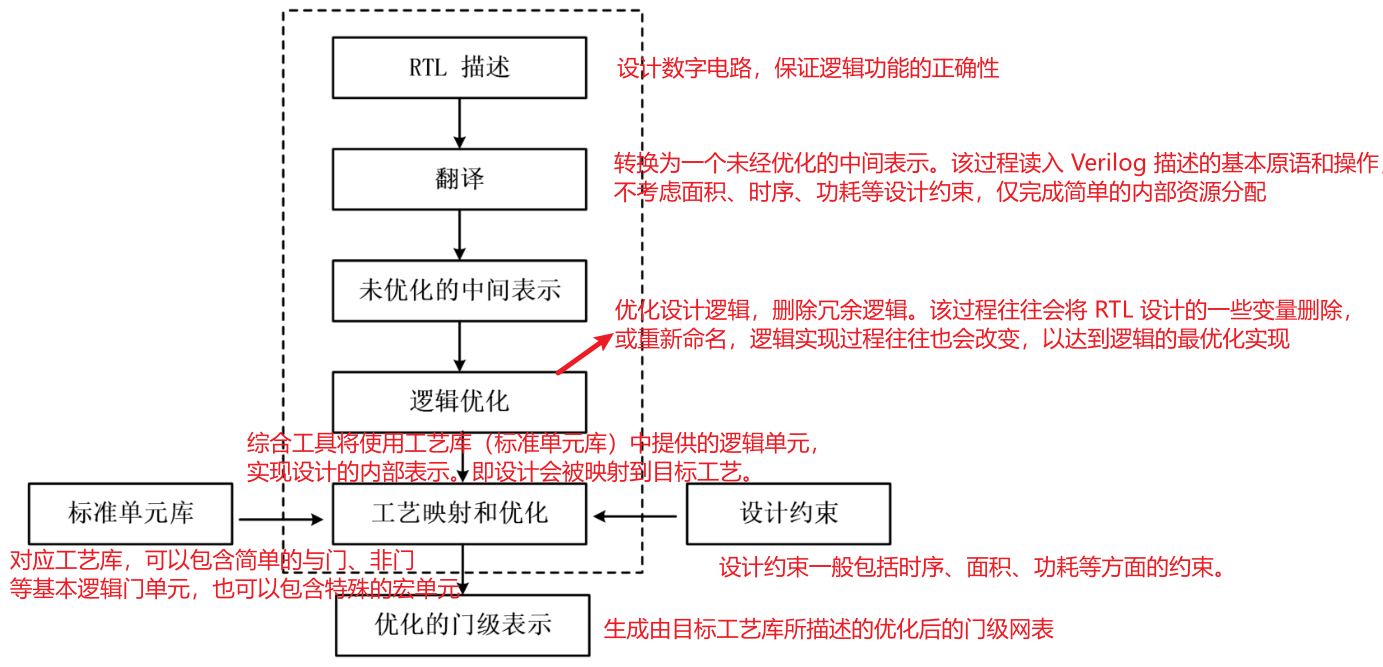
目录
一、前言
二、Scrapy框架简介
三、代理IP介绍
四、使用Scrapy框架进行数据爬取
1. 创建Scrapy项目
2. 创建爬虫
3. 编写爬虫代码
4. 运行爬虫
五、使用代理IP进行数据爬取
1. 安装依赖库
2. 配置代理IP和User-Agent
3. 修改爬虫代码
4. 运行爬虫
六、总结

一、前言
在进行大规模数据爬取时,我们常常会遇到被目标网站封禁IP的情况。为了应对这种情况,我们可以使用代理IP来进行爬取,以绕过封禁。Scrapy框架是一个强大的Python爬虫框架,可以帮助我们快速、高效地爬取数据。本文将介绍如何使用Scrapy框架和代理IP进行大规模数据爬取,并提供相应的代码示例。
二、Scrapy框架简介
Scrapy是一个为了爬取网站数据、提取结构性数据而编写的应用框架。它通过编写爬虫来定义如何请求和提取数据,然后按照一定的规则执行爬取任务。Scrapy框架具有以下特点:
- 快速高效:使用Twisted异步网络库,可以迅速地处理大量请求,提升爬取速度;
- 可扩展:Scrapy提供了丰富的扩展接口,可以根据需求灵活定制爬虫;
- 自动化:Scrapy自带了一套广泛适用的爬取流程,包括请求、页面解析、数据提取、存储等,可以大大简化开发流程;
- 多协议支持:Scrapy支持HTTP、HTTPS、FTP等协议,并且可以自定义扩展;
- 对Robots协议的支持:Scrapy可以遵守网站的Robots协议,自动处理爬取限制;
- 调试工具丰富:Scrapy提供了一系列调试工具,方便开发者调试和测试爬虫。
三、代理IP介绍
代理IP是指通过代理服务器获取的IP地址,可以将爬虫的请求通过代理服务器转发出去,从而隐藏真实的IP地址。使用代理IP的好处是可以绕过网站对特定IP的封禁,提高爬取数据的成功率。代理IP主要有以下种类:
- 免费代理:免费代理IP通常来源于一些公开的代理IP网站,可以免费获取。但是由于免费代理IP的可用性较差,经常会遇到连接超时、速度慢等问题。
- 付费代理:付费代理IP是通过购买获得的,稳定性更好。可以根据自己的需求选择适合的付费代理IP,并设置合理的爬取速度,避免被封禁。
- 私人代理:私人代理IP是由个人或组织自行维护的代理IP,稳定性和可用性相对较高。但是私人代理IP通常需要付费,并且不同的私人代理IP提供商有不同的服务质量。
四、使用Scrapy框架进行数据爬取
下面是一个使用Scrapy框架进行数据爬取的示例代码:
1. 创建Scrapy项目
首先,我们需要创建一个Scrapy项目。在命令行中运行以下命令:
scrapy startproject myproject
cd myproject2. 创建爬虫
接下来,我们需要创建一个爬虫。在命令行中运行以下命令:
scrapy genspider myspider example.com这里的"myspider"是爬虫的名称,"example.com"是爬虫要爬取的起始URL。
3. 编写爬虫代码
打开生成的爬虫代码文件`myproject/spiders/myspider.py`,可以看到以下代码:
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
allowed_domains = ['example.com']
start_urls = ['http://www.example.com/']
def parse(self, response):
