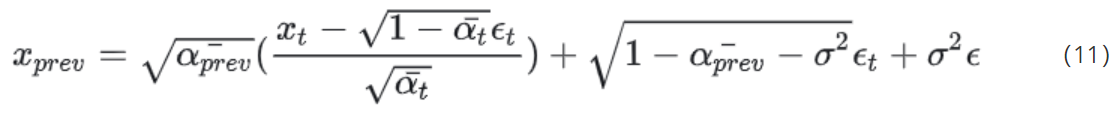文章信息
论文题目:Defeating DNN-Based Traffic Analysis Systems in Real-Time With Blind Adversarial Perturbations
期刊(会议):30th USENIX Security Symposium
时间:2021
级别:CCF A
文章链接:https://www.usenix.org/system/files/sec21-nasr.pdf
概述
对抗性扰动是各种图像处理应用中的一个活跃研究领域(称为对抗性样本)。然而,在网络流量中应用对抗性扰动并不是简单的,因为它面临两个主要挑战。首先,扰动实体,应能在实时网络流量上应用他的对抗性扰动,而不需要缓冲目标流量或了解即将到来的网络数据包的模式。这是因为在大多数流量分析应用中,扰动实体不能影响目标流量的生成,但他只能截取目标流量的数据包并实时进行扰动。第二,网络流量上的任何扰动机制都应该保留流量模式的各种约束,例如不同流量特征之间的依赖关系、来自底层协议的时序/大小统计分布等。
在本文中,我们首次设计了对抗性干扰实时网络流量的技术,以击败基于DNN的流量分类器;我们称我们的方法为盲对抗性扰动。我们的技术对出现在网络上的实时数据包应用对抗性扰动。我们的对抗性扰动算法的关键思想是,通过解决特定的优化问题来生成独立于目标输入的“盲”扰动。我们针对流量分析应用中常用的关键功能设计了对抗性扰动机制:我们的对抗性扰动包括更改数据包的时间和大小,以及插入虚拟网络数据包。
我们的盲目对抗扰动算法是通用的,可以应用于各种类型的流量分类器。我们通过将我们的技术实现为Tor可插拔传输来证明这一点,并在最先进的网站指纹识别(DeepFingerprinting)和流相关技术(DeepCorr)上对其进行评估。我们的评估表明,我们的对抗性扰动可以通过小的、实时的对抗性扰动有效地击败基于DNN的流量分析技术。我们的盲对抗扰动还可以在不同模型和架构之间转移,这表明它们的实际重要性,因为它们可以由黑盒对手实现。
准备工作
问题陈述
我们的问题:击败基于DNN的流量分析算法。最先进的流量分析技术使用深度神经网络,其性能远高于先前的技术。然而,深度学习模型因容易受到各种对抗性攻击而臭名昭著,在对抗性攻击中,对抗者会对输入添加微小的扰动来误导深度学习模型。这种技术在图像处理中被称为对抗样本,但在流量分析领域还没有被研究过。在这项工作中,我们研究了通过对抗性扰动击败基于DNN 的流量分析技术的可能性。
在我们的设置中,一些“流量分析方”出于各种目的使用基于DNN的流量分析技术。另一方面,流量分析方的对手旨在通过对其截获的连接的流量模式进行对抗性扰乱来干扰流量分析过程。为此,流量分析对手会扰乱截获流量的流量模式,以降低流量分析方使用的基于DNN的分类器的准确性。为了进一步明确参与者之间的区别,在流关联场景中,流量分析方可以是恶意的互联网服务提供商,其目的是通过分析Tor用户的Tor连接来实现去匿名化;流量分析方的对手可以是Tor中继,其目的是干扰流量模式以击败潜在的流量分析攻击。
挑战:我们的问题类似于图像分类中的对抗样本场景。然而,在网络流量中应用对抗性扰动会面临两大挑战。首先,对抗者应该能够在实时网络连接上应用对抗性扰动,而对抗者并不知道即将到来的网络数据包的模式。这是因为在流量分析场景中,对抗者并不负责生成流量模式。例如,在流量关联场景中,流量分析方的对手是一个良性的Tor中继,拦截并(轻微)扰乱Tor用户产生的流量。应用网络对抗扰动的第二个挑战是,它们应该保留网络流量的各种约束条件,例如不同流量特征的依赖关系。
我们的方法概述:在这项工作中,我们设计了盲对抗扰动,这是一套用于执行对抗性网络扰动的技术,可以克服上述两个挑战。为了应对第一个挑战(应用于实时流量),我们设计了独立于目标连接的盲扰动向量,因此它们可以应用于任何(未知)网络流量。图1显示了与传统(非盲)扰动技术相比,我们的盲对抗所需的条件。盲对抗者可能仍然需要知道目标网络协议的一些通用信息(如典型噪声模型、典型数据包大小分布等),以及来自相同底层分布的流量样本(如Tor流量样本),但不需要知道将到达目标连接的实际流量包。我们通过解决一个特定的优化问题来生成这种盲对抗扰动。为了应对第二个挑战(执行网络约束条件),我们通过使用各种重映射函数和正则调整器,调整扰动流量特征以遵循所需的约束条件。根据应用的不同,我们的扰动技术可能需要部署在多个端点上。

威胁模型
我们使用对抗性扰动的目的只是为了防御“基于DNN”的流量分析机制;因此,非DNN流量分析技术,如流水印和基于体积的流量分类器,不在我们的研究范围之内。未来的工作可以将我们的防御与针对此类非DNN机制的防御结合起来。此外,我们的工作只考虑了基于DNN的流量分析技术,即使用流量模式(即数据包时间、大小和方向)进行分类的技术,而没有考虑使用数据包内容进行分类的技术。因此,使用数据包内容签名的恶意软件分类器不在我们的研究范围内。我们的对抗扰动技术可应用于任何使用原始流量特征(如数据包时序、数据包间延迟、方向、流量、数据包计数等)进行分析的(基于模式的)流量分析技术。这包括大多数基于模式的流量分析系统。另一方面,我们的技术可能无法简单地应用于使用流量特征的不可微和不可逆函数的流量分析算法,如时间的哈希值或数据包内容的熵。将我们的技术应用于这类系统,需要我们提出特定的重映射函数或近似梯度函数。
敌手模型
