文章目录
- 一、背景
- 二、方法
- 2.1 网络设计策略
- 2.2 Partial Residual Networks
- 2.3 Cross Stage Partial Networks
- 2.4 Efficient Layer Aggregation Network
- 三、效果
论文:Designing Network Design Strategies Through Gradient Path Analysis
代码:暂无
出处:暂无
一、背景
现有网络结构设计的不同方向:
- 实际应用的高效性上:
- SENet:使用通道 attention 的方式,降低了 AlexNet 约 50 倍参数,但可以保持类似的效果
- MobileNet 和 ShuffleNet:MobileNet 将硬件的延迟直接考虑到了网络设计中,ShuffleNet 分析了硬件的特性并作为网络设计的参考原则
- 超深网络结构及不同层特征的融合上:
- ResNet、ResNeXt、DenseNet 等结构解决了超深网络结构训练的模型收敛问题
- 之后的其他模型从 ① 特征融合 ② 提高感受野 ③ attention ④ 分支选择等方面来进行研究
总结上述内容可以得到下面的结论:
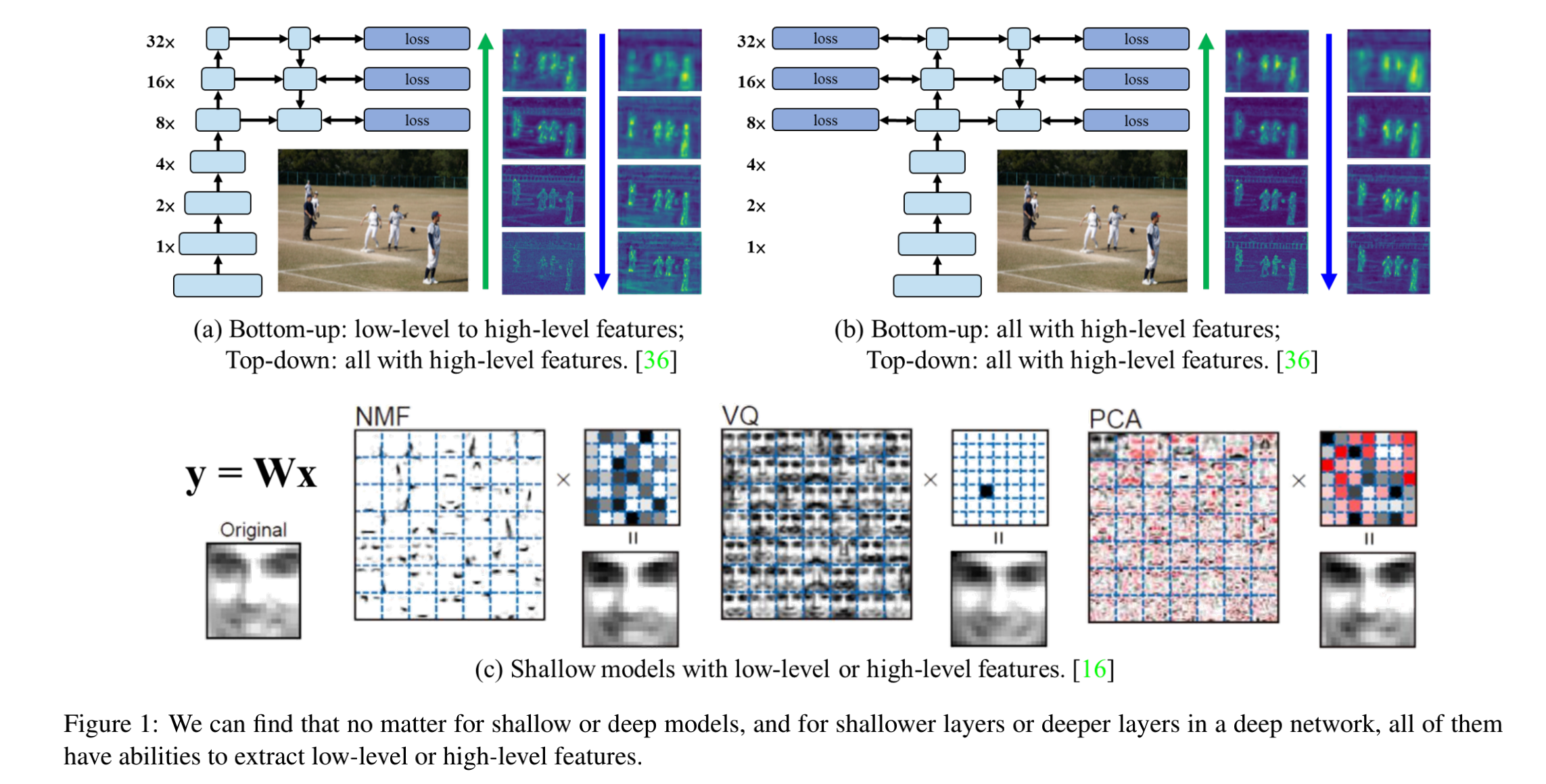
- 很多研究都是从相同的角度出发的,也就是从浅层抽取 low-level 特征,从深层抽取 high-level 特征,然后将这些特征结合起来,即是 data path(前向传播)的角度
本文作者的思考:
- 如图 1 所示,[16] 和 [36] 中,在 objective 和 loss 的角度分析了浅层和层模型,作者发现通过调整 objective 和 loss layer 的配置,就可以控制每层学习到的特征(无论浅层还是深层)。
- 也就是说,网络学习到什么类型的特征取决于训练人员用什么信息投喂,而不是如何组合这些层,基于此,作者重新设计的网络结构
