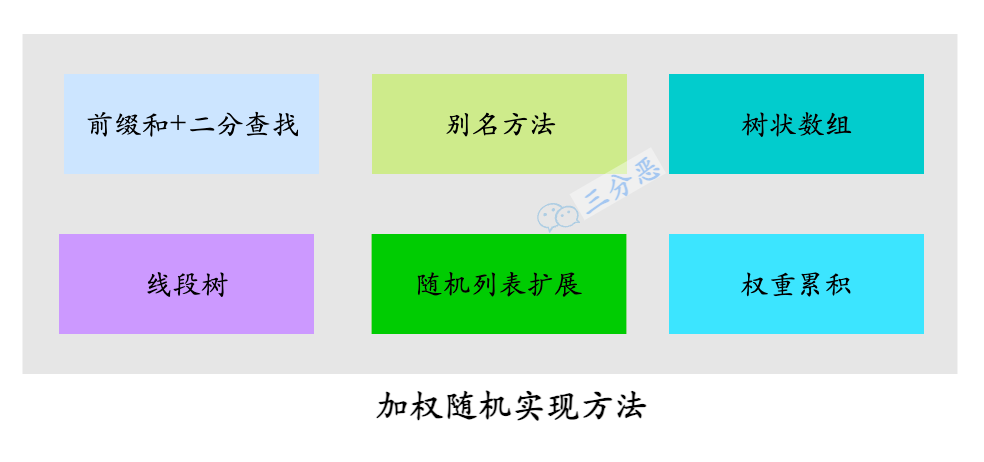
AIGC领域正迅速发展,特别是在视频生成方面取得了显著进展。本文介绍了AIGCBench,这是一个首创的全面而可扩展的基准,旨在评估各种视频生成任务,主要关注图像到视频(I2V)生成。AIGCBench解决了现有基准的局限性问题,这些问题主要表现为缺乏多样化的数据集,通过包含一个多样且开放域的图像文本数据集,该数据集评估了不同的最新算法在等效条件下的性能。本文采用了一种新颖的文本组合器和GPT-4来创建丰富的文本提示,然后使用先进的文本到图像模型生成图像。为了为视频生成任务建立统一的评估框架,本文使用的基准包括11个指标,涵盖了四个维度,以评估算法的性能。这些维度是控制-视频对齐、运动效果、时间一致性和视频质量。这些指标既依赖于参考视频又不依赖于视频,确保了一个全面的评估策略。所提出的评估标准与人类判断很好地相关,为了解当前I2V算法的优势和劣势提供了见解。本文广泛实验的结果旨在激发I2V领域的进一步研究和发展。AIGCBench代表了在更广泛的AIGC领域创建标准基准的重要一步,提出了一个适应性强、公平公正的未来视频生成任务评估的框架。
引言
人工智能生成内容(AIGC)涵盖了一系列利用AI技术自动创建或编辑各种媒体类型的应用,包括文本、图像、音频和视频。随着扩散模型和多模态AI技术的快速发展,AIGC领域正在取得显著而迅速的进步。AIGC的爆炸式增长使其评估和基准设定成为紧迫的任务。
AIGC的一个典型应用是视频生成。当前视频生成包括文本到视频(T2V)、图像到视频(I2V)、视频到视频(V2V)以及一些利用额外信息如深度、姿态、轨迹和频率来生成视频的其他工作。其中,T2V和I2V目前是最主流的两个任务。早期的视频生成主要使用文本提示生成视频并取得了良好的结果。然而,仅使用文本使得难以描述用户想要的特定场景。最近,I2V引起了AIGC社区的关注。I2V任务是指基于静态输入图像生成动态移动视频序列,通常伴随着文本提示。与T2V相比,I2V能更好地定义视频生成的内容,在许多场景中取得了出色的效果,如电影、电商广告和微动画效果。
虽然T2V任务的基准取得了显著进展,但I2V任务的基准进展甚微。之前的努力,如潜在流扩散模型(LFDM)和 CATER-GEN,在特定领域的视频场景下进行了测试。VideoCrafter和 I2VGen-XL仅利用视觉比较进行了I2V任务的测试。Seer和 Stable Video Diffusion(SVD)使用了视频文本数据集,并利用了一些需要参考视频的度量标准。现有的I2V基准存在以下问题:1)缺乏多样化的开放域图像,涵盖各种主题和风格,以测试不同最新算法的有效性;2)在评估最终生成的结果时缺乏对使用哪些评估指标的统一共识。从 [47] 的角度来看,这两个缺点阻碍了捕捉利益相关者关切和兴趣的能力,同时也未能构建等效的评估条件。
为填补这一空白,本文提出了AIGCBench,这是一个统一的视频生成任务基准。AIGCBench旨在涵盖所有主流的视频生成任务,如T2V、I2V、V2V以及从附加的模态(如深度、姿态、轨迹和频率)合成视频。下图1中概述了AIGCBench。

