已经唠了三章的RAG,是时候回头反思一下,当前的RAG是解决幻觉的终点么?我给不出直接的答案,不过感觉当前把RAG当作传统搜索框架在大模型时代下的改良,这个思路的天花板高度有限~
反思来源于对RAG下模型回答的直观感受,最初我们被ChatGPT的能力所震惊,并不是它能背诵知识,而是模型在知识压缩后表现出的“涌现能力”,更具体到RAG所属的问答领域,是模型能够精准的基于上文从压缩的参数中召回并整合相应的知识,甚至进行知识外推的能力。通俗点说它有可能生成我在任何地方都检索不到的答案!
但RAG当前的多数使用方法,采用只让模型基于检索到的内容进行回答的方案,其实限制了模型自身对知识压缩形成的智能,大模型似乎变成了文本抽取和总结润色的工具。体验上大模型直接回答的效果就像是学霸答题文采四溢,而RAG有时倒像是学渣开卷考试,答得小心翼翼一有不慎还会抄错答案......
既要保证事实性,又要保留模型智能,则需要最大化的使用模型已经内化压缩到参数中的信息,只在需要使用外部知识增强的时候再进行工具调用。看到过以下几种方案
-
Detection:通过前置判断,决策模型何时需要使用外挂,在模型可以自行回答的时候,使用模型回答,当模型不能回答的时候走RAG检索生成
-
Realtime Data:需要获取动态世界的信息,部分场景可以通过意图进行决策,相对好解决
-
Incorrect or Incomplete:模型不知道,或者模型推理幻觉,如何知道模型可能不知道是更难解决的问题
-
Calibration:通过后置处理,让模型先生成,再使用召回内容对模型回答进行修正校准和事实性检查
-
两种方案勾兑一下:高置信度判断模型可以自行完成直接回答,中置信度先生成再校验,低置信度直接走RAG检索生成,或者通过意图和场景进行决策
如何勾兑就不在这里说了,这里我们聊聊基础的前置判断和后置处理分别有哪些方案~
前置判断-Detection
检测模型回答存在幻觉可以通过检索外部知识进行校验,不过考虑生成式模型覆盖问题的广泛性,Self-Contradictory论文中评估chatgpt生成的回答中38.5%的内容无法通过Wiki等外部知识进行校验。
因此这里我们先介绍一种完全基于模型自身,不依赖外部知识的幻觉判断方案自我矛盾。后介绍一种模型直接拒绝回答的方案,和RLHF里面的事实性原则类似,这里是基于SFT的模型自我拒绝方案,不过个人对拒识类的方案持一定的保留意见,但不妨碍学习新思路哈哈~~
自我矛盾
第一种发现模型幻觉的方案是基于模型多次回答的不一致性来判断模型是否在胡说八道。相似的概念在解密Prompt系列9. 模型复杂推理-思维链基础和进阶玩法里面聊Self-Consistency COT时就提到过,该论文是使用多路COT推理来投票出一个最合理的推理路径,从而提高思考的准确率。这里只不过改变了使用的形式,通过模型多次回答的不一致来判断模型是否出现了幻觉。有以下几种生成模型多次回答,并度量一致性的方案
单模型推理
SELFCHECKGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models
