一、概述
C++ 的最初目标就是成为 “更好的 C”,因此新的标准首先要对基本的底层编程进行强化,能够反映当前计算机软硬件系统的最新发展和变化(例如多线程)。另一方面,C++对多线程范式的支持增加了语言的复杂度,通常一个范式就相当于其他的一门编程语言,学习难度大。为了使能够让C++吸引更多的用户,避免“曲高和寡”的局面,C++标准组委会有指定了一些具体的设计目标:
- 保持稳定性和兼容性
- 尽量使用库而不是扩展语言来增加新特性
- 对初级用户和高级用户都能提高良好的支持
- 增强类型的安全性
- 增强直接操作硬件时的效率和功能
新的C++11/14 标准基本实现了这些目标,而且依然较好地保持了与之前版本的兼容性。
二、左值与右值
1. 定义
C++11/14 标准描述了左值与右值的含义,简略如下:
- 所有表达式的结果不是左值就是右值
- 左值(lvalue)是一个函数或者对象实例
- 失效值(xvalue,expiring value)是生命周期即将结束的对象
- 广义左值(glvalue,generalized lvalue)包括左值和失效值
- 右值(rvalue)包括失效值、临时对象、以及不关联对象的值(如字面值)
- 纯右值(pvalue)是非失效值的那些右值
这里给一个简单的解释:左值是一个可以用来存储数据的变量,有实际的内存地址(即变量名),表达式结束后依然存在,(历史上)它因在赋值操作符左边而得名;而右值(更准确来说是“非左值”)是一个“匿名”的“临时”变量,它在表达式结束时生命周期终止,不能存放数据,可以被修改,以科研不被修改(被const 修饰)。基于此,我们可以总结出鉴别左值和右值的简单方法:
- 左值可以用取地址操作符 “&” 获取地址
- 右值则无法使用 “&” (报错)
int x = 0; //对象实例,有名,x是左值
int* p = &++x; //可以取地址,++x是左值
++x = 10; //前置++返回的是左值,可以赋值
p = &x++; //后置++返回的是一个临时对象,不能取地址或者赋值,是右值,报错
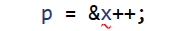

因为右值是“临时”的,生命周期即将结束,之后无人会关系它的值,所以我们可以把它的所有内容转移到其他对象中,消除昂贵的拷贝代价。
2. 右值引用
有了右值的概念,右值引用也应运而生,C++11/14 标准使用 “T&&” 的形式表示右值引用,而原来的 “T&” 则表示左值引用,两者可以简称为右引用和左引用,分别表示右值对象和左值对象(但在C++98 不能引用右值)。对一个对象使用右值引用,意味着显式地标记这个对象是右值,可以被转移来优化。同时也为它添加了一个“临时的名字”,生命周期得到了延长,不会在表达式结束时消失,而是与右值引用绑定到了一起。它们都可以被 const 修饰,“const&" 是一个”万能引用“,可以引用任何对象(但增加了常量性),虽然”const T&&" 是正确的,但因为右值引用对象是“临时的”,即将消失,对它增加常量性会使得它无法修改,也无法转移,没有实际意义。
int& r1 = ++x; //左值引用
int&& r2 = x++; //右值引用,引用了自增对象后的临时对象xvalue
const int& r3 = x++; //常量左值引用,也可以引用右值
const int&& r4 = x++; //常量右值引用,无意义
cout << r2 << endl; //右引用延长生命期,右值对象在表达式结束后仍然存在
C++11/14对此做出了新的规定——引用折叠:对引用类型 TR(可能是左引用或右引用)再进行左引用操作是 T&,右引用操作则不变化(仍然是TR),因此函数参数如果使用 T&& 的形式将总保持不变。
3. 转移语义
因为右值引用对象可以被转移进而优化代码,所以C++11/14标准头文件< utility > 里专门定义了便捷函数 std::move()来实现“转移”对象,它是一个模板函数,声明如下:
template<class T>
typename remove_reference<T>::type&& move(T&& t) noexcept;
move() 函数其实并没有任何“转移”操作,只是把一个对象明确地转换为“匿名”的右值引用,也即是说对该对象确认是右值对象,可以被安全地转移,相当于:
static_cast<T&&>(t); //静态强制转换, 转型为右值引用
C++11/14 标准为class 新增加了参数类型为 “T&& "的转移构造函数和转移赋值函数,只要类实现了这两个特殊函数就能够利用右值对象”零成本“构造,这就是转移语义。即现代C++语言优化性能的重要手段,只要对象被move()标记为右引用,就可以转移资源,不会进行”深拷贝“。以下实现转移构造函数和转移赋值函数:
class moveable
{
private:
int x;
public:
moveable() {}; //缺省构造函数
moveable(moveable&& other) //转移构造函数
{