对手对目标流量的了解:我们假设对手事先不知道即将被扰动的目标连接的网络数据包模式。但是,对手可能需要知道目标网络协议的一些通用统计信息(如抖动的分布),以及目标协议的规格(如Tor数据包的格式);需要这些信息来确保所应用的扰动在统计和语义上都是不可检测的。
对手对模型的了解:我们从对手可以白盒访问目标模型开始,即对手知道目标DNN模型的架构和参数。然后,我们利用技术的可移植性,将攻击扩展到黑盒环境,即对手不知道目标模型的架构或参数。
对手对训练数据的了解:我们假设对手知道一组与目标模型训练数据集分布相同的样本。例如,在网站指纹识别应用中,对手可以浏览要被错误分类的目标网站,以获得此类训练样本。
攻击目标:我们根据对手的源目标和目的目标(定义如下),考虑了四种类型的攻击,即ST-DT、ST-DU、SU-DT和SU-DU:
- 目标定向/非目标定向攻击(DT/DU):如果对手的目标是让模型将任意输入错误分类为特定的目标输出类别,我们就称这种攻击为目标定向攻击(DT)。另一方面,如果攻击的目标是将输入错误地分类到任意(不正确)的输出类别中,我们就称这种攻击为 “非目标定向攻击”(DU)。
- 源定向/非源定向攻击(ST/SU):源定向(ST)攻击者的目标是使特定输入类别的输入被流量分析模型错误分类。相比之下,非源定向(SU)对抗者的目标是使任意输入类别被错误分类。
基础知识
深度学习
深度神经网络由一系列线性和非线性函数组成,称为层。每一层都有一个权重矩阵
w
i
w_{i}
wi和一个激活函数。对于给定的输入
x
\boldsymbol{x}
x,我们用以下方式表示DNN 模型的输出:
f
(
x
)
=
f
n
W
n
(
f
n
−
1
W
n
−
1
(
⋯
f
1
W
1
(
x
)
)
⋯
)
f(\boldsymbol{x})=f_{n}^{W_{n}}(f_{n-1}^{W_{n-1}}(\cdots f_{1}^{W_{1}}(\boldsymbol{x}))\cdots )
f(x)=fnWn(fn−1Wn−1(⋯f1W1(x))⋯)
其中,
f
i
W
i
f_{i}^{W_{i}}
fiWi是深度神经网络的第i层(注意,我们使用粗体字母来表示向量)。我们的重点是监督学习,即我们有一组标注的训练数据。设X为目标d维空间中的一组数据点,其中每个维度代表输入数据点的一个属性。我们假设有一个预言机O,它能将数据点映射到其标签上。为简单起见,我们只关注分类任务。
训练的目标是找到一个分类模型f,将X中的每个点映射到类别集合Y中的正确类别。为了得到f,我们需要定义一个有下限的实值损失函数
l
(
f
(
x
)
,
O
(
x
)
)
l(f(\boldsymbol{x}),O(\boldsymbol{x}))
l(f(x),O(x)),该函数用于度量每个数据点
x
\boldsymbol{x}
x的
O
(
x
)
O(\boldsymbol{x})
O(x)与模型预测值
f
(
x
)
f(\boldsymbol{x})
f(x)之间的差值。因此,f的损失函数可定义为
L
(
f
)
=
E
(
x
,
y
)
∼
P
r
(
X
,
Y
)
[
l
(
f
(
x
)
,
y
)
]
L(f)= \underset{(\boldsymbol{x},y)\sim Pr(X,Y)}{\mathbb{E}} [l(f(\boldsymbol{x}),y)]
L(f)=(x,y)∼Pr(X,Y)E[l(f(x),y)]
训练的目标就是找到一个最小化该损失函数的f。由于Pr(X,Y)并不完全是训练实体所能获得的,因此在实践中,会使用其中的一组样本(称为训练集
D
t
r
a
i
n
⊂
X
×
Y
D^{train}\subset X\times Y
Dtrain⊂X×Y)来训练模型。因此,机器学习算法不是最小化上面那个式子,而是最小化模型在训练集D上的预期经验损失:
L
D
train
(
f
)
=
1
∣
D
train
∣
∑
(
x
,
y
)
∈
D
train
l
(
f
(
x
)
,
y
)
\mathrm{L}_{D^{\text {train }}}(f)=\frac{1}{\left|D^{\text {train }}\right|} \sum_{(\boldsymbol{x}, y) \in D^{\text {train }}} l(f(\boldsymbol{x}), y)
LDtrain (f)=∣Dtrain ∣1(x,y)∈Dtrain ∑l(f(x),y)
对抗样本
对抗样本是一种对抗性输入,它能欺骗目标分类器或回归模型,使其做出错误的分类或预测。对抗者的目标是通过对输入数据属性添加最小的扰动来生成对抗示例。因此,可以通过求解以下优化问题来生成对抗示例
x
∗
\boldsymbol{x} ^{*}
x∗:
x
∗
=
x
+
arg
min
{
z
:
O
(
x
+
z
)
≠
O
(
x
)
}
=
x
+
δ
x
\boldsymbol{x}^{*}=\boldsymbol{x}+\arg \min \{z: O(\boldsymbol{x}+\boldsymbol{z}) \neq O(\boldsymbol{x})\}=\boldsymbol{x}+\boldsymbol{\delta}_{x}
x∗=x+argmin{z:O(x+z)=O(x)}=x+δx
其中,
δ
x
\boldsymbol{\delta}_{x}
δx是对其添加的对抗扰动,
O
(
⋅
)
O(\boldsymbol{·})
O(⋅)代表输入的真实标签。对抗者的目标是添加最小的扰动
δ
x
\boldsymbol{\delta}_{x}
