有些情况下,当面临分辨率较低的图像时,可能会在进行诸如目标检测和图像分割等任务时遇到一些挑战和阻碍。这是因为低分辨率图像可能丢失了细节信息,使得计算机视觉系统难以准确捕捉和理解图像中的关键特征。在这种背景下,传统的方法可能表现不佳,因为它们通常依赖于高分辨率图像中的细微结构。
然而,谷歌的最新研究工作提出的参数化的交汇空间方法,为解决低分辨率图像中的目标检测和图像分割等任务提供了新的可能性。通过引入交汇空间参数化,该方法克服了低分辨率图像中信息丢失的问题,使计算机视觉系统能够更好地理解图像中的几何结构和特征。
本文主要介绍了一种名为 Boundary Attention 的模型,该模型能够在任何分辨率下找到微弱的边界,能够推断图像中的几何原语,如边缘、角、交叉点和均匀外观区域。此外,作者还详细描述了模型的输出以及如何利用模型进行 RGBD 图像的填充和非照片真实主义风格化。
本文的工作为计算机视觉领域带来了潜在的开创性研究,为目标检测、图像分割、图像修复等具体任务提供了新的思路和方法。
论文题目:
Boundary Attention: Learning to Find Faint Boundaries at Any Resolution
论文链接:
https://arxiv.org/abs/2401.00935
研究背景主要是针对在噪声严重影响下的图像边缘检测问题。作者认为,这个问题完全依赖于对边界的基本拓扑和几何属性的强大模型,即边界是由连接角点或交叉点的局部平滑曲线构成的。
受早期计算机视觉工作的启发,该模型提供了一种可以学习的无光栅边界推断方法,能够从深度学习中受益,同时实现了许多经典自下而上技术的优点(如对噪声的鲁棒性、亚像素精度和信号类型之间的适应性)。
▲图1 在合成数据上进行训练,面对大量噪音仍能生成准确且清晰定义的图像边界
图像表征
如图 2 所示,模型首先采用密集的邻域注意力,使用密集的、步幅为 1 的 token,尽管在图中以非重叠的形式呈现,以更清晰地展示结构。整个模型对离散空间的平移是不变的,这意味着它适用于任何分辨率的图像。每个 token 编码一个自适应大小的几何原语,用于表示像素周围未光栅化的本地边界。通过边界注意力,这些 token 逐渐变得几何一致。模型的输出是一个重叠的原语字段,这直接暗示了对输入图像的边界感知平滑和图像边界的无符号距离映射。

