selenium爬取代码
webcrawl.py
import re
import time
import json
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import TimeoutException, StaleElementReferenceException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class AgriInfoSpider:
def __init__(self):
chrome_options = Options()
chrome_options.add_argument("--headless") # 无界面模式
chrome_options.add_argument("--start-maximized")
chrome_options.add_argument("--disable-extensions")
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--disable-dev-shm-usage")
chrome_options.add_argument("--no-sandbox")
self.driver = webdriver.Chrome(options=chrome_options, executable_path='C:\\Users\\Administrator\\AppData\\Local\\Google\\Chrome\\Application\\chromedriver.exe')
def save_to_json(self, item, filename):
with open(filename, 'a', encoding='utf-8') as f:
json.dump(item, f, ensure_ascii=False)
f.write('\n')
def close(self):
self.driver.quit()
# TODO
# 农业网-农业科技
def agronet(self, stop_event):
self.driver.get('http://www.agronet.com.cn/Tech/List.html')
self.driver.implicitly_wait(60)
# 获取行业
industrys = self.driver.find_elements(By.XPATH, '//dl[@class="product_classification_nav"]/dd/ul/li/a')
item = {}
order = 0
# 点击各个行业
for m, industry in enumerate(industrys):
if stop_event.is_set():
break
item["industry"] = industry.text
industry.click()
# 确保页面正确到达
# WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//dl[@class="arrow_700"]/dt/span/em[2]'), item["industry"]))
articles = self.driver.find_elements(By.XPATH, '//dl[@class="arrow_700"]/dd/ul/li')
while True:
if stop_event.is_set():
break
for i, article in enumerate(articles):
if stop_event.is_set():
break
item["order"] = order
try:
WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//dl[@class="arrow_700"]/dt/em'), "农业技术文章列表"))
except TimeoutException:
continue
# 文章标题
article = self.driver.find_elements(By.XPATH, '//dl[@class="arrow_700"]/dd/ul/li/span/a')[i]
item["title"] = article.text
item["date"] = re.search(r'\d{4}-\d{1,2}-\d{1,2}', self.driver.find_element(By.XPATH, '//dl[@class="arrow_700"]/dd/ul/li/div').text).group()
item["source"] = self.driver.find_element(By.XPATH, '//dl[@class="arrow_700"]/dd/ul/li/em').text
# 点击文章
article.click()
# 获取所有打开的窗口句柄
window_handles = self.driver.window_handles
# 切换标签页
self.driver.switch_to.window(window_handles[-1])
try:
# 获取内容
content = self.driver.find_elements(By.XPATH, '//div[@class="font_bottom"]/p')
content_lists = [c.text.strip() for c in content]
item["content"] = [''.join(content_lists)]
except:
item["content"] = []
# 写入文件
self.save_to_json(item, './results/agronet.json')
# 关闭新标签页
self.driver.close()
# 切换回原始的标签页
self.driver.switch_to.window(self.driver.window_handles[0])
order += 1
# 点击下一页
try:
if stop_event.is_set():
break
next_page = self.driver.find_element(By.XPATH, '//a[contains(text(), "下一页")]')
next_page.click()
if self.driver.current_url == 'http://www.agronet.com.cn/Message/Error?aspxerrorpath=/Tech/List':
break
except:
break
# 中国农网-三农头条
def farmer(self, stop_event):
self.driver.get('https://www.farmer.com.cn/farmer/xw/sntt/list.shtml')
# 获取所有文章
articles = self.driver.find_elements(By.XPATH, '//div[contains(@class, "index-font")]')
item = {}
order = 0
# 点击文章
while True:
if stop_event.is_set():
break
for article in articles:
if stop_event.is_set():
break
item["order"] = order
item["title"] = article.text
article.click()
# 获取所有打开的窗口句柄
window_handles = self.driver.window_handles
# 切换标签页
self.driver.switch_to.window(window_handles[-1])
# 确保到达文章详情标签页
try:
WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//div[@class="index-title"]/span[3]'), "详情"))
except TimeoutException:
continue
item["author"] = self.driver.find_element(By.XPATH, '//div[@class="index-introduce"]/ul/li[2]/span').text
item["date"] = self.driver.find_element(By.XPATH, '//div[@class="index-introduce"]/ul/div/span').text
