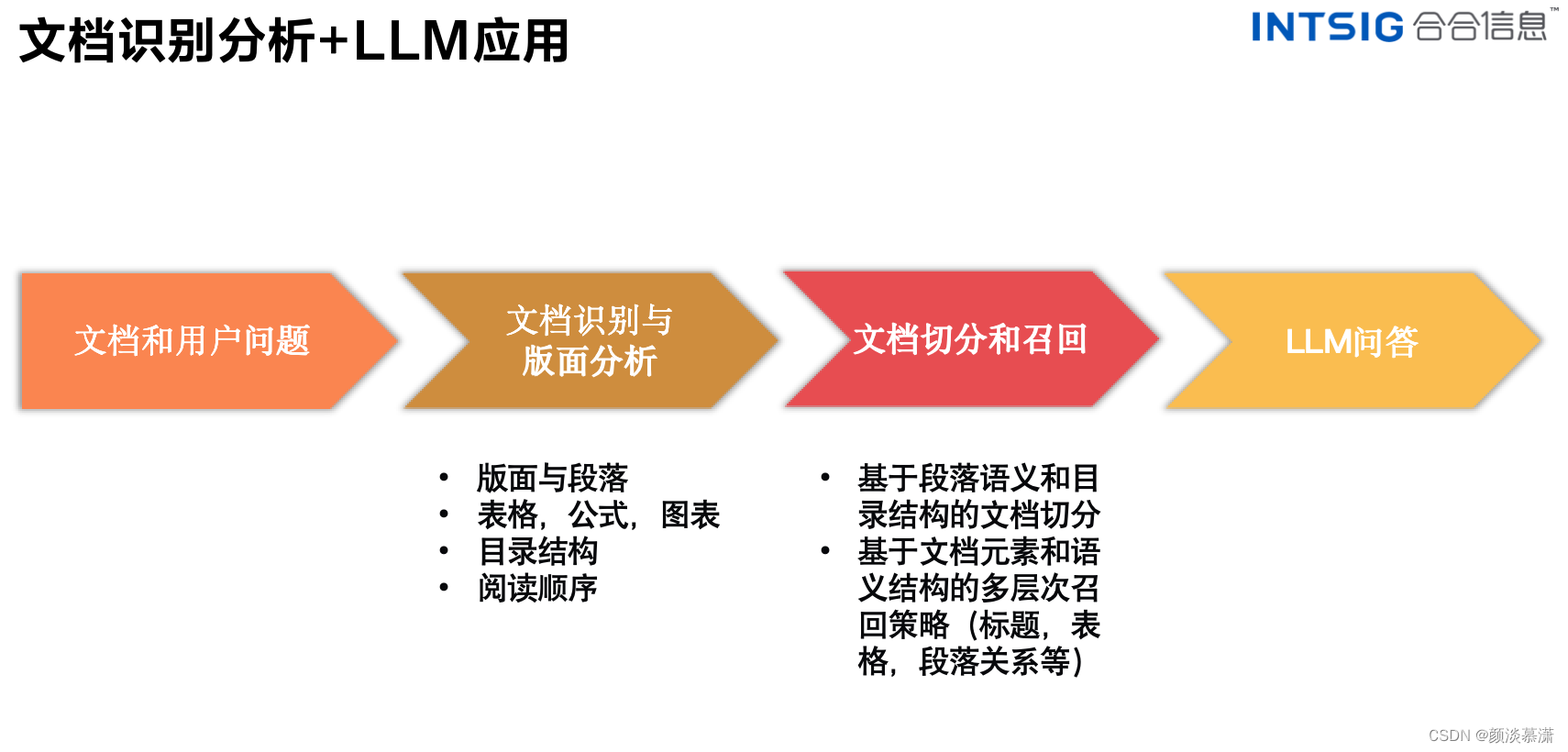
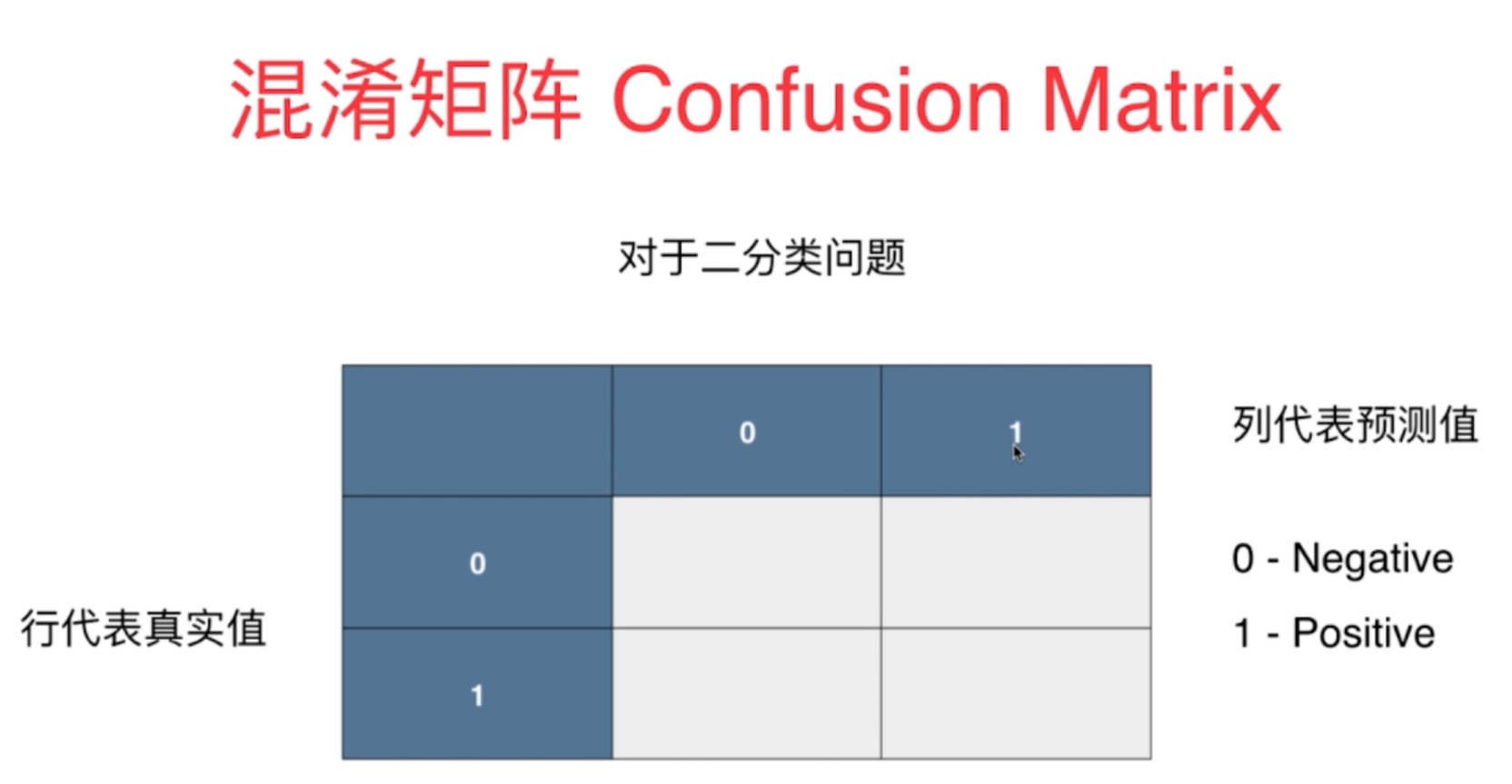
0. 混淆矩阵
其中关于 TP, TN; FP, FN 的解释;
其中
首字母 T,F代表预测的情况,即T代表预测的结果是对的, F代表预测的结果是错误的;
第二个字母代表预测是预测为 正样本,还是负样本, Positve 代表正样本;
注意,
此时这里的正样本代表的是预测属于某一类别的样本;
负样本则代表预测不属于某一类别的样本。
举例说来
- TP: True 模型预测正确, 预测为正样本Positive;
- FN: False 模型预测错误, 预测为负样本 Negative;
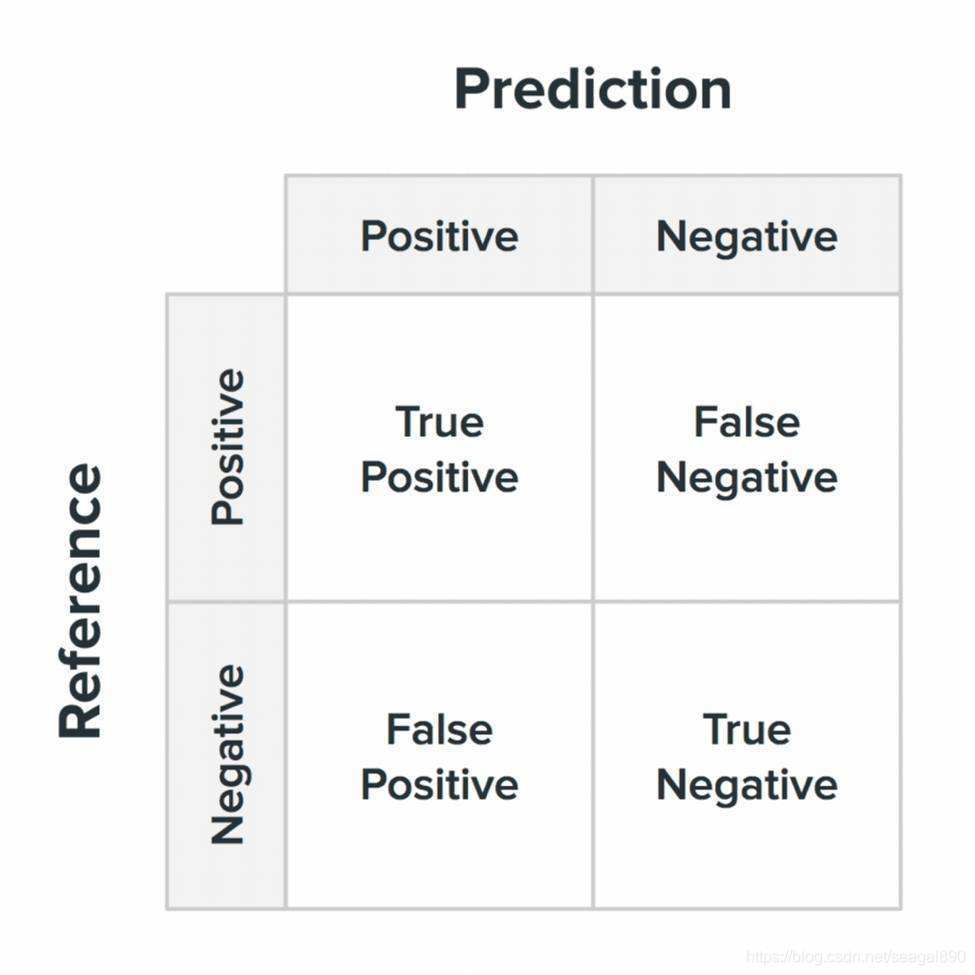