本文作者的出发点:
- 由于目前的参数更新方法都是反向传播规则,即目标函数会根据梯度来更新权重参数,所以本文是基于梯度传播路径来设计网络结构
本文的做法:为 layer-level、stage-level、network-level 设计了梯度路径:
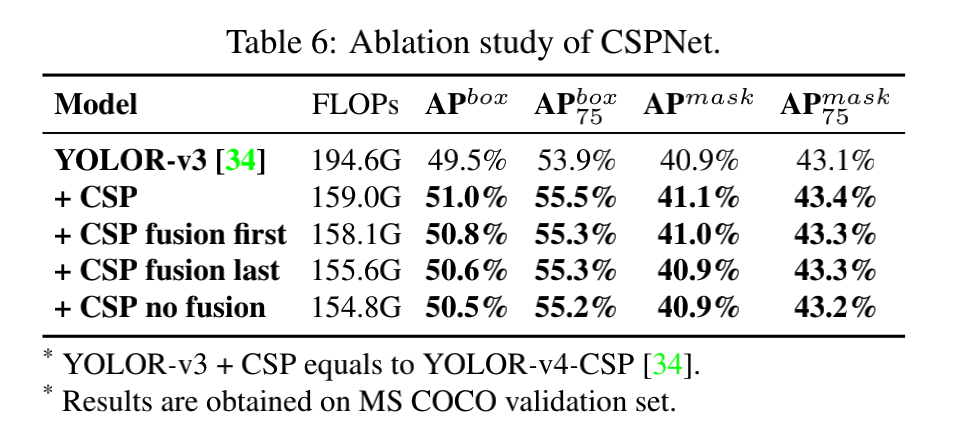
- Layer-level design:设计了梯度分流策略,并通过调整 layers 的数量和计算残差连接的 channel ratio,设计了 Partial Residual Network(PRN)(PRN 和本文是相同的作者团队)
- Stage-level design:将硬件的特性引入网络结构中来加速网络的推理过程。作者通过最大化梯度结合和最小化硬件消耗的两个方式,设计了 Cross Stage Network(CSPNet)[33] (CSPNet 和本文是相同的作者团队)
- Network-level design:作者考虑了梯度传播的效率来平衡网络的学习能力,以网络的梯度反传路径长度作为总基础,设计了 Efficient Layer Aggregation Network(ELAN)
二、方法
2.1 网络设计策略
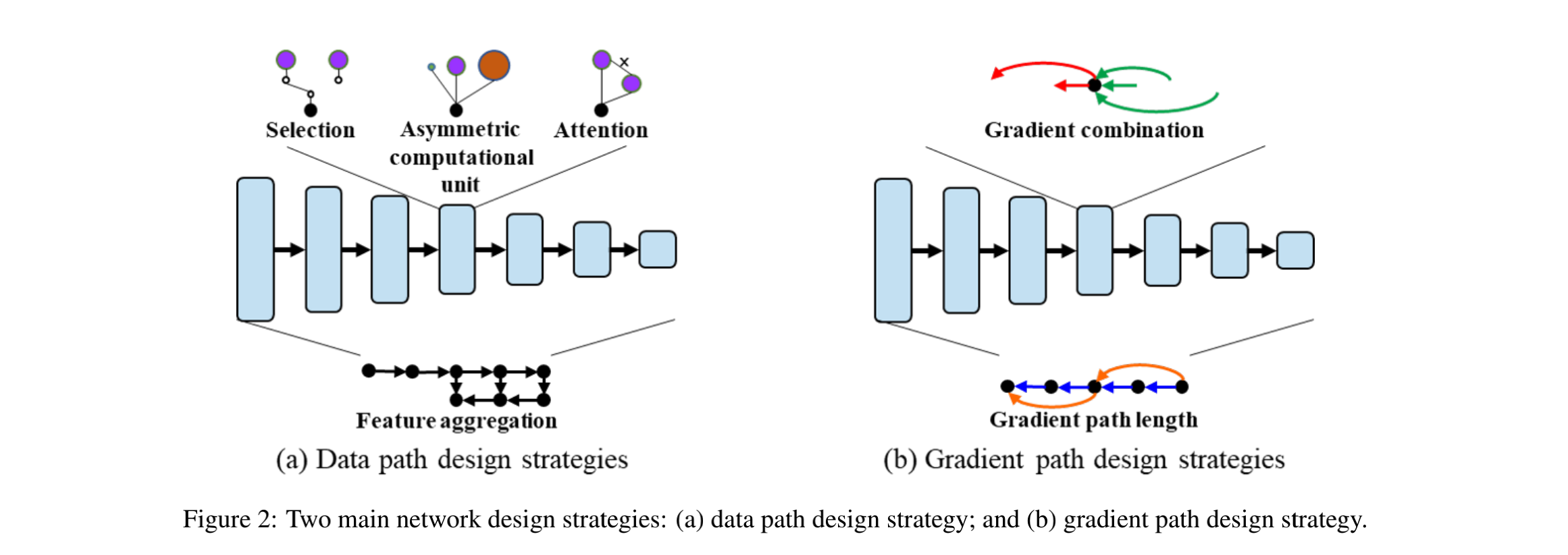
在本文中,作者将网络设计策略分为两种,如图 2 所示:
- data path design strategies:主要关注特征抽取方式、特征选择、特征融合方式等的设计
- gradient path design strategies:主要通过分析梯度的来源、组合方式、更新方式等,来进行网络设计,提高参数使用率,获得更好的效果
1、data path design strategy
优势:
- 可以提取有特殊物理含义的特征,比如使用对称计算单元来抽取不同感受野的特征
