参考https://zhuanlan.zhihu.com/p/673614739及https://zhuanlan.zhihu.com/p/673615788
具体来说,当SLAM系统在前一帧的动态物体上提取了特征点时,如果将这个特征点投影到当前帧,由于目标已经移动,这个点找到的匹配点必然是错误的,由此解算出的位姿必然也存在较大的误差。尤其是动态物体占据画面的比例很大时,SLAM系统极容易崩溃。
一、基于目标检测/语义分割的动态SLAM
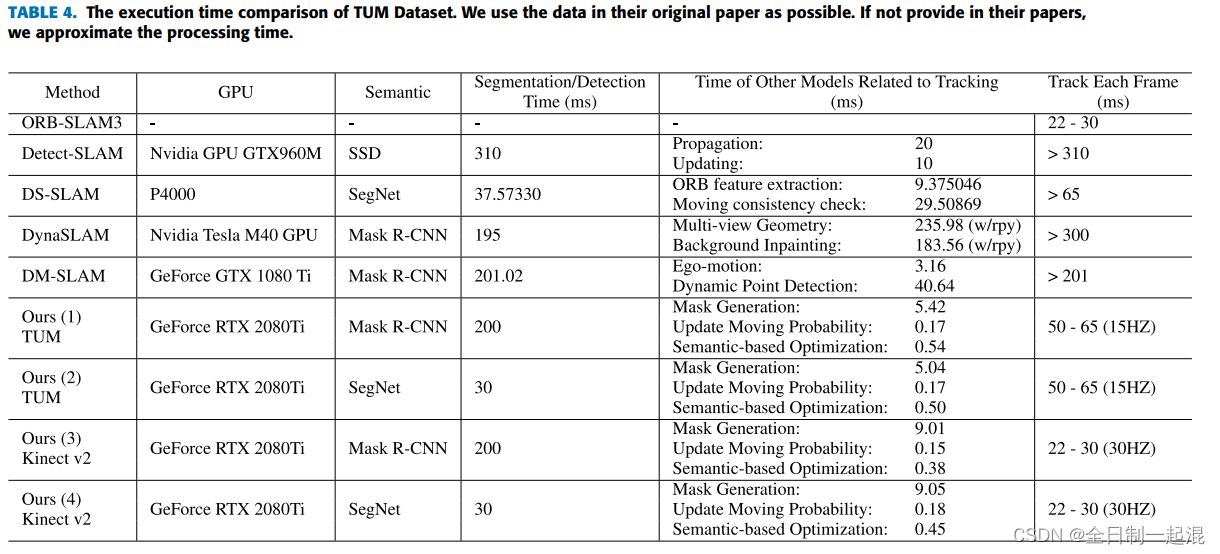
这一部分也是目前动态SLAM的主流方案,基本套路就是在ORB-SLAM2/3或者VINS的基础上加入YOLO。首先SLAM该怎么提特征点还怎么提,然后对于候选框内的特征点直接丢弃,这样位姿解算所使用的特征点也就没有了动态物体的影响。优点是效果还不错,尤其经过TensorRT加速的YOLO可以达到实时,对GPU显存的要求也没那么高。缺点是一方面在YOLO出现漏检时不稳定,另一方面只能识别预先定义好的物体类别,而且也没办法识别不在预定义类别范围内但真的在运动的物体,比如人手上拿着的书、正在搬运的椅子等等。
首先最经典的肯定是DS-SLAM和DynaSLAM了,这两篇文章也都来源于2018 IROS,虽然时间比较早,但是思想具有很高的借鉴意义。
1.1 DS-SLAM:(IROS 2018, 清华大学)
论文链接:https://arxiv.org/abs/1809.08379
代码链接:https://github.com/ivipsourceco
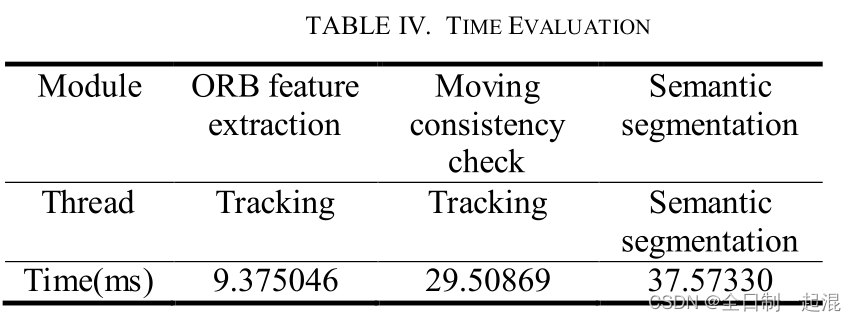
DS-SLAM是基于ORB-SLAM2开发的,有5个并行运行的独立线程:跟踪、语义分割、局部建图、回环检测和稠密语义八叉树地图。针对动态目标(主要是人),首先使用SegNet进行语义分割,然后进行运动一致性检查,剔除动态区域上的特征点。为啥要进行运动一致性检查呢?就是为了检测上面提到的"人手上拿着的书、正在搬运的椅子"这类无法提前定义的物体。
在DS-SLAM中,运动一致性检查的具体流程是:
- 1、计算光流金字塔,获得当前帧中的匹配对;
- 2、校验匹配关系,如果匹配对靠近边缘或其像素值与以它为中心的邻域的3x3区域内的像素值差别太大,就认为不合法,丢弃;
- 3、使用RANSAC寻找内点,并利用这些内点求解基础矩阵;
- 4、利用基础矩阵计算当前帧中极线方程;
- 5、计算匹配点到极线的距离,如果超过阈值则认为是外点(运动点)。