δx来迫使目标模型对输入
x
\boldsymbol{x}
x进行错误分类。对抗样本通常在图像分类应用中进行研究,其中寻找对抗样本的一个限制条件是,添加的噪声应是人眼无法察觉的。在本文中,我们将研究在具有不同不可感知约束条件的网络连接上应用对抗样本的问题。
流量分析技术
流量关联:流量关联的目的是通过关联流量特征(即数据包的时间和大小)来连接被混淆的网络流量。特别是Tor匿名系统一直是流关联攻击的目标。在这种攻击中,攻击者的目的是通过对流量特征的相关性将Tor连接的入口段和出口段连接起来。传统的流量关联技术主要使用标准的统计相关度量来关联跨流量的流量时序和大小向量,特别是互信息、皮尔逊相关性、余弦相似性和斯皮尔曼相关性。最近,Nasr 等人设计了一种基于DNN的流量相关方法,称为DeepCorr。他们的研究表明,DeepCorr远远优于统计流量相关技术。
网站指纹识别:网站指纹(WF)旨在检测通过VPN、Tor和其他代理服务器等加密渠道访问的网站。这种攻击由一个被动的对手实施,它监控受害者的加密网络流量,例如恶意的互联网服务提供商或监控机构。敌方将观察到的受害者流量与一组预先录制的网页痕迹进行比较,以识别正在浏览的网页。网站指纹识别与流量相关性不同,对手只观察连接的一端,例如客户端与Tor中继器之间的连接。网站指纹识别技术在Tor流量分析方面得到了广泛研究。
盲对抗扰动
一般表述
我们将盲对抗扰动问题表述为以下优化问题:
arg
min
δ
∀
x
∈
D
S
:
f
(
x
+
δ
)
≠
f
(
x
)
\arg \min _{\boldsymbol{\delta}} \forall \boldsymbol{x} \in D^{S}: f(\boldsymbol{x}+\boldsymbol{\delta}) \neq f(\boldsymbol{x})
argδmin∀x∈DS:f(x+δ)=f(x)
其中,目标是找到一个(盲)扰动向量
δ
\boldsymbol{\delta}
δ,当它添加到来自目标输入域
D
S
D^{S}
DS的任意输入时,会导致潜在的DNN 模型
f
(
⋅
)
f(·)
f(⋅)错误分类。在源定向(ST) 攻击中,
D
S
D^{S}
DS包含来自目标类别的输入,这些输入将被错误分类;而在非源定向(SU)攻击中,
D
S
D^{S}
DS将是来自不同类别的大量输入集合。需要注意的是,由于目标模型
f
(
⋅
)
f(·)
f(⋅)是一个非凸ML模型,即深度神经网络,因此无法找到该优化问题的闭式解。因此,上式可以表述如下,利用经验近似技术对问题进行数值求解:
arg
max
δ
∑
x
∈
D
S
l
(
f
(
x
+
δ
)
,
f
(
x
)
)
\arg\max_{\boldsymbol{\delta}}\sum_{\boldsymbol{x}\in \mathcal{D}^S}l(f(\boldsymbol{x}+\boldsymbol{\delta}),f(\boldsymbol{x}))
argδmaxx∈DS∑l(f(x+δ),f(x))
其中,l是目标模型的损失函数,
D
S
⊂
D
S
\mathcal{D}^{S} \subset D^{S}
DS⊂DS是对手的网络训练数据集。
我们的目标是找到一个扰动生成器模型G,当提供一个随机触发参数z时,这个生成器模型G将生成对抗性扰动向量(我们将相应的对抗性扰动表示为
δ
z
=
G
(
z
)
\boldsymbol{\delta}_{z}=G(z)
δz=G(z)),也就是说,我们能在不同的随机z上生成不同的扰动。因此,我们优化问题的目标是优化扰动发生器模型G的参数(而不是优化扰动向量)。使用生成器模型可以提高攻击性能,因此我们将优化问题表述为
arg
max
G
E
z
∼
uniform
(
0
,
1
)
[
∑
x
∈
D
S
l
(
f
(
x
+
G
(
z
)
)
,
f
(
x
)
)
]
\arg \max _{G} \underset{z \sim \text { uniform }(0,1)}{\mathbb{E}}\left[\sum_{\boldsymbol{x} \in \mathcal{D}^{S}} l(f(\boldsymbol{x}+G(z)), f(\boldsymbol{x}))\right]
argGmaxz∼ uniform (0,1)E[x∈DS∑l(f(x+G(z)),f(x))]
结合流量约束
针对图像识别应用的对抗样本研究只是对图像像素值进行了单独修改。然而,在网络流量上应用对抗性扰动则更具挑战性,因为在应用扰动时需要保留网络流量的各种约束条件。特别是,数据包间延迟应为非负值;目标网络协议可能需要遵循特定的数据包大小/时间分布;数据包不应从连接中删除;以及数据包编号应在注入新数据包后进行调整。
我们还可以根据底层网络协议添加其他网络约束。我们使用重映射和正则化函数来执行这些领域约束,同时创建盲对抗扰动。重映射函数会调整扰动流量模式,使其符合某些领域约束条件。例如,当对手在位置i处的流量中添加一个数据包时,重映射函数应移动所有连续数据包的索引。因此,我们通过加入重映射函数M来重新表述优化问题:
arg
max
G
E
z
∼
uniform
(
0
,
1
)
[
∑
x
∈
D
S
l
(
f
(
M
(
x
,
G
(
z
)
)
)
,
f
(
x
)
)
]