- 可以针对不同的输入来自动地选择合适的操作单元,比如使用不同的 kernel 来解决不同的输入 [2, 19]
- 学习到的特征可以直接复用,比如 FPN 可以直接使用从不同层得到的特征
劣势:
- 在训练过程中,容易导致无法预测的损失,所以需要复杂的结构来解决这些问题
- 多样且具有特殊设计的算术单元在模型优化过程中会造成一些困难
2、gradient path design strategy
优势:
- 能够高效地使用网络参数,通过调整梯度传播的路径,不同计算单元的权重可以学习更丰富的信息,提高性能
- 模型学习很稳定,由于梯度传输路径会直接影响每个计算单元的参数的更新,训练过程中可以避免性能损坏
- 前向传播效率更高,通过控制梯度传输的路径,模型可以在不增加其他复杂结构的基础上得到高准确率。
2.2 Partial Residual Networks
PRN 是本文作者团队在 2019 年提出的,属于 layer-level 的设计策略
在 PRN 的设计中,主要是围绕着如何最大化梯度的组合来更新每层的权重
下面两个因素会主要影响梯度的组合:
- 梯度的来源层 source layer of the gradient
- 梯度从 loss 层传递到其他层的时间戳(链路法则)
以 ResNet 为例来分析 Masked residual layer:
- ResNet 中,每个 block 的输出都会和残差连接的特征相加
- 在 PRN 的设计中,使用 binary mask 和残差连接相乘,只允许一部分通道的残差信息和 block 输出相加,如图 3 所示
- 使用 masked residual layer 可以让特征图分为两部分,通过抑制另一半通道,只有一半的残差通道会和 block 输入通道相加,这样可以提高梯度结合的数量
- 此外,不同的梯度 source 层会影响整个梯度传播的时间,让梯度的结合冗余

