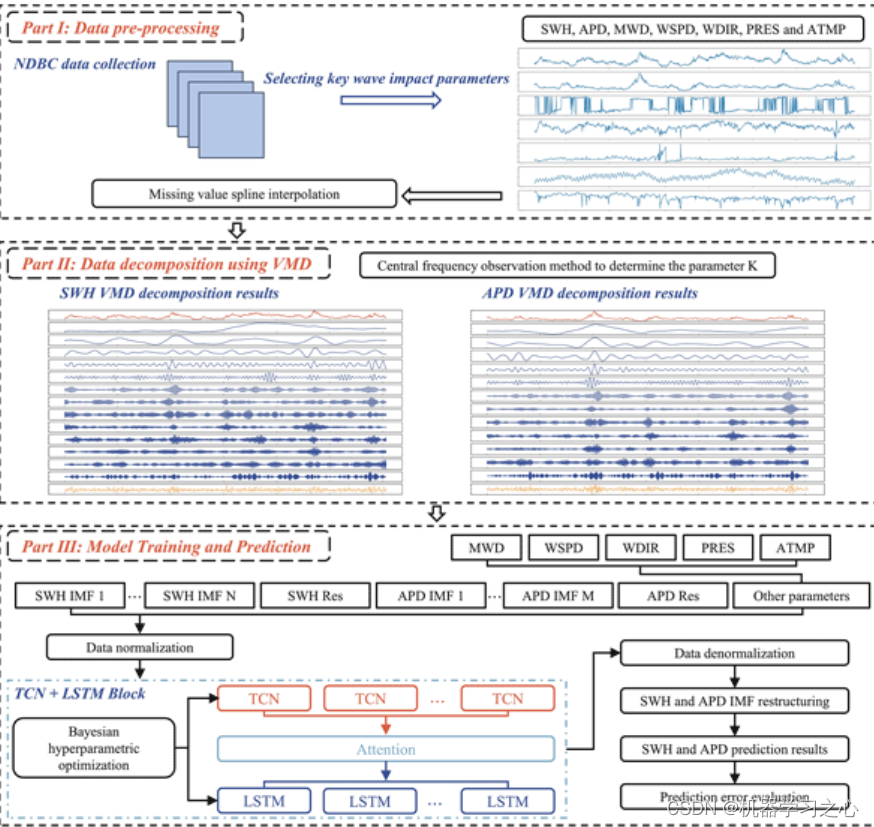
今天我们分享SENet实现遥感影像场景分类。
数据集
本次实验我们使用的是NWPU-RESISC45 Dataset。NWPU Dataset 是一个遥感影像数据集,其中 NWPU-RESISC45 Dataset 是由西北工业大学创建的遥感图像场景分类可用基准,该数据集包含像素大小为 256*256 共计 31500 张图像,涵盖 45 个场景类别,其中每个类别有 700 张图像。
这 45 个场景类别包括飞机、机场、棒球场、篮球场、海滩、桥梁、丛林、教堂、圆形农田、云、商业区、密集住宅、沙漠、森林、高速公路、高尔夫球场、地面田径、港口、工业地区、交叉口、岛、湖、草地、中型住宅、移动房屋公园、山、立交桥、宫、停车场、铁路、火车站、矩形农田、河、环形交通枢纽、跑道、海、船舶、雪山、稀疏住宅、体育场、储水箱、网球场、露台、火力发电站和湿地。
数据集划分
首先我们可以对数据集进行划分,按训练集、验证集、测试集比例7:1.5:1.5进行划分。
import os
import shutil
import random
# 设置数据集根目录
data_root = './datasets/NWPU-RESISC45'
# 设置训练集、验证集、测试集的目录
train_dir = './datasets/train'
val_dir = './datasets/val'
test_dir = './datasets/test'
# 创建目录
os.makedirs(train_dir, exist_ok=True)
os.makedirs(val_dir, exist_ok=True)
os.makedirs(test_dir, exist_ok=True)
# 获取所有子文件夹列表
class_folders = sorted(os.listdir(data_root))
# 定义训练集、验证集、测试集比例
train_ratio = 0.7
val_ratio = 0.15
test_ratio = 0.15
for class_folder in class_folders:
class_path = os.path.join(data_root, class_folder)
images = os.listdir(class_path)
random.shuffle(images) # 随机打乱顺序
num_images = len(images)
num_train = int(num_images * train_ratio)
num_val = int(num_images * val_ratio)
train_images = images[:num_train]
val_images = images[num_train:num_train + num_val]
test_images = images[num_train + num_val:]
# 移动图像到对应目录
for img in train_images:
src = os.path.join(class_path, img)
dest = os.path.join(train_dir, class_folder, img)
os.makedirs(os.path.dirname(dest), exist_ok=True)
shutil.copy(src, dest)
for img in val_images:
src = os.path.join(class_path, img)
dest = os.path.join(val_dir, class_folder, img)
os.makedirs(os.path.dirname(dest), exist_ok=True)
shutil.copy(src, dest)
for img in test_images:
src = os.path.join(class_path, img)
dest = os.path.join(test_dir, class_folder, img)
os.makedirs(os.path.dirname(dest), exist_ok=True)
shutil.copy(src, dest)
划分完毕后,数据集分别保存在train、val、test三个文件夹内。每个文件夹内有21个子文件夹分别对应21类。
SENet
