一. 内容简介
使用qtquick调用python程序
二. 软件环境
2.1vsCode
2.2Anaconda
version: conda 22.9.0
2.3pytorch
安装pytorch(http://t.csdnimg.cn/GVP23)
2.4QT 5.14.1
新版QT6.4,,6.5在线安装经常失败,而5.9版本又无法编译64位程序,所以就采用5.14.1这个用的比较多也比较稳定的一个版本。
QT编译器采用的是MSVC2017 64bit。
链接:https://pan.baidu.com/s/1ER98DPAkTUPlIyCC6osNNQ?pwd=1234
三.主要流程
3.1 qml中调用c++程序
qml里面不能直接调用python,有那个调命令行然后执行py文件的,我感觉很奇怪,就没用那种方式,就采用c++调用python程序。
首先创建一个c++类,基于QObject对象,名字随便起,我用的是mopsopy,

完成以后,可以直接在我的模板上面改,就是需要在类的成员上加一些声明,让qml认识,但是变量的那个可以用alt加enter加出来,我的没有那个选项,你们可以直接用用我的模板
头文件
#ifndef MOPSOPY_H
#define MOPSOPY_H
#include <QObject>
#include <QDate>
#include <QtQml>
#include <QDebug>
class MopsoPy : public QObject
{
Q_OBJECT
// 用于qml内部识别
Q_PROPERTY(QString name READ getName WRITE setName NOTIFY nameChanged)
public:
explicit MopsoPy(QObject *parent = nullptr);
~MopsoPy();
QString getName() const;
void setName(const QString &name);
Q_INVOKABLE void func();
signals:
void nameChanged(QString name);
public slots:
private:
QString name;
};
#endif // MOPSOPY_H
cpp文件
#include "mopsopy.h"
MopsoPy::MopsoPy(QObject *parent) : QObject(parent)
{
}
MopsoPy::~MopsoPy()
{
}
QString MopsoPy::getName() const
{
return name;
}
void MopsoPy::setName(const QString &name)
{
if (this->name == name)
return;
this->name = name;
emit nameChanged(this->name);
}
void MopsoPy::func()
{
}
完事后,要在main.cpp中注册一下,头文件别忘记了加
#include "mopsopy.h"
qmlRegisterType<MopsoPy>("MopsoPy", 1, 0, "MopsoPy");
qml文件中使用,测试代码自己写吧
import MopsoPy 1.0
MopsoPy{
id: mopsoPy;
name: "jjjj"
Component.onCompleted: {
mopsoPy.func()
}
}
3.2 c++调用python
首先,添加库的地址,换成自己的
INCLUDEPATH+=D:\Anaconda3\include #pythonenviroment
LIBS+=-LD:\Anaconda3\libs
-l_tkinter
-lpython3
-lpython39
qt里面创建python文件,
import numpy as np
def add(a,b):
# 创建日志文件
fileLog = open("log.txt", "w")
arr1 = np.array([1, 2, 3, 4, 5])
# 写入日志
fileLog.write(np.array2string(arr1))
# 写入日志
fileLog.write("写入完成")
# 关闭文件
fileLog.close()
return a+b
c++方法实现
头文件
// 不加会关键字重复,报错
#undef slots
#include <Python.h>
#define slots Q_SLOTS
cpp文件这么写
void MopsoPy::func()
{
// 新建一个元组,用来存放函数参数的值
if( !Py_IsInitialized()){ Py_Initialize();}
// 导入 Python 模块
PyObject* pModule = PyImport_ImportModule("ccc");
// 获取模块中的函数对象
PyObject* pFunc = PyObject_GetAttrString(pModule, "add");
// 创建参数元组
PyObject* pArgs = PyTuple_New(2);
int num1 = 42;
int num2 = 13;
// 这个i对应不同的数据格式
PyObject* arg1 = Py_BuildValue("i", num1);
PyObject* arg2 = Py_BuildValue("i", num2);
PyTuple_SetItem(pArgs, 0, arg1);
PyTuple_SetItem(pArgs, 1, arg2);
// 调用函数并获取返回值
PyObject* pResult = PyObject_CallObject(pFunc, pArgs);