以 ResNet 来分析 Asymmetric(非对称) residual layer:
- 在 ResNet 的结构下,只有大小相同的特征图可以详见,这也也导致该结构是一个比较受限制的结构
- 在使用 PRN 时,可以允许一些 channels 被抑制,通道抑制的数量也可以不同,可以看做非对称残差层,这样就可以让网络更灵活
梯度结合(gradient combination)的一些分析:
一般研究中通常使用『最短梯度路径』和『融合特征的数量』来衡量模型的学习效率和网络结构的能力,[39] 在任务,这些度量方式和 accuracy 及 参数 没有很强的关系,如表 1 所示。
作者认为梯度传播和梯度结合是被用来更新参数的,和网络相关性更大,所以下面会进行「梯度结合」的相关分析。
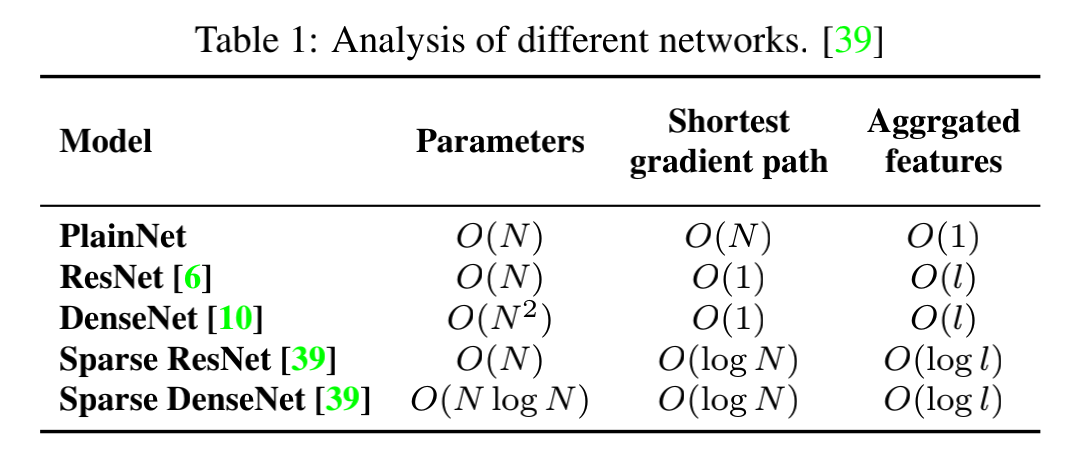
梯度结合包括:gradient timestamp 和 gradient source
1、gradient timestamp
如图 7,展示了四种不同的网络结构的 gradient timestamp
- ResNet 使用残差的方式,梯度结合方式比较受限
- PRN 使用 channel splitting 的方式,丰富了 gradient timestamp,和 ResNet 相比,梯度结合方式更多样
- SparseNet 使用 sparse connection 让不同的 layer 更灵活
- DenseNet 使用逐层 concat 的方式,梯度结合很冗余
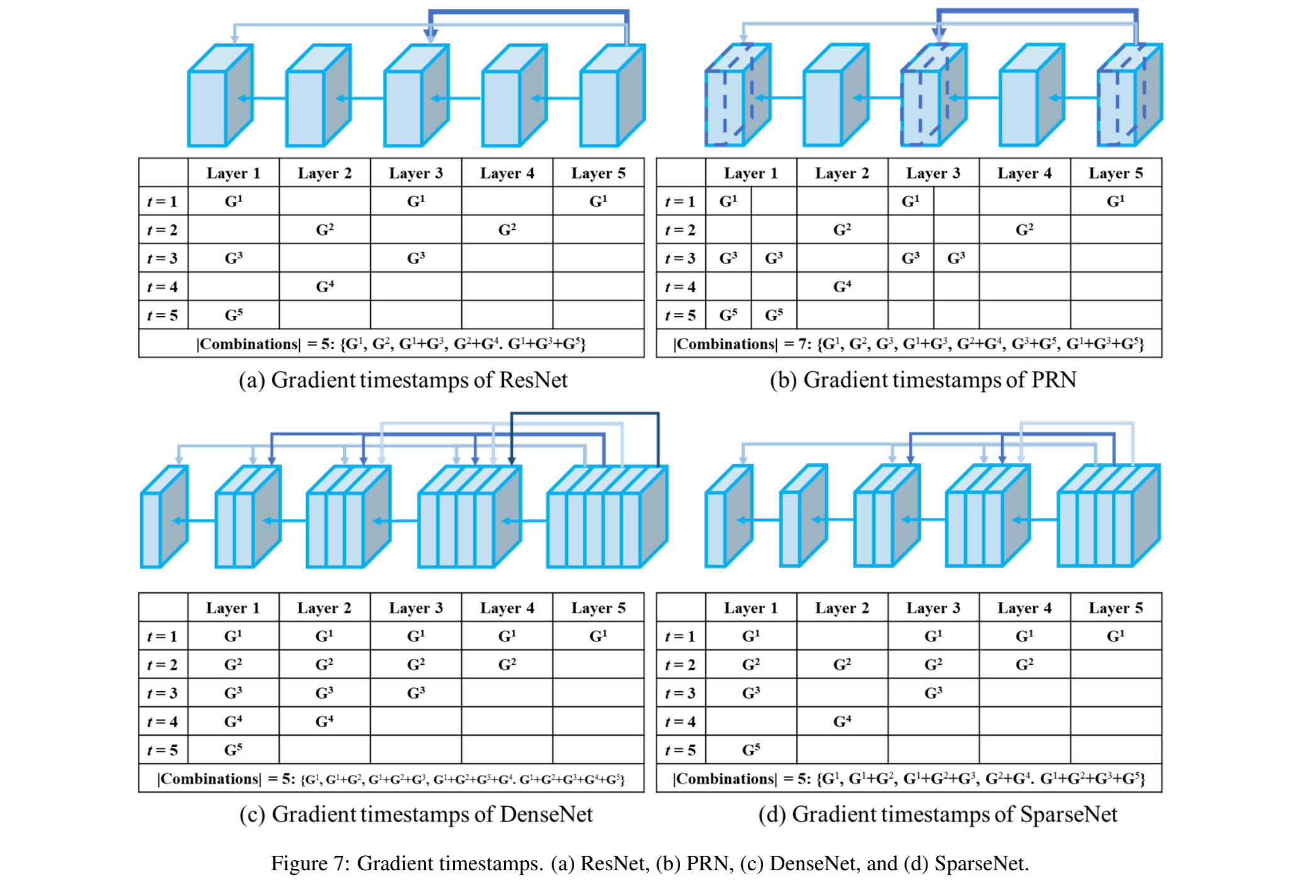
2、gradient source
如图 8 所示,展示了 3 种不同网络在第一个 gradient timestamp 处的 gradient source:
- 级联结构(DenseNet、SparseNet),需要特殊处理