std::swap(x, other.x);
}
moveable& operator=(moveable&& other) //转移赋值函数
{
std::swap(x, other.x);
return *this;
}
public:
static moveable create() //工厂函数创建对象
{
moveable obj; //栈上创建对象
return obj; //返回临时对象,即右值,会引发转移语义
}
};
moveable类里有一个工厂函数,它直接返回函数内的局部变量obj,在函数返回时是一个临时对象,也就是右值(无需再使用std::move()),而moveable类被定义了转移构造函数,所以可以直接使用临时对象的值来创建对象,避免了拷贝的代价,如:
moveable m1; //缺省构造函数创建对象
moveable m2(std::move(m1)); //条用转移构造函数,m1被转移
moveable m3 = moveable::create(); //调用转移赋值函数
C++标准库里的string、vector、deque等组件都实现了转移构造函数和转移赋值函数,可以利用转移语义优化,所以现在在函数里返回一个大容器对象是非常高效的。这些标准容器(std::array除外),还特别增加了emplace() 系列函数,可以使用语义直接插入元素,进一步提高了运行性能,如:
vector<complex<double>> v; //标准序列容器
v.emplace(3, 4); //直接使用右值插入元素,无需构造再拷贝
map<string, int> m; //标准映射容器
m.emplace("metroid", "prime"); //直接使用右值插入元素,无需构造再拷贝
4. 完美转发
标准头文件< utility >里还有一个函数std::forward(),用于泛型编程时实现”完美转发“,可以把函数的参数原封不动的转发给其他函数,如下声明:
template <class T> T&& forward(T& t) noexcept;
template <class T> T&& forward(T&& t) noexcept;
forward()在使用时必须指定模板参数,它引用C++11/14 标准的引用折叠规则。
void check(int&) //左值引用
{
cout << "lvalue" << endl;
}
void check(int&&) //右值引用
{
cout << "rvalue" << endl;
}
template<typename T>
void print(T&& v)
{
check(std::forward<T>(v)); //完美转发,依据函数参数类型调用不同的函数
}
int x = 10;
print(x); //传递左值引用,输出 ' lvalue '
print(std::move(x)); //传递右值引用,输出 'rvalue '

三、自动推导类型
C++11/14 标准增加了两个关键字: auto 和 decltype 。它们可以推到出表达式的类型信息,它们的推到能力可以极大的简化代码。
1. auto
C++是一种强静态语言,任何变量、表达式都要有明确的类型,例如:
long x = 0L; //声明x为long类型
const char* s = "hello"; //声明s为字符指针类型
对于简单的变量,可以很容易写出它的类型,但由于类、命名空间、模板等技术的扩展应用,变量的类型逐渐变得越来越复杂,有的类型名字甚至很难写出正确的类型:
map<string, string>::iterator iter = m.begin(); //迭代器
??? f = bind1st(std::less<int>(), 2); //很难推导出正确的函数对象类型
事实上,编译器是知道这些表达式的类型的,但在C++11/14 之前,这些信息都隐藏在编译器内部。C++11/14 标准重新定义了auto关键字的语义,能够在编译器自动推导出表达式的类型。
auto x = 0L; //x为long类型
auto s = "hello"; //s为字符指针类型
auto iter = m.begin(); //迭代器
auto f = bind1st(std::less<int>(), 2); //推导出正确的函数对象类型
auto的用法相当简单,但也有几个需要注意的地方:
- auto 只能用于赋值语句里的类型推导,不能直接声明变量
- auto 总数能推导出值类型(非引用)
- auto 运行使用”const / volatile / & / *" 等修饰符修饰,从而得到新类型
- auto&& 总是推导出引用类型
下列代码示范了auto的更多用法:
int x = 0;
const long y = 100;
volatile string s("one punch");
auto a1 = ++x; //值类型int
auto& a2 = x; //引用类型
auto a3 = y * y; //值类型long
