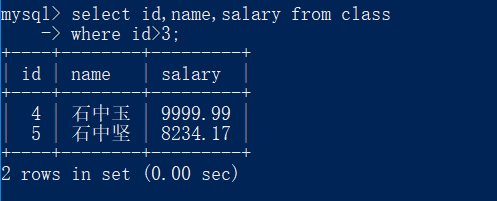
官网:https://kennycason.com/posts/2014-07-03-kumo-wordcloud.html
一:添加POM文件
<!-- 词云 -->
<dependency>
<groupId>com.kennycason</groupId>
<artifactId>kumo-core</artifactId>
<version>1.27</version>
</dependency>
<dependency>
<groupId>com.kennycason</groupId>
<artifactId>kumo-tokenizers</artifactId>
<version>1.27</version>
</dependency>二:词云图方法生成
import cn.hutool.core.lang.UUID;
import com.kennycason.kumo.CollisionMode;
import com.kennycason.kumo.WordCloud;
import com.kennycason.kumo.WordFrequency;
import com.kennycason.kumo.bg.CircleBackground;
import com.kennycason.kumo.font.KumoFont;
import com.kennycason.kumo.image.AngleGenerator;
import com.kennycason.kumo.nlp.FrequencyAnalyzer;
import com.kennycason.kumo.nlp.tokenizers.ChineseWordTokenizer;
import com.kennycason.kumo.palette.LinearGradientColorPalette;
import com.kennycason.kumo.placement.RectangleWordPlacer;
import com.*.*.bigdata.dto.GxyItemData;
import com.*.*.bigdata.entity.SchoolGeneralDataEntity;
import com.*.*.bigdata.utils.AutoReport.CreateSchoolReportV4;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.system.ApplicationHome;
import org.springframework.core.io.Resource;
import org.springframework.core.io.ResourceLoader;
import java.awt.*;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.lang.reflect.Field;
import java.net.URL;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.*;
import java.util.List;
/**
* ClasseName: WordCloud
*
* @Author: 李指导
* @Create: 2024/01/09 - 12:44
* @Version: v1.0
* Description: 通过com.kennycason生成词云图
**/
public class WordCloudUtils {
private static final Logger logger= LoggerFactory.getLogger(WordCloudUtils.class);
public static final String PATH = "src/main/resources/image/";
public static void main(String[] args) throws IOException, IllegalAccessException {
//GxyItemData 为我自己的对象 这里可以根据实际情况切换
List<GxyItemData> list = new ArrayList<>();
GxyItemData data = new GxyItemData();
data.setName("张三");
data.setName2("一年级");
data.setValue2("25");
data.setValue1("100");
data.setValue4(new double[] {100});
GxyItemData data2 = new GxyItemData();
data2.setName("李四");
data2.setName2("二年级");
data2.setValue2("74");
data2.setValue1("200");
data2.setValue4(new double[] {100});
GxyItemData data3 = new GxyItemData();
data3.setName("王五");
data3.setName2("三年级");
data3.setValue2("60");
data3.setValue1("300");
data3.setValue4(new double[] {100});
list.add(data);list.add(data2);list.add(data3);
GxyItemData dataa = new GxyItemData();
dataa.setName("马六");
dataa.setName2("一年级");
dataa.setValue2("45");
dataa.setValue1("220");
dataa.setValue4(new double[] {100});
GxyItemData dataa2 = new GxyItemData();
dataa2.setName("九七");
dataa2.setName2("二年级");