item["source"] = self.driver.find_element(By.XPATH, '//div[@class="index-introduce"]/ul/li[1]/span').text
content = self.driver.find_elements(By.XPATH, '//div[@class="textList"]/p')
content_lists = [c.text.strip() for c in content]
item["content"] = [''.join(content_lists)]
# 写入文件
self.save_to_json(item, './results/farmer.json')
# 关闭新标签页
self.driver.close()
# 切换回原始的标签页
self.driver.switch_to.window(self.driver.window_handles[0])
order += 1
# 点击下一页
try:
if stop_event.is_set():
break
next_page = self.driver.find_element(By.XPATH, '//a[contains(text(), "下一页")]')
next_page.click()
except:
break
# 中国农业农村信息网-数据-市场动态
def agri(self,stop_event):
self.driver.get('http://www.agri.cn/sj/scdt/')
item = {}
order = 0
while True:
if stop_event.is_set():
break
# 获取所有文章
articles = self.driver.find_elements(By.XPATH, '//ul[@class="nxw_list_ul"]/li/div/div/p[1]/a')
for i, article in enumerate(articles):
if stop_event.is_set():
break
item["order"] = order
try:
WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//div[contains(@class, "title_common") and contains(@class, "title_common_w")]'), "市场动态"))
except TimeoutException:
continue
# 点击文章
article = self.driver.find_elements(By.XPATH, '//ul[@class="nxw_list_ul"]/li/div/div/p[1]/a')[i]
article.click()
# 获取所有打开的窗口句柄
window_handles = self.driver.window_handles
# 切换标签页
self.driver.switch_to.window(window_handles[-1])
# 确保到达文章详情标签页
try:
WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//div[@class="bread_nav"]/a[3]'), "市场动态"))
except TimeoutException:
continue
item["title"] = self.driver.find_element(By.XPATH, '//div[@class="detailCon_info_tit"]').text
item["date"] = re.search(r'\d{4}-\d{1,2}-\d{1,2}', self.driver.find_element(By.XPATH, '//div[@class="updateInfo_mess"]/span[1]').text).group()
item["source"] = re.search(r'来源:(.+)', self.driver.find_element(By.XPATH, '//div[@class="updateInfo_mess"]/span[3]').text).group()
try:
content = self.driver.find_elements(By.XPATH, '//div[contains(@class, "content_body_box") and contains(@class, "ArticleDetails")]/p')
content_lists = [c.text.strip() for c in content]
item["content"] = [''.join(content_lists)]
except:
item["content"] = []
# 写入文件
self.save_to_json(item, './results/agri.json')
# 关闭新标签页
self.driver.close()
# 切换回原始的标签页
self.driver.switch_to.window(self.driver.window_handles[0])
order += 1
# 点击下一页
pages_sum = re.search(r'\d+', self.driver.find_element(By.XPATH, '//font[contains(@class, "clear") and contains(@class, "jump_con")]/span[2]').text).group()
pages_cur = re.search(r'\d+', self.driver.find_element(By.XPATH, '//a[@class=" cur"]').text).group()
if pages_cur != pages_sum:
next_page = self.driver.find_element(By.XPATH, '//a[contains(text(), "下一页")]')
next_page.click()
else:
break
# 新农网-农业新闻-行业资讯
def xinnong(self, stop_event):
self.driver.get('http://www.xinnong.net/news/hangye/list_14_1.html')
self.driver.implicitly_wait(60)
item = {}
order = 0
while True:
if stop_event.is_set():
break
# 获取所有文章
articles = self.driver.find_elements(By.XPATH, '//div[@class="newslist"]/ul/li/a')
for i, article in enumerate(articles):
if stop_event.is_set():
break
item["order"] = order
try:
WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//div[@class="lsttit"]/h1'), "行业资讯"))
except TimeoutException:
continue
# 点击文章
article = self.driver.find_elements(By.XPATH, '//div[@class="newslist"]/ul/li/a')[i]
article.click()
# 获取所有打开的窗口句柄
window_handles = self.driver.window_handles
# 切换标签页
self.driver.switch_to.window(window_handles[-1])
# 确保到达文章详情标签页
try:
WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//div[@class="spos"]/a[3]'), "行业资讯"))
except TimeoutException:
continue
item["title"] = self.driver.find_element(By.XPATH, '//div[@class="arctit"]/h1').text
item["date"] = re.search(r'\d{4}-\d{1,2}-\d{1,2}', self.driver.find_element(By.XPATH, '//div[@class="arcinfo"]').text).group()