SELF-CONTRADICTORY HALLUCINATIONS OF LLMS: EVALUATION, DETECTION AND MITIGATION
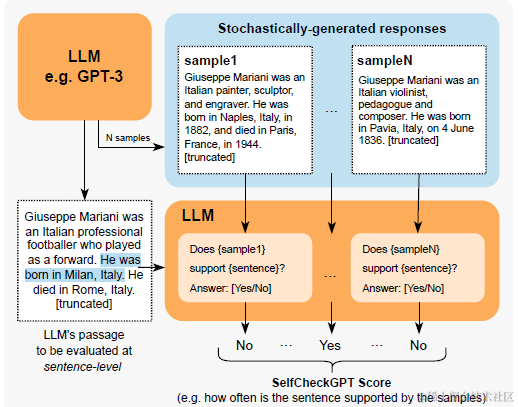
对于如何度量模型随机生成的多个回答之间的不一致性,Self-Check尝试了包括Bert相似度计算在内的5种方法,其中效果最好的两种分别是传统NLI和基于大模型prompt的NLI,从推理性价比上传统NLI有优势,效果上LLM更好,以下是使用不同相似度计算方案来衡量模型多次随机解码的不一致性,并用该指标来计算模型回答是否符合事实性的AUC效果
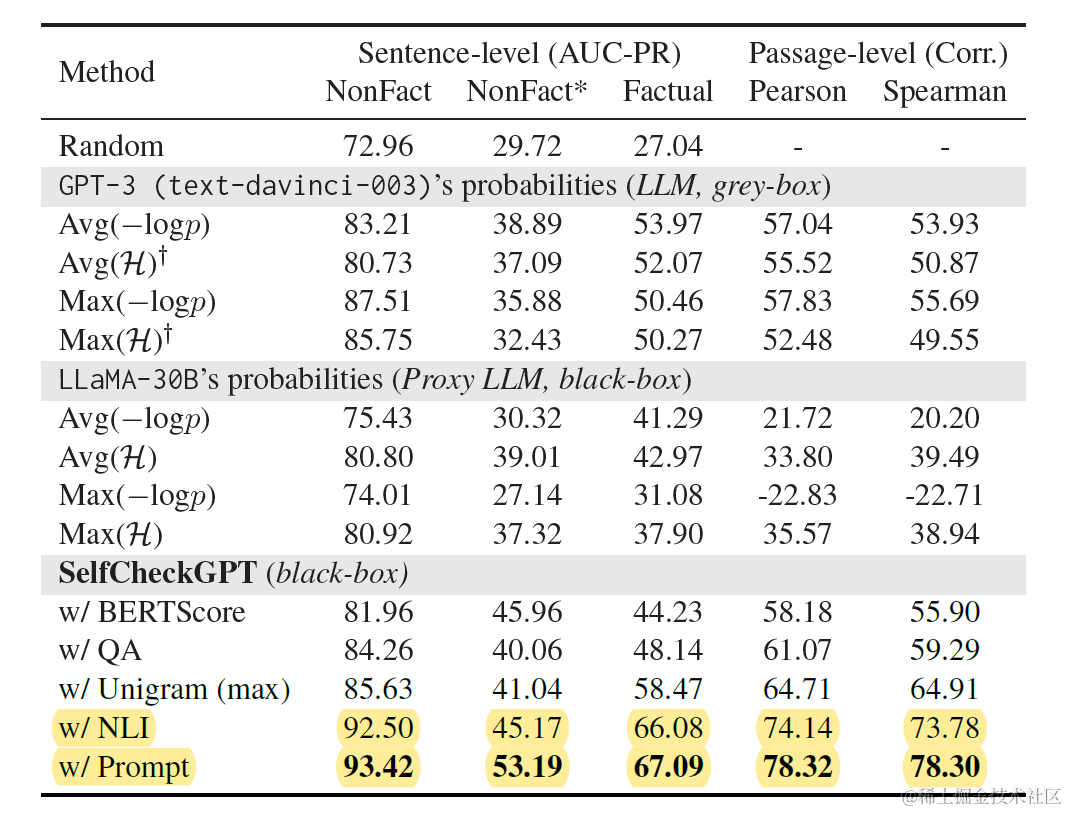
传统NLI推理任务,是给定前提(premise)判断假设(hypothesis)是否成立或者矛盾。这里论文就是使用MNLI数据训练的Debarta-v3-Large来判断模型生成的回答r(hypothesis),是否和其他N个采样生成的回答(premise)相矛盾。论文分别尝试了句子级的判断和整个回答粒度的判断,句子级别的效果显著更好。

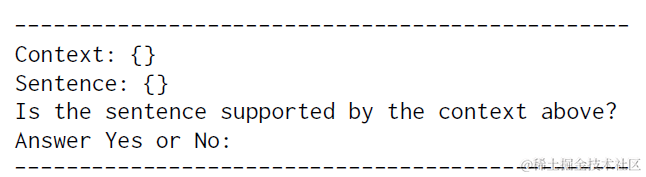
而基于大模型prompt,同样是NLI任务的思路,只不过改成了自然语言指令,以下context等同于以上的 Sn, sentence就是 ri, 大模型推理返回的Yes/NO会被转化成0/1,并计算均值。
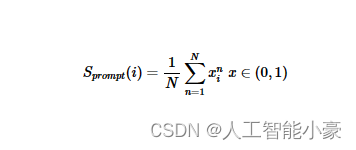
SELF-Contradictory的思路很相似,方法更加复杂些,感兴趣的朋友自己去看论文吧~
多模型问答
DeepMind LM vs LM: Detecting Factual Errors via Cross Examination
Improving Factuality and Reasoning in Language Models through Multiagent Debate
同样是自我矛盾的思路,还可以通过多模型对话的方式来进行。LM VS LM采用了模型B多次反复提问模型A的方式来生成多个回答。类似的方式也用于问卷中问题的设计,出题人会用不同的方式把一个问题问好几遍,如果每次回答都不一样,说明做题人对类似问题的回答是不确定的。如下图
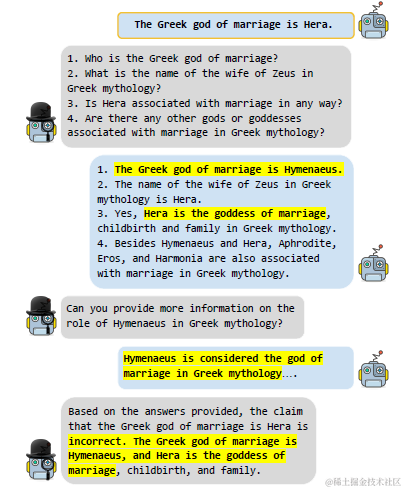
第一步模型A先生成回答(claim)。第二步模型B会针对cliam,从多个角度生成提问并让模型A再次进行回答。第三步模型B会基于A的原始回答,和对多个问题的回答来判断原始回答的正确性。以上B提问A回答的步骤,如果B判断需要进行补充提问的话,可能会重复多次。
这里涉及到的三个任务都是通过大模型指令来进行的,三个任务分别是:模型B基于A的cliam进行提问,模型B判断是否继续提问,模型B基于A的所有回答判断claim是否正确。对应的具体prompt如下

