从2017年底到2018年初,整个人工智能学术研究领域谈论最多的应该就是被誉为深度学习之父Geoffrey E. Hinton 发表的论文 Dynamic Routing Between Capsules,其中介绍了全新的深度学习模型——胶囊网络(Capsule Network)
1. 普通CNN的困境
虽然CNN在图像识别领域取得了巨大成功并掀起了深度学习浪潮,Hinton指出CNN的工作方式与人类大脑大相径庭,继续沿着CNN的“卷积——池化”模型进行同构扩展无法达到更高的智能水平。
相对于普通神经网络,CNN的主要创新在于用卷积层自动提取各层级的特征并用这些特征进行最终预测。然而卷积层使得神经元数量大量增加,在提取特征后必须用池化层(一般为Max-pooling)进行数据降维才形成最终特征,由此带来的问题是:
- Max-pooling 使得卷积层中的非局部最大点的信息丢失
- Max-pooling 丢失了卷积识别出的特征在位置与角度等方面的信息。
第一条并非完全是一个缺点,它在某种程度上增加了网络的鲁棒性;但第二条会带来大问题,即它使得后续的处理无法识别特征之间的位置关系。
观察图9-48(左),其中有四个几何特征:大矩形、小矩形、两个圆形,神经网络可以通过这四个特征学习到它是一辆汽车。但如果丢失了这些特征的位置信息,则很可能将同样具有这四个特征的图9-48(右)也识别成一辆汽车。

2. 什么是胶囊
产生CNN困境的根本原因是在普通神经网络中执行运算的基本单位——神经元(neural)——处理的数据是标量(scalar),在卷积层后用抛弃神经元的方式降低数据复杂度直接丢失了很多信息。
而在新的架构中,承载运算的基本单元——胶囊(capsule)——处理的数据变成了向量(vector),用向量的线性变换降低数据复杂度使得所有信息都能够参与其中。
这个改变推翻了沿用了几十年的基于神经元的网络计算方法,产生了全新的基于向量的胶囊运算流程。胶囊与传统神经元的运算方式对比如图9-49所示。
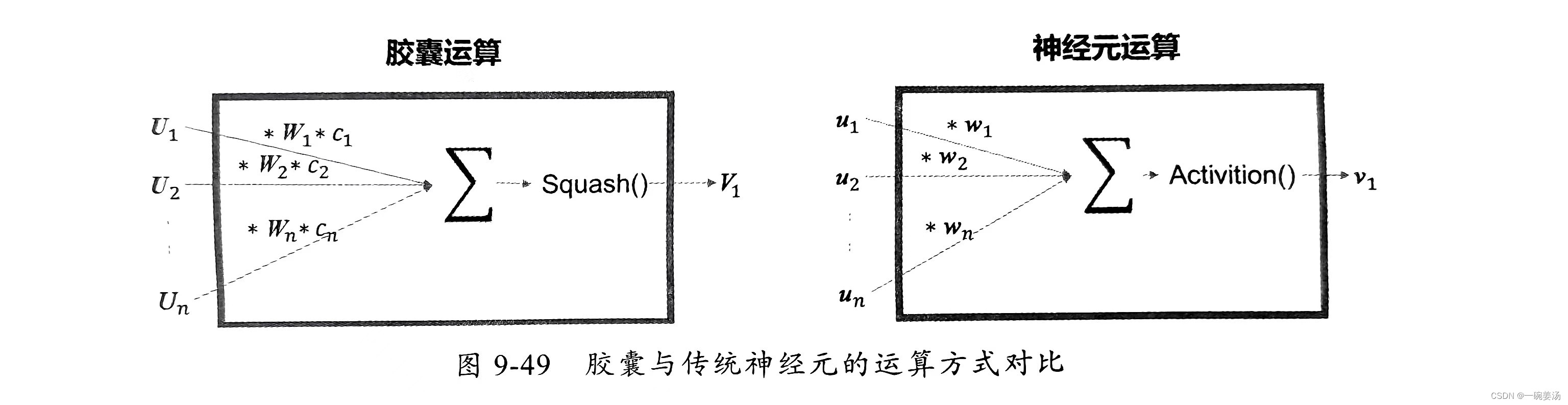
对该图解释如下:
- 胶囊的输入
与输出