\arg \max _{G} \underset{z \sim \text { uniform }(0,1)}{\mathbb{E}}\left[\sum_{\boldsymbol{x} \in \mathcal{D}^{S}} l(f(\mathcal{M}( \boldsymbol{x},G(z))), f(\boldsymbol{x}))\right]
argGmaxz∼ uniform (0,1)E[x∈DS∑l(f(M(x,G(z))),f(x))]
此外,我们还在损失函数中添加了一个正则化项,这样就可以强制执行额外的约束条件。因此,下面就是我们的完整优化问题:
arg
max
G
E
z
∼
uniform
(
0
,
1
)
[
(
∑
x
∈
D
S
l
(
f
(
M
(
x
,
G
(
z
)
)
)
,
f
(
x
)
)
)
+
R
(
G
(
z
)
)
]
\arg \max _{G} \underset{z \sim \text { uniform }(0,1)}{\mathbb{E}}\left[(\sum_{\boldsymbol{x} \in \mathcal{D}^{S}} l(f(\mathcal{M}( \boldsymbol{x},G(z))), f(\boldsymbol{x})))+\mathcal{R}(G(z)) \right]
argGmaxz∼ uniform (0,1)E[(x∈DS∑l(f(M(x,G(z))),f(x)))+R(G(z))]
我们可以将 l ( f ( M ( x , G ( z ) ) ) , f ( x ) ) l(f(\mathcal{M}( \boldsymbol{x},G(z))), f(\boldsymbol{x})) l(f(M(x,G(z))),f(x))替换为 l ( f ( M ( x , G ( z ) ) ) , O T ) l(f(\mathcal{M}( \boldsymbol{x},G(z))), \boldsymbol{O_{T}}) l(f(M(x,G(z))),OT),其中 O T \boldsymbol{O_{T}} OT是目标输出类别,从而实现目标定向(DT)攻击。另外,请注意,对于源定向攻击, D S \mathcal{D}^{S} DS只包含目标类别的样本。
算法概述
算法1总结了我们生成盲对抗扰动的方法,图2说明了算法的主要组成部分。

扰动技术
基于模式的流量分析使用三个主要特征来构建流量分析分类器:1)数据包时序;2)数据包大小;3)数据包方向。我们的盲对抗扰动技术利用这些特征对流量进行对抗扰动。可以通过延迟数据包、调整数据包大小或注入新的(虚假)数据包(不能丢弃数据包,否则会破坏底层应用)来修改这些特征。
操纵现有的数据包
我们可以修改目标网络连接现有数据包的时间和大小(但不能修改方向)。我们将网络连接表示为一个特征向量: F = [ f 1 , f 2 , ⋯ , f n ] \boldsymbol{F}=[f_{1},f_{2},\cdots ,f_{n}] F=[f1,f2,⋯,fn],其中 f i f_{i} fi可以表示第i个数据包的大小、时间、方向或这些特征的组合。我们设计一个盲对抗扰动模型G,从而输出一个与F大小相同的扰动向量 G ( z ) = [ g 1 , g 2 , ⋯ , g n ] \boldsymbol{G}(z)=[g_{1},g_{2},\cdots ,g_{n}] G(z)=[g1,g2,⋯,gn]。当数据包到达时,将G(z)添加到原始流量模式中,因此 F p = F + G ( z ) = [ f 1 + g 1 , f 2 + g 2 , ⋯ , f n + g n ] \boldsymbol{F}^{p}=\boldsymbol{F}+G(z)=[f_{1}+g_{1},f_{2}+g_{2},\cdots ,f_{n}+g_{n}] Fp=F+G(z)=[f1+g1,f2+g2,⋯,fn+gn]是扰动连接的模式。
扰动时序:我们首先介绍如何扰动时序特征。我们使用数据包间延迟(IPD)来表示数据包的时间信息。对时序特征的一个重要限制是,不应在数据包上引入过多延迟。我们通过使用重映射函数
M
T
\mathcal{M}^{T}
MT来控制增加的延迟量,具体如下:
M
T
(
x
,
G
(
z
)
,
μ
,
σ
)
=
x
+
G
(
z
)
−
max
(
G
(
z
)
‾
−
μ
,
0
)
−
min
(
G
(
z
)
‾
+
μ
,
0
)
std
(
G
(
z
)
)
min
(
std
(
G
(
z
)
)
,
σ
)
\mathcal{M}^{T}(\boldsymbol{x}, G(z), \mu, \sigma)=\boldsymbol{x}+ \frac{G(z)-\max (\overline{G(z)}-\mu, 0)-\min (\overline{G(z)}+\mu, 0)}{\operatorname{std}(G(z))} \min (\operatorname{std}(G(z)), \sigma)
MT(x,G(z),μ,σ)=x+std(G(z))G(z)−max(G(z)−μ,0)−min(G(z)+μ,0)min(std(G(z)),σ)
其中,
G
(
z
)
‾
\overline{G(z)}
G(z)是扰动G(z)的平均值,
μ
\mu
μ和
σ
\sigma
σ分别是延迟的最大允许平均值和标准偏差。利用这个重映射函数,我们可以控制数据包的延迟量。