item["source"] = re.search(r'来源:(.+)', self.driver.find_element(By.XPATH, '//div[@class="arcinfo"]').text).group()
content = self.driver.find_elements(By.XPATH, '//div[@class="arcont"]/p')
content_lists = [c.text.strip() for c in content]
item["content"] = [''.join(content_lists)]
# 写入文件
self.save_to_json(item, './results/xinnong.json')
# 关闭新标签页
self.driver.close()
# 切换回原始的标签页
self.driver.switch_to.window(self.driver.window_handles[0])
order += 1
# 点击下一页
try:
if stop_event.is_set():
break
next_page = self.driver.find_element(By.XPATH, '//a[contains(text(), "下一页")]')
next_page.click()
except:
break
# 富农网-行业资讯
def richagri(self, stop_event):
self.driver.get('http://www.richagri.com/news')
item = {}
order = 0
while True:
if stop_event.is_set():
break
# 获取所有文章
articles = self.driver.find_elements(By.XPATH, '//div[@class="head"]/ul/li/a')
for i, article in enumerate(articles):
if stop_event.is_set():
break
item["order"] = order
try:
WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//div[@class="head"]/div[2]/a[2]'), "行业资讯"))
except TimeoutException:
continue
# 点击文章
article = self.driver.find_elements(By.XPATH, '//div[@class="head"]/ul/li/a')[i]
article.click()
# 确保到达文章详情标签页
try:
WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//div[@class="head"]/div[2]/a[2]'), "行业资讯"))
except TimeoutException:
continue
item["title"] = self.driver.find_element(By.XPATH, '//div[@class="head"]/b').text
item["date"] = re.search(r'\d{4}-\d{1,2}-\d{1,2}', self.driver.find_element(By.XPATH, '//div[@class="head"]/font').text).group()
content = self.driver.find_elements(By.XPATH, '//div[@class="head"]')
content_lists = [c.text.strip('\n') for c in content]
content_lists = re.search(r'时间:(\d{4}-\d{1,2}-\d{1,2})\n(.*?)(?=\n回顶部)', content_lists[0], re.S)
item["content"] = [''.join(content_lists.group(2))]
# 写入文件
self.save_to_json(item, './results/richagri.json')
# 返回原始的标签页
self.driver.back()
order += 1
# 点击下一页
try:
if stop_event.is_set():
break
next_page = self.driver.find_element(By.XPATH, '//a[contains(text(), "下页")]')
next_page.click()
except:
break
# 金农网-分析
def jinnong(self, stop_event):
self.driver.get('https://www.jinnong.cn/1002/')
# 存储已经爬取的文章链接
crawled_links = set()
item = {}
order = 0
while True:
if stop_event.is_set():
break
# 获取所有文章
articles = self.driver.find_elements(By.XPATH, '//ul[@class="left-side-items"]/li/a')
for i, article in enumerate(articles):
if stop_event.is_set():
break
article_link = article.get_attribute('href')
if article_link not in crawled_links:
item["order"] = order
try:
WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//span[@class="current-path-2"]'), "农业市场分析"))
except TimeoutException:
continue
# 点击文章
article = self.driver.find_elements(By.XPATH, '//ul[@class="left-side-items"]/li/a')[i]
article.click()
# 获取所有打开的窗口句柄
window_handles = self.driver.window_handles
# 切换标签页
self.driver.switch_to.window(window_handles[-1])
# 确保到达文章详情标签页
try:
WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//div[@class="current-path"]/span[3]'), "正文"))
except TimeoutException:
continue
item["title"] = self.driver.find_element(By.XPATH, '//div[@class="article-title"]/h1').text
item["author"] = self.driver.find_element(By.XPATH, '//div[@class="article-title"]/div/div[1]/span[3]').text
item["date"] = self.driver.find_element(By.XPATH, '//div[@class="article-title"]/div/div[1]/span[1]').text
item["source"] = re.search(r'来源:(.+)', self.driver.find_element(By.XPATH, '//div[@class="article-title"]/div/div[1]/span[2]').text).group()
content = self.driver.find_elements(By.XPATH, '//div[@class="article-conte-infor"]')
content_lists = [c.text.strip() for c in content]
item["content"] = [''.join(content_lists)]
# 写入文件
self.save_to_json(item, './results/jinnong.json')
