基于MATLAB车牌识别系统设计
一、设计方案
智能交通系统已成为现代社会道路交通发展趋势。在智能交通系统中,车牌自动识别系统是一个非常重要的发展方向。对于车牌识别系统的要满足当车辆通过摄像头采集车辆图片,将其图片进行图像预处理、车牌定位、字符分割、字符识别、输出识别的车牌结果的基本要求。如下图1 车牌识别的应用所示。

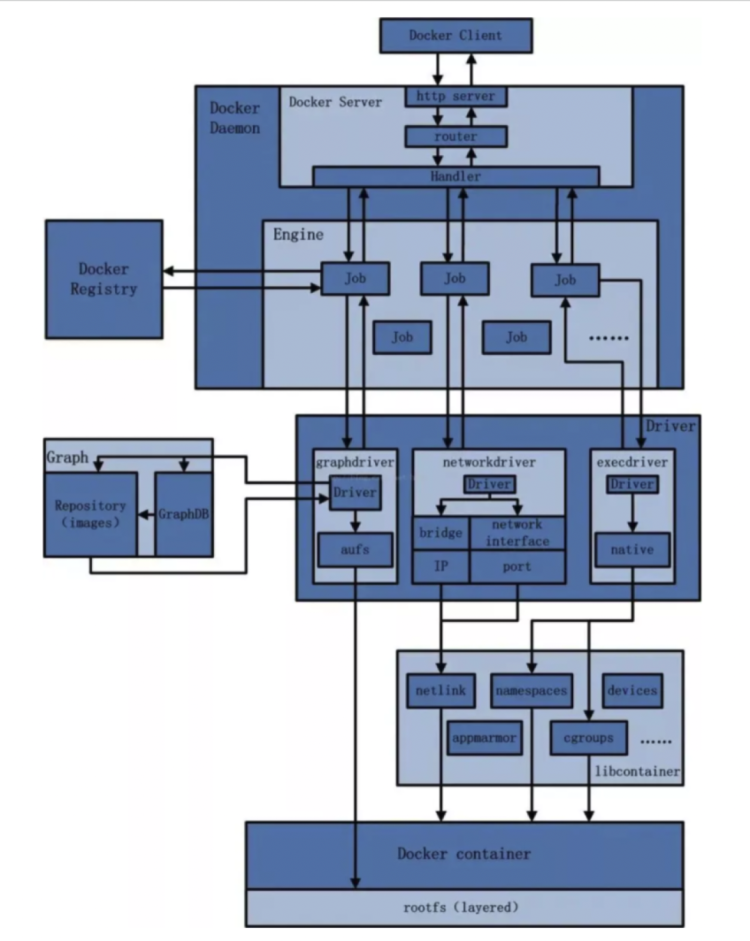
车牌识别是一项利用车辆的动态视频或静态图像进行车牌号码、车牌颜色自动识别的模式识别技术。其硬件基础一般包括触发设备、摄像设备、照明设备、图像采集设备、识别车牌号码的处理设备等,其软件核心包括车牌定位算法、车牌字符分割算法和字符识别算法等。一个完整的车牌识别系统应包括车辆检测、图像采集、车牌识别等几部分。当车辆检测部分检测到车辆到达时触发图像采集单元,采集当前的视频图像。车牌识别单元对图像进行处理,定位出车牌位置,再将车牌中的字符分割出来进行识别,然后组成车牌号码输出。车牌识别系统设计方案如下图2所示。