auto& a4 = y; //引用类型
auto a5 = std::move(y); //值类型long,右引用被忽略
auto&& a6 = std::move(y); //引用类型const long&&
const auto a7 = x + x; //常引用类型const int
auto* a8 = &y; //const long*, auto本身推导为值类型
auto&& a9 = s; //引用类型volatile string&
auto a10; //不是赋值初始化,无法推导,编译错误
auto还可以用于函数的返回值声明处,自动推导函数的返回值类型
auto func(int x) { return x * x; } //int
现代C++,编程中应当尽量使用auto,它不会右任何的效率损失,而且带来了更好的返回值类型和可读性。
2. decltype
auto关键字能够在赋值语句里推导类型,但这只是C++语言里一种很少见的应用场景,要想在任意场合都能得到表达式的类型需要使用另一个关键字:decltype。它在技术和用法上与sizeof非常相似,因为都需要编译器在编译期计算类型,但sizeof返回的是整数,而decltype返回的是类型。
decltype(expreesion) //获取表达式类型,编译器计算
decltype 可以像 auto 一样用在赋值语句,但可以根据表达式的结果类别和表达式的性质推断出引用或非引用,能够更精确地控制类型:
decltype(x) d1 = x; //int
decltype(&x) d2 = &x; //int*
decltype(x)& d3 = x; //int&
decltype(x + y) d4 = x + y; //long
decltype(y)& d5 = y;//const long&
除了赋值语句,decltype 还可以用在变量声明、类型定义、函数参数列表、模板参数列表等任意的地方,因为它实际上就是一个编译器的类型名(只是通过表达式计算得到)
decltype(std::less<int>()) func; //声明一个函数对象,注意不是赋值语句
decltype(0.0f) func(decltype(0L) x) {return x * x;} //用于函数返回值和参数声明
typedef decltype(func)* fun_ptr; //简单地定义函数指针裂隙
vector<int> v;
decltype(v)::iterator iter; //计算v的类型,再取其迭代器类型
template<typename T>
class demo {};//模板类
demo<decltype(v)> obj; //模板参数使用decltype
auto 和 decltype 用法一样,但同样有语法细节需要注意:
- decltype(e) 的形式获得表达式计算结果的值类型
- decltype((e)) 的形式获得表达式计算结果的引用类型,类似 auto&& 的效果
int x = 0; //int
const volatile int y = 0; //直接对它所在内存读取数据,而不是使用保存在寄存器的的备份
decltype(x) d1 = x; //int
decltype((x)) d2 = x; //int&
decltype(y) d3 = y; //const volatile int
decltype((y)) d4 = y; //const volatile int&
下面示例更好的解释decltype(x) 和 decltype((x)) 的区别:
decltype(p->x) d5 = 42; //int
decltype((p->x)) d6 = p->x; //int&
decltype(p->x)& d7 = p->x; //报错
这里我们声明了一个volatile的指针p,decltype(p->x) 只能得到的值类型int,失去了volatile修饰,而decltype((p->x)) 可以得到p->x 的真正引用类型。
3. decltype(auto)
auto和decltype这两个关键字都可以推导类型,但用法有差异。auto的使用更加方便,但用途有限,只能用在赋值语句里; decltype用法广,可以任意推导表达式的类型,但使用时必须在括号内写全表达式,用法不便。C++14 标准增加了一种新的语法,运行将两者结合起来,即 “decltype(auto)” ,使用decltyoe 的语义推导,但用的却是 auto 语法,如:
//仅 C++ 14
decltype(auto) x = 6; //int
decltype(auto) y = 7L; //long
decltype(auto) z = x + y; //long
四、面向过程编程
C++语言继承了C语言的传统,支持最基本的面向过程编程,这个编程范式里C++11/14 的变化并不多,但增加的新特性却可以改进程序,甚至改变我们的编程思维。
1. 空指针