# 记录已爬取的链接
crawled_links.add(article_link)
# 关闭新标签页
self.driver.close()
# 切换回原始的标签页
self.driver.switch_to.window(self.driver.window_handles[0])
order += 1
# 点击加载更多
button = self.driver.find_element(By.CSS_SELECTOR, '.click_more a span').text
if button == "点击加载更多":
next_page = self.driver.find_element(By.CSS_SELECTOR, '.click_more a')
self.driver.execute_script("arguments[0].click();", next_page)
# 结束
elif button == "已加载全部":
break
# 中国乡村振兴服务网-新闻动态-行业资讯
def xczxfw(self, stop_event):
self.driver.get('http://www.xczxfw.org.cn/news/12/list')
item = {}
order = 0
while True:
if stop_event.is_set():
break
# 获取所有文章
articles = self.driver.find_elements(By.XPATH, '//div[@class="zdhd"]/dl/dd/p/a')
# articles = self.driver.find_elements(By.XPATH, '//dl[@class="lb_dt"]/dd/p/a')
for i, article in enumerate(articles):
if stop_event.is_set():
break
item["order"] = order
# 点击文章
article = self.driver.find_elements(By.XPATH, '//div[@class="zdhd"]/dl/dd/p/a')[i]
# article = self.driver.find_elements(By.XPATH, '//dl[@class="lb_dt"]/dd/p/a')[i]
article.click()
# 获取所有打开的窗口句柄
window_handles = self.driver.window_handles
# 切换标签页
self.driver.switch_to.window(window_handles[-1])
# 确保到达文章详情标签页
try:
WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//div[@class="gy_1"]/span/a[2]'), "行业资讯"))
except TimeoutException:
continue
item["title"] = self.driver.find_element(By.XPATH, '//div[@class="zdhd"]/h1').text
item["date"] = re.search(r'\d{4}-\d{1,2}-\d{1,2} \d{2}:\d{2}', self.driver.find_element(By.XPATH, '//div[@class="zdhd"]/h2').text).group()
item["source"] = re.search(r'来源:(.+)', self.driver.find_element(By.XPATH, '//div[@class="zdhd"]/h2').text).group()
content = self.driver.find_elements(By.XPATH, '//div[@class="com_de"]/p')
content_lists = [c.text.strip() for c in content]
item["content"] = [''.join(content_lists)]
# 写入文件
self.save_to_json(item, './results/xczxfw.json')
# 关闭新标签页
self.driver.close()
# 切换回原始的标签页
self.driver.switch_to.window(self.driver.window_handles[0])
order += 1
# 点击下一页
try:
if stop_event.is_set():
break
next_page = self.driver.find_element(By.XPATH, '//a[contains(text(), "下一页")]')
next_page.click()
except:
break
# 农博网-农博数据中心-实用技术
def shujuaweb(self, stop_event):
self.driver.get('http://shuju.aweb.com.cn/technology/technology-0-1.shtml')
item = {}
order = 0
while True:
if stop_event.is_set():
break
# 获取所有文章
articles = self.driver.find_elements(By.XPATH, '//ul[@class="newList2"]/li/a[2]')
for i, article in enumerate(articles):
if stop_event.is_set():
break
item["order"] = order
try:
WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//h2[@class="h2s"]'), "实用技术:"))
except TimeoutException:
continue
# 点击文章
article = self.driver.find_elements(By.XPATH, '//ul[@class="newList2"]/li/a[2]')[i]
article.click()
# 获取所有打开的窗口句柄
window_handles = self.driver.window_handles
# 切换标签页
self.driver.switch_to.window(window_handles[-1])
try:
# 确保到达文章详情标签页
WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//ul[@class="sub"]/li[7]/a/span'), "实用技术"))
except TimeoutException:
continue
item["title"] = self.driver.find_element(By.XPATH, '//div[@id="content"]/div[1]/div[1]/div/p[1]').text
item["date"] = re.search(r'\d{4}年\d{1,2}月\d{1,2}日 \d{2}:\d{2}', self.driver.find_element(By.XPATH, '//div[@id="content"]/div[1]/div[1]/div/p[2]/span').text).group()
# 避免来源为空报错
source_element = self.driver.find_element(By.XPATH, '//div[@id="content"]/div[1]/div[1]/div/p[2]/span')
source_match = re.search(r'来源:(.+)', source_element.text)
item["source"] = source_match.group() if source_match else ""
content = self.driver.find_elements(By.XPATH, '//ul[@class="name"]/following-sibling::p')
content_lists = [c.text.strip() for c in content]
item["content"] = [''.join(content_lists)]
# 写入文件
self.save_to_json(item, './results/shujuaweb.json')
# 关闭新标签页
self.driver.close()