相比上面SELF-CHECK随机解码生成多个答案的方案,从多角度进行提问,个人感觉更有针对性,但两种方法都会有遗漏和误伤。推理成本上SELF-CHECK更低,LM vs LM更高。
自我拒绝
R-Tuning: Teaching Large Language Models to Refuse Unknown Questions
除了通过不一致性判断模型出现幻觉,另一种更干脆直接的方案,是让模型在碰到自己不确定的问题时,直接选择拒绝回答,和RLHF中的事实性原则的是一个思路。但我对这类方案最大的疑惑是拒识能力的泛化性。究竟模型是学到了对于自身parametric knowledge置信度较低,混淆度较高的问题进行拒绝回答,还是模型背下来了对某些知识和上文语义空间进行拒绝回答。这个我也还没想明白哈哈哈~
所以这里我们绕过这个问题,聊一种中间策略,毕竟西医好多疾病也没研究明白,但病还得治不是。R-Tunning提出指令微调可能放大了模型的回答幻觉。因为指令微调的数据集中所有问题都有答案,微调任务就是负责教会模型各种任务范式,以及在不同的任务中如何召回预训练中学习的知识并回答问题。但我们忽略了SFT中很多任务涉及到的知识在模型预训练中可能是没接触过的,但我们依旧选择让模型去进行回答。这种预训练和指令微调间的不一致性,可能会进一步放大模型幻觉。
R-Tunning给出的解决方案是在构建指令微调数据集时,加入模型是否对改答案表示肯定的描述,这样允许模型拒绝自己不确定的问题。分成2个步骤
-
找到模型不确定的问题,论文尝试了两种方案
-
R-Tuning:模型回答和标注答案不一致,适用于有标准答案的QA问题
-
R-Tuning-U:模型回答自我矛盾,这里论文计算模型回答包含的所有答案的熵值
-
构建允许模型拒绝的指令数据集,论文也尝试了以下两种prompt指令模板
-
R-Tuning:"Q:{Question},A:{Answer}.{Propmt}.",其中prompt是Are you sure you accurately answered the question based on your internal knowledge:对于上面模型确定的问题加上I am sure,不确定的问题加上I am not sure
-
R-Tuning-R: 对于确定给的问题使用"Q:{Question},A:{Answer}",对于不确定的问题用I am not sure 的各种相似表达来直接替换Answer
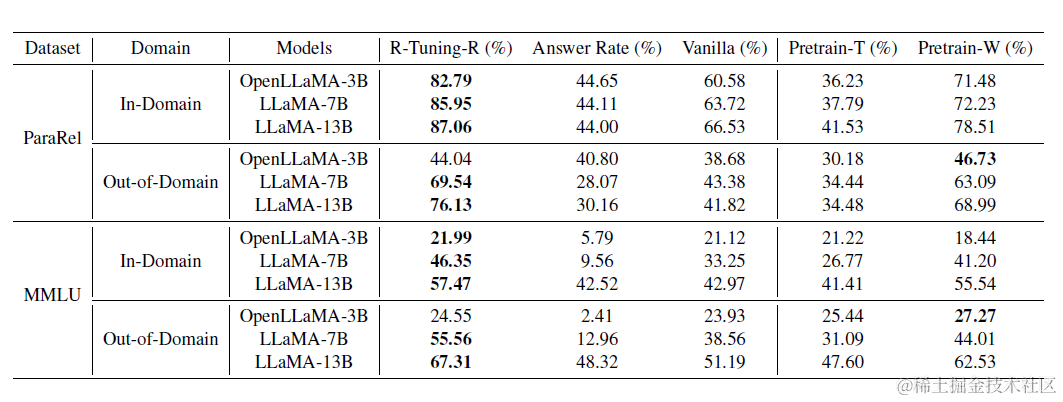
然后使用以上加入模型不确定性表达的数据集进行指令微调即可。在我们的使用场景中R-Tunning-R这种直接拒绝的方案更加合适,毕竟我倾向于指令微调的核心并不是知识注入,而是任务对齐,所以模型只要学习到对于自己不确定的问题选择拒绝回答即可。在论文验证的MMLU等数据集上这种拒绝微调方案有一定的领域外的泛化效果,不过这些数据集和我们的使用场景相差很大,具体效果要等测试后才知道了。