// 解析返回值
double result;
PyArg_Parse(pResult, "d", &result);
// 打印结果
printf("Result: %f\n", result);
// 释放资源
Py_DECREF(pModule);
Py_DECREF(pFunc);
Py_DECREF(pArgs);
Py_DECREF(pResult);
Py_Finalize();
}
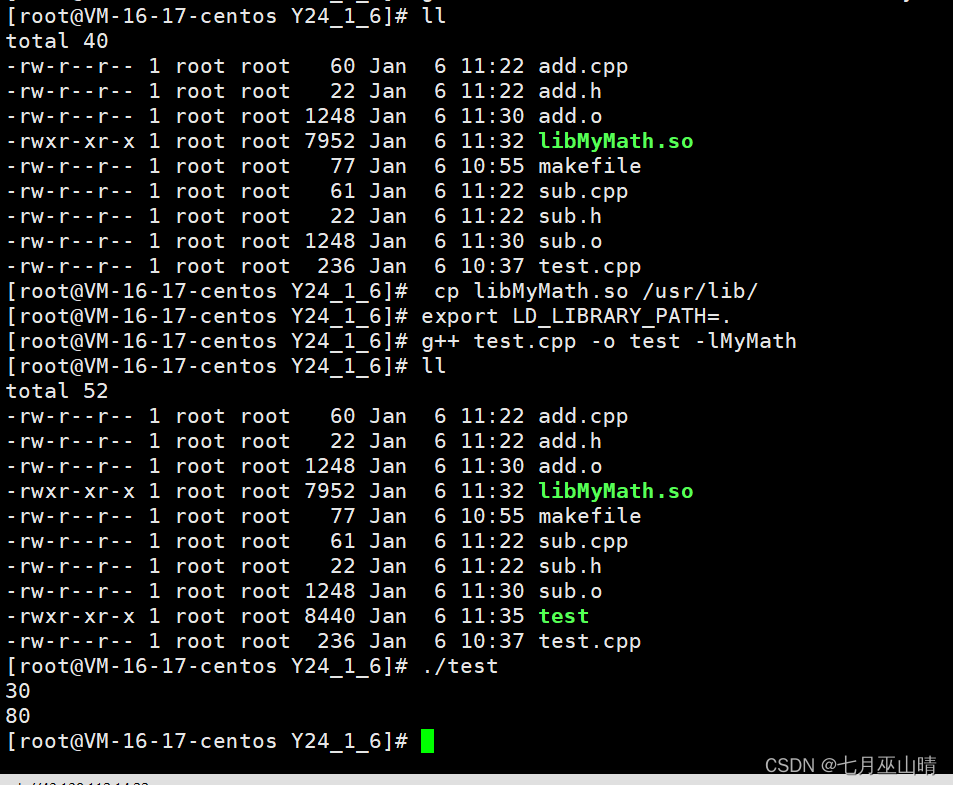
最后把文件放到要执行的文件里面,不然会报找不到文件的,放到release里面就行(我用多个release编译的),我外面也扔了一个,
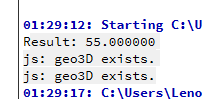
 结果,另外两个不用管,是我的其他模块出的。
结果,另外两个不用管,是我的其他模块出的。
3.3 调用复杂的python程序,读取神经网络
神经网络的模型保存以及读取
# 保存神经网络,这个只是保存训练的参数的
torch.save(model,'angelminLoss.pkl')
# 神经网络的结构,因为读取只是读取参数,
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
# 这个是有wx+b
self.linear1 = torch.nn.Linear(2, 56)
self.linear2 = torch.nn.Linear(56, 56)
self.linear3 = torch.nn.Linear(56, 56)
self.linear4 = torch.nn.Linear(56, 28)
self.linear5 = torch.nn.Linear(28, 14)
self.linear6 = torch.nn.Linear(14, 4)
self.linear7 = torch.nn.Linear(4, 1)
self.ReLU = torch.nn.ReLU() # 将其看作是网络的一层,而不是简单的函数使用
self.Sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.ReLU(self.linear1(x))
x = self.ReLU(self.linear2(x))
x = self.ReLU(self.linear3(x))
x = self.ReLU(self.linear4(x))
x = self.ReLU(self.linear5(x))
x = self.ReLU(self.linear6(x))
x = self.linear7(x)
return x
# 读取神经网络参数,没有结构
model = torch.load('angelminLoss.pkl')
下面是测试的py文件test.py,
import numpy as np
import torch
import matplotlib.pyplot as plt
from IPython import display
from d2l import torch as d2l
import os
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
# 这个是有wx+b
self.linear1 = torch.nn.Linear(5, 56)
self.linear2 = torch.nn.Linear(56, 56)
self.linear3 = torch.nn.Linear(56, 56)
self.linear4 = torch.nn.Linear(56, 28)
self.linear5 = torch.nn.Linear(28, 14)
self.linear6 = torch.nn.Linear(14, 5)
self.linear7 = torch.nn.Linear(5, 1)
self.ReLU = torch.nn.ReLU() # 将其看作是网络的一层,而不是简单的函数使用
self.Sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.ReLU(self.linear1(x))
x = self.ReLU(self.linear2(x))
x = self.ReLU(self.linear3(x))
x = self.ReLU(self.linear4(x))
x = self.ReLU(self.linear5(x))
x = self.ReLU(self.linear6(x))
x = self.linear7(x)
return x
def init():
model = Model()
modelFF = torch.load("hminLoss.pkl")
print("success_1")
if __name__ == "__main__":
model = Model()
modelFF = torch.load("hminLoss.pkl")
print("success_2")
可以看到运行没有问题的,单独运行test.py

但是现在存在一个问题,当调用当前文件时候,qt里面会报这个错,如果没有报错的,直接闪退的话,可以让他打印错误信息
// 新建一个元组,用来存放函数参数的值
if( !Py_IsInitialized()){ Py_Initialize();}
// 导入包含你的 Python 类的模块
PyObject* pModule = PyImport_ImportModule("ccc");
PyErr_Print(); // 打印 Python 异常信息
// 获取模块中的函数对象