通常情况下,混淆矩阵中, 行代表真实值,列代表预测值,
此外,存在部分代码仓库, 与此不一致,使用列代表真实值,行代表预测值,
需要阅读代码的时候,通过查看文档确定;
1. 基础指标
1.1 准确率 (accuracy)
准确率:衡量正确预测的样本占总样本的比例。这是最简单的指标,
计算方式为 :
预测正确的样本数目
所有预测的样本数目
\frac{预测正确的样本数目 }{所有预测的样本数目}
所有预测的样本数目预测正确的样本数目
更具体的表达:
A c c = T P + T N T P + T N + F P + F N Acc = \frac{TP + TN }{TP + TN + FP + FN} Acc=TP+TN+FP+FNTP+TN
然而,普通的准确率不适合不平衡的数据集。
- 因为在类别不均衡的数据集中,
假设正常类别的样本数目特别多, 异常类别的样本数目很少。
此时, 正常样本的预测正确的个数很高, 但是异常类别的样本全部预测错误,
此时,在这种情况下, 整体样本的准确率仍然非常高, 然而实际情况却并非如此,因为此时异常样本的预测的准确率几乎为0;
由于样本不平衡的问题,导致了得到的高准确率结果含有很大的水分。即如果样本不平衡,准确率就会失效。
正因为如此,也就衍生出了其它两种指标:精准率和召回率。
- 准确率则代表整体的预测准确程度,包括正样本和负样本。
- 精准率代表对正样本结果中的预测准确程度, 精准率是用来衡量预测结果的;
1.2 精准率(查准率) Precision
精准率(Precision)又叫查准率,它是用来衡量预测结果的。
在预测结果为正类的数据中,有多少数据被正确预测.