AIGCBench分为三个模块:评估数据集、评估指标以及要评估的视频生成模型。考虑到视频生成任务的高相关性和相互连接性,AIGCBench可以在等效的评估条件下比较不同算法。这使得能够分析不同最新视频生成算法的优缺点,从而促进视频生成领域的进展。在AIGCBench的第一个版本中,通过为I2V任务提供全面的评估来解决当前缺乏合理基准的问题。在后续版本中,计划包括更多的视频生成任务,并将它们置于等效的评估条件下,以进行公平比较。
鉴于现有基准的局限性,AIGCBench被设计以满足用户对动画化广泛静态图像的多样需求。在之前的基准中存在不足之处,未能充分适应用户可能选择动画的广泛图像范围,例如在时代广场滑板的蓝龙,AIGCBench迎接了这一挑战。通过使用文本组合器生成丰富多样的文本提示,涵盖多种主题、行为、背景和艺术风格来解决这个问题。为了进一步完善创意过程,利用GPT-4的先进功能增强文本提示,使其更生动、更复杂。这些详细的提示然后通过最先进的文本到图像扩散模型引导图像生成。通过巧妙地结合视频文本和图像文本数据集,以及生成的图像文本对,AIGCBench确保对一系列I2V算法进行了强大而全面的评估,从而解决了现有基准中存在的第一个主要缺陷。
为建立一个全面且标准化的评估指标体系,以满足主流任务(如T2V和I2V)的视频生成任务,AIGCBench评估了四个关键维度:控制-视频对齐、运动效果、时间一致性和视频质量,从而全面捕捉视频生成的各个方面。这一集成框架结合了既依赖于参考视频的指标,又包括不依赖于视频的指标,增强了基准的严谨性,不仅仅依赖于视频文本数据集或图像文本数据集。通过将图像文本数据集纳入评估中来加强这一方法,这使本文能够评估超出现有视频文本数据集范围的内容,并为评估添加不依赖于参考视频的指标。实验结果表明,本文的评估标准与人类评分高度相关,证实了其有效性。经过彻底的评估,呈现了每个模型的优势和劣势,以及一些见解深刻的发现,希望能促进对I2V领域的进一步讨论。
本文的贡献如下:
-
引入AIGCBench,一个用于全面评估多样化视频生成任务的基准,最初侧重于图像到视频(I2V)生成,并承诺将这些模型置于等效的评估条件下,以进行公平比较。
-
通过使用文本组合器和GPT-4,结合最先进的文本到图像模型,扩展了图像文本数据集,生成高质量图像,从而深入评估I2V算法的性能。
-
使用依赖于参考视频的指标和不依赖于视频的指标全面评估I2V算法,涵盖了四个方面,并通过人类判断验证了本文提出的评估标准的有效性。
-
提供了一些见解深刻的发现,以帮助更好地推动I2V社区的发展。
背景与相关工作
当前视频生成主要包括两个主要任务:文本到视频(T2V)和图像到视频(I2V)。鉴于T2V任务与I2V任务的高相关性,将介绍与T2V相关的基准,描述对I2V任务的现有评估,并简要介绍I2V模型。
文本到视频生成的基准
FETV基准对代表性的T2V模型进行全面的手动评估,从多个角度揭示了它们在处理多样化的文本提示时的优势和劣势。EvalCrafter首先利用大语言模型创建了一组新的T2V生成提示,确保这些提示能够代表实际用户查询。EvalCrafter的基准被精心设计,以从视觉质量、内容准确性、动态运动和生成视频内容与原始文本标题之间的对齐等几个关键方面评估生成的视频。VBench创建了16个不同的评估维度,每个维度都有专门的提示,以进行精确评估。