# 切换回原始的标签页
self.driver.switch_to.window(self.driver.window_handles[0])
order += 1
# 点击下一页
try:
if stop_event.is_set():
break
next_page = self.driver.find_element(By.XPATH, '//a[contains(text(), "下一页")]')
next_page.click()
except:
break
# 三农综合信息服务平台-12316头条-动态
def agri_12316(self, stop_event):
self.driver.get('http://12316.agri.cn/news/A12316dt/index.html')
self.driver.implicitly_wait(60)
item = {}
order = 0
while True:
if stop_event.is_set():
break
# 获取所有文章
articles = self.driver.find_elements(By.XPATH, '//ul[@class="dongtai_list"]/table[last()]/tbody/tr/td/li/a/p')
for i, article in enumerate(articles):
if stop_event.is_set():
break
item["order"] = order
try:
WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//p[@class="weizhi"]'), "12316头条-动态"))
except TimeoutException:
continue
# 点击文章
article = self.driver.find_elements(By.XPATH, '//ul[@class="dongtai_list"]/table[last()]/tbody/tr/td/li/a/p')[i]
article.click()
# 确保到达文章详情标签页
try:
WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//div[@class="content"]/p[1]'), "正文"))
except TimeoutException:
continue
item["title"] = self.driver.find_element(By.XPATH, '//div[@class="detail_box"]/h3').text
item["date"] = self.driver.find_element(By.XPATH, '//p[@class="zuozhe"]/span[1]/i').text
item["source"] = self.driver.find_element(By.XPATH, '//p[@class="zuozhe"]/span[2]/i').text
content = self.driver.find_elements(By.XPATH, '//div[@class="news_box"]')
content_lists = [c.text.strip() for c in content]
item["content"] = [''.join(content_lists)]
# 写入文件
self.save_to_json(item, './results/agri_12316.json')
# 返回原始的标签页
self.driver.back()
order += 1
# 点击下一页
try:
if stop_event.is_set():
break
next_page = self.driver.find_element(By.XPATH, '//a[contains(text(), "下一页")]')
next_page.click()
except:
break
# 吾谷网-农技通
def wugu(self, stop_event):
self.driver.get('http://www.wugu.com.cn/?cat=6')
self.driver.implicitly_wait(60)
item = {}
order = 0
# 获取总页数
try:
pages = self.driver.find_elements(By.XPATH, '//div[@class="nav-links"]/a')
total_pages = int(pages[1].text)
except (ValueError, IndexError):
total_pages = 1
for current_page in range(1, total_pages + 1):
if stop_event.is_set():
break
# 打开每一页
page_url = f'http://www.wugu.com.cn/?paged={current_page}&cat=6'
self.driver.get(page_url)
# 获取所有文章
articles = self.driver.find_elements(By.XPATH, '//div[@class="mg-posts-sec-inner"]/article/div/h4/a')
for i, article in enumerate(articles):
if stop_event.is_set():
break
item["order"] = order
try:
WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//div[@class="mg-breadcrumb-title"]/h1'), "分类:农技通"))
# 点击文章
article = self.driver.find_elements(By.XPATH, '//div[@class="mg-posts-sec-inner"]/article/div/h4/a')[i]
self.driver.execute_script("arguments[0].click();", article)
except TimeoutException:
continue
# 确保到达文章详情标签页
try:
WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//div[@class="mg-header"]/div[1]/a'), "农技通"))
except TimeoutException:
continue
item["title"] = self.driver.find_element(By.XPATH, '//div[@class="mg-header"]/h1/a').text
item["date"] = self.driver.find_element(By.XPATH, '//div[@class="mg-header"]/div[2]/div/span[1]').text
content = self.driver.find_elements(By.XPATH, '//div[@class="mg-blog-post-box"]/article/p')
content_lists = [c.text.strip() for c in content]
item["content"] = [''.join(content_lists)]
# 写入文件
self.save_to_json(item, './results/wugu.json')
# 返回原始的标签页
self.driver.back()
order += 1
# 新农村商网-农业资讯-政策法规
def mofcom(self, stop_event):
self.driver.get('http://nc.mofcom.gov.cn/nyzx/zcfg')
self.driver.implicitly_wait(60)
item = {}
order = 0
while True:
if stop_event.is_set():
break
# 获取所有文章
articles = self.driver.find_elements(By.XPATH, '//div[@id="showList"]/div//ul/li/h5/a')
for i, article in enumerate(articles):
if stop_event.is_set():
break
item["order"] = order
try:
WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//div[contains(@class, "w") and contains(@class, "u-nav-wrap")]/span'), "政策法规"))
except TimeoutException:
continue
# 重新获取文章列表
articles = self.driver.find_elements(By.XPATH, '//div[@id="showList"]/div//ul/li/h5/a') # 重新获取文章列表
article = articles[i] # 重新获取对应的文章元素
article_link = self.driver.find_element(By.XPATH, '//div[@id="showList"]/div//ul/li/h5/a')
try:
# 点击文章链接
self.driver.execute_script("arguments[0].click();", article_link)
except StaleElementReferenceException:
continue
# 获取所有打开的窗口句柄
window_handles = self.driver.window_handles
# 切换标签页
self.driver.switch_to.window(window_handles[-1])
# 确保到达文章详情标签页
try:
WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//div[contains(@class, "w") and contains(@class, "u-nav-wrap")]'), "正文"))
except TimeoutException:
continue
item["title"] = self.driver.find_element(By.XPATH, '//h3[@class="u-tt"]').text
item["date"] = self.driver.find_element(By.XPATH, '//span[@class="u-time"]').text
# 避免来源为空报错
source_element = self.driver.find_element(By.XPATH, '//span[@class="u-source"]')
source_match = re.search(r'信息来源:(.+)', source_element.text)
item["source"] = source_match.group() if source_match else ""
content = self.driver.find_elements(By.XPATH, '//div[@class="u-txt"]/p')
content_lists = [c.text.strip() for c in content]
item["content"] = [''.join(content_lists)]
# 写入文件
self.save_to_json(item, './results/mofcom.json')
# 关闭新标签页
self.driver.close()
# 切换回原始的标签页
self.driver.switch_to.window(self.driver.window_handles[0])
order += 1
# 点击下一页
try:
if stop_event.is_set():
break
next_page = WebDriverWait(self.driver, 20).until(EC.element_to_be_clickable((By.XPATH, '//a[contains(text(), "下一页")]')))
self.driver.execute_script("arguments[0].click();", next_page)
except:
break
# 惠农网-行业资讯-行情资讯
def cnhnb(self, stop_event):
self.driver.get('https://news.cnhnb.com/hqjd/?pi=1')
item = {}
order = 0
while True:
if stop_event.is_set():
break
# 获取所有文章
articles = self.driver.find_elements(By.XPATH, '//div[@class="latest-list"]/div/div[2]/div[1]/a')
for i, article in enumerate(articles):
if stop_event.is_set():
break
item["order"] = order
try:
WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//div[@class="ci_crumbs"]/dl/dd[2]'), "行情解读"))
except TimeoutException:
continue
# 分类
item["classify"] = self.driver.find_element(By.XPATH, '//span[@class="ct-s"]').text
# 点击文章
article = self.driver.find_elements(By.XPATH, '//div[@class="latest-list"]/div/div[2]/div[1]/a')[i]
article.click()
# 确保到达文章详情标签页
try:
WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//div[@class="ci_crumbs"]/dl/dd[2]/a'), "行情解读"))
except TimeoutException:
continue
item["title"] = self.driver.find_element(By.XPATH, '//div[@class="title"]/h1').text
item["date"] = re.search(r'\d{4}-\d{1,2}-\d{1,2} \d{2}:\d{2}', self.driver.find_element(By.XPATH, '//div[@class="d-tips"]').text).group()
# 避免来源为空报错
source_element = self.driver.find_element(By.XPATH, '//div[@class="d-tips"]')
source_match = re.search(r'来源:([^采编]+)', source_element.text)
item["source"] = source_match.group(1) if source_match else ""
content = self.driver.find_elements(By.XPATH, '//div[@class="content"]/p')
content_lists = [c.text.strip() for c in content]
item["content"] = [''.join(content_lists)]
# 写入文件
self.save_to_json(item, './results/cnhnb.json')
# 返回原始的标签页
self.driver.back()
order += 1
# 点击下一页
try:
if stop_event.is_set():
break
next_page = self.driver.find_element(By.XPATH, '//button[@class="btn-next"]')
WebDriverWait(self.driver, 20).until(EC.element_to_be_clickable(next_page))
next_page.click()
except:
break