- 它评估模型预测正类的准确性,计算公式为:
公式表达为,正确预测为正样本的个数占所有预测为正样本总数的比率。
P r e = T P T P + F P Pre = \frac{TP }{TP + FP } Pre=TP+FPTP
分子: True Positive: 预测正确,且预测为正样本. 即混淆矩阵中,在每一行中处于对角线位置上的值;
分母: False Positive: 预测错误, 且预测为正样本. 在混淆矩阵中,体现为每一列上, 除去对角线位置上的那个数值(代表预测正确,为正样本), 其余的都是代表了的错误的预测为正样本。
1.3 召回率(查全率) Recall (Sensitivity)
召回率(Recall)又叫查全率,它是针对原样本而言的
召回率(Recall) 是针对原样本而言的,其含义是在实际为正的样本中被预测为正样本的概率。
-
它衡量正确预测的正样本个数与所有实际正样本的比率。
-
它评估模型检测所有正实例的能力,
具体的表达:
R
e
c
a
l
l
=
T
P
T
P
+
F
N
Recall = \frac{TP }{TP + FN }
Recall=TP+FNTP
分子: True Positive: 预测正确,且预测为正样本, 即混淆矩阵中对角线上的值;
分母: False Negative : 预测错误, 且预测为负样本; 在混淆矩阵中,体现为每一行上, 除去对角线位置上的那个数值(代表预测正确,为正样本), 其余的都是代表了的错误的预测为正样本。 所以,一行上所有的数相加,便代表了该类别下,所有的正样本的个数。
例子:假设我们手上有60个正样本,40个负样本,我们要找出所有的正样本,系统查找出50个,其中只有40个是真正的正样本,计算上述各指标。
TP: 将正类预测为正类数 40
FN: 将正类预测为负类数 20
FP: 将负类预测为正类数 10
TN: 将负类预测为负类数 30
准确率(accuracy) = 预测对的/所有 = (TP+TN)/(TP+FN+FP+TN) = 70%
精确率(precision) = TP/(TP+FP) = 80%
召回率(recall) = TP/(TP+FN) = 2/3
1.4 P-R 曲线
通过上面的公式,我们发现:
精准率和召回率的分子是相同,都是TP,但分母是不同的,一个是(TP+FP),一个是(TP+FN)。两者的关系可以用一个P-R图来展示:
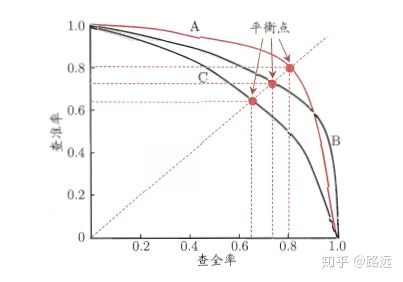
如何理解P-R(查准率-查全率)这条曲线?
