用于回归的决策树与用于分类的决策树类似,在DecisionTreeRegressor中实现。DecisionTreeRegressor不能外推,也不能在训练数据范围之外的数据进行预测。
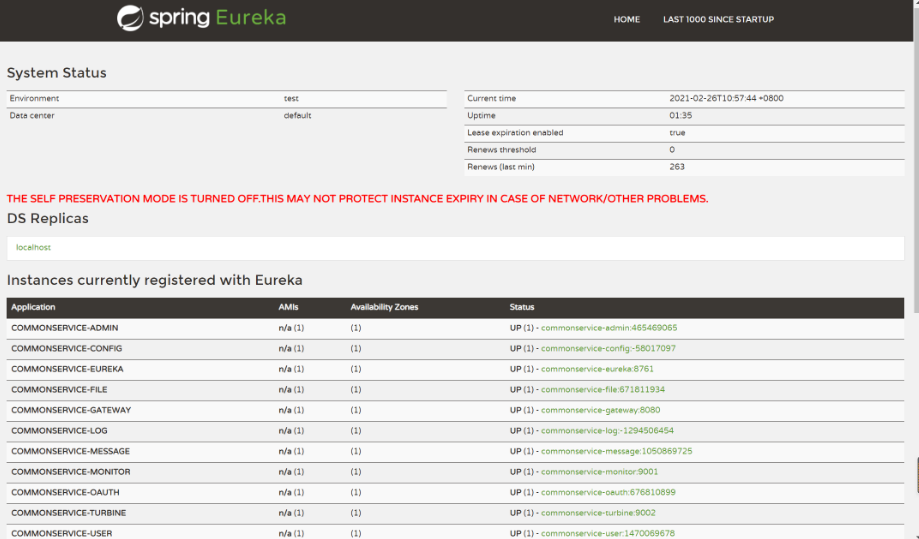
利用计算机内存历史及格的数据进行实验,数据展示:
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
ram_price=pd.read_csv('ram_price.csv')
plt.semilogy(ram_price.date,ram_price.price)
plt.xlabel('年份')
plt.ylabel('价格')
plt.show()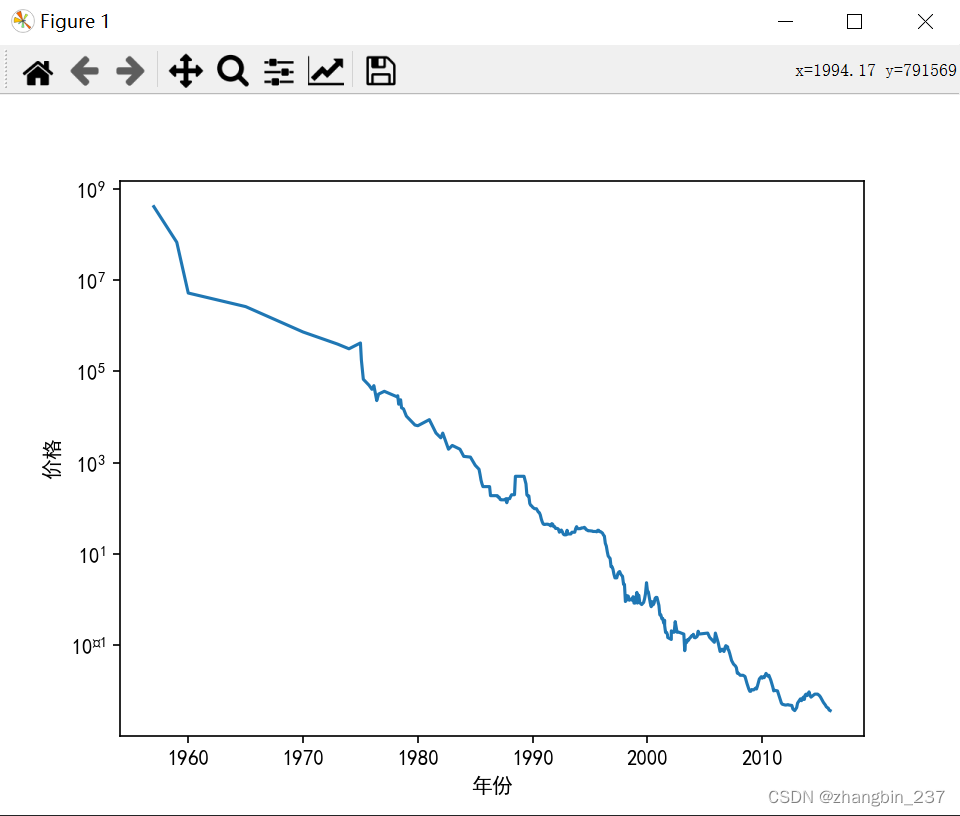
利用2000年前的历史数据来预测2000年之后的价格,只用日期作为特征,对比决策树、线性模型的预测结果:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import LinearRegression
plt.rcParams['font.sans-serif'] = ['SimHei']
ram_price=pd.read_csv('ram_price.csv')
#plt.semilogy(ram_price.data,ram_price.price)
data_train=ram_price[ram_price.date<2000]
data_test=ram_price[ram_price.date>=2000]
X_train=np.array(data_train)
#X_train=data_train.date[:, np.newaxis]