缺点就是太慢了,总单帧耗时达到了59.4ms。
1.2 DynaSLAM:(IROS 2018)
论文链接:https://arxiv.org/abs/1806.05620
代码链接:https://github.com/BertaBescos/DynaSLAM
DynaSLAM的主要思想和DS-SLAM很像。具体的流程是:
- 1、使用Mask R-CNN和几何方法(将深度或者角度差距较大的数据关联点当做动态点)分别检测可能运动和正在运动的物体;
- 2、只使用静态区域和非动态物体掩膜边缘的ORB特征点进行相机位姿估计;
- 3、使用历史观测数据做背景修复。
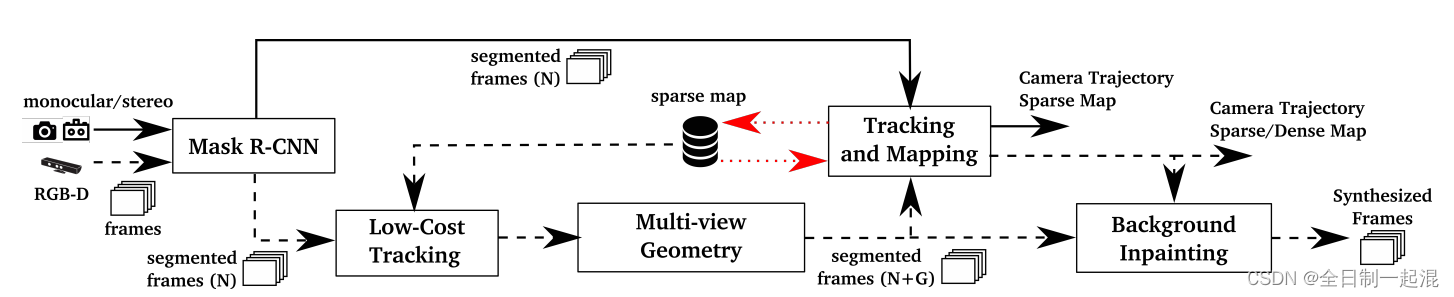
DynaSLAM中几何一致性验证的具体流程是:
- 1、选取5个与当前关键帧CF重合度最高的KF;
- 2、计算每个KeyPoint从KF到CF的投影,得到投影后的坐标和投影深度;
- 3、计算两个坐标之间的视差角,如果大于30°就滤除,计算两个深度之间的差值,如果超过一定阈值就滤除。
效果还不错,但是缺点也是耗时太大了。

1.3 Detect-SLAM(2018 IEEE WCACV, 北京大学)
论文链接:Detect-SLAM: Making Object Detection and SLAM Mutually Beneficial
代码链接:https://github.com/liadbiz/detect-slam
主要思想:
目标检测的网络并不能实时运行,所以只在关键帧中进行目标检测,然后通过特征点的传播将其结果传播到普通帧中
- 1.只在关键帧中用SSD网络进行目标检测(得到的是矩形区域及其置信度),图割法剔除背景,得到更加精细的动态区域;
- 2.在普通帧中,利用feature matching + matching point expansion两种机制,对每个特征点动态概率传播,至此得到每个特征点的动态概率;
- 3.object map帮助提取候选区域。

1.4 RDS-SLAM: (2021,Access)
论文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=9318990
代码链接:https://github.com/yubaoliu/RDS-SLAM
前面说到,语义分割的主要问题在于太过耗时。而RDS-SLAM的主要贡献就是在实时性上的提升。RDS-SLAM是在ORB-SLAM3的基础上,开辟了一个独立的语义线程。这样就可以不等待语义信息进入跟踪线程,将语义分割与跟踪分离。利用移动概率将语义信息从语义线程传递到跟踪线程。利用移动概率来检测和去除跟踪中的异常值。

那么具体来说,为啥开辟一个新的语义线程就可以提高实时性呢?作者定义了语义延时来说明该部分如何保证语义分割的实时性。首先按照时间顺序分割每一帧(假设语义分割一次耗时10次采样时间,每隔两帧取一个关键帧),同时连续分割两帧。注意,作者使用了双向模型(bi-directional model),关键帧的分割不是按顺序进行的,而是分割队列的前面和后面。这里还有一个问题,就是为什么还要对前面的关键帧做分割呢?这是因为如果前几帧没有语义信息,由于跟踪线程很快,可能已经因为动态物体累计了很大的误差。因此,需要使用语义信息来把漂移拉回来。