有的朋友疑惑:这条曲线是根据什么变化的?为什么是这个形状的曲线? 其实这要从排序型模型说起。拿逻辑回归举例,逻辑回归的输出是一个0到1之间的概率数字,因此,如果我们想要根据这个概率判断用户好坏的话,我们就必须定义一个阈值 。通常来讲,逻辑回归的概率越大说明越接近1,也就可以说他是坏用户的可能性更大。比如,我们定义了阈值为0.5,即概率小于0.5的我们都认为是好用户,而大于0.5都认为是坏用户。因此,对于阈值为0.5的情况下,我们可以得到相应的一对查准率和查全率。
但问题是:这个阈值是我们随便定义的,我们并不知道这个阈值是否符合我们的要求。 因此,为了找到一个最合适的阈值满足我们的要求,我们就必须遍历0到1之间所有的阈值,而每个阈值下都对应着一对查准率和查全率,从而我们就得到了这条曲线。
有的朋友又问了:如何找到最好的阈值点呢? 首先,需要说明的是我们对于这两个指标的要求:我们希望查准率和查全率同时都非常高。 但实际上这两个指标是一对矛盾体,无法做到双高。图中明显看到,如果其中一个非常高,另一个肯定会非常低。选取合适的阈值点要根据实际需求,比如我们想要高的查全率,那么我们就会牺牲一些查准率,在保证查全率最高的情况下,查准率也不那么低。
但通常,如果想要找到二者之间的一个平衡点,我们就需要一个新的指标:F1分数。
1.5 F1值、
首先看下F值,该值是精确率precision和召回率recall的加权调和平均。
值越大,性能performance越好。
F值可以平衡precision少预测为正样本和recall基本都预测为正样本的单维度指标缺陷。
计算公式如下:
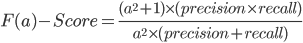
常用的是F1-Score,即a=1,所以上述公式转化为:
F1分数同时考虑了查准率和查全率,让二者同时达到最高,取一个平衡。
F1 分数:精确率和召回率的调和平均值。
- F1 分数在精确度和召回率之间提供了平衡,对这两个指标给予相同的权重。
其计算方式为
R e c a l l = 2 ∗ P r e c i s i o n ∗ R e c a l l P r e c i s o n + R e c a l l Recall = \frac {2 *Precision * Recall }{ Precison + Recall } Recall=Precison+Recall2∗Precision∗Recall
2. ROC与AUC,mAP曲线图
AUC-ROC (Area Under the Receiver Operating Characteristic Curve)
- ROC 曲线是各种阈值的真阳性率(召回率)与假阳性率(1 - 特异性)的图形表示。
- AUC-ROC 测量该曲线下的面积,并提供所有可能的分类阈值的总体性能测量
2.1 灵敏度与特异度
在正式介绍ROC/AUC之前,我们还要再介绍两个指标,这两个指标的选择也正是ROC和AUC可以无视样本不平衡的原因。
这两个指标分别是:灵敏度和(1-特异度),也叫做真正率(TPR)和假正率(FPR)。
灵敏度(Sensitivity) = TP/(TP+FN)
特异度(Specificity) = TN/(FP+TN)
其实我们可以发现灵敏度和召回率是一模一样的,只是名字换了而已。
由于我们比较关心正样本,所以需要查看有多少负样本被错误地预测为正样本,所以使用(1-特异度),而不是特异度。
真正率(TPR) = 灵敏度 = TP/(TP+FN)
假正率(FPR) = 1- 特异度 = FP/(FP+TN)
下面是真正率和假正率的示意,我们发现TPR和FPR分别是基于实际表现1和0出发的,也就是说它们分别在实际的正样本和负样本中来观察相关概率问题。
正因为如此,所以无论样本是否平衡,都不会被影响。
-
还是拿之前的例子,总样本中,90%是正样本,10%是负样本。我们知道用准确率是有水分的,但是用TPR和FPR不一样。这里,TPR只关注90%正样本中有多少是被真正覆盖的,而与那10%毫无关系,同理,FPR只关注10%负样本中有多少是被错误覆盖的,也与那90%毫无关系.