T2V任务与I2V任务不同,因为从相同文本生成的视频可能差异很大,这使得其不太适合需要参考视频的评估指标。对于T2V任务,不同模型对于相同文本提示生成的结果可能相差较大。然而,对于I2V任务,由于图像施加了一定的约束,不同模型生成的结果变化通常不会那么显著。此外,考虑到模型的输入包含图像信息,还必须考虑图像的复杂性。AIGCBench借鉴了这些T2V基准,但在几个方面与它们不同:1)需要为I2V模型的输入收集或构建图像,这需要考虑文本提示集和图像集的全面性。2)尽管评估在评估的维度上类似于T2V任务,但由于T2V和I2V任务之间的差异,需要采用新的评估标准。
图像到视频生成的基准
「特定域的I2V基准」。LFDM Eval在面部表情和人体动作数据集上进行评估,仅使用少量评估指标来衡量视频生成的质量。CATER-GEN基准使用预定义的3D目标和特定的初始图像来测试描绘3D目标运动的视频质量。然而,LFDM Eval和CATER-GEN基准都不适用于在开放域场景中评估视频生成。
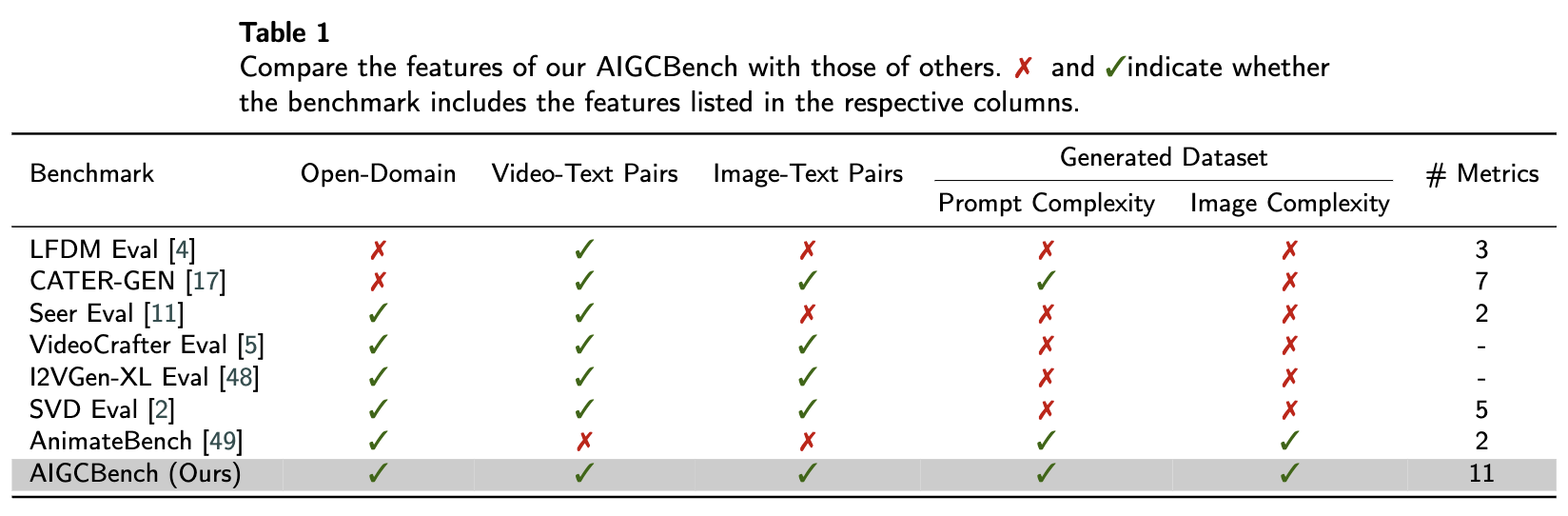
「开放域的I2V基准」。目前,开放域的I2V基准主要基于两种类型的评估数据:视频文本和图像文本数据集。Seer和SVD利用了视频文本数据集,并使用了一些需要参考视频进行评估的有限指标。VideoCrafter和I2VGen-XL使用图像文本数据集,并完全依赖于视觉比较。最近,AnimateBench旨在评估I2V任务。他们也使用文本到图像模型生成图像。然而,他们受限于少量文本提示和有限的图像集合。同时,缺乏全面的评估指标。这两者都受到有限的评估数据集和不完整的评估指标集的制约。本文使用最先进的文本到图像模型扩展图像文本数据集。为了确保生成的文本提示的复杂性,通过四种元类型的组合遍历生成提示,并利用大语言模型的能力进行增强。将AIGCBench与其他I2V基准进行了比较,见下表1。
图像到视频生成
由于扩散模型和多模态技术的发展,视频生成算法变得越来越复杂。早期的视频生成主要基于文本到视频的方法。然而,考虑到仅使用文本可能难以直观地描绘用户想要生成的视频场景,图像到视频开始在视频生成社区中变得流行。
Seer引入了一种I2V任务的方法,将条件图像潜在与噪声潜在结合,在3D U-Net的时间组件中利用因果关注。VideoComposer将图像嵌入与图像样式嵌入串联起来,以保留初始图像信息。最近,VideoCrafter通过轻量级图像编码器对图像提示进行编码,并将其输入交叉注意力层。类似地,I2VGen-XL不仅在输入层将图像潜在与噪声潜在合并,还使用全局编码器将图像CLIP特征提取到视频潜在扩散模型(VLDM)中。稳定视频扩散是预训练的基于图像的扩散模型的扩展。它通过三个阶段进行训练:文本到图像的预训练、视频预训练和高质量视频微调。Emu Video确定了一些关键的设计决策,如扩散和多阶段训练的调整噪声计划,使其能够生成高质量的视频,而无需像以前的工作那样深层次地级联模型。除了学术研究外,来自产业玩家如Pika 和Gen2的视频生成结果也相当令人印象深刻。所有这些I2V算法都基于视频扩散模型,大多数利用图像扩散模型的参数先验以帮助视频模型的收敛。