SeNet(Squeeze-and-Excitation Networks)是一种卷积神经网络(CNN)架构,由Jie Hu、Li Shen和Gang Sun于2017年提出。SeNet旨在通过引入注意力机制来增强模型对重要特征的学习能力,从而提高CNN在图像分类等计算机视觉任务上的性能。 SeNet的关键创新在于引入了“Squeeze-and-Excitation”模块,这个模块可以在不增加网络复杂度的情况下,自适应地学习特征通道之间的相关性,并对每个通道进行加权,以增强重要特征的表示。它由两个关键步骤组成: Squeeze(压缩)阶段:通过全局池化操作(通常是全局平均池化),将特征图的每个通道的信息进行汇总,生成通道级别的描述信息。 Excitation(激发)阶段:在Squeeze阶段生成的描述信息基础上,引入了多层感知机(MLP)结构来学习每个通道的权重。这些权重用于重新加权特征图,以增强有助于任务的重要特征并抑制不重要的特征。 SeNet模块可以轻松地集成到各种CNN架构中,例如ResNet、Inception等,通过在这些网络中插入SeNet模块,可以提高模型的性能,使其更具有泛化能力。 SeNet的提出在图像分类、目标检测和语义分割等计算机视觉任务中取得了显著的性能提升,并成为了当时领域内的重要技术之一。 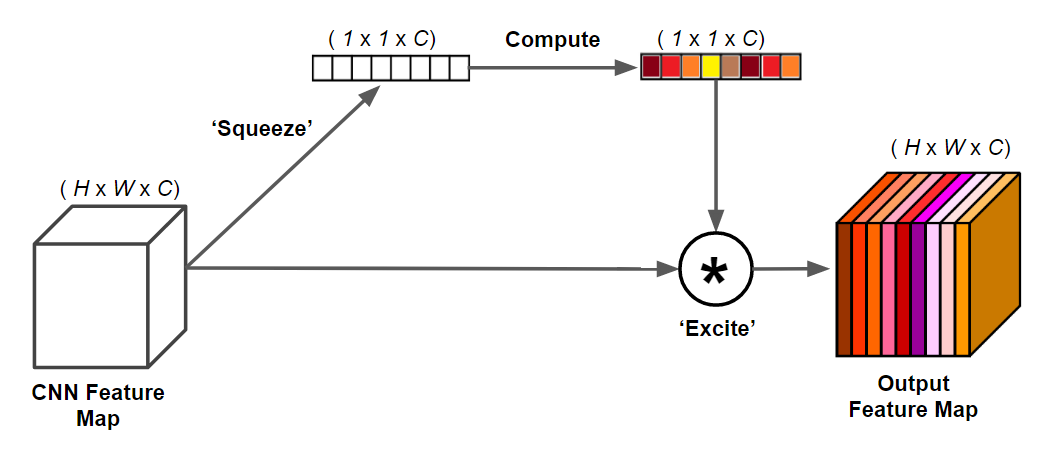
import torch.nn as nn
from torch.nn import functional as F
class Residual(nn.Module):
def __init__(self, in_channel, out_channel, use_1x1Conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(in_channel, out_channel, kernel_size=3, padding=1, stride=strides)
self.bn1 = nn.BatchNorm2d(out_channel)
self.conv2 = nn.Conv2d(out_channel, out_channel, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(out_channel)
if use_1x1Conv:
self.conv3 = nn.Conv2d(in_channel, out_channel, kernel_size=1, stride=strides)
else:
self.conv3 = None
def forward(self, X):
out = F.relu(self.bn1(self.conv1(X)))
out = self.bn2(self.conv2(out))
if self.conv3:
X = self.conv3(X)
out += X
return F.relu(out)
def residualBlock(in_channel, out_channel, num_residuals, first_block=False):
blks = []
for i in range(num_residuals):
if i == 0 and not first_block:
blks.append(Residual(in_channel, out_channel, use_1x1Conv=True,
strides=2))
else:
blks.append(Residual(out_channel, out_channel))
return blks
class SEBlock(nn.Module):
def __init__(self, C, r=16):
super().__init__()
self.squeeze = nn.AdaptiveAvgPool2d(1)
self.excitation = nn.Sequential(
nn.Linear(C, C//r, bias=False),
nn.ReLU(),
nn.Linear(C//r, C, bias=False),
nn.Sigmoid())
def forward(self, x):
bs, c, _, _ = x.shape
s = self.squeeze(x).view(bs, c)
e = self.excitation(s).view(bs, c, 1, 1)
return x * e.expand_as(x)
class SENet(nn.Module):
def __init__(self, input_channel, n_classes):
super().__init__()
self.b1 = nn.Sequential(
nn.Conv2d(input_channel, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
self.b2 = nn.Sequential(*[SEBlock(C=64)])
self.b3 = nn.Sequential(*residualBlock(64, 64, 2, first_block=True))
self.b4 = nn.Sequential(*[SEBlock(C=64)])
self.b5 = nn.Sequential(*residualBlock(64, 128, 2))
self.b6 = nn.Sequential(*[SEBlock(C=128)])
self.b7 = nn.Sequential(*residualBlock(128, 256, 2))
self.b8 = nn.Sequential(*[SEBlock(C=256)])
