本质:
Attention机制的本质来自于人类视觉注意力机制。人们在看东西的时候一般不会从头看到尾全部都看,往往只会根据需求观察注意特定的一部分。简单来说,就是一种权重参数的分配机制,目标是协助模型捕捉重要信息。
原理:
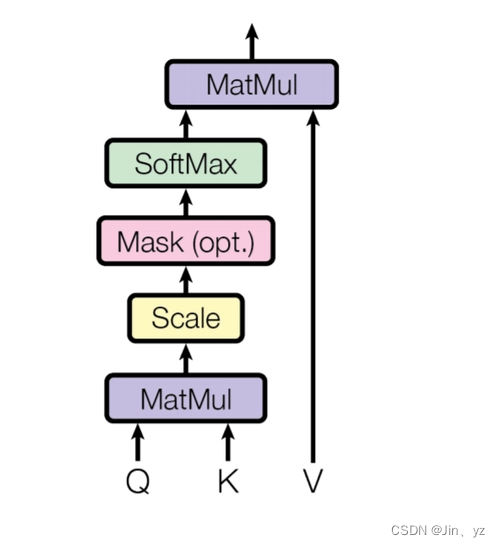
具体一点就是,给定一组<key,value>,以及一个目标(查询)向量query,attention机制就是通过计算query与每一组key的相似性,得到每个key的权重系数,再通过对value加权求和,得到最终attention数值。
作用:
Attention机制可以增强神经网络输入数据中某些部分的权重,同时减弱其他部分的权重,以此将网络的关注点聚焦于数据中最重要的一小部分。例如,在翻译任务中,Attention机制可以使模型集中于输入序列的相关部分。
优点:
Attention机制的引入主要有三个优点:
- 参数少:模型复杂度跟CNN、RNN相比,复杂度更小,参数也更少。
- 速度快:Attention解决了RNN不能并行计算的问题。Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。
- 效果好:Attention是挑重点,就算文本比较长,也能从中间抓住重点,不丢失重要的信息。
问题:
并行计算导致了丢失位序的问题
![[Linux] 一文理解HTTPS协议:什么是HTTPS协议、HTTPS协议如何加密数据、什么是CA证书(数字证书)...](https://img-blog.csdnimg.cn/img_convert/543dfa000d3648162ab5c79d1f022a07.webp?x-oss-process=image/format,png)


![[C#]C# OpenVINO部署yolov8-pose姿态估计模型](https://img-blog.csdnimg.cn/direct/d0c9b3cd324a47b8930bd360768b79ea.jpeg)