- 残差结构(ResNet、PRN),ResNet 相同的梯度信息会传输到输出的所有层,source 有冗余,PRN 更灵活
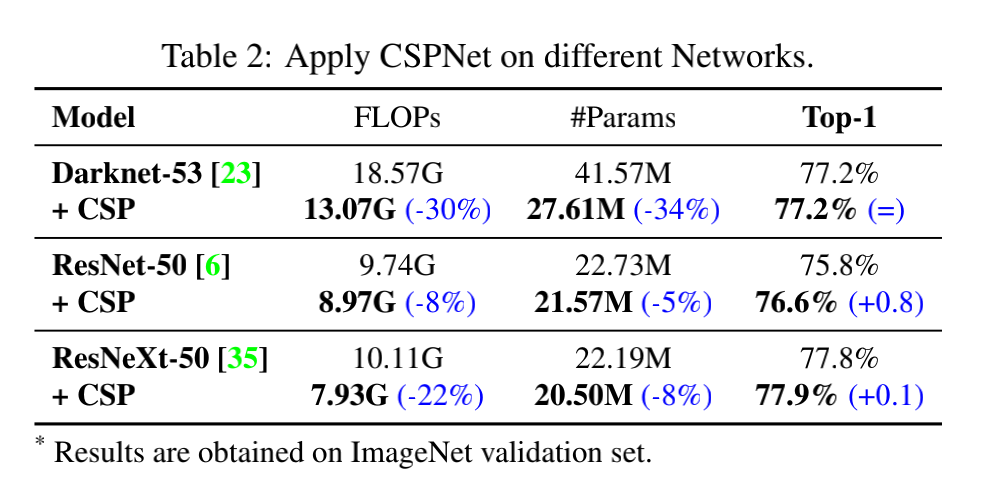
2.3 Cross Stage Partial Networks
CSPNet 也是本文团队在 2019 年提出的,可以看做 stage-level 梯度网络
CSPNet 也是基于最大化梯度组合来实现的
CSPNet 和 PRN 的不同:
- CSPNet:是为提升硬件推理速度来设计的
- PRN:是从理论角度出发并通过梯度的结合来提升网络的学习能力
所以,在 CSPNet 设计的时候,是从 layer-level 扩展到了 stage-level
CSPNet 的结构如下:
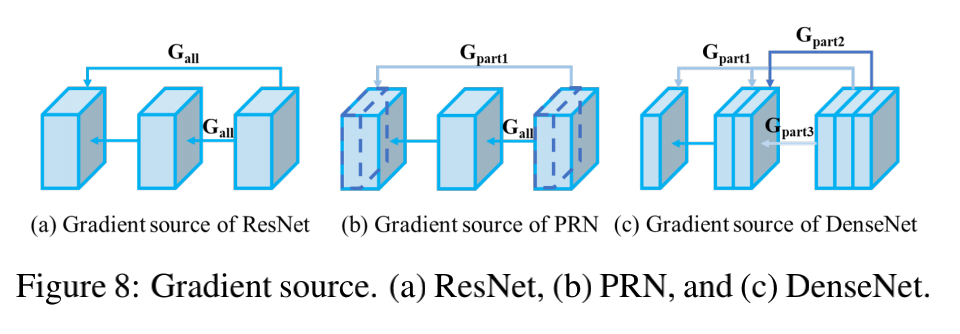
1、Cross stage partial operation
当每个 channel 都有不同的梯度传播路径的时候,可以达到 the source of gradient 的最大化
当每个 channel 都不同的计算深度的时候,梯度时间戳的数量可以最大化
所以,可以通过上面的两个理论来设计结构,最大化 gradient source 和 gradient timestamp
划分 channel 可以提高 gradient source,让子网络和不同 layer 的不同 channel 结合可以提高 gradient timestamps 的数量
结构如图 4 所示:
- 将输入划分为两部分,一部分经过 block ,一部分直接和 block 的输出特征进行进行 concat 即可
- 如此一来,可以降低计算量,提升网络推理速度
2、Gradient flow truncate operation
作者分析了 CSPNet 的梯度流传播
由于 block 中用了很多残差连接,特征流和残差流的梯度有很多重复的,所以作者在 block 和残差连接的末尾都插入了 transition layer,来截断一些梯度。