均是向量,神经元输入与输出均是标量。
- 胶囊中的参数
是矩阵,用于对输入向量进行线性变换,从物理的角度理解就是做旋转、位移、缩放等处理,这部分功能是传统神经元中的缺失。
- 胶囊中的参数
是标量,作用相当于普通神经网络中的
,用于衡量每个输入的重要性。
- 普通神经元用各种
函数做非线性变换,而胶囊用所谓的
函数对向量进行非线性变换。
在Hinton的论文中采用的 函数形如
,该函数保持向量
方向不变,而只改变向量
的长度。在胶囊网络中,向量的方向用于定义某种特征,而向量的长度用于表示该特征存在的可能性,因此可以将
函数理解为对预测置信度的调整与归一化。
3. 网络架构
论文在提出了胶囊的概念后设计了一个用于识别MNIST(数字手写图像库)的胶囊网络架构,如图9-50所示。
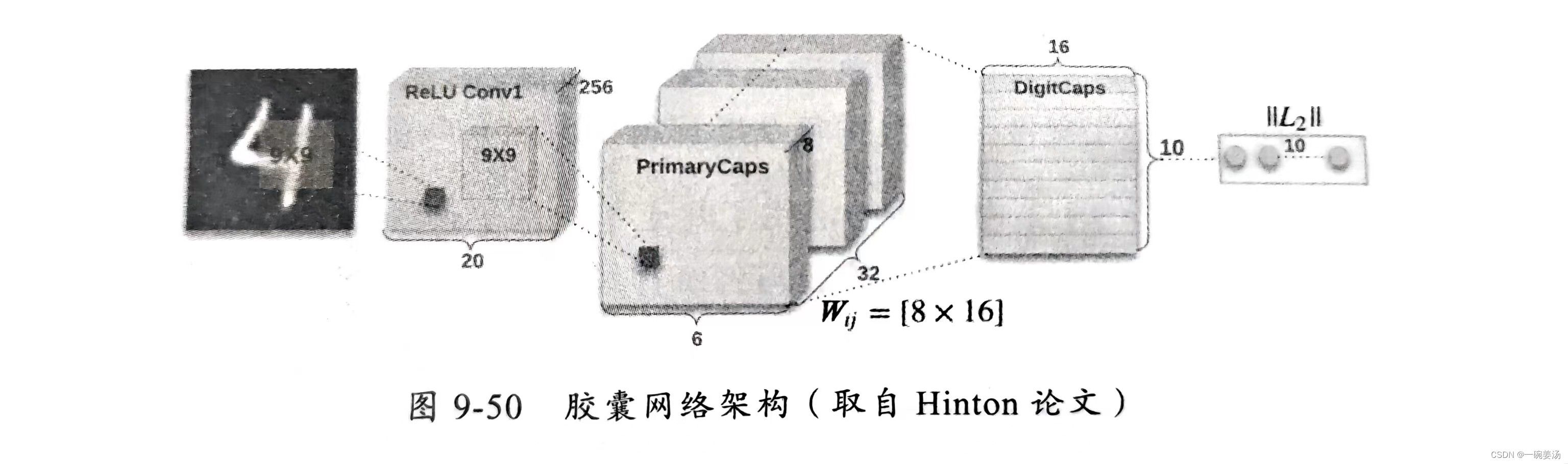
对该网络解释如下:
- 通过卷积层对原始图像进行特征提取,形成256个 feature map
- 与普通CNN不同的是,在卷积层后没有使用池化层进行数据降维,而是使用胶囊层 PrimaryCaps。
- 由于卷积层有256个 feature map,因此胶囊层的每个输入向量是256维,即图9-49中的
等都是256维向量。
- 与卷积层每个神经元从原始图像中的某个局部区域扫描特征类似,每个胶囊也从上一层的某局部区域的向量获得输入,论文中每个 PrimaryCaps 中的胶囊有
个输入向量,即图9-49中的输入向量个数n等于81。
- PrimaryCaps 中共有
个胶囊,每个胶囊输出 8 维向量。
因此,卷积层中的标量数值共有 个,而 PrimaryCaps 中的标量数值共有
个,达到了相当于池化层的降维目的,并且不会丢失卷积层中特征的位置信息。
在 PrimaryCaps 之后可以连接任意胶囊层继续搭建网络,其意义与在CNN中用多个卷积层逐层提炼更高级别知识的作用类似。
此外,论文中还提到了胶囊网络参数新的训练方法——动态路由算法(Dynamic Routing Algorithm),它用于替代传统网络中的反向传播对图9-45中的参数进行训练,有兴趣的读者可以研读原论文。