一直以来,在C/C ++ 语言里空指针都使用宏 NULL 表示,它的定义通常是 “0”,即:
#define NULL 0 //空指针宏NULL定义
但NULL存在严重的缺陷,它实际上是一个整数,而不是真正的指针,所以有时候会造成语义混淆(例如重载函数的参数)。C++11/14 增加了新的关键字“nullptr" ,彻底解决了这个问题,增加了安全性。
"nullptr"明确地表示空指针的概念,可以完全替代NULL,它可以隐式转化为任意类型的指针,也可以与指针进行比较运算,但绝不能转化为非指针都其他类型:
int* p1 = nullptr; //初始化为空指针
vector<int>* p2 = nullptr;//
assert(!p1 && !p2); //
assert(10 >= nullptr); //报错
nullptr 与 NULL 有重要区别,它的强类型的,但类型不是int或者void*,而是一个专用的类型nullptr_t ,其利用decltype 的能力:
typedef decltype(nullptr) nullptr_t; //nullptr_t的定义
还需要注意,nullptr 并不是指针,而是一个类型为nullptr_t 的编译期常量实例,只是其行为很像指针,所以我们也可以使用nullptr_t 任意定义与nullptr 等价的空指针常量,如:
nullptr_t nil; //初始化一个新的空指针常量
double* p3 = nil; //使用nil初始化空指针
assert(nil == p3); //完全等价
2. 初始化
C++中初始化是一个基本操作,但C++98 标准并没有非常明确的定义,而且初始化的语法也不一致。C++11/14 标准对这个问题给出了完整的解决方案,统一使用花括号 ”{}“ 初始化变量,称为 ”列表初始化“,例如:
int x{}; //x缺省初始化,值为0
double y{ 2.13 }; //
string s{ "hellow" }; //
complex<double> c(1, 1); //
int a[] = { 1, 2, 3 }; //
vector<int> v = { 4, 5, 6 }; //
在函数里也可以使用 ”{ . . . }" 作为值返回,类型自动推导:
set<int> get_set()
{
return { 2, 3, 9 }; //直接使用花括号返回一个集合容器
}
实际上,花括号形式的语法会生成一个类型为 std::initialized_list 的对象,它定义在头文件< initializer_list > 里,具有类似标准容器的接口,只要实现对它的构造函数就可以支持列表的初始化。
3. 新式for循环
遍历并操作 array、vector等容器里的元素是C ++里常见的操作,通常我们会使用循环语句,利用容器的首尾位置来完成,例如:
int a[] = {1, 2, 3, 5};
for(inti = 0 ;i < 4;i ++) //按int索引遍历
{
cout << a[i] << " " ;
}
vector<int> v = {12, 25};
for(auto iter = v.begin(); iter != v.end(); iter ++) //使用迭代器遍历
{
cout << *iter << " " ;
}
C++11/14 引入了一种更简单便捷的方式,无需显式使用迭代器首尾位置,也无需解引用迭代器,就可以直接访问容器序列里的元素,如:
for (auto x : v) cout << x << " "; //直接访问,无须遍历
for (const auto& x : v) cout << x << " "; //推导为常引用类型
这种新式for循环的正式名称是“基于范围遍历的for”(range-based for),使用两个“:” 分割了两个表达式,第一个是遍历容器时的元素类型,通常我们使用auto来自动推导,第二个是目标容器。
在声明元素类型时使用auto推导出类型,有拷贝代价,也不能修改元素,所以可以为auto添加修饰,如:“const auto& / auto&& "来避免拷贝,或者使用 auto& 来修改元素的值。
for(auto & x : v) cout << ++x << " "; //推导为引用类型,可修改值
新式for循环支持C++ 内建数组和所有标准容器,对于其他类型,只要它具有begin(),end()成员函数,或者能够使用函数std::begin() 和 std::end() 确定迭代范围就可以应用于 for。注意:新式for循环只是一种”语法糖“,本质上还是使用迭代器来实现。
auto&& _range = v;
for (auto _begin = std::begin(_range); //获得容器的引用
_end != std::end(_range); //确定范围迭代起点
_begin != _end; _begin++); //确定范围迭代终点
{
auto x = *_begin; //解引用
...