-
所以可以看出:如果我们从实际表现的各个结果角度出发,就可以避免样本不平衡的问题了,这也是为什么选用TPR和FPR作为ROC/AUC的指标的原因。
2.2 ROC(接受者操作特征曲线)
ROC(Receiver Operating Characteristic)曲线,又称接受者操作特征曲线。该曲线最早应用于雷达信号检测领域,用于区分信号与噪声。后来人们将其用于评价模型的预测能力,ROC曲线是基于混淆矩阵得出的。
ROC曲线中的主要两个指标就是真正率和假正率, 上面也解释了这么选择的好处所在。其中横坐标为假正率(FPR),纵坐标为真正率(TPR),下面就是一个标准的ROC曲线图。
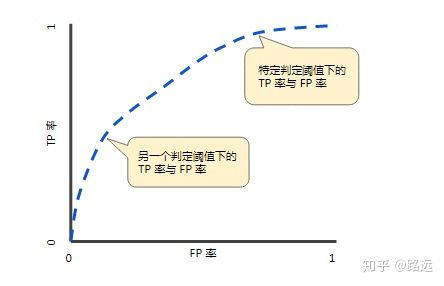
- ROC曲线的阈值问题
与前面的P-R曲线类似,ROC曲线也是通过遍历所有阈值 来绘制整条曲线的。如果我们不断的遍历所有阈值,预测的正样本和负样本是在不断变化的,相应的在ROC曲线图中也会沿着曲线滑动。
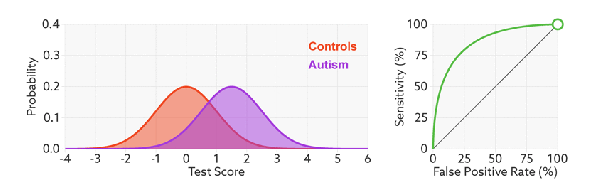
- 如何判断ROC曲线的好坏?
改变阈值只是不断地改变预测的正负样本数,即TPR和FPR,但是曲线本身是不会变的。那么如何判断一个模型的ROC曲线是好的呢?这个还是要回归到我们的目的:FPR表示模型虚报的响应程度,而TPR表示模型预测响应的覆盖程度。我们所希望的当然是:虚报的越少越好,覆盖的越多越好。所以总结一下就是TPR越高,同时FPR越低(即ROC曲线越陡),那么模型的性能就越好。 参考如下
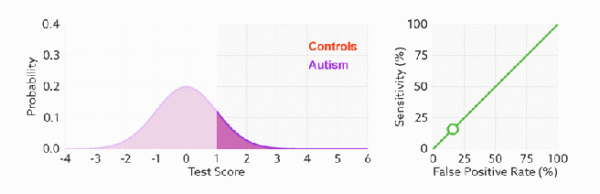
- ROC曲线无视样本不平衡
前面已经对ROC曲线为什么可以无视样本不平衡做了解释,下面我们用动态图的形式再次展示一下它是如何工作的。我们发现:无论红蓝色样本比例如何改变,ROC曲线都没有影响。
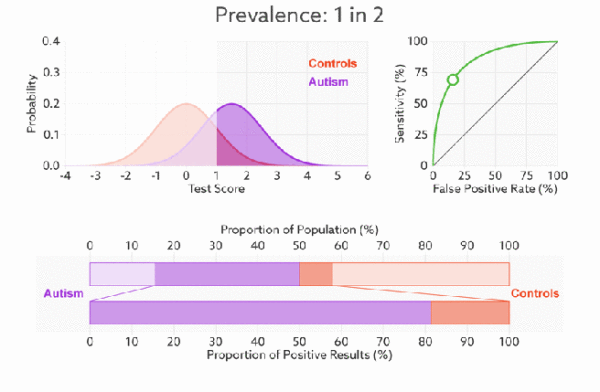
2.3 AUC
为了计算 ROC 曲线上的点,我们可以使用不同的分类阈值多次评估逻辑回归模型,但这样做效率非常低。幸运的是,有一种基于排序的高效算法可以为我们提供此类信息,这种算法称为曲线下面积(Area Under Curve)。
比较有意思的是,如果我们连接对角线,它的面积正好是0.5。对角线的实际含义是:随机判断响应与不响应,正负样本覆盖率应该都是50%,表示随机效果。
ROC曲线越陡越好,所以理想值就是1,一个正方形,而最差的随机判断都有0.5,所以一般AUC的值是介于0.5到1之间的。
AUC的一般判断标准
0.5 - 0.7: 效果较低,
0.7 - 0.85: 效果一般
0.85 - 0.95: 效果很好
0.95 - 1: 效果非常好,但一般不太可能
AUC的物理意义
曲线下面积对所有可能的分类阈值的效果进行综合衡量。曲线下面积的一种解读方式是看作模型将某个随机正类别样本排列在某个随机负类别样本之上的概率。以下面的样本为例,逻辑回归预测从左到右以升序排列:

Python中我们可以调用sklearn机器学习库的metrics进行ROC和AUC的实现,简单的代码实现部分如下:
from sklearn import metrics
from sklearn.metrics import auc
import numpy as np
y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
fpr, tpr, thresholds = metrics.roc_curve(y, scores, pos_label=2)
metrics.auc(fpr, tpr)
0.75
2.4 mAP
3. 上述代码实现
3.1 scikit-learn
上述指标中,在 Python 中使用 scikit-learn,这些指标可以计算如下:
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
# Assuming y_true contains true labels and y_pred contains predicted labels
# Calculate different evaluation metrics
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
auc_roc = roc_auc_score(y_true, y_scores) # y_scores are the predicted scores or probabilities
# Print the calculated metrics
print(f"Accuracy: {accuracy}")