为了评估最先进的I2V模型,在本文中审查了三个开源工作:VideoCrafter、I2VGen-XL和Stable Video Diffusion,以及两个闭源产业努力,Pika和Gen2。这些目前代表着视频生成社区中最有影响力的五个工作,后面将简要介绍它们的实验参数。
AIGCBench:建立图像到视频生成基准
AIGCBench框架如前面图1所示。AIGCBench框架包括三个组件:评估数据集、待评估的视频生成模型和评估指标。为构建一个全面的基准,使用两种类型的数据集评估I2V模型:视频文本和图像文本。对于图像文本数据集,利用不需要参考视频的评估指标。在本节中,将介绍如何收集评估数据集,建立的评估标准,以及简要介绍待评估的视频生成模型。
从现实世界的视频文本对中收集数据集
WebVid-10M数据集是一个庞大的集合,专门设计用于发展和培训用于视频理解任务的AI模型。它包含约1000万个视频文本对,使其成为此类研究中可用的较大数据集之一。考虑到视频生成是耗时的,从WebVid10M数据集的验证集中基于子类型对进行了1000个视频的采样,用于评估目的。
图像文本对LAION-5B数据集是一个大规模的开放数据集,包括约585亿个图像文本对。它被创建以促进计算机视觉和机器学习领域的研究,特别是在多模态语言-视觉模型、文本到图像生成等领域(例如CLIP、DALL-E)方面。LAION-Aesthetics是LAION-5B的子集,具有高视觉质量。从LAION-Aesthetics数据集中随机采样了925个图像文本对,用作无视频参考的评估指标。
生成的图像文本对
仅使用现实世界的数据集是不够的。用户通常输入由设计师或T2I(文本到图像)模型生成的图像和文本来创建视频。这包括在现实世界中无法采样的某些图像文本对。为了弥补这一差距,提出了一个T2I生成pipeline。如下图2所示,概述了生成pipeline,并在下面呈现了一些生成的案例。

文本组合器
为了生成尽可能多样化的文本提示,基于四种类型构建文本模板:主题、行为、背景和图像风格。然后,按照模板生成了一个包含3,000个文本提示的列表:主题+行为+背景,在图像风格样式中。列举了一些例子:
-
主题:一条龙、一名骑士、外星人、机器人、熊猫、仙女;
-
行为:骑自行车、与怪物战斗、寻找宝藏、跳舞、解谜;
-
背景:在森林中、在未来城市中、在太空站中、在老西部城镇中的正午;
-
图像风格:油画、水彩、卡通、写实、梵高、毕加索。
从Civit AI T2I社区中用户经常输入的高频词汇中编制了文本语料库,同时加入了一些可能有价值的文本提示。考虑到生成pipeline的灵活性,基准是可扩展的。随后,可以更新和迭代文本语料库的版本。
优化文本提示
尽管使用各种文本语料库的文本模板可以生成合理的图像,但可能导致生成的图像缺乏多样性,这对于评估I2V任务并不有利。利用GPT-4模型 的能力,使用提示“使内容更生动丰富”来优化从模板生成的文本。