# # 农一网 商城(舍弃)
# def agri_16899(self):
# self.driver.get('https://www.16899.com/Product/ProductList.html')
# self.driver.implicitly_wait(60)
#
# item = {}
# order = 0
# while True:
# # 获取所有文章
# articles = self.driver.find_elements(By.XPATH, '//div[@id="postData"]/div[1]/dl/dd[1]/a')
#
# for i, article in enumerate(articles):
# item["order"] = order
# try:
# WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//li[@class="selected"]/a'), "农资商城"))
# except TimeoutException:
# continue
#
# # 重新获取文章列表
# article = self.driver.find_elements(By.XPATH, '//div[@id="postData"]/div[1]/dl/dd[1]/a')[i]
# # 点击文章
# article.click()
#
# # 获取所有打开的窗口句柄
# window_handles = self.driver.window_handles
# # 切换标签页
# self.driver.switch_to.window(window_handles[-1])
#
# # 确保到达文章详情标签页
# try:
# WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//li[@class="active"]/a'), "产品介绍"))
# except TimeoutException:
# continue
#
# # 分类
# item["classify"] = self.driver.find_element(By.XPATH, '//h1[@class="pro_name"]/span[1]').text
#
# item["title"] = self.driver.find_element(By.XPATH, '//h1[@class="pro_name"]/span[2]').text
# item["price"] = self.driver.find_element(By.XPATH, '//span[@id="strongprice"]').text
#
# # 写入文件
# self.save_to_json(item, 'agri_16899.json')
#
# # 关闭新标签页
# self.driver.close()
#
# # 切换回原始的标签页
# self.driver.switch_to.window(self.driver.window_handles[0])
#
# order += 1
#
# # 点击下一页
# try:
# next_page = self.driver.find_element(By.XPATH, '//a[contains(text(), "下页")]')
# if next_page.get_attribute("class") == "disabled":
# break
# else:
# next_page.click()
# except:
# break
# 191农资人-精华帖-植保技术
def agri_191(self, stop_event):
self.driver.get('https://www.191.cn/searcher.php?digest=1&starttime=&endtime=&fid=3')
self.driver.implicitly_wait(60)
item = {}
order = 0
# 获取总页数
try:
pages = self.driver.find_elements(By.XPATH, '//div[@class="pages"]/a')
total_pages = int(pages[-1].text)
except (ValueError, IndexError):
total_pages = 1
for current_page in range(1, total_pages + 1):
if stop_event.is_set():
break
# 打开每一页
page_url = f'https://www.191.cn/searcher.php?type=special&condition=digest&authorid=&fid=3&starttime=&endtime=&page={current_page}'
self.driver.get(page_url)
# 获取所有文章
articles = self.driver.find_elements(By.XPATH, '//div[@class="dlA"]/dl/dt/a')
for i, article in enumerate(articles):
if stop_event.is_set():
break
item["order"] = order
try:
WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//li[@id="fid_3"]/a'), "植保技术"))
except TimeoutException:
continue
# 重新获取文章列表
article = self.driver.find_elements(By.XPATH, '//div[@class="dlA"]/dl/dt/a')[i]
# 点击文章
article.click()
# 获取所有打开的窗口句柄
window_handles = self.driver.window_handles
# 切换标签页
self.driver.switch_to.window(window_handles[-1])
# 确保到达文章详情标签页
try:
WebDriverWait(self.driver, 20).until(EC.text_to_be_present_in_element((By.XPATH, '//td[@id="td_tpc"]/div[1]/a'), "楼主"))
except TimeoutException:
continue
item["title"] = self.driver.find_element(By.XPATH, '//h1[@id="subject_tpc"]').text
item["date"] = self.driver.find_element(By.XPATH, '//td[@id="td_tpc"]/div[1]/span[2]').text
content = self.driver.find_elements(By.XPATH, '//div[@id="read_tpc"]')
content_lists = [c.text.strip() for c in content]
item["content"] = [''.join(content_lists)]
# 写入文件
self.save_to_json(item, './results/agri_191.json')
# 关闭新标签页
self.driver.close()
# 切换回原始的标签页
self.driver.switch_to.window(self.driver.window_handles[0])
order += 1
GUI界面代码
main.py
# 同时爬取所有网站
# import traceback
# import concurrent.futures
# from webcrawl import AgriInfoSpider
#
#
# def run_spider(spider_method):
# spider = AgriInfoSpider()
#
# try:
# spider_method()
# except Exception as e:
# print(f"{spider_method.__name__} 爬虫发生错误: {str(e)}")
# traceback.print_exc()
#
# spider.close()
#
#
# if __name__ == "__main__":
# spider_methods = [
# AgriInfoSpider().agronet,
# AgriInfoSpider().farmer,
# AgriInfoSpider().agri,
# AgriInfoSpider().xinnong,
# AgriInfoSpider().richagri,
# AgriInfoSpider().jinnong,
# AgriInfoSpider().xczxfw,
# AgriInfoSpider().shujuaweb,
# AgriInfoSpider().agri_12316,
# AgriInfoSpider().wugu,
# AgriInfoSpider().mofcom,
# AgriInfoSpider().cnhnb,
# AgriInfoSpider().agri_191,
# ]
#
# with concurrent.futures.ThreadPoolExecutor() as executor:
# executor.map(run_spider, spider_methods)
import tkinter as tk