图 5 展示了 3 种不同的结合方式:
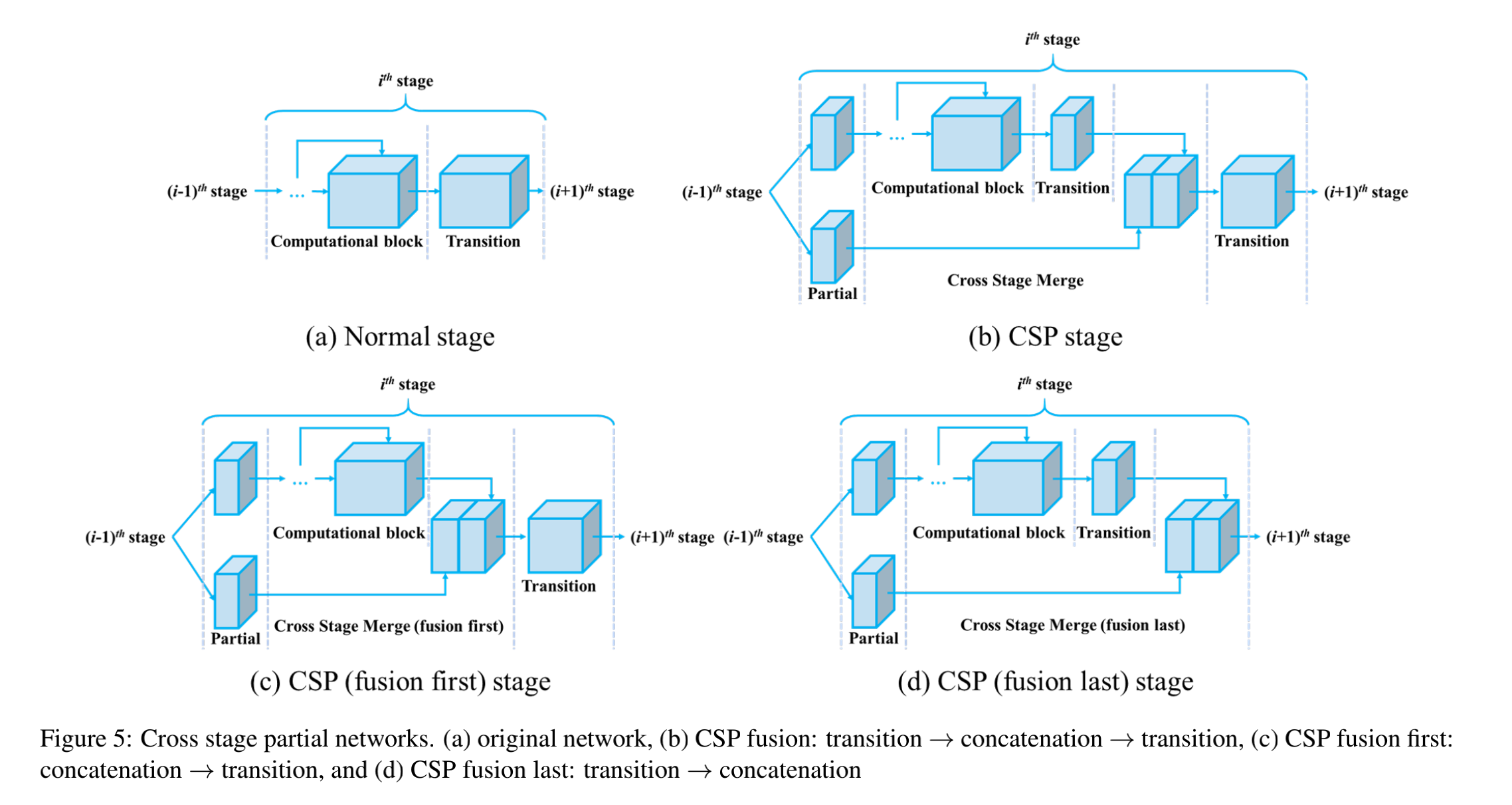
CSPNet 设计之初是为了加强模型在线学习的能力,并且加速推理。
2.4 Efficient Layer Aggregation Network
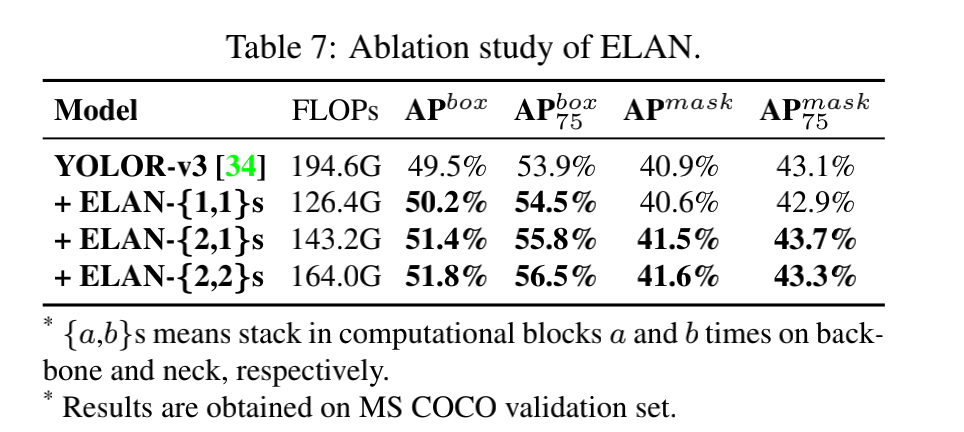
ELAN 代码在 2022 年 7 月开源,在 layer-level 上设计了 gradient path designed network。
ELAN 的主要目标是为了解决 deep model scaling 时难以收敛的问题
ELAN 是由 VoVNet 和 CSPNet 结合而来的,且其整个网络的梯度长度的优化是基于 Stack in computational block 结构的
Stack in computational block:
在做模型缩放时,如果网络达到了一定的深度,再叠加深度时,网络的效果可能会不升反降
举个例子:
- scaled-YOLOv4,P7 model 使用很多操作和参数,但只获得了很小的性能提升
- ResNet-152 约是 ResNet-50 参数量的 3 倍,但在 ImageNet 只带了了 1% 的 acc 提升,当 ResNet 堆叠到大约 200 层时,性能比 ResNet-152 更差
- VoVNet 堆叠到 99 层时,其 acc 比 VoVNet-39 还低
分析:
- 从梯度路径的设计来看,作者认为随着堆叠层数的增加, VoVNet 比 ResNet 的性能下降更多的原因在于,VoVNet 是基于 OSA module 堆叠而来,而每个 OSA module 都包括一个 transition layer,所以每堆叠一个 OSA module,每个层的梯度路径都会增加 1