}
迭代范围已经在for循环开始前就确定好了,所以在for循环里我们不能变动容器,也不能增减容器里的元素,否则会导致遍历的迭代器失败,发生为定义的错误。
4. 新式函数声明
C++ 11/14 增加了一种新的函数语法,允许返回类型后置,它使用了auto 和 decltype 的类型推导能力,基本形式为:
auto func(...) -> type {...} //语法
有两处变化,首先,函数返回值必须使用auto来占位;其次,函数名后需要用 ”-<type " 的形式来声明真正的返回值类型,这里的“type" 可以说任意类型,也包括 decltype,如:
auto func(int x) -> declype(x)
{
return x * x;
}
这种语法看起来十分怪异,但实际上在泛型编程时,函数返回值的可能类型需要由实际的参数来决定,所以有必要将返回值类型的声明”延后“,如下:
template<typename T, typename U> //目标参数列表
auto calc(Tt, U u) -> decltype(t + u) //后置函数声明
{ reutrn t + u; } //返回两个变量之和
后置式函数声明语法虽然不常用,但在关键时刻能够解决特定的问题
五、面向对象编程
面向对象编程是一种很重要的编程范式,可以很好的控制类的封装、继承和多态
1. default
C ++11/14 重用了关键字default,可以显示地声明类的缺省构造 / 析构等特殊成员函数,能很好的表示代码意图。default 的用法于声明纯虚构函数的语法类似,在构造 / 析构 等成员函数后面是用 ”=default" 就可以了,如:
class default_demo
{
public:
//显式知道构造函数和析构函数使用编译器的缺省实现
default_demo() = default;
~default_demo() = default;
//显式知道拷贝构造函数和拷贝赋值函数使用编译器的缺省实现
default_demo(const default_demo&) = default;
default_demo& operator = (const default_demo&) = default;
//显式知道转移构造函数和转移赋值函数使用编译器的缺省实现
default_demo(default_demo&&) = default;
default_demo& operator= (default_demo&&) = default;
};
使用default 声明缺省构造函数后并不影响其他构造函数的重载于实现,我们仍然可以编写其他形式的构造函数:
class default_demo
{
public:
... //之前的default 构造、析构函数
int defautl_demo(int x);
};
2.delete
与defaule 类型,在C++11/14 里关键字delete 也增加了一种用法,可以显式地禁用某些函数——通常是类的拷贝构造函数和构造函数,以阻止对象的拷贝,如:
class delete_demo
{
public:
delete_demo() = default; //使用default 缺省实现
~delete_demo() = default;
//显式禁用拷贝构造函数和拷贝赋值函数
delete_demo(const delete_demo&) = delete;
delete_demo& operator = (const delete_demo) = delete;
};
delete_demo s1; //声明一个对象
delete_demo s2 = s1; //无法拷贝赋值,发生编译错误

显式delete不仅可以用于类成员函数,也可以作用于普通函数,禁用某些形式的重载。
3. override
C++ 的类继承体系里有虚函数的概念,它可以允许时动态绑定,是实现多态的关键。虚函数的声明需要使用virtual 关键字,如果一个成员函数是虚函数,那么在后续派生类里的同名函数都会说虚函数,无须再使用virtual 修饰。
但当继承关系较复杂或者派生类里的成员函数很多时,阅读者很难分辨出哪些函数继承自基类,哪些函数是派生类特有的,增加了代码的维护成本,且派生类可能无意使用了同名但签名不同的函数 “覆盖” 了基类的虚函数。
如下示例:
struct base
{
virtual ~base() = default; //虚析构函数
virtual void f() = 0; //纯虚函数
virtual void g() const {}; //虚函数,const修饰
void h() {}
};
struct derived : public base //派生类
{
virtual ~derived() = default; //虚析构函数,用default修饰
void f() {} //虚函数重载
void g() {} //不是虚函数重载,签名不同,无const修饰
void h() {} //不是虚函数重载,直接覆盖
};
base类很清晰,它定义了两个虚函数接口 f() 和 g(),还有一个非虚函数 h(),但是单独看derived类却信息有限,f()、g()、h() 三个函数中只要 f() 是正确的虚函数重载,g() 因为少了 “const” 修饰,函数与基类不同,是一个新的成员函数,而h() 函数则与虚函数无任何关系,直接是derived类自己专有的函数,“覆盖”了base类的原函数实现。
unique_ptr<base> p(new derived); //一个派生类对象,使用基类指针
// unique_ptr: 禁止拷贝和赋值,只能 unique_ptr<int> p1(new int(20));
p->f(); //正确,调用了派生类的f()
p->g(); //错误,调用了基类的g()
p->h(); //调用了基类的h(),未实现原意图
C++11/14里增加了一个特殊的标识符 “override" ,它可以显式地标记虚函数的重载,明确代码编写的意图,派生类里的成员函数如果使用了override 修饰,则必须是虚函数,而且签名也必须与基类的声明一致。即,可修改代码为如下所示:
void f() override{} //虚函数重载
void g() const override{} //虚函数重载
4. final
C++的类体系非常灵活,但这种灵活有时候会带来麻烦,没有阻止类继承或者阻止重载虚函数的手段,对于标准库里面的vector、list等容器,设计者也不希望它们派生出子类,但在C++11/14 之前没有语言层面的强制保证。
与override一样,它也增加了一个特殊的标识符 ”final”,不仅可以控制类的继承,也可以控制虚函数:
- 在类名后面使用final,显式地禁止类被继承,即不能有派生类
- 在虚函数后使用final,显式地禁用该函数在子类里再被重载
override 和 final 可以婚姻,更好的标记类的继承体系虚函数,如下:
struct interface
{
virtual void f() = 0; //纯虚函数
virtual void g() = 0;
};
struct abstrace : public interface
{
void f() override final {} //f()不能再被继承和重载
void g() override; //不能再被继承,还可以重载
};
struct last_final final : public abstrace
{
void f() {}; //不能重载
void g() {}; //g() 仍然可以重载
};
struct error : public last_final {}; //last_final 不能被继承

final也不是关键字,仅在类声明里有特殊含义,但不建议再将它作为其他的标识符。
5. 委托构造
有时候我们会声明多个不同形式的构造函数,用于不同情况下创建对象,这些代码大多都有初始化成员变量,非常类似,仅有少量不同,但代码却不能复用,导致代码冗余。而其常用的一种解决方法就是实现一个特殊的初始化函数(通常是init),然后在每个构造函数里调用它,如:
class demo
{
private:
int x, y;
void init(int x, int y) { x = x, y = y };
public:
demo() { //缺省构造函数
init(0, 0);
}
demo(int a) { //但参数构造函数
init(a, 0);
}
demo(int a, int b) { //双参数构造函数
init(a, b);
}
};
C++ 11/14 标准引入了委托构造函数(delegating constructor)的概念,解决方法相同,但不需要再次构造一个特殊的初始化函数,而是可以直接调用本类的其他构造函数,把对象的构造工作“委托”给其他构造函数来完成,能够更好的简化代码,如下:
class demo
{
public:
demo() : demo(0, 0) {} //缺省构造函数,委托给双参数构造函数
demo(int a) :demo(a, 0) {} //单参数构造函数委托给双参数的构造函数
demo(int a, int b) { x = a, y = b; } //双参数构造函数,被其他构造函数调用
private:
int x;
int y;
};
委托构造函数可以配合类成员在初始化是使用,在类声明时先初始化成员变量,然后再使用委托构造函数金星额外的构造操作,进一步简化代码。
六、泛型编程
自从关键字template出现后,泛型编程逐渐成为C++的主流编程范式之一,更扩展出了允许在编译器的模板元编程。泛型编程使用泛型容器、泛型算法成为可能,深刻地改变了C++语言,同时也影响了C++之外的语言。
1. 类型别名
C++ 11/14 扩展了using关键字的能力,可以完成与typedef 相同的工作,使用 “using alias= type ” ,的形式为类型起别名,如:
using int64 = long; //long 类型的别名为int64
using ll = long long; //long long 类型的别名为 ll
它与typedef 的顺序恰好相反,易于理解。但是不止于此,它超越了typedef ,可以结合template 关键字为模板类声明 “部分特化” 的别名,如:
template<typename T> //为标准容易map取别名
using int_map = std::map<int, T>; //
int_map<string> m; //使用别名,省略了一个模板参数
template<typename T ,typename U> //自定义类,两个模板参数
class demo final {} ;
template<typename T> //保留一个模板参数
using demo_long = demo<T, long> //别名,第二个参数固定
demo<char, double>; //原模板类,给出两个参数
demo_long<char>; //模板别名,给出一个参数
对于拥有复杂模板参数列表的类来说,using的别名用法可以给出一些常用的形式,简化模板类的使用,增加代码可读性。
2. 编译期常量
3. 静态断言
C语言提供断言assert,它是一个宏,可以允许时验证某些条件是否成立,有利于保证程序的正确运行,但泛型编程主要工作在编译期,assert 不起作用。而C++11/14 增加了关键字static_assert ,它是编译期的断言,可以在编译期加入诊断信息,提前检查可能发生的错误。其用法与assert 基本一致:
static_assert(condition, message); //
如果bool值表达式在编译期的计算结果为false,那么编译器会报错,并给出message的提示信息。static_assert 通常需要配合type_traits 库来使用:
static_assert(sizeof(int) == 4, "it must be 32bit !!!");
4. 可变参数模板
七、函数式编程