对于速度的提升也很明显,可以在2080Ti上达到实时。
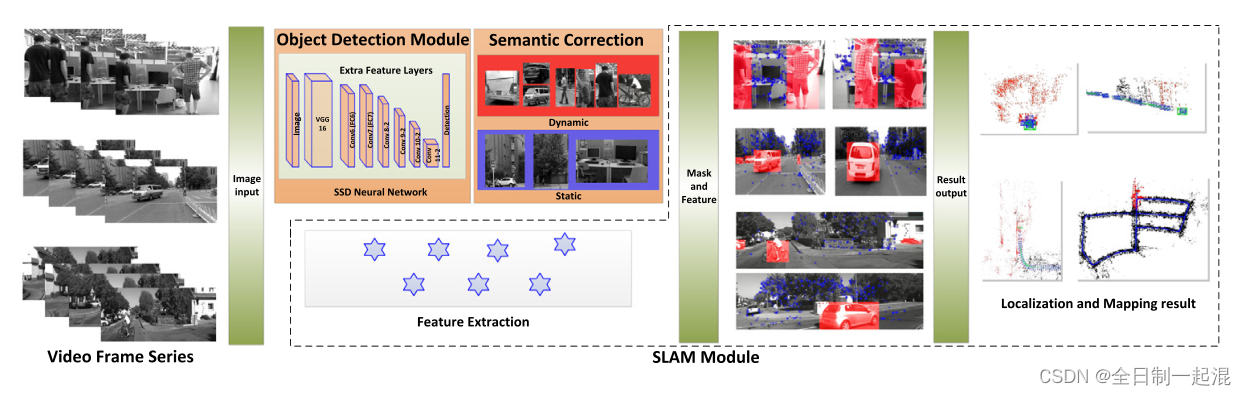
1.5 Dynamic-SLAM : (2019 Robotics and Autonomous Systems)
在动态环境中工作时,由于动态对象的干扰,传统的SLAM框架的性能很差。 通过在对象检测中利用深度学习的优势,提出了一种语义动态的动态地图定位和映射框架Dynamic-SLAM,以解决动态环境中的SLAM问题。
本文的主要三大贡献:
- 1.针对SLAM系统提出了一种基于相邻帧速度不变性的丢失检测补偿算法,提高SSD的recall rate,为后续模块提供了良好的依据。
- 2.提出了一种选择跟踪算法,以一种简单有效的方式消除动态对象,提高了系统的鲁棒性和准确性。
- 3.构建了基于特征的可视化动态SLAM系统。 构建了基于SSD的目标检测模块线程,并将其检测结果作为先验知识提升SLAM性能。
1.6 DynaVINS : (2022 IEEE Robotics and Automation Letters)
论文链接:https://arxiv.org/abs/2208.11500
代码链接:https://github.com/url-kaist/dynavins
前面的方案都是基于ORB-SLAM开发的,我们再来看几个基于VINS的。DynaVINS是2022 RAL的文章,主要贡献在于解决了临时静态对象引起的假阳性回环问题。
DynaVINS的输入为单目/双目图像和IMU,并进行特征跟踪和IMU预积分。一方面,DynaVINS设计了一个鲁棒BA来从动态对象中丢弃跟踪的特征,保留静态特征。之后使用被追踪特征的数量对关键帧进行分组,并且聚类在当前关键帧组中检测到的回环假设。最后在选择性优化中使用或拒绝具有权重的每个假设,最终获得面向动态和暂时静态对象鲁棒的轨迹。

1.7 Dynamic-VINS: (2022 IEEE Robotics and Automation Letters)
论文链接:https://arxiv.org/abs/2304.10987
代码链接:https://github.com/HITSZ-NRSL/Dynamic-VINS
哈工大深圳的最新工作,发表在2022 RAL上。Dynamic-VINS的输入是RGBD图像和IMU,性能和YOLO-DynaSLAM类似,但是对计算资源要求更低。Dynamic-VINS结合目标检测和深度信息进行动态特征识别,达到了与语义分割相当的性能,并且将IMU应用于运动预测,进行特征跟踪和运动一致性检查。

Dynamic-VINS使用YOLOv3进行运动物体检测,然后使用深度阈值和IMU进行运动一致性检查。注意这里深度阈值的作用与普通的运动一致性检查不太一样,主要是考虑到动态对象的bounding box内还包含很多静态背景点,如果直接滤除则有点浪费,因此希望将这部分静态背景点保留。具体流程是:
- 1、对于每个动态对象的bounding box,根据四个角点计算物体深度平均值;
- 2、提取特征点深度值;
- 3、比较特征点深度值与物体深度平均值,如果较小则滤除,较大则保留。
IMU运动一致性检查的方法也很直接,就是将当前帧的特征点投影到IMU坐标系,再投影到世界坐标系,再根据之前关键帧的IMU投影到图像坐标系。判断两个投影点之间的距离值,如果超过一定阈值则认为是动态点,需要滤除。