在上一篇文件的重定向,通常会涉及文件描述符的操控。文件描述符1(fd 1)通常代表着标准输出(stdout),它默认是指向用户的终端或控制台。当执行文件重定向操作时,如果我们关闭文件描述符1,并打开一个新的文本文件,这个新的文本文件将会接管原本分配给文件描述符1的位置。这意味着,从此刻起,所有原本应该输出到标准输出的内容(比如通过printf函数输出的内容)将会被写入到这个新的文本文件中。
如果在这个过程中,我们使用cat命令来读取这个文本文件的内容,并尝试输出到标准输出,我们在终端上将看不到任何输出,因为标准输出已经被重定向到了文本文件。只有在关闭了重定向到文本文件的文件描述符之后,标准输出才会恢复到终端,此时通过printf函数输出的内容才会再次显示在终端上。
本文就是针对这一现象的解释。其中就涉及到缓冲区。
缓冲区的本质是什么?为什么要有缓冲区??缓冲区在哪里??
细读本文,会有新发现。
什么是缓冲区?
本质就是一块内容!
缓冲区的作用
假如你身处广东,你想给北京的朋友送一份礼物。
- 当然你可以立刻出发(坐车、坐飞机)
在花费大半个的时间后,你终于到达你的朋友身边,将礼物交给他!
- 在过了一年,你又想给你的朋友礼物。但是想起来上一次的经历!千辛万苦、花费大量时间和金钱
这一次,你到学校的快递站。将礼物交给快递员,没过俩天。你的礼物就被送到朋友手上!
将上述的事情抽象:
进程将数据交给缓冲区,缓冲区来统一将数据管理,并送出。
缓冲区管理的好处:
由于有了缓冲区,那么就可以积累一定量的数据,再统一发送!
提高发送的总效率。
缓冲区刷新的方式
由于缓冲区能够暂存数据,那么必须要有能够刷新的方式
- 无缓冲(立即刷新)
- 行缓冲(行满了就刷新)
- 全缓冲(缓冲区满了就刷新)
一般策略:
强制刷新进程结束退出时,要刷新缓冲区
一般对于显示器文件,是行缓冲。
对于磁盘文件是全缓冲(写满了,在刷新)
样例
1 #include<stdio.h>
2 #include<string.h>
3 #include<unistd.h>
4
5 int main()
6 {
7 fprintf(stdout,"C hellow fp\n");
8 printf("C hellow p\n");
9 fputs("C hellow fput\n",stdout);
10 const char *str="system call \n";
11 write(1,str,strlen(str));
12
13 fork();
14 return 0;
15
16 }
在上述的例子中,通过fprintf,printf,fput,这些C语言的接口,和write系统调用的接口向显示器写入5句话,之后fork创建子进程。
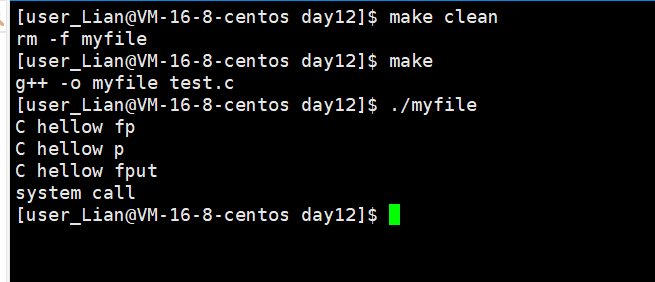
- 编译运行进程,能够按顺序得到五个字符串
当我们直接向显示器打印的时候,显示器对应的文件是行刷新,而我们的字符串每一句话后面都有\n !fork()之前内容已经全部被刷新。
2.重定向到log.txt
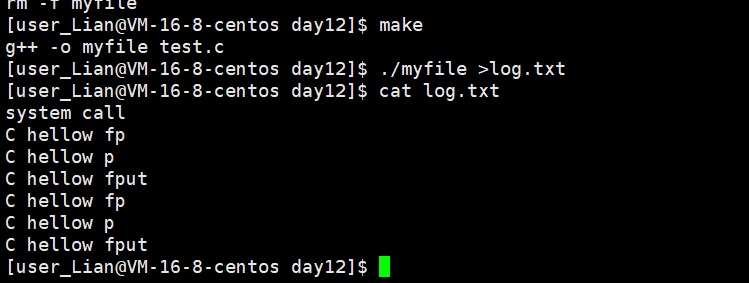
系统调用在前,fprintf fprint和fput都被调用了俩次!
分析问题
我们重定向到log.txt本质就不是往显示器文件输出了,而是往磁盘,刷新方式变味了全刷新。
全缓冲意味着缓冲区的空间会更大于行缓冲,我们写入的简单数据,势必不能将缓冲区写满。fork执行的时候,缓冲区得不到刷新,数据依旧在缓冲区里。
对于系统调用的write只被刷新一次,说明系统调用缓冲区有所不同。
结论:
目前我们谈到的缓冲区都是C语言的缓冲区,和OS没有关系,是操作系统的!
fork()退出后,任意一个进程在退出的时候,就要发生写时拷贝。
write调用是直接写到OS中,没有使用C语言的缓冲区。
C语言的缓冲区在哪里!
封装在file*的结构体里
FILE* 的结构体内不仅封装了fd文件描述符,还包含buffer的缓冲区。日常中,我们使用最多的就是C/C++的缓冲区!
在使用printf和fprintf的C结口函数时,并不是调用write函数,而是把数据写入结构体里的缓冲区。
当数据积累到一定规则后,调用write函数,将C语言缓冲区的数据写入OS的缓冲区中
这就是C语言的缓冲区,充当了一个中介。
总结
缓冲区能提高调用者的效率,减少磁盘的读写次数。
缓冲区刷新的规则有全缓冲、无缓冲、行缓冲。
显示器一般是行缓存,磁盘文件是全缓冲。
我们平时说的缓冲区是C/C++的,每一个file*结构体都有一个C/C++缓冲区