函数式编程(functional programming)是与面向过程编程、泛型编程并列一种编程范式,它基于 “那麽达” 演算理论,把计算过程视为数学函数的组合运算。引入了lambda 表达式,更好支持函数式编程,简化代码。
1. lambda 表达式
C++ 11/14 标准里,lambda 表达式实际上是对函数对象的一种强化和扩展,可以直接就定义“匿名”的函数对象(所谓的“语法糖”)。基本形式:
[] (params) {...} //
这里的 [] 称为lambda 表达式引出操作符,它之后的代码就是lambda 表达式,形式如同一个标准的函数,圆括号里是函数的参数,而花括号内则是函数体,可以实现任何功能。lambda 表达式的类型称为“闭包”,无法直接写出,所以通常需要使用auto 的类型推导功能来存储,如下:
auto f1 = [](int x)
{
return x * x;
}; //末尾需要分号
int a[] = {9, 2, 3, 1, 6};
sort(a, a + 5, [](int x, int y){ return x < y; }); //排序
lambda 表达式的返回值会自动推导,但也可以使用新的返回值后置语法:
auto f = [](int x) -> long { . . .}; //指定返回值类型为 long
2. 捕获外部变量
lambda 表达式的功能不止于此,它还能捕获外部变量。其完整声明语法是:
[captures] (params) mutable -> type {. . .} //
操作符 [] 里的“captures” 称为“捕获对象”,可以捕获表达式外部作用域的变量,在函数式内部直接使用。
| 操作符 | 功能 |
|---|---|
| [] | 无捕获,函数式内不能访问任何外部变量 |
| [=] | 以值(拷贝)的方式捕获所有外部变量,函数体内可以访问但不能修改 |
| [&] | 以引用的方式捕获所有变量,函数体内可以访问并修改 |
| [var] | 以值(拷贝)的方式捕获某个外部变量,函数体可以访问但不能修改 |
| [&var] | 以引用的方式捕获某个外部变量,函数体内可以访问并修改 |
| [this] | 捕获this指针,可以访问类的成员变量和成员函数 |
| [=, &var] | 引用捕获变量var,其他外部变量使用值捕获 |
| [&, var] | 值捕获变量var,其他外部变量使用引用捕获 |
下面的代码示范了这些列表的用法:
int x = 0, y = 0;
auto f1 = [=]() { return x; }; //以值方式捕获使用变量,不能修改
auto f2 = [&]() {return x++; }; //以引用方式捕获变量,可修改
auto f3 = [x]() { return x; }; //值捕获x
auto f4 = [x, &y]() {y += x; }; //值捕获x,引用捕获y,可修改y
auto f5 = [&, y]() {x += y; }; //值捕获y,其他外部变量为引用捕获
auto f6 = []() {return x; }; //无捕获,不能使用外部变量,报错
需要注意值捕获发生在lambda 表达式的声明之前,如果使用值方式捕获,即使之和变量发生变化,lambda 表达式也不会感知,仍然使用最新的值;如想要使用外部变量的最新值就必须使用引用的不会方式,担心变量的生命周期,防止引用失败。
lambda 表达式还可以使用关键字 mutable 修饰,它为值捕获添加了一个例外情况,允许变量在函数体也能修改,但这只是内部的拷贝,不会影响外部的变量,如:
auto f = [=]() {return x ++;}; //可以在内部修改,不影响外部变量
lambda 表达式也可以转换为一个签名相同的函数指针,但需要注意转换时,它必须是无捕获列表的,如:
typedef void (*func)(); //函数指针类型
func p1 = []() {cout << endl; }; //直接赋值
auto g = [&]() { x++; }; //有捕获的lambda 的表达式
func p2 = g; //无法转换,报错
八、并发编程
并发编程是提高程序允许效率的一个必备手段,C++11/14 充分考虑了这个现实的需求,以库的形式提供了较好的支持,如< thread> 、< mutex >、< atomic >等,还新增了关键词 thread_local ,它实现了线程的本地村村,是一个与extern 、static 类型的变量类型存储指示标记。
线程本地存储是多线程编程里的概念,是指变量在进程中拥有不止一个实例,每个线程都会由于一个完全独立的、“线程本地化” 的拷贝,多个线程对变量的读写互不干扰,完全避免了竞、同步的麻烦,如:
extern int x; //外部变量,实体存储在外部,非本编译单元
static int y = 0; //静态变量,实体存在本编译单元内
thread_local int z = 0; //线程局部存储,每个线程都拥有独立的实体
以上代码声明了三个变量: x 使用extern 修饰,是一个外部变量; y 使用static 修饰,是一个静态变量,只能在本实现文件内访问,在多线程下是不安全的; 而 z 使用了 thread_local 关键字,是线程安全的,每个线程都有一份属于直接的独立的实例。下面代码验证了其结果:
auto f = [&]() { //lambda 表达式,线程实际执行的函数
y++;
z++;
cout << y << " " << z << endl; //输出值
};
thread t1(f); //启动两个线程
thread t2(f);
t1.join(); //回收线程
t2.join();
cout << y << " " << z << endl; //在主线程里输出变量值
运行结果如下:

可见,静态变量y在进程里是唯一的,两个线程都改变了y的值,而z因为是thread_local 的,两个子线程和主线程分别持有互相独立的三个实例,所有子线程里均独立的加 1,而主线程因为没有对z做任何操作,所有值为0.
