本文主要介绍OpenMP并行编程技术,编程模型、指令和函数的介绍、以及OpenMP实战的几个例子。希望给OpenMP并行编程者提供指导。
🎬个人简介:一个全栈工程师的升级之路!
📋个人专栏:高性能(HPC)开发基础教程
🎀CSDN主页 发狂的小花
🌄人生秘诀:学习的本质就是极致重复!
目录
一、OpenMP 简介
二、OpenMP 编程模型
1. 指令与库函数
1.1 OpenMP指令格式
1.1.1 并行区域(Parallel Region)
1.1.2 并行构造(Parallel Construct)
1.1.3 任务(Task)
1.1.4 同步(Synchronize)
1.2 OpenMP常用的指令和函数
1.3 OpenMP常用库函数
2. 并行执行
3. 线程管理
4. 同步与通信
5. 调度策略
三、OpenMP编程实战
1 Linux下编译选项
2 C语言 OpenMP 并行化程序示例(包含)
3 C++ OpenMP并行编程示例(包含宏定义#ifdef _OPENMP)
4 OpenMP 多线程性能对比
一、OpenMP 简介
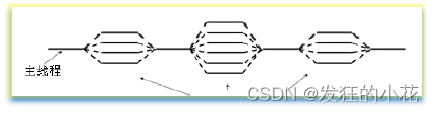
OpenMP 是一个为共享内存并行计算设计的编程接口,广泛应用于 Fortran、C 和 C++ 语言。它提供了一套编译器指令和库函数,使得开发者能够轻松地编写并行程序。OpenMP 的“fork/join”模型是其中最核心的并行执行模式,其中最初只有一个主线程在运行。当遇到需要并行计算的部分时,主线程会派生出其他线程来执行并行任务。当并行代码执行完毕,派生的线程会退出或挂起,控制权回到主线程。类似与多线程技术。
二、OpenMP 编程模型
1. 指令与库函数
OpenMP 的基本语法是通过预处理指令 #pragma omp 来实现的。例如,#pragma omp parallel for 用于并行化 for 循环。此外,OpenMP 还提供了一系列的库函数,用于线程的创建、同步等操作。这些库函数和指令使得开发者能够更灵活地控制并行程序的执行。
1.1 OpenMP指令格式
1.1.1 并行区域(Parallel Region)
用于指定一个代码块,该代码块将在多个线程上并行执行。
#pragma omp parallel
{
// 并行执行的代码块
}
1.1.2 并行构造(Parallel Construct)
用于创建一个新线程并执行指定的代码块
#pragma omp parallel sections
{
#pragma omp section
{
// 线程1执行的代码块
}
#pragma omp section
{
// 线程2执行的代码块
}
}
1.1.3 任务(Task)
用于创建一个新任务并在当前线程上执行指定的代码块。
#pragma omp task firstprivate(a, b) shared(c)
{
// 任务执行的代码块,使用变量a和b,以及共享变量c
}
1.1.4 同步(Synchronize)
用于等待所有线程完成指定的任务。
#pragma omp for schedule(static, chunk_size) reduction(+:sum)
for (int i = 0; i < n; i++) {
// 循环体,使用变量i和sum
}
1.2 OpenMP常用的指令和函数
-
parallel:用于指定一个代码段,该代码段将在多个线程上并行执行。
-
for:用于for循环之前,将循环分配到多个线程中并行执行,必须保证每次循环之间无相关性。
-
parallel for:parallel 和 for语句的结合,也是用在一个for循环之前,表示for循环的代码将被多个线程并行执行。
-
sections:用在可能会被并行执行的代码段之前。
-
parallel sections:parallel和sections两个语句的结合。
-
critical:用在一段代码临界区之前。
-
single:用在一段只被单个线程执行的代码段之前,表示后面的代码段将被单线程执行。
-
flush:用来保证线程的内存临时视图和实际内存保持一致,即各个线程看到的共享变量是一致的。
-
barrier:用于并行区内代码的线程同步,所有线程执行到barrier时要停止,直到所有线程都执行到barrier时才继续往下执行。
-
atomic:用于指定一块内存区域被制动更新。
-
master:用于指定一段代码块由主线程执行。
-
ordered:用于指定并行区域的循环按顺序执行。
-
threadprivate:用于指定一个变量是线程私有的。
-
copyprivate:配合single指令,将指定线程的专有变量广播到并行域内其他线程的同名变量中;
-
copyin n:用来指定一个threadprivate类型的变量需要用主线程同名变量进行初始化;
-
default:用来指定并行域内的变量的使用方式,缺省是shared。
1.3 OpenMP常用库函数
OpenMP库函数是一组用于并行计算的函数,它们可以帮助程序员在C、C++和Fortran等编程语言中实现多线程编程。以下是一些常用的OpenMP库函数:
- omp_get_num_threads():返回正在执行的线程数。
- omp_get_max_threads():返回支持的最大线程数。
- omp_get_thread_num():返回当前线程的编号。
- omp_get_num_procs():返回正在执行的程序的处理器数。
- omp_set_num_threads():设置并行区域中的线程数。
- omp_get_nested():测试当前块是否嵌套在其他并行区域内。
- omp_set_nested():设置当前块允许嵌套在其他并行区域内。
- omp_get_schedule():获取指定并行区域的调度策略。
- omp_set_schedule():设置指定并行区域的调度策略。
- omp_get_chunk_size():获取指定并行区域的块大小。
- omp_set_chunk_size():设置指定并行区域的块大小。
- omp_barrier():在所有线程都到达该点时阻塞所有线程。
- omp_critical():创建一个临界区,确保同一时间只有一个线程可以执行该段代码。
- omp_atomic():对一个变量进行原子操作,确保多个线程对该变量的操作是有序的。
- omp_flush():将缓冲区中的数据立即写入共享内存或设备。
- omp_lock_t:用于同步的锁类型。
- omp_init_lock():初始化锁对象。
- omp_destroy_lock():销毁锁对象。
- omp_set_lock():对锁对象加锁。
- omp_unset_lock():对锁对象解锁。
2. 并行执行
OpenMP 提供了多种并行执行的方法,如 parallel for、parallel sections 等。这些方法使得开发者能够将代码块分配给多个线程执行,从而实现更高效的计算。通过合理地划分代码块和选择合适的并行执行方法,开发者可以显著提高程序的性能。