生成图像和筛选
为了基于生成的文本生成高质量的图像,采用了迄今为止最好的文本到图像(T2I)模型 - Stable Diffusion模型。Stable Diffusion模型特别值得注意,因为它能够创建与输入文本提示描述的风格和内容紧密匹配的高质量、连贯的图像。使用了由其社区发布的最新xl-base T2I模型。考虑到I2V模型主要是以16:9的宽高比进行训练的,使用高度720和宽度1280来生成图像。
为了选择高质量的图像文本对,作者根据T2I-CompBench的自动指标筛选出了前2000个高质量的图像文本对。pipeline生成的一些示例可以在图2的下半部分看到。
评估指标
本文的评估数据集包括视频文本和图像文本两种类型的数据集。为了进行全面的评估,采用了两种类型的评估指标:一种需要参考视频,另一种不需要。此外,还考虑了先前的文本到视频基准,并将其整合提出了一种适用于图像到视频(I2V)任务的评估标准,涵盖了这两种类型的数据集。从四个方面评估了不同I2V模型的性能:控制-视频对齐、运动效果、时间一致性和整体视频质量。考虑到由不同算法生成的视频具有不同数量的帧,为了进行标准化评估,采用提取前16帧的方法,除非另有说明。
控制-视频对齐
考虑到当前视频生成任务主要涉及两种类型的输入——一个起始图像和一个文本提示——在我们基准的第一个版本中引入了两个评估指标:图像保真度和文本-视频对齐。图像保真度指标评估生成的视频帧与输入到I2V模型的图像(特别是第一帧)有多相似。为了评估保真度,对于生成视频的第一帧,使用均方误差(MSE)和结构相似性指数(SSIM)等指标来计算第一帧的保留程度。对于整体视频帧,计算输入图像和生成视频的每一帧之间的图像CLIP相似性。分别使用MSE(First)、SSIM(First)和图像-生成视频CLIP来表示这三个评估指标。
考虑到我们评估的I2V模型还将文本作为输入,需要评估生成的视频是否与输入的文本相关。对于生成的视频,使用CLIP计算输入文本和生成的视频结果之间的相似性。假设视频文本数据集中的视频与文本描述一致。对于视频文本数据集,使用参考视频和生成的视频的关键帧来计算CLIP相似性。考虑到文本通常描述高级语义,并且生成的视频可能与原始视频并不完全对应,均匀采样四个关键帧进行比较。分别使用GenVideo-Text Clip和GenVideo-RefVideo CLIP(关键帧)来表示这两个评估指标。
运动效果
运动效果主要评估生成视频中运动的幅度是否显著以及运动是否合理。关于运动的幅度,遵循 [23, 19],使用预训练的光流估计方法,RAFT,来计算生成视频相邻帧之间的流分数,最终的平均值表示运动效果的幅度。使用相邻帧预测值的平方平均值来表示视频的运动动态,较高的值表示更强的运动效果。考虑到视频生成中存在一些糟糕的情况,设置了一个阈值,使得平方平均值必须小于10,以过滤掉这些糟糕的情况。对于视频文本数据集,有与文本对应的真实视频。通过计算生成视频的每一帧与参考视频的每一帧之间的相似性,然后取平均值来衡量生成的运动效果的合理性。为了保持鲁棒性,使用图像CLIP度量来计算帧之间的相似性。分别使用Flow-Square-Mean和GenVideo-RefVideo CLIP(对应帧)来表示这两个评估指标。