dataa2.setValue2("14");
dataa2.setValue1("1200");
dataa2.setValue4(new double[] {100});
GxyItemData dataa3 = new GxyItemData();
dataa3.setName("勾八");
dataa3.setName2("三年级");
dataa3.setValue2("40");
dataa3.setValue1("2100");
data.setValue4(new double[] {100});
list.add(dataa);list.add(dataa2);list.add(dataa3);
WordCloudUtils wordCloudUtils =new WordCloudUtils();
wordCloudUtils.createWordCountPic(list);
}
/**
* 制作词云图方法
* **/
public String createWordCountPic(List<GxyItemData> list) throws IOException {
//是一个用于分析文本中词频的工具类
FrequencyAnalyzer frequencyAnalyzer = new FrequencyAnalyzer();
//设置要返回的词频数量,这里设置为 600
frequencyAnalyzer.setWordFrequenciesToReturn(600);
//设置词的最小长度,这里设置为 2,表示忽略长度小于 2 的词。
frequencyAnalyzer.setMinWordLength(2);
//设置词的分词器,这里使用了中文的分词器 ChineseWordTokenizer,用于将中文文本拆分成单个词语。
frequencyAnalyzer.setWordTokenizer(new ChineseWordTokenizer());
// 可以直接从文件中读取
List<WordFrequency> wordFrequencies = new ArrayList<>();
// 用词语来随机生成词云
Collections.sort(list, Comparator.comparing(GxyItemData::getValue2).reversed());
//这里换成自己对象当中的参数,name和value
list.forEach(c->{
wordFrequencies.add(new WordFrequency(c.getName(),Integer.parseInt(c.getValue2())));
});
//设置图片分辨率
Dimension dimension = new Dimension(300, 300);
//此处的设置采用内置常量即可,生成词云对象
WordCloud wordCloud = new com.kennycason.kumo.WordCloud(dimension, CollisionMode.PIXEL_PERFECT);
//词频的背景为白色
wordCloud.setBackgroundColor(Color.WHITE);
//调节词云的稀疏程度,越高越稀疏
wordCloud.setPadding(0);
//字号的大小范围,最小是多少,最大是多少
//wordCloud.setFontScalar(new LinearFontScalar(10, 200));
//设置词云显示的三种颜色,越靠前设置表示词频越高的词语的颜色
//wordCloud.setColorPalette(new ColorPalette(15));
wordCloud.setColorPalette(new LinearGradientColorPalette(new Color(90,174,243), new Color(251,110,108), new Color(254,182,77), 30, 30));
// 设置字体 //此处不设置会出现中文乱码 字体设置为仿宋
wordCloud.setKumoFont(new KumoFont(new Font("楷体", Font.BOLD, 25)));
// 设置偏转角,角度为0时,字体都是水平的
wordCloud.setAngleGenerator(new AngleGenerator(2,2,2));
wordCloud.setBackground(new CircleBackground(100));
wordCloud.build(wordFrequencies);
//生成词云图路径
UUID uuid = UUID.randomUUID();
String hexString = uuid.toString().replace("-", "").substring(0,32);
//获取编译路径,这里运行后会写到改目录下,可以自定义一个目录,
String targetPath = "./output/";
//String targetPath = this.getClass().getResource("/").getPath()
String path = targetPath+hexString+".png";
// windows目录符号 \\ , 提交到linux 要改成 //
File filePath = new File(targetPath+File.separator);
if(!filePath.exists()){
filePath.mkdirs();
}
wordCloud.writeToFile(path);
return path;
}
}
测试运行结果:
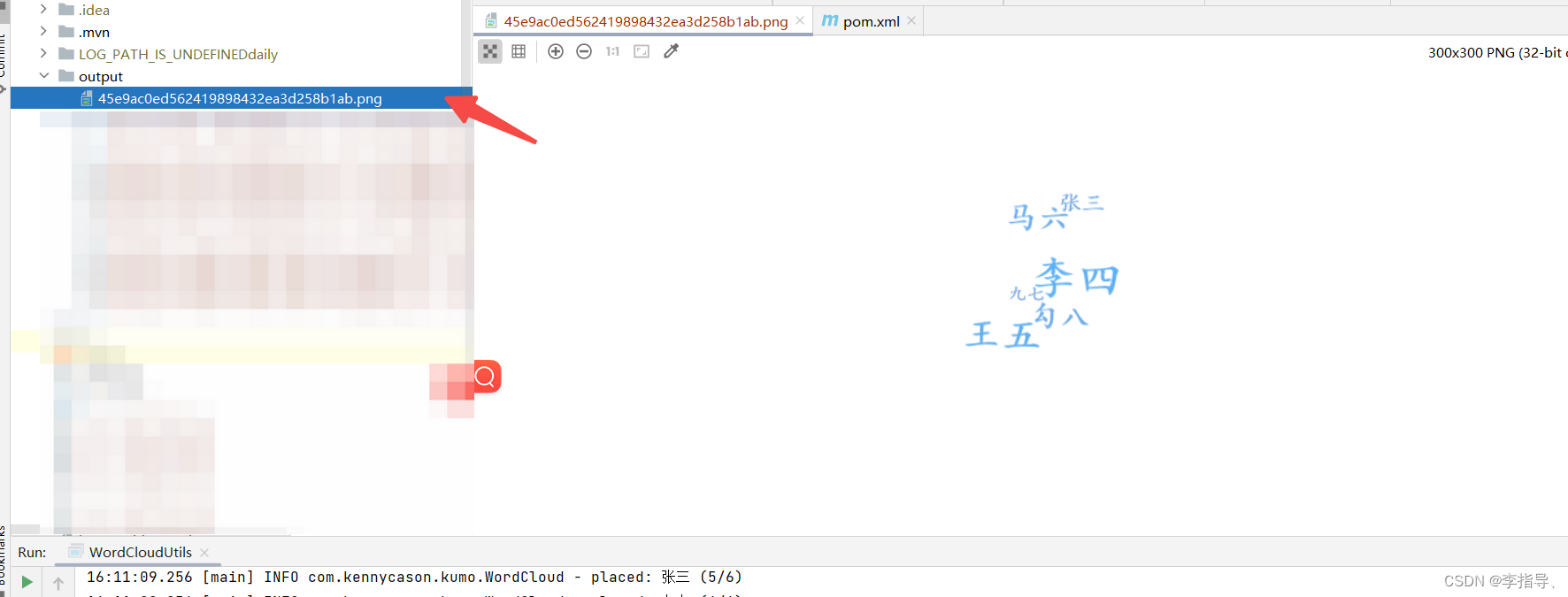 生产运行结果:
生产运行结果:

可以单独设置纬度高的词语颜色,字体稀疏度和字体的旋转角度, 都在代码当中,如果有比较好的修改建议,可以评论区留言,一起学习







![[足式机器人]Part3 机构运动学与动力学分析与建模 Ch00-2(4) 质量刚体的在坐标系下运动](https://img-blog.csdnimg.cn/direct/5d11d57df3424ac89acac118bbbde115.png)