print(f"Precision: {precision}")
print(f"Recall: {recall}")
print(f"F1 Score: {f1}")
print(f"AUC-ROC: {auc_roc}")
3.2 average 参数的选择
对于 precision_score 、 recall_score 和 f1_score , average 参数指定对每类指标执行平均的类型,以计算总体指标:
-
average=‘micro’ :
通过计算所有类别的真阳性、假阴性和假阳性总数来全局计算指标。然后使用这些聚合值计算指标。 -
average=‘macro’: 单独计算每个类的指标,然后取这些指标的未加权平均值。平等对待所有类别,无论类别是否不平衡。
-
average=‘weighted’ :单独计算每个类的指标,然后取这些指标的加权平均值,其中每个类的分数按其支持度(真实实例的数量)进行加权。
from sklearn.metrics import precision_score, recall_score, f1_score
# Assuming y_true contains true labels and y_pred contains predicted labels for multi-class classification
# Calculate precision, recall, and F1-score with different averaging methods
precision_micro = precision_score(y_true, y_pred, average='micro')
precision_macro = precision_score(y_true, y_pred, average='macro')
precision_weighted = precision_score(y_true, y_pred, average='weighted')
recall_micro = recall_score(y_true, y_pred, average='micro')
recall_macro = recall_score(y_true, y_pred, average='macro')
recall_weighted = recall_score(y_true, y_pred, average='weighted')
f1_micro = f1_score(y_true, y_pred, average='micro')
f1_macro = f1_score(y_true, y_pred, average='macro')
f1_weighted = f1_score(y_true, y_pred, average='weighted')
# Print the calculated metrics
print(f"Precision - Micro: {precision_micro}, Macro: {precision_macro}, Weighted: {precision_weighted}")
print(f"Recall - Micro: {recall_micro}, Macro: {recall_macro}, Weighted: {recall_weighted}")
print(f"F1 Score - Micro: {f1_micro}, Macro: {f1_macro}, Weighted: {f1_weighted}")
4. 回归任务指标
reference
-
https://www.6aiq.com/article/1549986548173
-
https://www.cnblogs.com/Yanjy-OnlyOne/p/11362315.html#:~:text=3%E3%80%81%E6%B7%B7%E6%B7%86%E7%9F%A9%E9%98%B5(Confusion%20Matrix,%E4%BB%A3%E8%A1%A8%E7%9A%84%E6%98%AF%E9%A2%84%E6%B5%8B%E5%80%BC%E3%80%82
-
机器学习,周志华
-
Python数据科学技术详解与商业实践,常国珍
-
https://developers.google.com/machine-learning/crash-course/classification/roc-and-auc
-
https://lukeoakdenrayner.wordpress.com/2018/01/07/the-philosophical-argument-for-using-roc-curves/