时间一致性
时间一致性衡量生成的视频帧是否相互一致且连贯。计算生成视频中每两个相邻帧之间的图像CLIP相似性,并将平均值作为生成视频的时间一致性的指标。使用GenVideo Clip(相邻帧)来表示这个评估指标。此外,还使用GenVideo-RefVideo(对应帧)来表示时间一致性。
视频质量
视频质量是一个相对主观的维度,衡量视频制作的整体质量。首先使用视频生成的帧数来评估不同算法生成长视频的能力。利用无参考视频质量评估度量(DOVER),这是一种无参考视频质量评估度量。DOVER从审美和技术两个方面全面评估视频,使用收集到的DIVIDE-3k数据集。实验结果表明,DOVER度量在审美和技术两个方面高度与人类意见相关。对于DOVER评估指标,使用各自算法生成的所有帧来计算它。对于视频文本数据集,由于有参考视频可用,通过计算生成视频的每一帧与参考视频的对应帧之间的SSIM(结构相似性指数)来衡量生成视频与参考视频之间的空间结构相似性。我们将这个评估指标表示为GenVideo-RefVideo SSIM。
实验
被评估的模型
开源项目
「VideoCrafter」 VideoCrafter是一个用于制作视频内容的开源视频生成和编辑工具箱。它支持从图像生成视频。使用了一个导向尺度为12和25个ddim步骤。对于宽高比为1的视频,使用分辨率为512 * 512,而对于宽高比为0.5625的视频,使用分辨率为512 * 320,然后统一调整大小以与其他方法使用的分辨率对齐。
「I2VGen-XL」 I2VGen-XL是由阿里巴巴同益实验室开发的开源视频合成代码库,具有先进的视频生成模型。使用导向尺度为9进行推理,并使用fp16精度。
「Stable Video Diffusion」 Stable Video Diffusion (SVD)是基于Image Stable Diffusio的模型的扩展。使用了 Stable Video Diffusion 的25帧版本。值得注意的是,当前的模型暂时不支持文本输入,因此没有计算该模型的文本-视频对齐。
闭源项目
「Pika」 Pika是一家通过使视频创建变得轻松和可访问,正在彻底改变视频创作的技术公司。仅在六个月内,Pika建立了一个拥有数十万用户的社区,每周制作数百万个视频。该公司最近推出了Pika 1.0,这是一个重大升级,具有支持各种视频风格的新AI模型,包括3D动画、动漫、卡通和电影,同时还改进了Web体验。鉴于Pika没有开源代码,作者在Discord平台上手动测试了60个案例(30个来自WebVid数据集,30个来自我们自己生成的数据集)。使用了默认的运动设置为1和导向尺度设置为12。
「Gen2」 Gen2是一个多模态人工智能系统,可以生成具有文本、图像或视频剪辑的新型视频。使用了演示中的默认运动设置为5,并且没有使用相机运动参数来生成视频。
综合结果分析
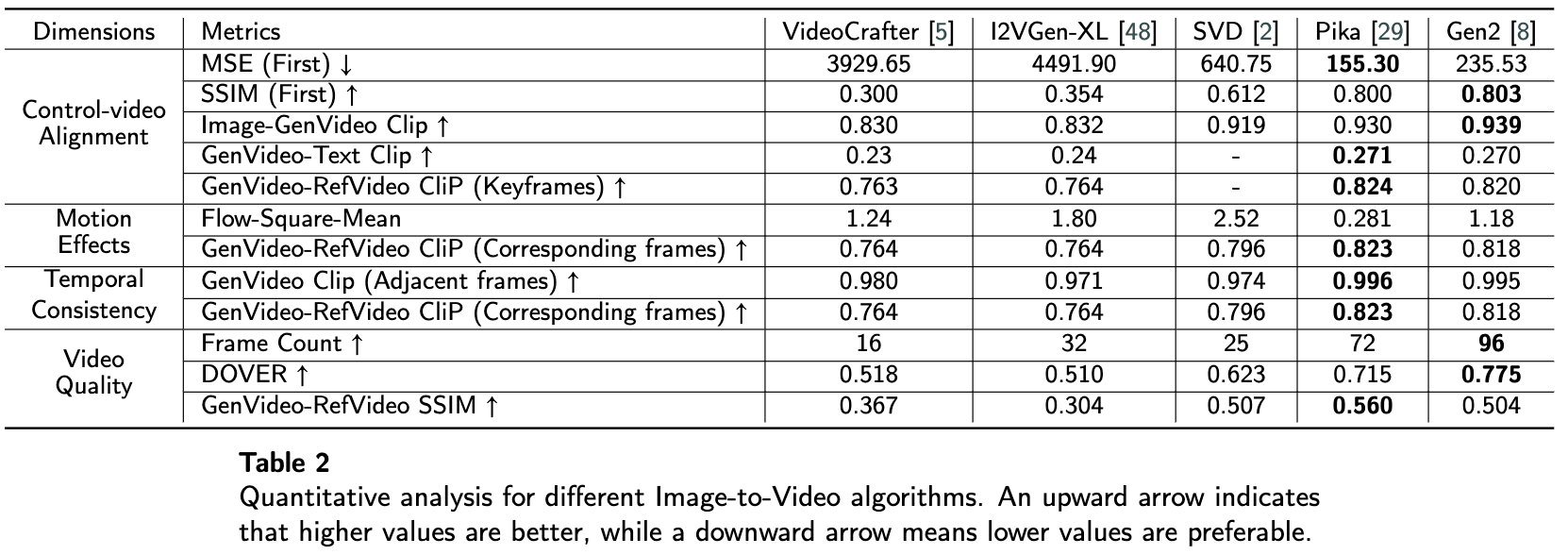
下表2呈现了五种最先进的I2V算法在五个维度上的评估结果:图像保真度、动效、文本-视频对齐、时序一致性和视频质量。