3. 线程管理
OpenMP 提供了一些指令和函数,如 num_threads、thread_bind 等,用于设置和控制并行区域中的线程数量和绑定策略。这些功能使得开发者能够更好地控制并行程序的执行流程,确保程序的正确性和稳定性。
4. 同步与通信
为了确保并行执行的正确性,OpenMP 提供了一些同步机制,如 barrier、critical、atomic 等。这些机制确保了线程之间的正确协作和数据一致性。此外,还提供了一些数据传输函数,如 reduction,用于实现线程之间的数据共享和计算结果的汇总。这些同步和通信机制是并行程序中必不可少的部分,它们确保了程序的正确性和可靠性。
5. 调度策略
OpenMP 支持多种调度策略,如静态调度、动态调度和运行时调度。这些调度策略允许开发者根据需要选择合适的调度策略来优化程序的性能。通过合理地选择调度策略,开发者可以更好地平衡线程的负载和利用系统资源,从而提高程序的执行效率。
三、OpenMP编程实战
1 Linux下编译选项
Linux下GCC编译器仅仅编译选项增加-fopenmp即可完成对OpenMP的支持。
2 C语言 OpenMP 并行化程序示例(包含<omp.h>)
#include <omp.h>
#include <stdio.h>
int main() {
#pragma omp parallel for
for (int i = 0; i < 10; i++) {
printf("Thread %d: %d\n", omp_get_thread_num(), i);
}
return 0;
}这个程序使用了 #pragma omp parallel for 指令将 for 循环进行并行化。在循环体内部,使用 omp_get_thread_num() 函数获取当前线程的编号,并打印出来。这个示例展示了 OpenMP 的基本用法和并行化效果,通过简单的修改和调整,你可以将其应用于更复杂的并行计算任务。
运行结果:

由于使用的电脑是八核的,因此,最多有八个线程,由上述的线程编号可以看出。
如果将上述的循环代码变成8个,如下:
#include <omp.h>
#include <stdio.h>
int main() {
#pragma omp parallel for
for (int i = 0; i < 8; i++) {
printf("Thread %d: %d\n", omp_get_thread_num(), i);
}
return 0;
}运行结果:
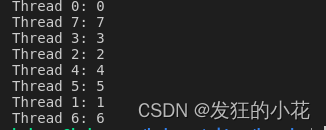
运行结果是八个线程,线程编号和循环编号相同。
3 C++ OpenMP并行编程示例(包含宏定义#ifdef _OPENMP)
#include <iostream>
#include <omp.h>
int main()
{
#ifdef _OPENMP // 如果定义了这个宏
std::cout << "Hello, OpenMP!" << std::endl;
#pragma omp parallel for
for (int i = 0;i < 8;i++)
{
printf("thread ID is %d i = %d\n",omp_get_thread_num(),i);
}
#else
std::cout << "OpenMP is not enabled." << std::endl;
#endif
return 0;
}运行结果:
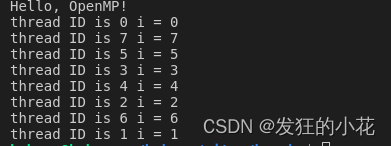
C++ OpenMP并行编程例子。-fopenmp编译选项开启后,_OPENMP宏被打开。
4 OpenMP 多线程性能对比
#include <stdlib.h>
#include <stdio.h>
#include "omp.h"
void test()
{
for (int i = 0; i < 80000; i++)
{
//执行代码
}
}
int main(int argc, char **argv)
{
#ifdef _OPENMP
printf("OpenMP is Enable!\n");
#else
printf("OpenMP is Disable!\n");
#endif
float startTime = omp_get_wtime();
//指定2个Thread
#pragma omp parallel for num_threads(2)
for (int i = 0; i < 80000; i++)
{
test();
}
float endTime = omp_get_wtime();
printf("2 个Thread,latency: %f\n", endTime - startTime);
startTime = endTime;
//指定4个Thread
#pragma omp parallel for num_threads(4)
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("4 个Thread,latency: %f\n", endTime - startTime);
startTime = endTime;
//指定8个Thread
#pragma omp parallel for num_threads(8)
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("8 个Thread,latency: %f\n", endTime - startTime);
startTime = endTime;
//指定12个Thread
#pragma omp parallel for num_threads(10)
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("10 个Thread,latency: %f\n", endTime - startTime);
startTime = endTime;
//不使用OpenMP
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("不使用OpenMP Mutil Thread,latency: %f\n", endTime - startTime);
startTime = endTime;
return 0;
}运行结果:

分析结果可知,随着线程数量的增加运行的时间减少,由于使用的电脑是八核的,因此并行只能同时有八个线程,使用十个线程的运行效率不增反减。
🌈我的分享也就到此结束啦🌈
如果我的分享也能对你有帮助,那就太好了!
若有不足,还请大家多多指正,我们一起学习交流!
📢未来的富豪们:点赞👍→收藏⭐→关注🔍,如果能评论下就太惊喜了!
感谢大家的观看和支持!最后,☺祝愿大家每天有钱赚!!!下一节将继续开展OpenMP编程更加详细的实战。