- 而 ResNet 是基于 residual layers 堆叠而来的,每堆叠一个 residual layer,只会增加梯度最长路径
为了进一步分析,作者基于 YOLOR-CSP 进行了一些实验,并且发现:
- 当堆叠层数达到 80+ 时, CSP 早融合的方式比 normal CSP 效果更好,每个 stage 的最短梯度路径会减 1
- 当网络继续变深和变宽,CSP 晚融合的方式得到了更好的效果,每个 layer 的最短梯度路径会减 1
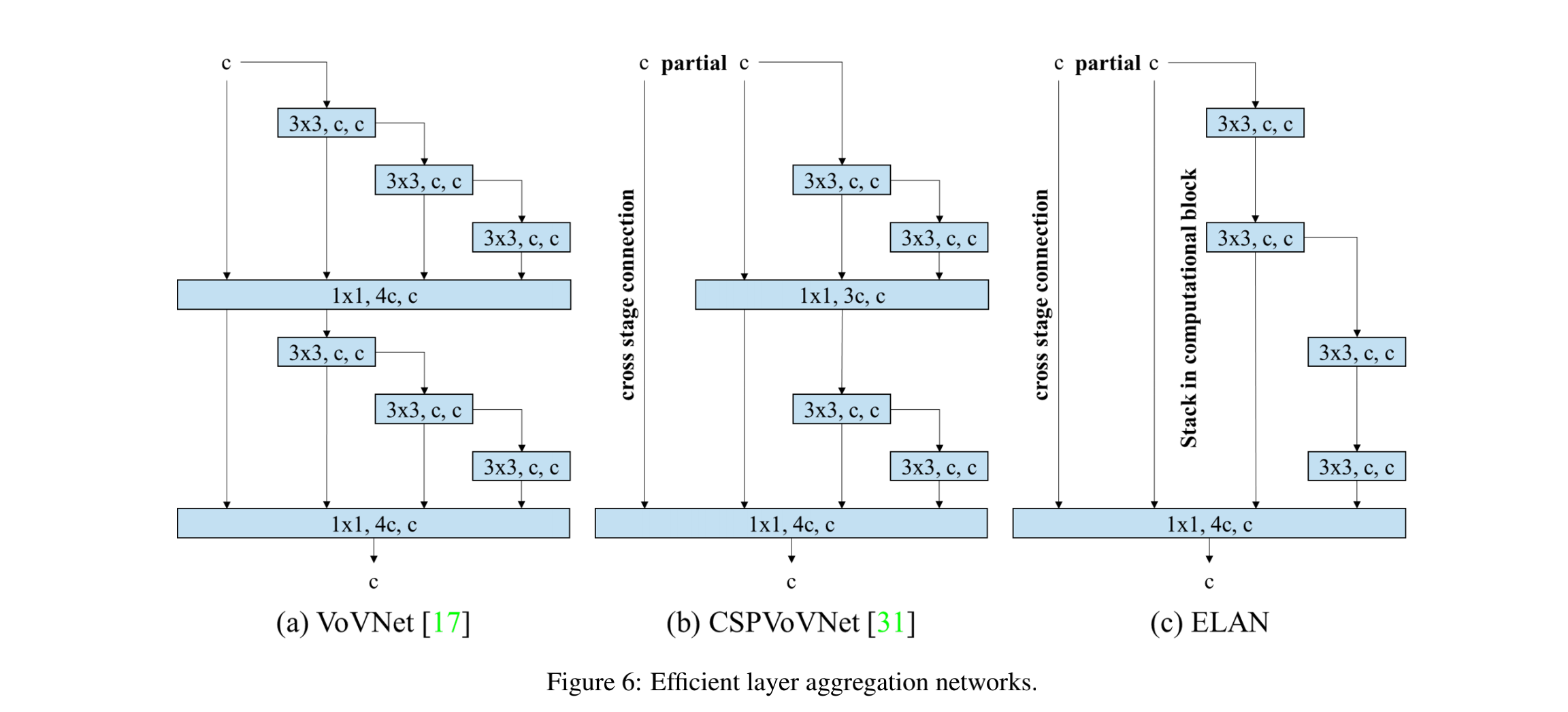
Stack in computational block 如图 6 所示:
- 出发点 1:为了避免使用更多 transition layer
- 出发点 2:让整个网络的最短梯度路径变得更长一些
这里介绍一下 VoVNet:
- 提出了 One-shot Aggregation(OSA),将中间的特征一次性聚合(在最后一层聚合一次),如图 1b 所示,能够在保留 concat 优势的同时优化 MAC(中间层输入输出通道相同) 和 GPU 计算效率(无需 1x1 卷积)
- 基于 OSA 模块,构建了 VoVNet,一个 backbone 网络结构,并且将该 backbone 用于 DSOD、RefineDet、Mask R-CNN 等方法中,取得了比 DenseNet、ResNet 等方法更好的效率和准确率的平衡
- VoVNet 是基于 DenseBlock 的,DenseBlock 中的每一层的输入都是前面所有层 feature map 的叠加。而 VoVNet 只有最后一层的输入是前面所有层 feature map 的叠加。
E-LAN 结构如图 6c 所示:主要为了避免过多的使用 transition layer(会提升梯度最短路径,影响网络加深)
我们已知,在分析梯度路径时,不能只看整个网络的最短梯度路径和最长梯度路径,而且需要更详细的梯度路径分析。
