前言
在【OpenVoice本地部署教程与踩坑记录】一文中介绍了OpenVoice的基本概念与,并且完成了项目的安装与运行。官方给的示例和用法中仅包含了文本转TTS再克隆音色的功能,仅能用于TTS场景下的文字朗读。
本文基于官方示例改造,实现了实时采集麦克风音频进行语音克隆的功能。在阅读项目论文理论后,少量修改了官方源码,取得了不错的实测效果。
论文
项目论文可以在这里查看【OpenVoice: Versatile Instant Voice Cloning】,我将原文机器翻译成了中文,也可以参考中文版的论文【百度网盘,提取码: d7ja】。
阅读论文后可以知道,OpenVoice将 IVC 任务解耦为独立的子任务,与耦合任务相比,每个子任务都更容易实现,音调颜色的克隆与所有其余风格参数和语言的控制完全分离。我们也可以不依赖原有的TTS,可以使用本地录音进行音色转换。在阅读完论文和相关代码后发现大部分为音频数据的基础数学计算,未包含前后强逻辑关联,故我们可以引入Buff的概念,将音频数据一段一段的送入转换,所以实时音频转换从理论上是可行的。
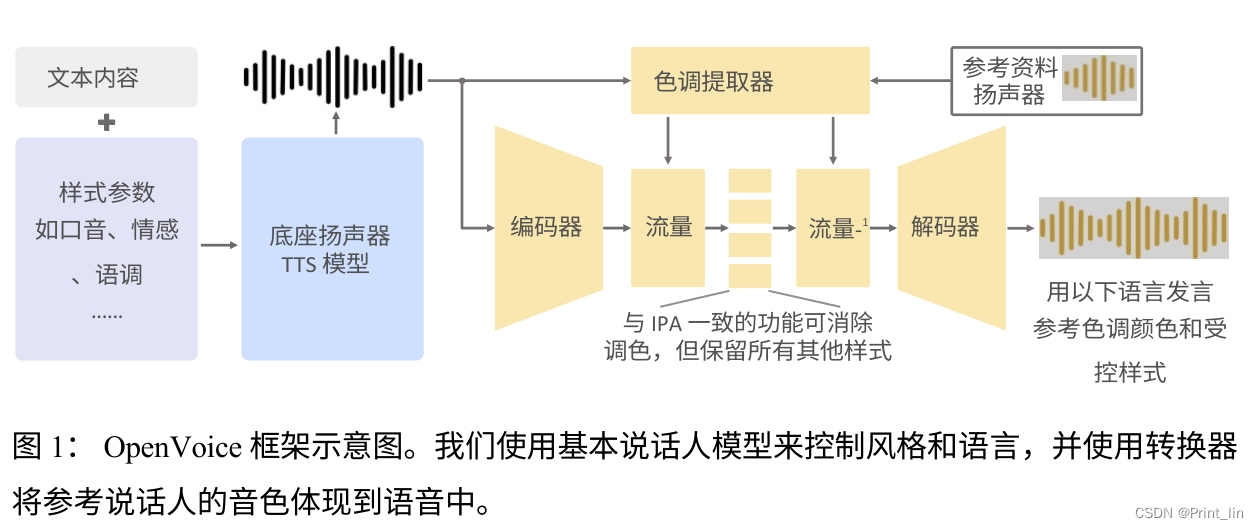
*我不是专业研究员,上述内容如有错误还望不吝赐教
实现
我们实现的基本思路是利用pyaudio库从麦克风实时采集np.float32的音频数据,然后传入到convert方法中进行转换,将转换后的结果同样通过pyaudio库播放即可。
pyaudio安装
使用pip下载pyaudio库即可正常使用:
pip install pyaudiopyaudio基础使用
关于pyaudio的基础使用可以参考网上的其它文章,这个库用起来不复杂,仅需要简单配置即可,我让chatGPT帮我写了一个测试示例供大家参考:
import pyaudio
import numpy as np
def play_and_record():
# 设置参数
FORMAT = pyaudio.paInt16
CHANNELS = 1 # 单声道
RATE = 44100 # 采样率,您可以根据需要调整
CHUNK = 1024 # 每次读取的样本数
p = pyaudio.PyAudio()
# 打开麦克风
stream_in = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
# 打开扬声器
stream_out = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
output=True,
frames_per_buffer=CHUNK)
print("开始录音并播放...")