下图3中展示了不同I2V算法的定性结果。

发现VideoCrafter和I2VGen-xl在保留原始图像方面存在困难。I2VGen-xl保持了相对良好的语义,但初始图像的空间结构大多未被保留。VideoCrafter在一定程度上能够近似初始图像的空间结构,但对细节的保留通常一般。SVD、Pika和Gen2相当好地保留了原始图像,其中Gen2实现了最佳的保留效果。至于文本-视频对齐方面,Gen2和Pika几乎持平,并且两者均优于开源算法。然而,现有的算法和评估指标并不能有效捕捉细粒度的文本变化。在动效方面,VideoCrafter往往保持静态。I2VGen-xl和SVD更倾向于摄像机运动而非主体运动,这解释了它们在流平均方面得分较高但在GenVideo-RefVideo Clip方面得分较低。Pika倾向于同时支持局部运动和主体运动,因此在GenVideo-RefVideo Clip方面得分较高而在流平均方面得分较低。另一方面,Gen2偏爱前景和背景的运动,但背景运动不如SVD明显。在时序一致性方面,由于其较差的动效,VideoCrafter在时序一致性方面表现不佳。考虑到SVD具有较强的动效且仍然保持良好的时序一致性,因此在开源I2V算法中表现最佳。类似地,由于其局部运动的倾向,Pika在总体时序一致性方面表现最好。至于视频质量,Gen2能够生成最长达96帧的视频,具有最高水平的美感和清晰度。由于其局部运动的倾向,Pika在GenVideo-RefVideo SSIM指标中实现了最高的相似度。SVD受益于图像稳定扩散模型的先验知识,导致在开源I2V算法中达到最佳性能的视频。总的来说,两个闭源项目,Pika和Gen2,实现了最理想的生成效果,能够生成长视频。Pika在生成局部运动方面表现出色,而Gen2更倾向于全局运动。SVD在开源选项中取得了最佳结果,其结果接近这两个闭源项目的结果。
用户研究
为了验证所提出的评估标准是否与人类偏好一致,随机抽取了每种方法的30个生成结果,并通过人工投票统计了每个维度(图像保真度、动效、时序一致性、视频质量)中的最佳算法结果。共计统计了42个参与者的投票,具体结果见下图4。

Gen2的性能与Pika持平,两者均取得了最佳结果。Pika在时序一致性和动效方面表现出色,而Gen2在图像保真度和视频质量方面表现最佳。SVD在所有方面都表现出平衡的性能,在开源选项中取得了最佳结果。用户的投票相对一致地与本文的评估标准得出的结果相符。
发现与讨论
尽管I2V取得了显著的成就,新算法也在快速更新,但现有解决方案仍有很大改进的空间。通过对学术界和工业界最先进的五种I2V算法进行详细调查和评估,得出了以下发现:
「缺乏细粒度控制」 在I2V任务中,文本输入也至关重要。用户期望通过将精确的文本描述与图像结合,生成合理且具有美感的结果。考虑到大多数现有解决方案依赖于CLIP或大语言模型的编码器,认识到它们的局限性是重要的。CLIP模型是在图像-文本对上训练的,而大语言模型是在纯文本数据上训练的,这使得这些文本编码器难以捕捉细粒度的时间特征。作者认为有必要专门为视频上下文训练一个大规模的跨模态模型,以使视频和文本相互对齐,从而实现对视频生成的细粒度控制,提升用户体验。