self.b9 = nn.Sequential(*residualBlock(256, 512, 2))
self.b10 = nn.Sequential(*[SEBlock(C=512)])
self.finalLayer = nn.Sequential(
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(),
nn.Linear(512, n_classes))
self.b1.apply(self.init_weights)
self.b2.apply(self.init_weights)
self.b3.apply(self.init_weights)
self.b4.apply(self.init_weights)
self.b5.apply(self.init_weights)
self.b6.apply(self.init_weights)
self.b7.apply(self.init_weights)
self.b8.apply(self.init_weights)
self.b9.apply(self.init_weights)
self.b10.apply(self.init_weights)
self.finalLayer.apply(self.init_weights)
def init_weights(self, layer):
if type(layer) == nn.Conv2d:
nn.init.kaiming_normal_(layer.weight, mode='fan_out')
if type(layer) == nn.Linear:
nn.init.normal_(layer.weight, std=1e-3)
if type(layer) == nn.BatchNorm2d:
nn.init.constant_(layer.weight, 1)
nn.init.constant_(layer.bias, 0)
def forward(self, X):
out = self.b1(X)
out = self.b2(out)
out = self.b3(out)
out = self.b4(out)
out = self.b5(out)
out = self.b6(out)
out = self.b7(out)
out = self.b8(out)
out = self.b9(out)
out = self.finalLayer(out)
return out
训练过程

精度与测试
「精度」
import torch
import torchvision.transforms as transforms
from torchvision import datasets
from models.SENet import SENet
# 定义测试集目录
test_dir = './datasets/test'
# 加载测试集数据
transform = transforms.Compose([
transforms.Resize((256, 256)), # 图像调整为模型输入大小
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
test_data = datasets.ImageFolder(root=test_dir, transform=transform)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=32, shuffle=False)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载模型
model = SENet(input_channel=3, n_classes=45).to(device)
model.load_state_dict(torch.load(f'SENet.pt', map_location='cuda:0'))
model.eval()
# 对测试集进行验证
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100*correct / total
print(f"Accuracy on test set: {accuracy}")

「测试」 这里我们从测试集中选取几张图片并在我们的GUI界面中进行测试看看
1
总结
感兴趣的可以按文末方式,免费获取数据集、完整代码与训练结果。
获取方法
如有需要,请关注微信公众号「DataAssassin」后,后台回复「027」领取。
更多更多内容与代码请加入我们的星球!  加入前不要忘了领取优惠券哦!
加入前不要忘了领取优惠券哦! 
本文由 mdnice 多平台发布






![buuctf[极客大挑战 2019]BabySQL--联合注入、双写过滤](https://img-blog.csdnimg.cn/img_convert/1e4e3e43bc63da5974db1263c270c6d2.png)