▲图2 模型通过密集邻域注意力的方式处理图像,以实现对图像边界的感知和平滑
边界原语(Boundary Primitives)
这部分主要讨论了如何表示局部区域的几何结构,以及如何在图像处理中利用这些结构。
作者定义了一个更大的分区簇,以包含更多种类的局部边界结构,可以用于描述边缘、角点和交叉点等。此外,还提到了一种将这些局部结构与图像的其他部分相连接的方法,即边界注意力机制。这种机制通过在像素周围密集地应用局部注意力操作,逐步优化与每个像素相关的局部边界变量场。
这个模型可以从输入图像中提取边界信息,并生成一系列可重叠的几何原语,用于生成图像边界的无符号距离函数、边界感知的平滑通道值,以及与每个像素相关的软局部注意力分布。
如图 3 所示,通过沿着光滑的轨迹在几何原语空间中取样,可以得到一系列几何原语的实例。在这些样本中,选择一个进行放大操作,并伴随着对应的距离图在右侧进行可视化展示。
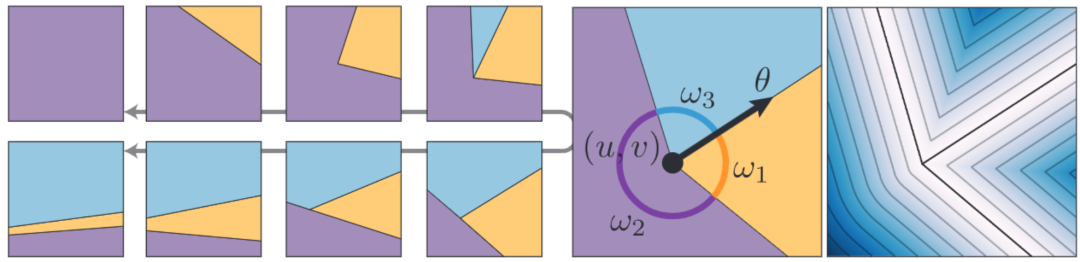
▲图3 在几何原语空间中的样本生成过程
聚集和切片操作
这是一种用于处理图像边界信息的方法,主要应用于上述提到的边界注意力模型。
-
聚集操作:将相邻像素的信息汇聚到一起,形成一个更高维度的表示,以便网络学习有意义的隐藏状态。
-
切片操作:将这些高维度表示分割成更小的块,以便进行局部操作和分析。
这两种操作相互配合,有助于网络在不同尺度上捕捉边界信息,从而提高边界定位的精度和鲁棒性。
输出可视化
如图 4 所示为模型的输出结果和可视化。
-
模型的输出:包括场景的边界感知平滑,图像边界的全局无符号距离函数,以及与每个像素相关的软局部注意力图。
-
如何可视化输出:全局无符号距离函数可以用来可视化图像边界的全局边界图。

▲图4 可视化模型的输出
此外,作者还展示了如何通过查询像素周围的几何注意力图来生成空间注意力图。如图 4 的底部两行所示,可以将输出字段的任何部分展开到它所包含的重叠区域中。
模型架构
本文提出的网络的参数比大多数边界学习检测器小几个数量级,通过迭代地优化场来逐步细化每个像素周围的局部边界。具体构件包括邻域 MLP 混合器(MLP-Mixer)、边界注意力模块、聚集与切片操作等组件。使用四种全局 loss 函数(针对全局平均场)和两种局部函数(针对每个局部块)来训练。