y_train=np.log(data_train.price)
tree=DecisionTreeRegressor().fit(X_train,y_train)
line_reg=LinearRegression().fit(X_train,y_train)
X_all = np.array(ram_price)
#X_all=ram_price.date[:,np.newaxis]
pred_tree=tree.predict(X_all)
pred_lr=line_reg.predict(X_all)
price_tree=np.exp(pred_tree)
price_lr=np.exp(pred_lr)
plt.semilogy(data_train.date,data_train.price,label='训练数据')
plt.semilogy(data_test.date,data_test.price,label='测试数据')
plt.semilogy(ram_price.date,price_tree,label='决策树预测')
plt.semilogy(ram_price.date,price_lr,label='线性预测')
plt.legend()
plt.show()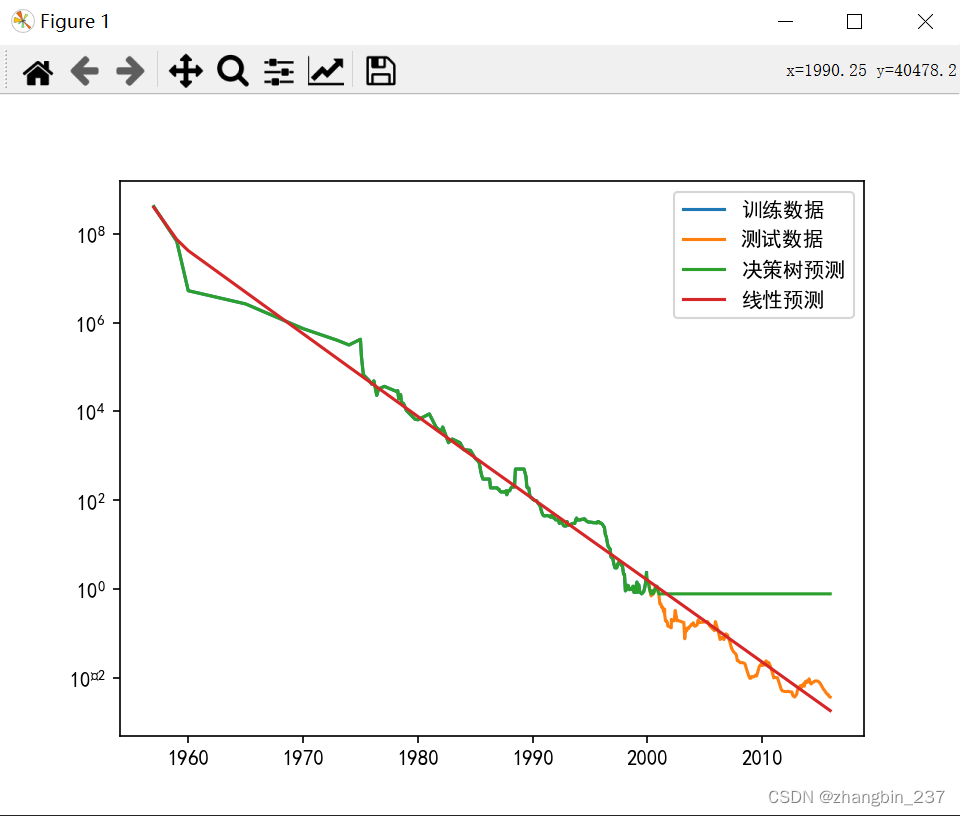
可以看到两个模型的差异非常明显。线性模型用一条直线对数据做近似,对2000年后的价格预测结果非常好,但忽略了训练数据和测试数据中一些更细微的变化。树模型则完美预测了训练数据,但一旦输入超过了模型训练数据的范围,模型就只能持续预测最后一个已知数据点。树不能在训练数据的范围之外生成新的响应,所有基于树的模型都有这个缺点。