车牌识别系统各个步骤的作用:
- 图像预处理:在整个车牌识别系统中,由于采集进来的图像为彩色图像,再加上实际采集环境的影响以及采集硬件等原因,图像质量并不高,其背景和噪声会影响字符的正确分割。和识别,所以在进行车牌分割和识别处理之前,需要先对车牌图像进行图像预处理操作。
- 车牌定位:首先对车牌的二值图片进行形态学滤波,使车牌区域形成一个连通区域,然后根据车牌的先验知识对所得到的连通区域进行筛选,获取车牌区域的具体位置,完成从图片中提取车牌的任务。
- 字符分割:首先对车牌进行水平投影,去除水平边框;再对车牌进行垂直投影。通过对车牌进行投影分析可知,与最大值峰中心对应的为车牌中第二个字符和第三个字符的间隔,与第二大峰中心距离对应的即为车牌字符的宽度,并以此为依据对车牌进行分割。
- 字符识别:本文采用模板匹配方法来对车牌进行识别。识别过程中,首先建立标准字库,再将分割所得到的字符进行归一化,将归一化处理后的字符与标准字库里的字符逐一比较,最后把误差最小的字符作为结果显示出来。
二、设计原理
该系统主要包括图像输入、图像预处理、车牌定位、字符分割、字符识别五大核心部分。系统的图像预处理模块是将图像经过图像灰度化、图像增强、边缘提取、二值化等操作,转换成便于车牌定位的二值化图像;利用车牌的边缘、形状等特征,再结合Roberts 算子边缘检测、数字图像、形态学等技术对车牌进行定位;字符的分割采用的方法是将二值化后的车牌部分进行寻找连续有文字的块,若长度大于设定的阈值则切割,从而完成字符的分割;字符识别运用模板匹配算法完成。下面我们对基于MATLAB的车牌识别系统各部分设计进行详细的介绍。
1、图像输入
要实现车牌识别,首先要从计算机中读取含有要识别车牌的图片,为了使用户更方便地从文件系统中直接选取图片,这里使用了uigetfile()函数。uigetfile()函数的调用格式为:[filename,filepath]=uigetfile(),执行此函数可得到供用户选择图片文件的对话框,用户选择要识别的图片并点击“打开”按钮后,会返回此图片的文件名和路径名,分别保存到filename和pathname两个变量中(为了避免用户在对话框中选择非图片文件出现异常,在调用uigetfile()函数时将函数参数设置成了“.png;.jpg”,所以文件选择对话框中只会出现图片文件),然后通过imread()函数将图像数据读出,赋值给变量I,从而实现图像数据的读入。
2、图像预处理
- 图像灰度化
输入的彩色图像包含大量颜色信息,会占用较多的存储空间,且处理时也会降低系统的执行速度,因此对图像进行识别等处理时.常将彩色图像转换为灰度图像,以加快处理速度。这里使用了rgb2gray()函数,该函数接收一个彩色图像变量作为参数,返回该图像转换为灰度图后的图像数据。
- 图像边缘检测
在车牌定位与字符的识别前我们需先对图片做边缘检测处理,提升图像像素,让图像更容易接下来的后续操作。在进行完边缘检测处理之后,能在相当程度上压低噪声影响、切割出车牌区域、留下完整车牌字符,使其方便接下来的定位与识别。在将彩色图转换为灰度图后,便可用edge()函数识别该图像的边界,edge()函数通过使用一阶导数和二阶导数检测亮度的不连续来确定图像的边界,它可以使用Sobel、Prewitt、Roberts、Canny、Log等多种算子,这里使用Roberts算子进行边缘检测。经预处理的图像如下图3所示。

3、车牌定位
- 图像腐蚀
由于边缘检测后的图像中无关结构太多,这里需对图像进行腐蚀处理,实现腐蚀处理的函数为imerode(),它接收一个图像数据和一个结构子,图像中背景与结构子完全重合的像素点输出值为1,不完全重合的和完全不重合的像素点输出值为0,最后返回使用该结构子腐蚀过后的图像数据,以此实现削减无关结构的目的。
- 图像平滑
腐蚀后的图像结构大多呈分散状分布,不连贯。为了方便之后确认车牌位置,这里需对该图像进行平滑处理,在此我们使用闭操作使车牌平滑,并减小噪音,闭操作可以理解为先膨胀后腐蚀。这里调用imclose()函数实现。
- 移除对象
然而通过平滑处理之后,周围像素平均值的平滑处理会导致图像部位内灰度值产生巨大的变化,会使得图像内物体边缘等变得不清晰。我们通常会根据具体方案设置一个适当的阈值在中心像素点以为其周围来减少平滑处理带来的负面影响。只有当当像素点大于我们设置的阈值时,该点才会被替换,当小于阈值时,该点将不会被改变。为了使接下来车牌位置的确定更精确,这里使用了bwareaopen()函数从图象中移除小对象。经过腐蚀、平滑和移除对象处理如下图4所示。