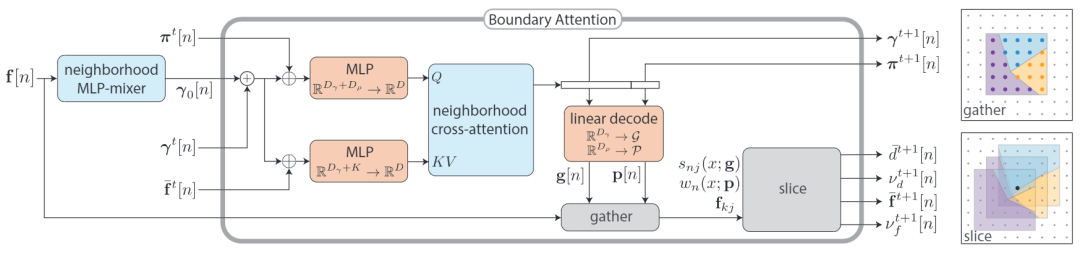
▲图5 模型架构,所有块都对图像的离散空间偏移是不变的,只有着色的块是可学习的。
如图 5 所示为模型架构,这种名为 "边界注意力" 的机制,通过密集且重复地应用,逐步优化一个变量场,该场包围每个像素的局部边界信息。
模型的输出是一系列重叠的几何原语,可以用于多种任务,包括生成图像边界的无符号距离函数、边界感知的通道值平滑以及与邻域相关的每像素软局部注意力映射。
作者分两个阶段训练网络:
-
首先训练邻域 MLP 混合器与第一个边界注意力块。
-
将第二个边界注意力块与初始权重复制添加到网络中,并对整个网络进行端到端的重新训练。
在第一阶段的训练中,他们将 loss 应用于网络的第 3 轮和第 4 轮迭代,而在端到端的优化阶段,他们将 loss 应用于第7轮和第8轮迭代。为了鼓励网络分配足够的容量以产生高质量的输出,他们将最终 loss 的权重设定为上一 loss 的三倍,这样梯度信息可以在网络中共享。
实验结果
对噪声水平的性能
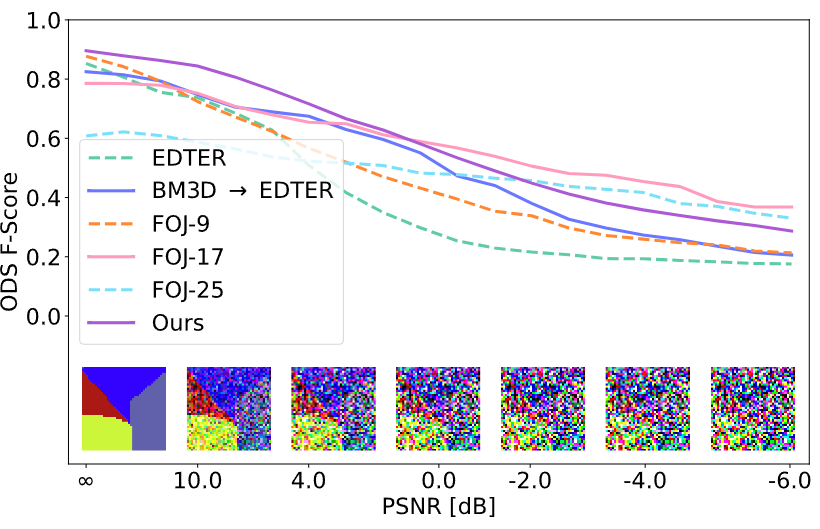
▲图6 在不同噪声水平下的 ODS F-Score
如图 6 和表 1 所示,在较低噪音水平下,本文方法优于所有 baseline 方法,并且在较高噪音水平下与 Junction 领域相媲美,同时速度快了数个数量级。

▲表1 不同方法在两个分辨率下的运行时间
亚像素精度
亚像素精度:在图像或视觉任务中能够超越像素级别的精确度。当一个算法或模型能够对目标或边界的位置进行更精细的定位,超过图像的原始像素边界时,就称之为亚像素精度。
为了测量亚像素精度,作者使用了包含重叠的圆和三角形对的高分辨率图像,获得了精确的二进制边界图。随后,他们对这些图像进行下采样至较低分辨率(125 × 125),并添加了不同程度的高斯噪声,作为模型的输入。为了评估模型的预测效果,将输出上采样回原始高分辨率(500 × 500)。相较于传统方法,本文使用了一种直观的参数形式,通过增加补丁步幅和相应地调整补丁大小,实现了保持模型输出在上采样时边界准确性。整体而言,实验结果表现出模型对于亚像素精度的处理能力,即在高分辨率图像中能够提供更为精确的目标位置定位。

▲图8 从低分辨率到高分辨率,都有着干净的边界
此外,还评估了模型在原始的 500×500 二进制图上的上采样输出,通过变化评估度量的最小距离阈值来衡量预测与真实结果的接近程度。图 7 的结果表明,即使输入图像包含加性高斯噪声,模型的 F-score 在所有匹配阈值上仍然保持较高水平。

▲图7 合成图像的 ODS F-score 和 PSNR
连接空间的线性插值
该实验观察到网络在隐藏状态中学到了一个空间平滑的连接流形。图 9 的可视化结果显示了这个学习的连接空间的一些特性。结果表明,嵌入空间呈现平滑的特性,有趣的是,它学会将零与近乎相等的角度和接近补丁中心的顶点关联起来。
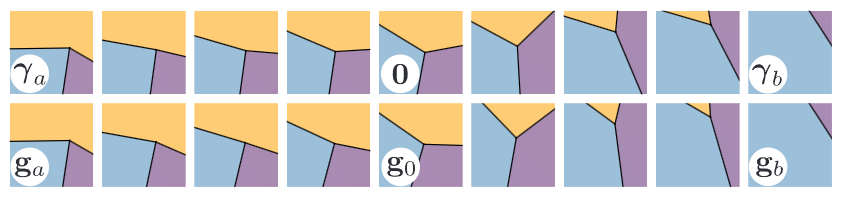
▲图9 该嵌入学会了平滑且直观的零
随时间推移的输出演化
实验结果显示在细化过程中距离图的演变。图 10 的可视化结果表明,早期迭代是探索性和无结构的,而后续迭代逐渐趋于一致,呈现出更加有序和一致的区域边界。这突显了网络在细化过程中逐渐完善和协调局部边界信息的能力。

▲图10 迭代过程中边界的演变
在真实图像上的结果
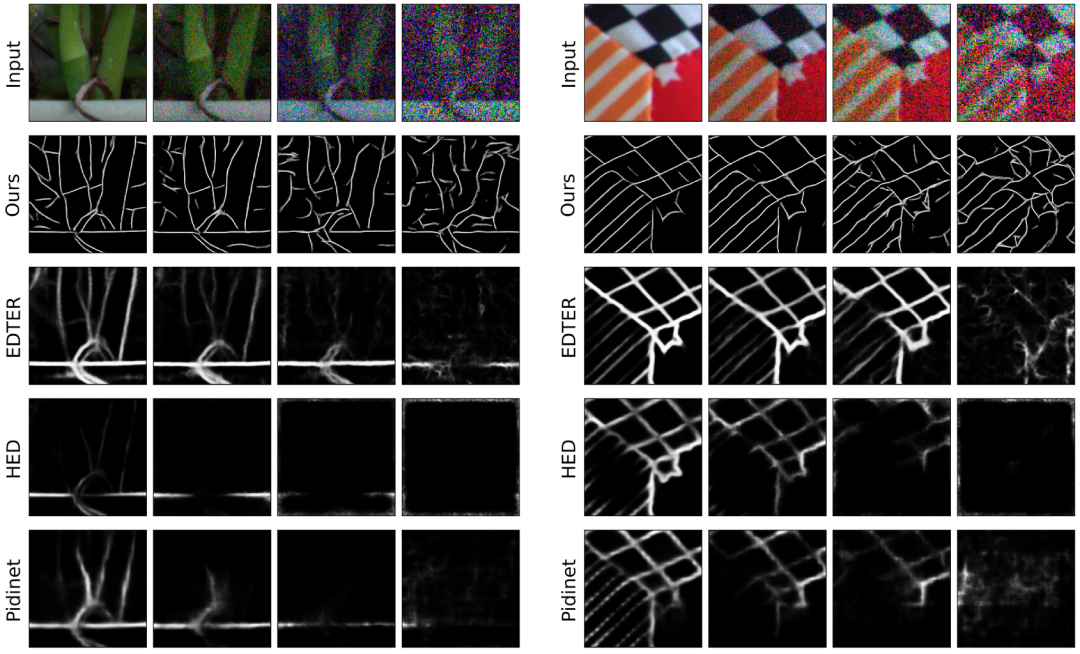
图 1 和 11 展示了在真实图像上的结果。尽管在合成数据上进行训练,本文的方法可以在 ELD 中存在的多个真实传感器噪声水平上胜过现有的 SOTA 方法,在高噪声水平下产生清晰且定义良好的边界。
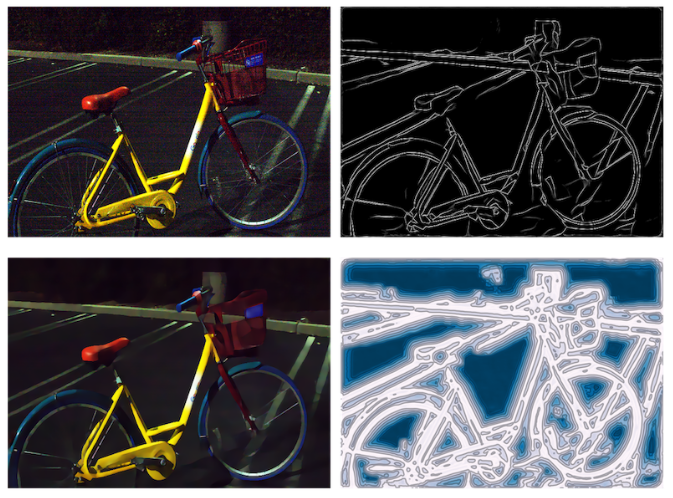
▲图11 模型对真实图像具有很好的泛化能力,在自然图像中能够找到准确的边界
总结
谷歌新发布的这项工作,引入了边界注意力模型,一个能够学习的专门用于推断未经栅格化图像边界的方法。
在实验中,作者验证了该模型在极大噪音污染的图像中找到边界的效果,并展示了其在处理真实传感器噪声的优越性。与现有方法相比,模型在较低噪音水平下表现更优,且在高噪音水平下与其他方法相媲美,同时运行速度更快。
本文的研究不仅推动了图像边界推断的技术边界,尤其是在不同分辨率的图像中,还为理解和利用几何原语在图像中的表达提供了新的思路。期待作者能够进一步优化和扩展这一模型,以更好地满足计算机视觉实际场景中目标检测、图像分割、图像修复等任务对图像边界处理的需求。