时序特征的第二个约束条件是,扰动时序应遵循目标协议的预期统计分布。为此,我们利用正则器R来强制执行盲扰动所需的统计行为。正如之前的研究所建议的那样,我们的正则器对网络抖动执行拉普拉斯分布,但它也可以执行任意分布。为此,我们使用了生成式对抗网络(GAN):我们设计了一个判别模型D(G(x)),试图将生成的扰动与拉普拉斯分布区分开来。然后,我们使用这个判别器作为正则函数,使生成的扰动分布与拉普拉斯分布相似。
扰乱大小:对手可以通过增加数据包大小(通过添加虚位)来扰乱数据包大小。不过,修改后的数据包大小不应违反底层协议的预期最大数据包大小以及预期的数据包大小统计分布。

如算法3 所示,我们使用重映射函数
M
S
\mathcal{M}^{S}
MS来调整大小修改的幅度,并强制执行所需的统计分布。算法3的输入包括:盲对抗扰动G(z)、希望增加的最大流量字节数N、单个数据包中希望增加的最大字节数n,以及底层网络协议的预期数据包大小分布s(如果网络协议没有任何特定的大小限制,则
s
=
1
s=1
s=1)。算法3首先从对抗扰动的输出中选择最高值,并将其添加到流量中直到加了N个字节。由于算法3不可微,我们不能简单地使用算法1。相反,我们为算法3定义了一个自定义梯度函数,通过该函数我们可以训练盲对抗扰动模型。考虑到目标模型的损失梯度与算法3的输出(即
∇
x
M
S
(
x
,
G
(
z
)
)
\nabla_{\boldsymbol{x}}\mathcal{M}^{S} (\boldsymbol{x},\boldsymbol{G(z)})
∇xMS(x,G(z)))的关系,我们将扰动模型的梯度修改为:
∇
G
z
=
∑
x
∈
b
i
∇
x
M
S
(
x
,
G
(
z
)
)
\nabla_{G_{z}}=\sum_{\boldsymbol{x}\in b_{i}}^{} \nabla_{\boldsymbol{x}}\mathcal{M}^{S} (\boldsymbol{x},\boldsymbol{G(z)})
∇Gz=x∈bi∑∇xMS(x,G(z))
其中,
b
i
b_{i}
bi是选定的训练批次。
注入对抗性数据包
除了扰乱现有数据包的特征外,我们还可以在特定时间向要扰乱的目标连接注入特定大小的假数据包(假数据包是通过向TCP应用层注入随机数据创建的,传输层将对其进行加密)。我们的目标是为注入的数据包找出最具对抗性的时间和大小值。我们设计了一个重映射函数 M I \mathcal{M}^{I} MI(算法4),用于获取注入数据包的排序及其特征值。与之前的攻击类似,算法4不可微,我们不能简单地将其用于算法1。相反,我们在算法4中使用了自定义梯度函数,这样就可以训练我们的盲对抗扰动模型。我们为不同类型的特征定义梯度函数,如下所述。

注入对抗性方向:虽然我们无法改变现有数据包的方向,但可以通过添加数据包来注入敌对方向。连接的数据包方向可以表示为一系列-1(下游)和+1(上游)值。
我们生成一个与目标连接大小相同的扰动向量G(z)。该向量的每个元素都显示了在特定位置(即算法4中的l)插入数据包的效果。我们选择绝对值最大的位置进行数据包注入;所选位置的符号决定了数据包注入的方向。最后,我们修改扰动模型的梯度为
∇
G
z
=
∑
x
∈
b
i
∇
x
M
I
(
x
,
G
(
z
)
)
\nabla_{G_{z}}=\sum_{\boldsymbol{x}\in b_{i}}^{} \nabla_{\boldsymbol{x}}\mathcal{M}^{I} (\boldsymbol{x},\boldsymbol{G(z)})
∇Gz=x∈bi∑∇xMI(x,G(z))
注入对抗性时序/大小:与数据包方向不同,对于时序和大小特征,我们需要同时学习添加数据包的位置和值。我们设计的扰动生成模型会输出两个向量,分别代表添加数据包的位置和值,其中值向量代表所选特征(时序或大小)。我们使用上式定义的梯度函数来计算插入数据包的位置。我们使用算法5计算插入数据包值的梯度。

注入多个对抗特征:为了注入同时扰动多个特征的数据包,我们修改了扰动生成模型G,为注入数据包的位置输出一个向量,为每个要扰动的特征集输出一个向量。我们使用算法5计算每个向量的梯度。此外,我们无法使用上式计算位置向量的梯度,因此,我们取所有不同输入特征向量梯度的平均值。
实验设置
衡量标准
对于给定的盲对抗扰动生成器
G
(
⋅
)
G(·)
G(⋅)和测试数据集
D
t
e
s
t
\mathcal{D}_{test}
Dtest,我们将攻击成功率定义为
A
=
{
1
∣
D
test
∣
∑
(
x
,
y
)
∈
D
test
1
[
f
(
x
+
G
(
z
)
)
≠
y
]
DU
1
∣
D
test
∣
∑
(
x
,
y
)
∈
D
test
1
[
f
(
x
+
G
(
z
)
)
=
t
]
DT
\mathcal{A}=\left\{\begin{array}{ll} \frac{1}{\left|\mathcal{D}_{\text {test }}\right|} \sum_{(\boldsymbol{x}, y) \in \mathcal{D}_{\text {test }}} \mathbb{1}[f(\boldsymbol{x}+G(z)) \neq y] & \text { DU } \\ \frac{1}{\left|\mathcal{D}_{\text {test }}\right|} \sum_{(\boldsymbol{x}, y) \in \mathcal{D}_{\text {test }}} \mathbb{1}[f(\boldsymbol{x}+G(z))=t] & \text { DT } \end{array}\right.