- 图像切割
这里确定车牌位置的思路为:通过前面图像处理,我们要通过代码求出白色区域,即车牌位置。首先求出车牌左右位置,先使用size()函数得到该图像矩阵的行数y和列数x,通过两个for语句嵌套遍历图片所有像素点,第一个for实现从左往右扫描,第二个for实现从上往下扫描,并通过if语句判断像素点是否等于1,如果等于1将列坐标的位置赋值给数组;遍历所有像素点后,返回数组最小值与最大值,即为车牌左右边界。同理,我们可以用相同的方法确定出车牌的上下边界。然后将原图按照上述方法确定的坐标进行裁剪,即可得到仅有车牌的图像。
4、字符分割
- 车牌二值化
车牌二值化处理是决定字符分割好坏非常重要的一个步骤,所谓二值化实际上就是把原图中的每个像素点的分别设置为0或255两个值,简单来说就是把整副原图转换成黑白图像。这个二值化主要是在灰度的基础上实际也就是取一个比较合适的值,将字符准确地从车牌中分割出来。过程大致就是选取一个合适的值,若当图中的哪点的灰度值大于这个值时就将该点设为最大255,反之如果图像中的某点的灰度值小于这个值的时候就将该点值设为最小0。因此,只有选取好一个合适的阈值,才能使二值化之后的图像能较好地区分出字符和车牌背景。根据实验经验得知图像最大灰度值减去图像最大灰度值与最小灰度值之差的三分之一可获得令人满意的阈值,二值化的效果较好。选取合适的阈值就能使二值化图像准确的表达图像的车牌区域与其他区域,所以二值化阈值的选取就成为了图像二值化的关键所在。
- 车牌均值滤波,膨胀和腐蚀处理
在车牌转换为二值图像后,为了使图像中干扰元素减少,我们对其进行均值滤波,通过fspecial()函数构造均值滤波器,然后使用filter2()函数进行滤波,以减小图中噪音。由于不同原始图像的差异,处理到这里后,字符可能会不连续,也可能会连在一起,这时我们需要再次对滤波后的图像进行腐蚀或者膨胀处理,这里使用判断结构以图中白色部分的面积为判断依据决定使用腐蚀或者膨胀。经过处理的车牌如下图5所示。

- 字符分割
字符分割可以说在整个系统里起着承前启后的作用,之前所做的所有操作都是为了能够较好地分割出车牌,而字符分割的成功与否也将决定着整个系统的最终结果的好坏。在分离字符之前,我们还要切去车牌边缘的黑色部分,从图像顶部向底部逐行扫描,对扫描到的行求和,若某行全部像素点求和为0,则切去这一行,直到扫描到某一行求和后值不为零,以这一行为上边界。同理,再用相同的方法从其他三个方向扫描,切割出下边界,左边界和右边界,最后得到切去边缘黑色部分的图像。将切割过后,就可以对图片中的字符进行分离了,先对图像从左到右逐列扫描,并将每列中像素点的值进行求和,若和不为零,则向右继续扫描下一列,直到某一列求和后值为零,图像最左侧到这一列之间即为第一个字符,将其切出,然后将该区域内所有像素点赋值为0,重复以上操作直至分离出所有字符。
- 字符归一化
分割出字符后为了更方便于接下来的模板匹配,还需要对其进行大小归一化处理。大小归一化就是将尺寸大小不一样的字符变换成尺寸相同的字符。目前常用的主要有两个,一是缩小或放大待识别字符的外框使其变成一特定的大小;另一种则是通过分析字符在两个方向上的像素点做字符归一化,这两种方法都有不足之处,第一种对字符边缘会有较大的干扰,另一种可能让本身外形相似的字符更难以辨别。
由于一些因素影响,经切割出来的字符大小基本都会有些区别,所以在匹配前我们必须对已切割出来的字符做特定的处理。使其与前期做的字符模板的图像大小能够一样,在做过这个处理后,字符就没有较大的出入,这就能更好的解决前面所说因素的影响,这样就更容易与模板库中的字符进行匹配识别。以下图6为经过字符分割、归一化处理后的车牌。

5、字符识别
该系统使用的模板匹配的识别方法,它先依次提取需要识别的字符的二值图像上下左右四个点的像素点,想沿着图像中心方向提取周围像素点,计算出每个像素点与标准模板对应该坐标的像素点的相识度,其中相似度最高的标准字符图就作为需要的字符的对应字。也可以计算出原始图像一些特征像素点之间的距离,再计算出标准模板对应特征点的距离,再判断他们距离的差异。取最小差异的标准模板为结果。但是,由于原始字符在可能会由于拍摄的时候角度原因和图像经过处理后,图像像素点距离发生改变。所以,在对标准模板的设计时应根据实际拍摄角度等多做一些相对于的模板,让比较结果更为精确。
此处采用相减的方法来求得字符与模板中哪一个字符最相似,然后找到相似度最大的输出。汽车牌照的字符一般有七个,大部分车牌第一位是汉字,通常代表车辆所属省份,或是军种、警别等有特定含义的字符简称;紧接其后的为字母与数字。车牌字符识别与一般文字识别在于它的字符数有限,汉字共约30多个,大写英文字母26个,数字10个。所以建立字符模板库也极为方便。为了实验方便,结合本次设计所选汽车牌照的特点,只建立了7个汉字26个字母与10个数字的模板。其他模板设计的方法与此相同。
首先取字符模板,接着依次取待识别字符与模板进行匹配,将其与模板字符的像素点进行判断,如果对应像素点相等的点数越多,那么就越匹配,即为识别出来的结果。具体操作流程如下图7所示。

三、结果展示
车牌识别系统完整界面效果展示:

代码:https://gitee.com/lovelots/vehicle-license-plate-recognition-system