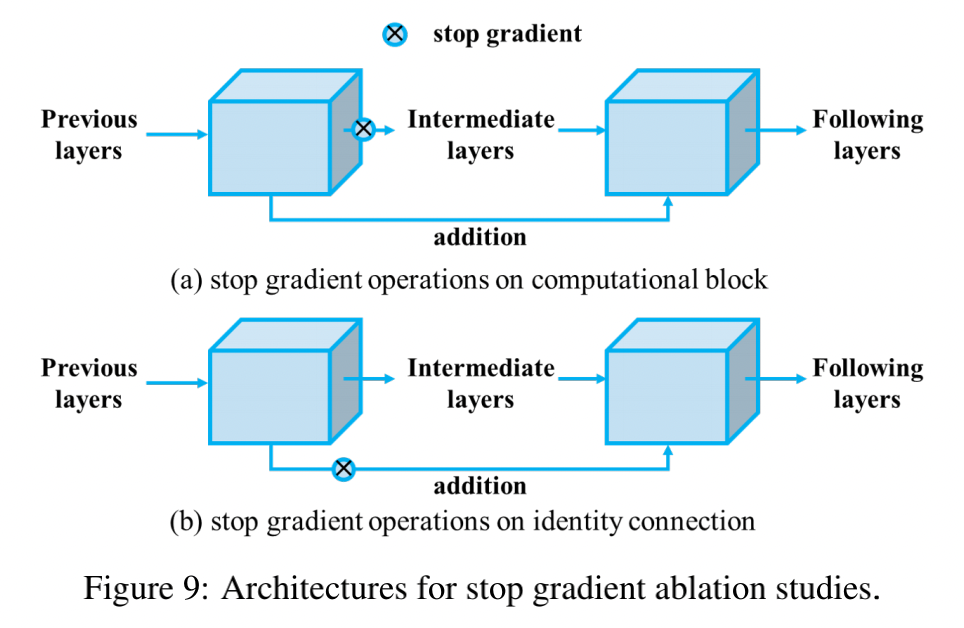
stop gradient:
首先,探索一下 ResNet 的最短路径长度。和 PlainNet,ResNet 的每个 block 都有一部分梯度是会经过 block 传递的
所以,作者会分别在 block 和残差连接上进行 stop gradient 操作,如图 9 所示:
- 残差连接上使用后:gradient path 会和 PlainNet 很类似,也就是说最长梯度路径和最短梯度路径相同了
- block 上使用后:最短梯度路径会直接从所有残差连接通过,所以最短梯度路径永远为 1,因为 block 有两层,所以最长梯度路径为 2
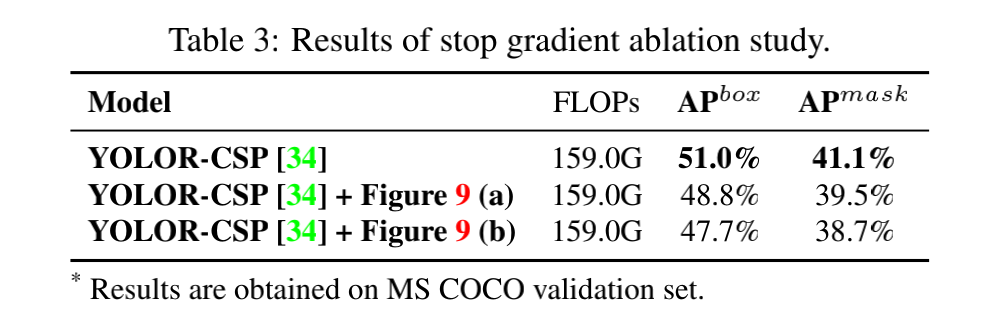
- 在 YOLOR-CSP 上的实验结果如表 3 所示,结果表明,在 ResNet 中缩短梯度路径是让深度网络能正常收敛的很重要的因素
Gradient path planning:
作者重新设计了 VoVNet 的 transition layer:
- 首先,移除 deep VoVNet 中的 OSA module 的所有 transition layer,只在最后一个 stage 的最后一个 OSA module 中使用 transition layer
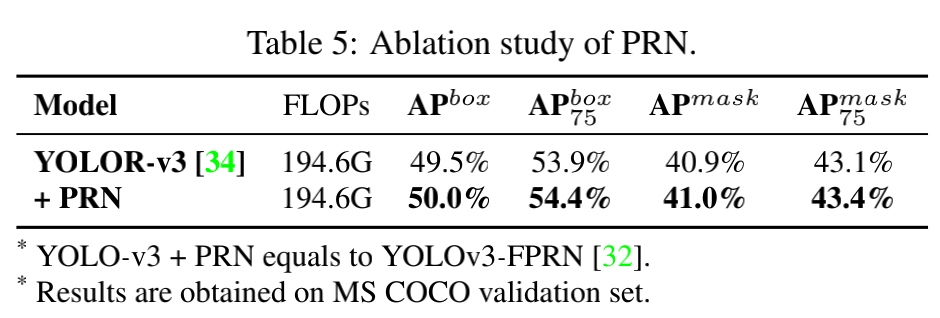
- 然后,将 CSPNet 的结构应用于上面的往来账哦好难过,来进一步观察 CSPNet 的效果,结果如表 4
- 结论,deep VoVNet 从无法收敛到收敛良好。所以,不应该只考虑最短梯度路径和最长路径的数值,而是需要确保的是每层的梯度最短路径和整个网络的梯度最长路径都可以被有效的训练到
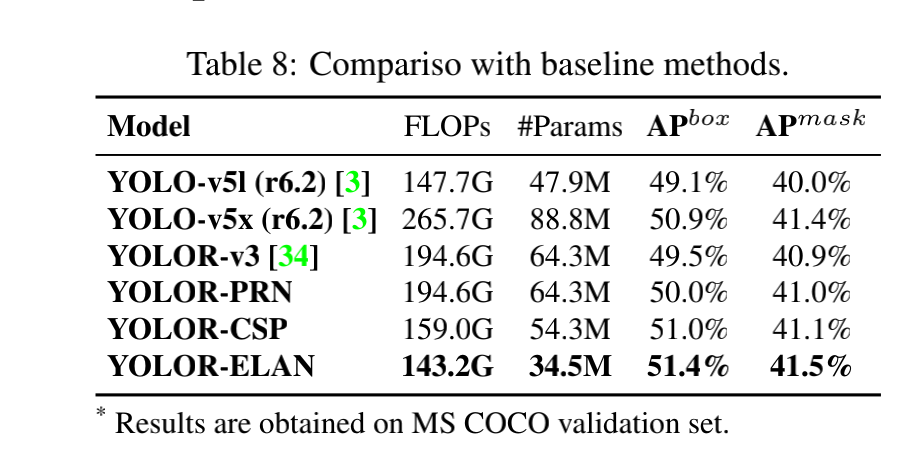
三、效果