from tkinter import messagebox
from threading import Thread, Event
from webcrawl import AgriInfoSpider
class App:
def __init__(self, root):
self.running_spiders = {} # 跟踪已经运行的爬虫
self.root = root
self.root.title("农业信息爬虫")
self.root.geometry("900x400")
self.create_listbox()
self.create_stop_button()
self.create_run_button()
def create_listbox(self):
self.listbox = tk.Listbox(self.root, bd=0, highlightthickness=0, bg=self.root.cget('bg'), selectmode=tk.SINGLE, font=('楷体', 12))
self.listbox.pack(side=tk.LEFT, fill=tk.BOTH, expand=True, padx=100, pady=70)
self.spider_functions = {
"农业网-农业科技": "agronet",
"中国农网-三农头条": "farmer",
"中国农业农村信息网-数据-市场动态": "agri",
"新农网-农业新闻-行业资讯": "xinnong",
"富农网-行业资讯": "richagri",
"金农网-分析": "jinnong",
"中国乡村振兴服务网-新闻动态-行业资讯": "xczxfw",
"农博网-农博数据中心-实用技术": "shujuaweb",
"三农综合信息服务平台-12316头条-动态": "agri_12316",
"吾谷网-农技通": "wugu",
"新农村商网-农业资讯-政策法规": "mofcom",
"惠农网-行业资讯-行情资讯": "cnhnb",
"191农资人-精华帖-植保技术": "agri_191"
}
for spider_name in self.spider_functions:
self.listbox.insert(tk.END, spider_name)
scrollbar = tk.Scrollbar(self.root, command=self.listbox.yview)
scrollbar.pack(side=tk.RIGHT, fill=tk.Y)
self.listbox.config(yscrollcommand=scrollbar.set)
def create_run_button(self):
self.run_button = tk.Button(self.root, text="运行", command=self.run_spider, font=('黑体', 12))
self.run_button.pack(side=tk.RIGHT, padx=(0, 20), pady=50)
def create_stop_button(self):
self.stop_button = tk.Button(self.root, text="停止", command=self.stop_spider, state=tk.DISABLED, font=('黑体', 12))
self.stop_button.pack(side=tk.RIGHT, padx=(20, 150), pady=50)
def run_spider(self):
selected_index = self.listbox.curselection()
if not selected_index:
messagebox.showwarning("警告", "请先选择一个爬虫")
return
selected_item = self.listbox.get(selected_index)
spider_name = self.spider_functions.get(selected_item)
if spider_name:
if spider_name in self.running_spiders:
messagebox.showinfo("提示", f"{selected_item} 爬虫已经在运行")
else:
stop_event = Event() # 创建一个Event对象
spider = AgriInfoSpider()
thread = Thread(target=self.run_spider_function, args=(spider, spider_name, stop_event))
thread.start()
self.running_spiders[spider_name] = {"thread": thread, "stop_event": stop_event} # 将新运行的爬虫加入跟踪字典
self.stop_button.config(state=tk.NORMAL) # 启用停止按钮
else:
messagebox.showwarning("警告", "选择的爬虫不存在")
def run_spider_function(self, spider, spider_name, stop_event):
try:
getattr(spider, spider_name)(stop_event)
except Exception as e:
messagebox.showerror("错误", f"爬虫运行出错: {e}")
finally:
self.root.after(0, self.update_stop_button, spider_name)
def stop_spider(self):
selected_index = self.listbox.curselection()
if not selected_index:
messagebox.showwarning("警告", "请先选择一个爬虫")
return
selected_item = self.listbox.get(selected_index)
spider_name = self.spider_functions.get(selected_item)
if spider_name and spider_name in self.running_spiders:
Thread(target=self.stop_spider_thread, args=(spider_name, selected_item)).start()
else:
messagebox.showwarning("警告", "选择的爬虫不存在或未运行")
def stop_spider_thread(self, spider_name, selected_item):
spider_info = self.running_spiders[spider_name]
spider_info["stop_event"].set()
spider_info["thread"].join()
self.root.after(0, self.update_stop_button, spider_name)
messagebox.showinfo("提示", f"{selected_item} 爬虫已停止")
def update_stop_button(self, spider_name):
del self.running_spiders[spider_name]
if not self.running_spiders:
self.stop_button.config(state=tk.DISABLED)
if __name__ == "__main__":
root = tk.Tk()
app = App(root)
root.mainloop()
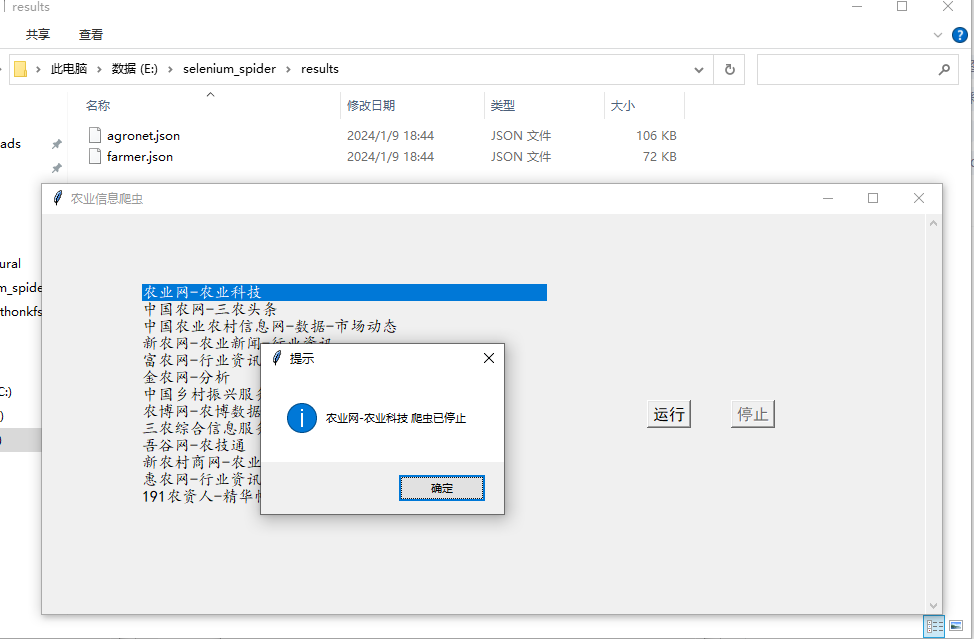
运行的GUI界面及结果如下
最开始的界面:

点击运行:
运行第二个爬虫:
停止运行: