场景:
项目上需要将mysql表中数据迁移到clickhouse。
理论:
借助MaterializeMySQL

说明:
首先该方案实施需要启动mysql的binlog配置否则同步不了,尽管MaterializeMySQL官方说是在实验阶段,不应该在生产上使用,但是我们借助他来迁移一下历史数据,还是很好用的。
方案:
第一步:首先开启mysql的binLog配置,及clickhouse-server开启物化MaterializeMySQL
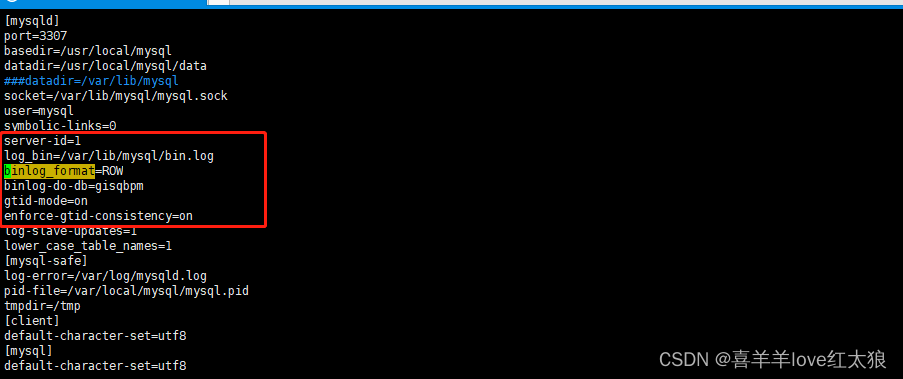
在/etc/clickhouse-server下users.xml中开启MaterializeMySQL

<allow_experimental_database_materialized_mysql>1</allow_experimental_database_materialized_mysql>
第二步:借助官方同步命令进行迁移
create database gisqbpm1 ENGINE = MaterializeMySQL('192.168.85.128:3307', 'gisqbpm', 'root', 'wxy123456');
注意:这里还没有结束,因为生产中不能使用MaterializeMySQL!!!且mysql还开着binlog影响性能呢!!!
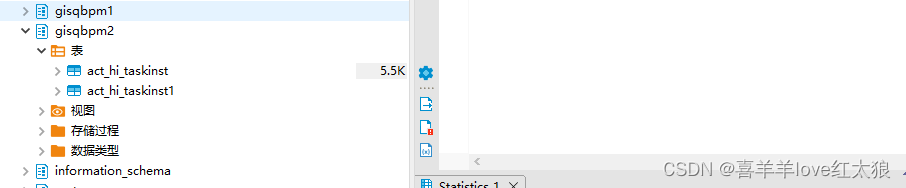
第三步:建立生产环境中的表
create table gisqbpm2.act_hi_taskinst1 ENGINE = ReplacingMergeTree() primary key ID_ as select * from gisqbpm1.act_hi_taskinst aht ;
注:gisqbpm2是我生产中实际要用的模式,gisqbpm1 只是一个桥梁作用
create table gisqbpm2.act_hi_taskinst1 ENGINE = MergeTree() primary key ID_ as select * from gisqbpm1.act_hi_taskinst aht ;
说明:这里需要什么表引擎就可以建立对应的表引擎十分方便,其他的就和mysql建立复制表语法一样了!!这样就可以了,只是麻烦一点需要把所有表名列出来执行一下复制语句!!
含表结构和数据
use database gisqbpm2;
create table gisqbpm2.act_hi_taskinst1 ENGINE = ReplacingMergeTree() primary key ID_ as select * from gisqbpm1.act_hi_taskinst aht ;
create table gisqbpm2.act_hi_taskinst ENGINE =MergeTree() primary key ID_ as select * from gisqbpm1.act_hi_taskinst aht ;只含表结构
use database gisqbpm2;
create table gisqbpm2.act_hi_taskinst1 ENGINE = ReplacingMergeTree() primary key ID_ as select * from gisqbpm1.act_hi_taskinst aht where 1=2 ;
create table gisqbpm2.act_hi_taskinst ENGINE =MergeTree() primary key ID_ as select * from gisqbpm1.act_hi_taskinst aht where 1=2;
第四步:生产环境中关闭binlog的同步配置及clickhouse的配置,删除在clickhouse中建立的中间桥梁库