A={∣Dtest ∣1∑(x,y)∈Dtest 1[f(x+G(z))=y]∣Dtest ∣1∑(x,y)∈Dtest 1[f(x+G(z))=t] DU DT
其中,DU和DT分别代表非目标定向和目标定向的情况。对于源定向(ST),
D
t
e
s
t
\mathcal{D}_{test}
Dtest仅包含指定源类别的实例。此外,在对定向攻击(ST和DT)的评估中,我们只报告目标类别的最小和最大攻击准确率的结果。例如,"最大 ST-DT"表示源和目标定向攻击的最佳结果,我们使用
T
a
r
g
e
t
D
e
s
t
←
T
a
r
g
e
t
S
r
c
TargetDest\gets TargetSrc
TargetDest←TargetSrc表示指定类别,这意味着 TargetDest是指定的目标类别,TargetSrc是指定的源类别。最高准确率表示模型的最坏情况,最低准确率表示对手成功率的下限。如果有多个类导致同一个最大/最小准确率,我们只提及其中一个。
目标系统
DeepCorr:DeepCorr是最先进的流关联系统,它使用深度学习来学习特定网络设置(如 Tor)的流量相关函数。DeepCorr 使用数据包间延迟(IPD)和数据包大小作为特征。DeepCorr使用卷积神经网络从原始时序和大小信息中提取复杂特征,其性能明显优于传统的统计流量相关技术。由于DeepCorr使用数据包的时间和大小作为特征,因此我们对DeepCorr应用了基于时间和大小的攻击。
Var-CNN:Var-CNN是一种基于深度学习的网站指纹识别(WF)系统,它同时使用手动和自动特征提取技术,甚至能够处理少量的训练数据。Var-CNN采用了最先进的卷积神经网络ResNets,并将其作为基础结构。此外,Var-CNN还表明,与以往的WF攻击不同,结合数据包定时信息(IPD)和方向信息可以提高WF对手的性能。除了数据包IPD和方向外,Var-CNN还使用累积统计信息作为网络流的特征。由于Var-CNN同时使用IPD和数据包方向特征进行指纹识别,因此我们同时使用基于时间和方向的技术来生成对抗扰动。
深度指纹识别(DF):深度指纹(DF)是一种基于深度学习的WF攻击,它使用CNN对Tor实施WF攻击。DF部署了自动特征提取,并使用方向信息进行训练。与Var-CNN不同的是,DF不需要手工制作数据包序列的特征。与 Var-CNN类似,DF同时考虑了封闭世界和开放世界场景。Sirinam等人的研究表明,在击败WTF-PAD和W-T的 WF防御方面,DF优于先前的WF系统。
对手设置和模型
对手的拦截点:我们的对手与传统的Tor流量分析具有相同的位置。在WF场景中,我们假设对手正在操纵Tor客户端与Tor第一跳(即Tor桥接器或Tor保护中继器)之间的流量。因此,我们的盲对抗扰动可以作为Tor可插拔传输来实现,在这种情况下,Tor客户端软件和Tor网桥都会应用盲扰动。在流关联设定中,与文献类似,流量操纵由Tor入口和出口中继器执行(因为流关联攻击者会拦截出口和入口Tor连接)。在我们的评估中,我们发现即使只在入口流量上应用我们的盲对抗扰动,也足以击败流关联攻击,即与WF相同的位置。
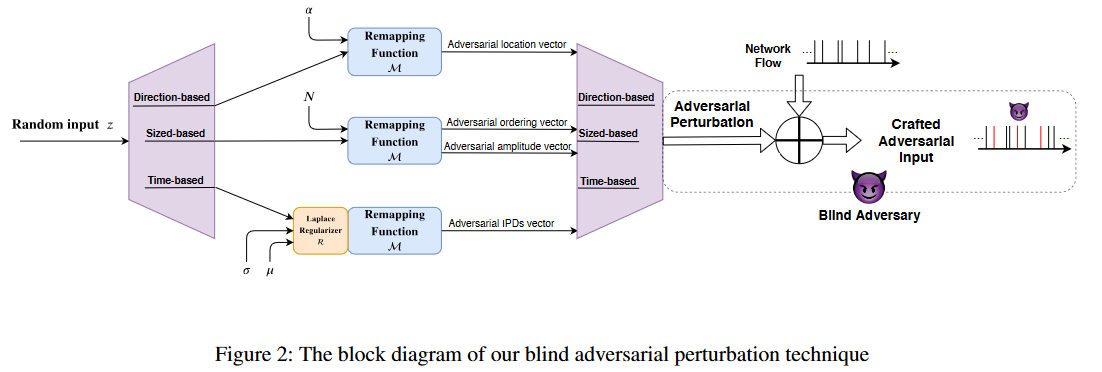
对抗扰动模型:如前所述,我们设计了一个深度学习模型来生成盲对抗噪声。对于每种扰动类型,对抗模型都是一个全连接模型,有一个大小为500的隐藏层和一个ReLu激活函数。对抗模型的参数见表1。对抗模型的输入和输出大小等于目标流中特征的长度。我们使用Adam优化器学习盲噪声,学习率为0.001。
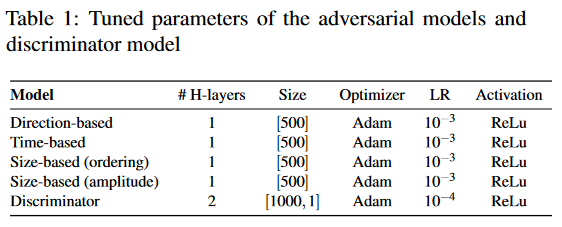