PyObject* pFunc = PyObject_GetAttrString(pModule, "init");
PyErr_Print(); // 打印 Python 异常信息
// 创建参数元组
PyObject* pArgs = PyTuple_New(0);
// int num1 = 42;
// int num2 = 13;
// PyObject* arg1 = Py_BuildValue("i", num1);
// PyObject* arg2 = Py_BuildValue("i", num2);
// PyTuple_SetItem(pArgs, 0, arg1);
// PyTuple_SetItem(pArgs, 1, arg2);
// 调用函数并获取返回值
PyObject* pResult = PyObject_CallObject(pFunc, pArgs);
// 释放资源
PyErr_Print(); // 打印 Python 异常信息
// 解析返回值
double result;
PyArg_Parse(pResult, "d", &result);
// 打印结果
printf("Result: %f\n", result);
// 释放资源
PyErr_Print(); // 打印 Python 异常信息
Py_Finalize();

AttributeError: Can’t get attribute ‘Model’ on <module ‘main’ (built-in)>在我们自己单独运行时候是没有报错的。
当我们把文件改成这样,就会报相同的错误,就是torch.load(“hminLoss.pkl”)在导入参数时候,他是没有得到神经网络的结构了,所以报错。我一开始以为是我们c++调用python时候,只会运行导入的函数,没有执行那个Model类,所以会报错,其实不是的,因为在用numpy时候,import导入以后下下面可以直接用,而且上面Model类也可以实例出对象,这就说明其实网络结构应该是有的,但是他拿不到,在调用时候会把import和类这些先运行一下的。
import numpy as np
import torch
import matplotlib.pyplot as plt
from IPython import display
from d2l import torch as d2l
import os
def init():
model = Model()
modelFF = torch.load("hminLoss.pkl")
print("success_1")
if __name__ == "__main__":
model = Model()
modelFF = torch.load("hminLoss.pkl")
print("success_2")
后来我就把网格结构单独放在一个py文件,作为一个模块导入进去,也还是这个问题,单独文件运行都没报错,作为模块导入就会报错,就发现其实PyObject_GetAttrString(pModule, “init”),他其实和import init from pModule是一样的,知道这点以后,我们将其当成一个模块,在其他py文件导入,报错如下

# 如果当前执行的是这文件的话,就有__name__= "__main__,
# 我们看报错信息 Can't get attribute 'Model' on <module '__main__' from,里面有一个__mian__
# 就是在当前文件中声明类Model时候,会往__main__中挂载一些信息,然后torch.load会去__main__里面拿,在当前文件中运行的话,都是可以获取到的
# 所以不会报错,但是作为模块导入时候,__main__其实已经变了,当前文件中__main__是没有网络结构信息的,他又不能去导入模块的__main__
# 去拿,所以就会报错,没有网络结构,PyObject_GetAttrString(pModule, "init"),他其实和import init from pModule一样,所以他就会报
# Can't get attribute 'Model' on <module '__main__'
if __name__ == "__main__":
init()
model = Model()
modelFF = torch.load("hminLoss.pkl")
print("success_2")
解决办法就是,把整个网络参数以及结构全部保存
import numpy as np
import matplotlib.pyplot as plt
from IPython import display
from d2l import torch as d2l
import random
import numpy as np
import torch
import matplotlib.pyplot as plt
from IPython import display
from d2l import torch as d2
# 在保存模型时,将模型转化为脚本并保存,整个网络参数以及结构全部保存
model = torch.load('angelminLoss.pkl')
scripted_model = torch.jit.script(model)
torch.jit.save(scripted_model, 'angelminLoss_scripted.pkl')
读取模型
model = torch.jit.load('angelminLoss_scripted.pkl')
这样就可以正常读取了
四.参考
https://blog.51cto.com/wangjichuan/5691185(Qt调用Python详细过程)