pass在`parse`方法中,我们可以编写相应的逻辑来解析页面和提取数据。具体的代码逻辑根据实际需求来编写。
4. 运行爬虫
在命令行中运行以下命令来运行爬虫:
scrapy crawl myspider爬虫将会开始运行,并按照我们编写的逻辑进行数据爬取。
五、使用代理IP进行数据爬取
下面是一个使用代理IP进行数据爬取的示例代码:
1. 安装依赖库
首先,我们需要安装一些依赖库。在命令行中运行以下命令:
pip install scrapy-rotating-proxies
pip install scrapy-user-agents2. 配置代理IP和User-Agent
在`settings.py`中添加以下配置:
ROTATING_PROXY_LIST = [
'http://proxy1.example.com:8000',
'http://proxy2.example.com:8000',
# ...
]
DOWNLOADER_MIDDLEWARES = {
'scrapy_rotating_proxies.middlewares.RotatingProxyMiddleware': 610,
'scrapy_user_agents.middlewares.RandomUserAgentMiddleware': 400,
}
USER_AGENT_LIST = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.85 Safari/537.36',
# ...
]在`ROTATING_PROXY_LIST`中添加代理IP地址,可以根据实际情况添加多个。`DOWNLOADER_MIDDLEWARES`中的配置表示使用代理IP和随机User-Agent进行请求。
3. 修改爬虫代码
在`myspider.py`中添加以下代码:
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class MySpider(CrawlSpider):
name = 'myspider'
allowed_domains = ['example.com']
start_urls = ['http://www.example.com/']
rules = (
Rule(LinkExtractor(allow=r'/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
# 数据解析和提取的逻辑
pass
def process_request(self, request, spider):
request.meta['proxy'] = 'http://proxy.example.com:8000'
request.headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'在`parse_item`方法中编写数据解析和提取的逻辑。在`process_request`方法中设置代理IP和User-Agent。
4. 运行爬虫
通过以上设置,我们就可以使用代理IP进行数据爬取了。在命令行中运行以下命令:
scrapy crawl myspider六、总结
本文介绍了如何使用Scrapy框架和代理IP进行大规模数据爬取。通过使用代理IP,我们可以避免被目标网站封禁IP的问题,提高爬取的成功率。Scrapy框架是一个功能强大的Python爬虫框架,可以帮助我们快速、高效地进行数据爬取。希望本文对您理解和应用Scrapy框架和代理IP有所帮助。