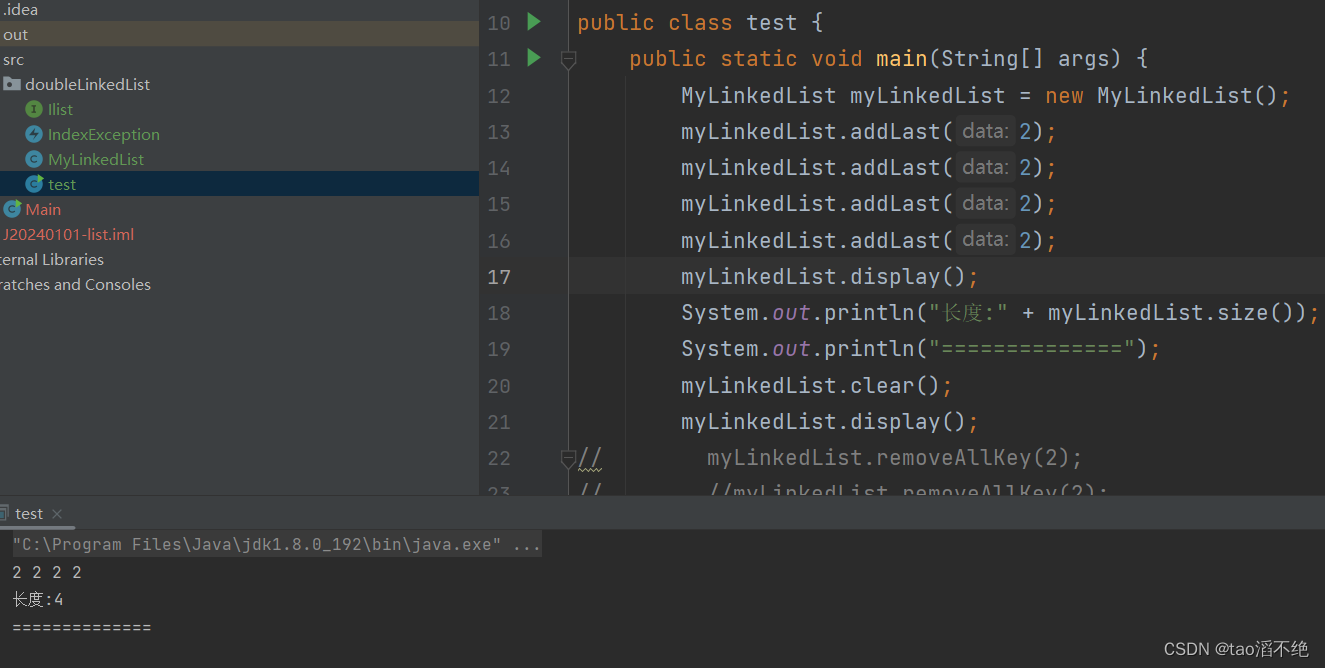
ABSTRACT
现代大规模视觉-语言模型(LVLMs)采用了相同的视觉词汇-CLIP,可以涵盖大多数常见的视觉任务。然而,对于一些需要密集和细粒度视觉感知的特殊视觉任务,例如文档级OCR或图表理解,尤其是在非英语环境中,CLIP风格的词汇可能在分词视觉知识方面效率较低,甚至遇到词汇表外问题。因此,我们提出了一种名为Vary的有效方法,用于扩大LVLMs的视觉词汇。Vary的过程自然地分为两个步骤:生成和整合新的视觉词汇。在第一阶段,我们设计了一个词汇网络以及一个小型的仅解码器的transformer,通过自回归方式生成所需的词汇。接下来,我们通过将新的词汇与原始词汇(CLIP)合并,扩大了原始的视觉词汇,使LVLMs能够快速获得新特征。与流行的BLIP-2、MiniGPT4和LLaVA相比,Vary在保持其原有功能的同时,拥有更出色的细粒度感知和理解能力。具体而言,Vary在新的文档解析功能(OCR或标记转换)上表现出色,在DocVQA中实现了78.2%的ANLS,以及在MMVet中实现了36.2%的成绩。我们的代码将在主页上公开发布。
论文地址:论文
即将开源:主页
开源代码:代码
该论文旨在解决大规模视觉-语言模型(LVLMs)中视觉词汇表规模的限制问题。在传统的视觉-语言模型中,通常使用一个固定大小的视觉词汇表来表示图像的视觉信息。然而,这种固定大小的词汇表可能无法有效地覆盖复杂和多样化的视觉世界。
为了扩大视觉词汇表的规模,论文提出了一种名为Vary的方法。Vary方法利用自回归生成技术,通过一个小型解码器(称为"vocabulary network"),从已有的有限词汇表中扩展出更多的词汇。该方法可以根据上下文和语言模型的预测进行表征,并在生成过程中利用了注意力机制。

Vary方法的关键思想是通过生成来扩大词汇表,而非直接增加预训练参数的数量。这使得扩展视觉词汇表的计算和存储成本大大降低,并且可以通过少量参数快速生成大规模的词汇。
论文通过在多个视觉-语言任务上的实验验证了Vary方法的有效性。实验结果表明,使用扩展后的视觉词汇表可以显著提升模型在图像分类、图像生成和视觉问答等任务上的性能。