「孤立的视频生成」 当前的I2V算法在单次推理中最多可以生成96帧,远不能满足用户对更长视频制作的需求。考虑到视频场景通常具有24帧每秒的帧率,主流算法的基本生成能力约为3秒。解决这一限制主要有两种方法。一种是使用多次推理,其中大多数采用粗到细的生成流程——首先生成稀疏的关键帧,然后密集生成所有帧。这种方法的挑战在于在多次推理中保持时间一致性。另一种方法是使用单一模型的多GPU训练和推理,目前在保证令人满意的结果方面仍存在困难。如何生成更长的视频应该是AI生成内容(AIGC)社区下一步需要解决的紧急问题。
「推理速度」 目前,视频生成的速度相对较慢。对于一个3秒的视频,主流算法通常在V100显卡上需要约1分钟。考虑到视频生成场景是基于扩散模型,目前有两种主要加速过程的路径。一种是在潜在空间中减少视频的维度。例如,Stable Diffusion将视频映射到潜在空间,大致将视频的大小减小了约8倍,而视频质量只有最小的损失。另一种是提高扩散模型的推理速度,这也是AIGC(人工智能生成内容)社区的一个热门研究课题。
结论
本文介绍了AIGCBench,这是一个专为评估图像到视频(I2V)生成任务而定制的全面而可扩展的基准。AIGCBench提供了一个迫切需要的框架,以在相等的评估条件下评估各种最先进的I2V算法的性能。本文的基准通过整合多样化的真实世界视频文本和图像文本数据集,以及通过专有生成流程产生的新颖数据集,脱颖而出。此外还提出了一套新颖的评估指标,涵盖了四个关键维度:控制-视频对齐、运动效果、时间一致性和视频质量。这些指标已通过与人类判断的验证,以确保它们与人类偏好保持一致。对领先的I2V模型的广泛评估不仅突显了它们的优势和劣势,还发现了将指导I2V领域未来发展的重要见解。
AIGCBench标志着AIGC基准评估的基础性一步,推动了I2V技术评估的前沿。通过提供一个可扩展且精确的评估方法论,为这个迅速发展的研究领域中的持续增强和创新奠定了基础。随着进展,计划将AIGCBench扩展到涵盖更广泛的视频生成任务,打造一个统一而广泛的基准,反映AIGC多方面的本质。
限制与未来工作
由于I2V模型视频生成的推断速度较慢,以及一些工作未开源(例如,Pika,Gen2),本文的基准仅评估了3950个测试案例。考虑到视频生成任务的复杂性,作者认为这个数字是不足够的。此外,由于目前缺乏精细的视频识别模型,评估系统无法准确判断生成的视频中的目标移动方向是否与文本描述相匹配。例如,水流是从左到右还是从右到左,目前无法通过自动评估指标准确确定生成的视频中水流的方向是否与文本描述一致。
未来将把与T2V和新的视频生成任务相关的任务整合到一个大规模的视频生成基准中。此外,为了解决上述问题,可能会训练一个与文本对齐的精细视频表示模型,该模型将用于视频和文本场景的精细对齐。
参考文献
[1] AIGCBench: Comprehensive Evaluation of Image-to-Video Content Generated by AI
论文链接:https://arxiv.org/pdf/2401.01651
多精彩内容,请关注公众号:AI生成未来