try:
while True:
# 从麦克风读取数据
data = stream_in.read(CHUNK)
# 将数据写入扬声器以播放
stream_out.write(data)
except KeyboardInterrupt:
print("停止录音并播放。")
stream_in.stop_stream()
stream_in.close()
stream_out.stop_stream()
stream_out.close()
p.terminate()
if __name__ == '__main__':
play_and_record()
运行上述代码后,您应该能够从麦克风采集声音并立即通过扬声器播放。请注意,此示例简单地读取和播放声音,没有进行任何处理或分析。
OpenVoice修改
经过上文的入门后,相信你对OpenVoice的运行方式有了一个基础认识,OpenVoice核心的方法就是通过convert调用转换,要求我们传入源文件、目标输出、相关音色文件等参数,调用的代码看起来像这样:
tone_color_converter.convert(
audio_src_path=src_path,
src_se=source_se,
tgt_se=target_se,
output_path=save_path,
message=encode_message)我们进入convert方法里面,可以看到是使用librosa库读取音频文件,采样率为22050(hps.data.sampling_rate中定义)。然后转换为torch数据传入后文进行处理,进行上文提到的音频数据的基础数学计算(OpenVoice框架图中的黄色部分),在处理完成后得到audio原始数据,最后进行添加水印的操作后存储到目标文件或直接返回。这里的代码十分清晰明了,完整的还原了框架图中的步骤,我们的改造不必关心底层的处理逻辑,到API这一层已经足够满足功能了。
def convert(self, audio_src_path, src_se, tgt_se, output_path=None, tau=0.3, message="default"):
hps = self.hps
# load audio
audio, sample_rate = librosa.load(audio_src_path, sr=hps.data.sampling_rate)
audio = torch.tensor(audio).float()
with torch.no_grad():
y = torch.FloatTensor(audio).to(self.device)
y = y.unsqueeze(0)
spec = spectrogram_torch(y, hps.data.filter_length,
hps.data.sampling_rate, hps.data.hop_length, hps.data.win_length,
center=False).to(self.device)
spec_lengths = torch.LongTensor([spec.size(-1)]).to(self.device)
audio = self.model.voice_conversion(spec, spec_lengths, sid_src=src_se, sid_tgt=tgt_se, tau=tau)[0][
0, 0].data.cpu().float().numpy()
audio = self.add_watermark(audio, message)
if output_path is None:
return audio
else:
soundfile.write(output_path, audio, hps.data.sampling_rate)在理解了官方代码后,我们加入断点进行debug查看各个环节的数据流转。librosa库读取出来的是float32的np数组格式的音频数据,最后生成的audio也是float32的np数组格式的音频数据,我们需要保证实时音频满足相应的数据格式。我们仅需完成以下步骤的改造即可:
- 使用pyaudio采集22050采样率的float32格式的音频
- 将pyaudio读取到的byte数据转为np数组
- 修改入参,传入实时音频数据而不是音频文件地址
- 取消librosa文件读取相关代码
- 取消水印代码,因为加水印对音频时长有要求
- 取消文件保存相关代码,直接返回原始音频数组
我们的核心思路是将一整段音频文件转换的方式变为一小段一小段的实时音频转换的方式,所以需要引入buff的概念,经过实测发现我们的buff长度最好不低于10000(0.9s),这个参数可以在pyaudio中进行配置,完整的代码如下:
import pyaudio
import numpy as np
import torch
import se_extractor
from api import ToneColorConverter
ckpt_converter = 'checkpoints/converter'
# 使用CPU推理
device = 'cpu'
tone_color_converter = ToneColorConverter(f'{ckpt_converter}/config.json', device=device)
tone_color_converter.load_ckpt(f'{ckpt_converter}/checkpoint.pth')
# 欲克隆的声音,建议自行录制一段其他人的音频,官方例子是英语,对中文不太友好
reference_speaker = 'resources/example_reference.mp3'
target_se, _ = se_extractor.get_se(reference_speaker, tone_color_converter, target_dir='processed', vad=True)
# 当前说话人的音色文件,可以录音一段然后通过上面的方法生成,在processed文件夹中就可以找到
source_se = torch.load(f'processed/yl3/se.pth').to(device)
def play_and_record():
# 设置参数
FORMAT = pyaudio.paFloat32
CHANNELS = 1 # 单声道
RATE = 22050 # 采样率,固定
BUFF = 10000 # 每次读取的样本数,每段的音频长度
BUFF_OUT = 9984 # 每次播放的样本数,convert后长度有一定变化,避免产生杂音
p = pyaudio.PyAudio()
# 打开麦克风
stream_in = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=BUFF)
# 打开扬声器
stream_out = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
output=True,
frames_per_buffer=BUFF_OUT)
print("开始录音并播放...")