判别器模型:如前所述,我们使用GAN模型来执行修改后网络流的时间限制。为此,我们设计了一个全连接鉴别器模型,包含两个大小为1000的隐藏FC层。判别器模型的参数如表1所示。该模型的输入和输出大小等于盲对抗噪声的大小。在训练过程中,我们使用学习率为 0.0001的Adam优化器来学习判别模型。
数据集
Tor流关联数据集:为了进行流量关联实验,我们使用了DeepCorr的公开数据集,其中包含7000个用于训练的流量和500个用于测试的流量。这些流量是捕获的Alexa顶级网站的Tor流量,包含每个流量的时间和大小。然后,这些流量被用来创建大量流量对,包括关联流量对(属于同一Tor连接的流量)和非关联流量对(属于任意Tor连接的流量)。每个关联流对的标记为1,每个非关联流对的标记为0。
Tor网站指纹数据集:Var-CNN使用由900个受监控网站组成的数据集,每个网站有2500条跟踪记录。这些网站是从Alexa最受欢迎网站列表中整理出来的。基于方向的ResNet模型将一组1和-1作为每个数据包的方向,其中1表示传出数据包,-1表示传入数据包。基于时间的ResNet使用轨迹的IPD作为特征。元数据模型将七个浮点数作为跟踪的统计信息。为了与之前的WF攻击保持一致,我们使用给定跟踪的前5000个值作为方向和时间特征。
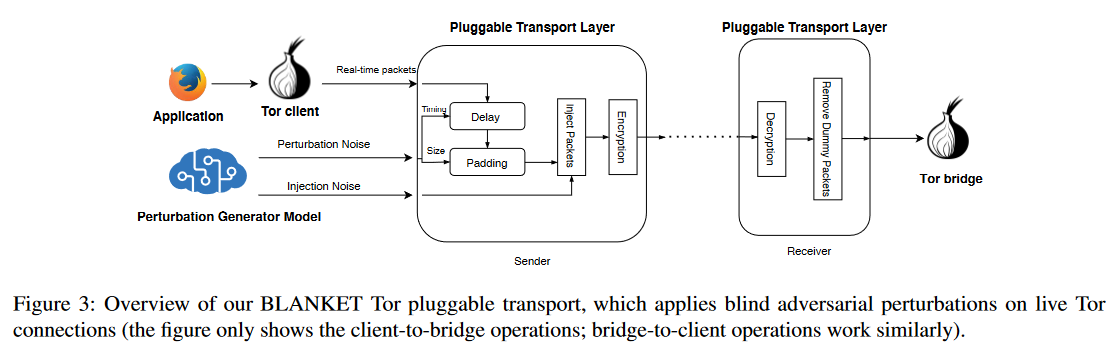
BLANKET Tor可插拔传输
为了展示我们技术的可部署性,我们在实时Tor流量上应用了我们的对抗扰动技术。我们使用BLANKET来扰乱使用上文介绍的数据集为不同目标系统生成的Tor连接。为了执行其时间不可区分性约束,BLANKET需要测量其客户端的抖动。我们使用Twisted框架在Python中实现了可插拔传输,该框架可在https://github.com/SPIN-UMass/BLANKET上获取。
BLANKET 有两个运行阶段:
会话初始化:与其他可插拔传输方式一样,BLANKET需要由Tor客户端和与其连接的Tor网桥共同安装。在每个会话开始时,客户端和网桥将协商一组对抗噪声向量(由客户端使用生成器函数G创建),用于扰乱流量(噪声向量包括扰乱所需的时间和数据包大小),以及一对AES密钥,用于加密流量(与其他可插拔传输类似)。这种协商可以集成到Tor的常规客户端桥接握手中,也可以通过带外渠道(如电子邮件、域名服务器等)进行交换。BLANKET目前的实现方式是带外协商。
流量扰动:图3显示了BLANKET如何修改实时Tor连接。具体来说,BLANKET应用了两种类型的扰动:扰动现有数据包的时序/大小(即时)或向流量中注入新的(假)数据包。
- 在注入假数据包时,BLANKET只需在传输层中添加具有特定时间/大小的新数据包;这样就不会修改底层协议(TCP/IP),而且在语义上也是正确的。在我们的可插拔传输的接收端,传输层会在将注入的虚假数据包传递给上游应用(如下一个Tor中继)之前将其删除;因此,上游数据包也将保持未修改和语义正确。
- 为了即时扰乱现有数据包,BLANKET会改变数据包的时间和大小。要改变数据包的大小,发送方的BLANKET会用随机字节填充该数据包,而这些字节会被接收方的BLANKET删除。对于时间扰动,BLANKET会通过延迟发送者的数据包来修改数据包时序。
实验结果
扰动方向
我们评估了针对Var-CNN和DF的不同对抗设置和强度的攻击。我们使用了10个epoch、学习率为0.001和Adam优化器来训练盲对抗扰动模型。表2和表3分别显示了当DF和Var-CNN只使用数据包方向作为特征时,攻击的成功率。可以看出,当敌方只注入少量数据包时,DF和Var-CNN都极易受到敌方的扰动攻击。具体来说,我们只需 25%的带宽开销,就能生成有针对性的扰动,将每个输入错误分类为目标类别。
扰动时序
