tiktoken使用问题——ValueError: too many values to unpack (expected 2)
文章目录
- tiktoken使用问题——ValueError: too many values to unpack (expected 2)
- 前言
- 一、报错原理是什么?
- 二、解决方法
- 1.设置TIKTOKEN_CACHE_DIR为None
- 2.拉取tiktoken源码,并修改
- 总结
前言
不知道大家最近在使用langchain的时候有没有碰到这个如同鬼魅般的问题。一开始的时候一头雾水,明明1个月前还能正常运行的代码,怎么就突然不能用了。
我是在用OpenAI的embeddings的时候发现的这个问题。后面在使用memory的时候也出现了同样的问题。
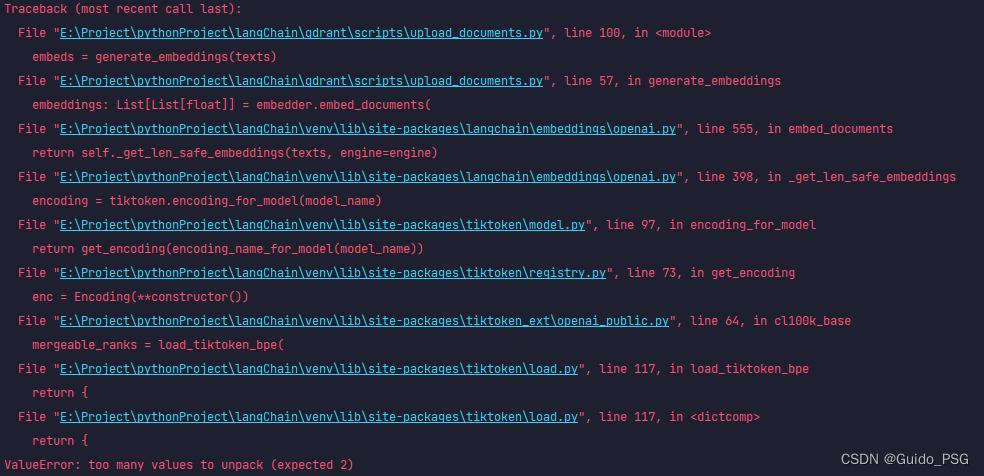
图1
一、报错原理是什么?
我们跟随图1的堆栈报错信息,找到tiktoken\load.py模块的load_tiktoken_bpe方法:
def load_tiktoken_bpe(tiktoken_bpe_file: str) -> dict[bytes, int]:
# NB: do not add caching to this function
contents = read_file_cached(tiktoken_bpe_file)
return {
base64.b64decode(token): int(rank)
for token, rank in (line.split() for line in contents.splitlines() if line)
}
很明显是因为return无法unpack,那么肯定是contents有问题。
接着进入read_file_cached方法:
def read_file_cached(blobpath: str) -> bytes:
if "TIKTOKEN_CACHE_DIR" in os.environ:
cache_dir = os.environ["TIKTOKEN_CACHE_DIR"]
elif "DATA_GYM_CACHE_DIR" in os.environ:
cache_dir = os.environ["DATA_GYM_CACHE_DIR"]
else:
cache_dir = os.path.join(tempfile.gettempdir(), "data-gym-cache")
if cache_dir == "":
# disable caching
return read_file(blobpath)
cache_key = hashlib.sha1(blobpath.encode()).hexdigest()
cache_path = os.path.join(cache_dir, cache_key)
if os.path.exists(cache_path):
with open(cache_path, "rb") as f:
return f.read()
contents = read_file(blobpath)
os.makedirs(cache_dir, exist_ok=True)
tmp_filename = cache_path + "." + str(uuid.uuid4()) + ".tmp"
with open(tmp_filename, "wb") as f:
f.write(contents)
os.rename(tmp_filename, cache_path)
return contents
根据这个函数,可以看出来这是在加载一个本地缓存文件,如果没有,那么就从网上获取,然后缓存到本地。
注意看os.rename(tmp_filename, cache_path),你在debug的时候会发现cache_path没有扩展名,导致后面读取出来的是一堆乱码,但凡把.tmp这个扩展名加上,都不会出现这个问题。
二、解决方法
按照read_file_cached方法中的思路来,有两种应对的办法。当然如果你不嫌麻烦,每次生成tmp的时候再删除也行,这也是一个方法。
1.设置TIKTOKEN_CACHE_DIR为None
在环境变量中,或者在你的入口py执行的时候,给环境变量设置成None的。
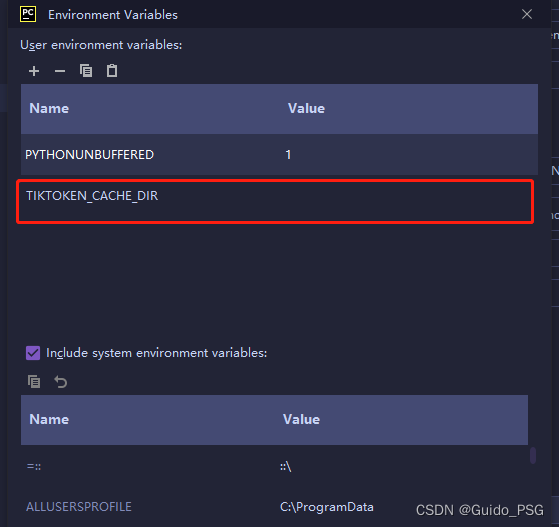
根据read_file_cached的逻辑,每次调用的时候都会去下载blobpath文件。
2.拉取tiktoken源码,并修改
如果对于时间要求比较高,那么把源码拉下来,自己进行修改。修改cache_path加上.tmp就行了。我自己亲自试过,是可行的。

总结
这算是tiktoken的源码的一个小bug吧。