try:
while True:
# 从麦克风读取数据
data = stream_in.read(BUFF)
# 转换为np数组
data = np.frombuffer(data, dtype=np.float32)
# 实时变音
audio = tone_color_converter.convertRealTime(
audio_data= data,
src_se=source_se,
tgt_se=target_se)
# 将数据写入扬声器以播放
stream_out.write(audio.tobytes())
except KeyboardInterrupt:
print("停止录音并播放。")
stream_in.stop_stream()
stream_in.close()
stream_out.stop_stream()
stream_out.close()
p.terminate()
if __name__ == '__main__':
play_and_record()
修改api.py文件,加入convertRealTime方法:
def convertRealTime(self, audio_data, src_se, tgt_se, tau=0.3):
hps = self.hps
# 重采样,可选
# audio = librosa.resample(audio_data, orig_sr=16000, target_sr=22050)
audio = torch.tensor(audio_data).float()
with torch.no_grad():
y = torch.FloatTensor(audio).to(self.device)
y = y.unsqueeze(0)
spec = spectrogram_torch(y, hps.data.filter_length,
hps.data.sampling_rate, hps.data.hop_length, hps.data.win_length,
center=False).to(self.device)
spec_lengths = torch.LongTensor([spec.size(-1)]).to(self.device)
audio = self.model.voice_conversion(spec, spec_lengths, sid_src=src_se, sid_tgt=tgt_se, tau=tau)[0][
0, 0].data.cpu().float().numpy()
# 直接返回音频数据
return audio优化
如果一切顺利,我相信你已经跑起来了,并可以实时的听到你说出的话被正常采集和变音。不过你会发现CPU利用率会一直很高,因为我们持续不断的在采集和处理麦克风的数据,即使没有任何人在说话。为了解决这一问题,我们需要进行静音检测,在音频能量值(响度)大于某一个阈值时才激活音频转换,这样可以避免不必要的消耗。
在实现的过程中会发现基于每个音频包的静音检测会有一定的延迟并会导致丢字的现象,原因不难理解,我们上文提到buff的长度未10000,这是一个很大的值,会引入大约0.9s的延迟。如果我们说话的起始音处于buff的靠后位置,这样程序还是会认为我们处于静音状态,直到下一个包才激活,这样就会丢失最开始的一个字。反之亦然,如果结束音处于buff的靠前位置,那么就会丢失末尾的一个字。
我们需要将10000长度的buff进行拆分,只要存在超过阈值的响度就认为是激活状态,这样就可以避免首字或尾音丢失的问题。在从激活到静音的过程中,我们引入了一个静音包的过渡,这样会更好的保证音频的自然度。
上述的优化方案很简单,不过实际效果还是很不错,因为时间有限,未进行更深入的研究,希望社区能够共创更优的解决方案。
优化后的完整代码:
import pyaudio
import numpy as np
import torch
import se_extractor
from api import ToneColorConverter
ckpt_converter = 'checkpoints/converter'
# 使用CPU推理
device = 'cpu'
tone_color_converter = ToneColorConverter(f'{ckpt_converter}/config.json', device=device)
tone_color_converter.load_ckpt(f'{ckpt_converter}/checkpoint.pth')
# 欲克隆的声音,建议自行录制一段其他人的音频,官方例子是英语,对中文不太友好
reference_speaker = 'resources/example_reference.mp3'
target_se, _ = se_extractor.get_se(reference_speaker, tone_color_converter, target_dir='processed', vad=True)
# 当前说话人的音色文件,可以录音一段然后通过上面的方法生成,在processed文件夹中就可以找到
source_se = torch.load(f'processed/yl3/se.pth').to(device)
# 上一次静音状态缓存,用于尾音平滑
lastSilence = True
# 静音阈值(根据实际需求调整)
THRESHOLD_ENERGY = 0.05
# 静音检测
def is_silence(frame):
# 将10000的buff拆分为2000,减少延迟,提高灵敏度
for i in range(5):
# 计算能量
energy = np.sum(frame[i*2000 : (i+1)*2000] ** 2) / len(frame[i*2000 : (i+1)*2000])
print(energy)
# 检测音频帧是否为静音
if energy > THRESHOLD_ENERGY:
# 只要有一个buff超过阈值就返回不是静音
return False
# 是静音
return True
def play_and_record():
# 设置参数
FORMAT = pyaudio.paFloat32
CHANNELS = 1 # 单声道
RATE = 22050 # 采样率,固定
BUFF = 10000 # 每次读取的样本数,每段的音频长度
BUFF_OUT = 9984 # 每次播放的样本数,convert后长度有一定变化,避免产生杂音
p = pyaudio.PyAudio()
# 打开麦克风
stream_in = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=BUFF)
# 打开扬声器
stream_out = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
output=True,
frames_per_buffer=BUFF_OUT)
print("开始录音并播放...")
try:
while True:
# 从麦克风读取数据
data = stream_in.read(BUFF)
# 转换为np数组
data = np.frombuffer(data, dtype=np.float32)
# 当前静音状态
currSilence = is_silence(data)
# 当前是静音 且 上次是静音,保证一个包的平滑过渡
if currSilence and lastSilence:
print("静音")
else:
print("有声音")
# 实时变音
audio = tone_color_converter.convertRealTime(
audio_data= data,
src_se=source_se,
tgt_se=target_se)
# 将数据写入扬声器以播放
stream_out.write(audio.tobytes())
# 缓存上次状态
lastSilence = currSilence
except KeyboardInterrupt:
print("停止录音并播放。")
stream_in.stop_stream()
stream_in.close()
stream_out.stop_stream()
stream_out.close()
p.terminate()
if __name__ == '__main__':
play_and_record()
*如果本文对您有帮助,求三连(点赞、收藏、关注)





![[ArkUI开发技巧] 应用的全屏式沉浸适配](https://img-blog.csdnimg.cn/img_convert/33e3392fdf5e46acbc1b182ccc1dc0eb.webp?x-oss-process=image/format,png)