我们考虑了产生对抗性时序扰动的两种情况:有隐形约束和无隐形约束。在这两种情况下,我们都限制了对抗者的能力,使增加到数据包时序上的噪声具有最大均值和标准偏差。对于隐蔽性约束,我们强制增加的噪声具有与自然网络抖动相同的分布,即拉普拉斯分布。
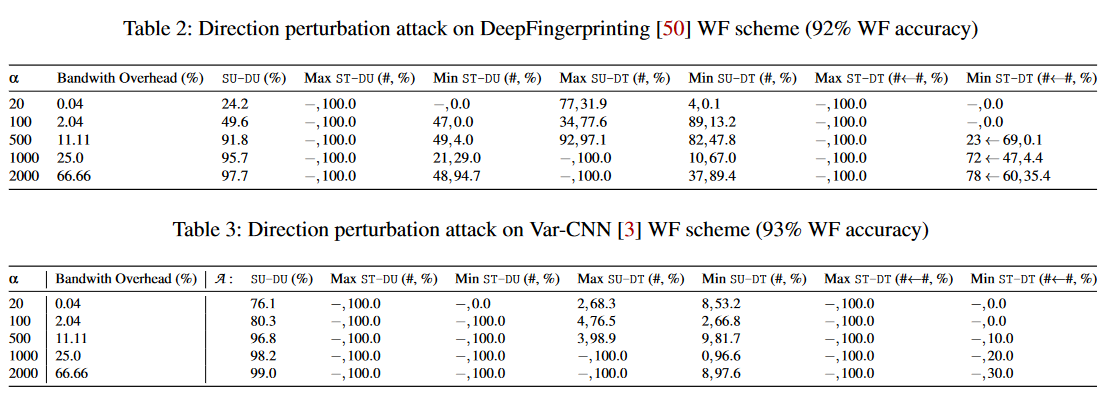
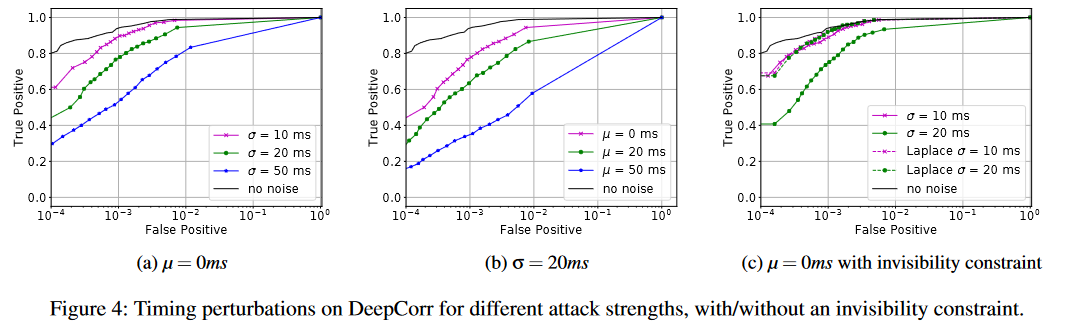
图4显示了敌方仅操纵数据包时序时,我们针对DeepCorr的攻击性能。此外,我们还可以创建具有高隐蔽性的有效对抗扰动:图5显示了生成的定时扰动的直方图,其参数为μ = 0、σ = 30毫秒,是在强制其遵循拉普拉斯分布的隐形约束下学习的。对于这种不可见噪声,图4c比较了不同攻击强度的时序扰动对DeepCorr的影响;图4c还显示了任意拉普拉斯分布扰动对DeepCorr的影响。
我们还在Var-CNN上应用了时序扰动。表4显示了有隐形约束和无隐形约束时的攻击成功率。

多特征扰动
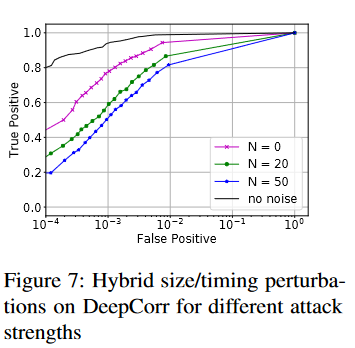
在本节中,我们将对同时扰动多个特征时的对抗性扰动性能进行评估。Var-CNN使用数据包时序和方向来对网站进行指纹识别。表5显示了同时对这两个特征进行对抗性扰动对Var-CNN的影响。同样,在图7中,我们可以看到,通过结合时间和大小扰动,DeepCorr在仅注入20个数据包的情况下,准确率从95%降至59%( F P = 1 0 − 3 FP=10^{-3} FP=10−3),而仅使用时间扰动,准确率则降至78%。

与传统攻击比较
数据包插入技术:和WTF-PAD对比,本文结果好。
时间扰动技术:和添加随机拉普拉斯噪声对比,本文结果好。
非盲对抗扰动:和Mockingbird比,本文结果好。
可移植性
如果一种对抗性扰动方案为目标模型创建的扰动也能规避其他模型,那么这种方案就被称为可移植扰动方案。可移植扰动算法更为实用,因为对手无需白盒访问其目标模型;相反,对手可以使用代理(白盒)模型来制作其对抗性扰动,然后将其应用于原始黑盒目标模型。
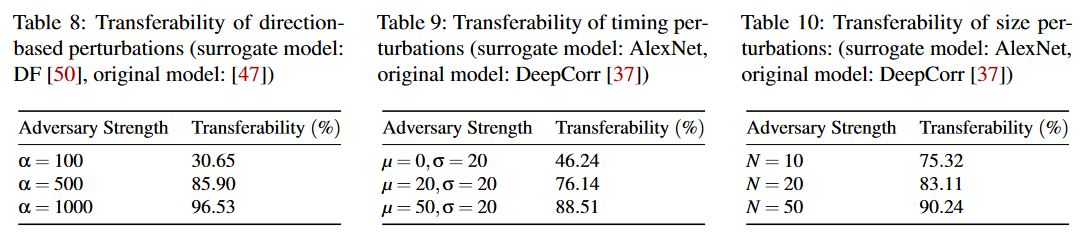
在本节中,我们将评估盲对抗扰动技术的可移植性。首先,我们为流量分析应用训练一个代理模型。需要注意的是,原始模型和代理模型不需要具有相同的架构,但它们是针对相同的任务进行训练的(分类精度可能不同)。接下来,我们为代理模型创建扰动生成函数G(z)。我们使用G(z)生成扰动,并将这些扰动应用于一些样本流。最后,我们将生成的扰动流作为输入输入到流量分析应用的原始模型(即目标黑盒模型)中。我们使用一个通用指标来衡量可移植性:在应用盲对抗扰动之前,我们识别出被原始模型和代理模型正确分类的输入流量;然后,在这些样本中,我们返回被原始模型错误分类的样本与被代理模型错误分类的样本之比,作为我们的可移植性指标。
表8显示了我们基于方向的攻击在不同噪声强度下的可移植性。表9显示了不同盲噪声强度下基于时间的攻击的高度可移植性(假阳性率恒定为 1 0 − 4 10^{-4} 10−4)。表10显示了在假阳性率为 1 0 − 4 10^{-4} 10−4时,不同盲噪声强度下基于大小的技术的可移植性。
总结
在本文中,我们介绍了盲对抗扰动,这是一种通过扰动实时网络连接特征来打败基于DNN的流量分析分类器的机制。我们提出了一种系统方法,通过解决针对流量分析应用的特定优化问题来生成盲对抗扰动。我们的盲对抗扰动算法具有通用性,可应用于具有不同网络约束条件的各类流量分类器。我们针对最先进的流量分析系统评估了我们的攻击,结果表明我们的攻击在击败流量分析方面优于传统技术。我们还证明,我们的盲对抗扰动甚至可以在不同模型和架构之间转移,因此黑盒对抗者也可以应用。最后,我们证明了现有的对抗性实例防御措施在对抗盲目对抗性扰动方面表现不佳,因此我们设计了一种针对盲目扰动的定制对策。