thread_local 变量的声明周期比较特殊,它在线程启动时构造,在线程结束时析构,也就是说仅在线程的声明周期里是有效的,比static 变量的生命周期短,但比普通局部变量的生命周期长。thread_local 仅适用于线程需要独立存储的情况,当线程间需要共享资源访问时,仍然需要使用互斥量等保护机制。
九、面向安全编程
1. 无异常保证
C++ 的异常机制比较复杂,允许程序抛出任意类型的对象作为异常,为了规范异常的使用,C++ 提出了 “ 异常规范” 的概念,可以使用 throw (. . .)的形式来说明函数可能会抛出异常,但用得较少。而C++11/14 里 “异常规范” 被废弃,保留了一个很小的功能:声明函数不会抛出任何异常,并且引入一个关键字 noexcept 来明确表明这个含义,如:
void func() noexcept; //函数决不会抛出异常
使用它可以减少异常处理的成本,提高运行效率。
2. 内联命名空间
C++ 使用命名空间来解决命名冲突的问题,关键字 namespace 可以声明一个专有的作用域,其内的所有变量、函数或者类都不会与外部发生冲突,但是使用时也必须加上命名空间的限定,或者使用using打开 命名空间。它通常需要用一个名字来标识,但C++ 也允许不使用命名空间来声明一个“匿名” 的命名空间,这是相当与使用 static 静态初始化了命名空间里的成员,如:
namespace{
int x= 0; //具有静态属性
}
assert(x == 0); //可直接访问
也可以增肌一个 inline 关键字修饰,使其也不需要命名空间限定,可直接访问
inline namespace temp
int xx = 0;
}
assert(xx == 0);
内联命名空间的这个特性对于代码的版本化很有用,可以在多个子命名空间里实现不同的功能,而且发布的时候对外只暴露一个实现,隔离版本的差异,有利于维护,如:
namespace release { //对外发布的命名空间
namespace v001 { //旧版本
void func() {}
}
inline namespace v002 { //使用inline内联
void func() {}
}
}
release::func(); //看不到子命名空间,直接使用父命名空间
3. 强枚举类型 enum
enum color{ //弱枚举类型
a = 1, b = 2, c = 3
};
assert(b == a + 1); //可以运算
int a = 1; // 报错,编译错误
强枚举类型可以使用 ”struct / class “ 的形式声明, 但它不能被隐式转化为整数
enum class color{ . . . }
auto x = color::a; //正确,必须使用类型名
auto y = a; //错误,没有类型名限定
auto z = color::a + 1; //错误,不能隐式转化为整数运算
十、一些特性
标准预定义宏 ”_cplusplus " ,是一个整型常数,可辨别编译器版本
cout << "C++ : " << _cplusplus << endl;
超长整数 uLL、LL
auto a = 52313LL ;
auto b = 2147483647uLL ;
原始字符串 -> 两边不超过16个字符
auto s = R"hello \\\\ world"; //不需要转义
auto b = R"***(biographicldd infsfspl)***"; //定界符 ***
auto d = R"====(Dark souls)===="; //定界符 ===
auto f = 2.14f' //后缀f 指示float
auto s = L"wide char"; //前缀L,指示wcahr_t
auto x = 0x199L; //前缀0x:十六进制; 后缀L:long类型
.........这里就不一一列举了
至此结束