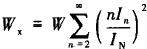作者 |张祥威
编辑 |德新

2023年,在比亚迪那次公布智驾数据规模后,智能化下半场的战斗就正式打响了。
如今,自动驾驶正在沿着特斯拉提出的「BEV+Transformer」急速推进,这条技术路线短短几年就得到了验证,随着智驾起较晚的比亚迪大举进场,让新技术再次得以普及。
新路线的普及,也让整个自动驾驶行业对数据提出了更高要求。
通常,激光雷达的算法要满足自动驾驶的性能要求,需要至少几十万帧的数据训练。单目摄像头要求更高,需要百万帧的训练数据。不过这两者和BEV方案比起来,差距仍然十分巨大。
自动驾驶采用的BEV感知方案,需要达到1亿帧以上的训练数据才能满足车规要求,否则泛化性、准确率和召回率就难以保障。
如何获取这么大规模的数据,获取之后如何有效回传、标注以及训练,并最终OTA反馈到车端,是数据闭环的核心任务,也是大多数车企迫切想要拥有的能力。
近日,HiEV与觉非科技CEO李东旻进行了一场对话,在过去几年里,他基本上见证了车企对于数据闭环上车的完整历程。
用他的话说,数据闭环已经成为实现高阶智驾的「华山一条路」,没有一家车企可以绕开。甚至,本土车企在上马数据闭环这件事上,已经到了不预研也得上的程度。
一、特斯拉打造样板间,车企争相入局
要弄明白数据闭环,还要回到自动驾驶的先锋特斯拉,和那位大牛人物Andrej Karpathy(简称AK)。
2017年6月,马斯克从OpenAI挖来AK,任命其为特斯拉人工智能和自动驾驶视觉总监。次年在「Spark+AI 」的会上,AK展示了一页写着Data Engine字样的PPT,上面列出了Data Source——notice a problem——boost——label——train——deploy的流程。
有心者会发现,去年特斯拉AI Day上的那张图,正是AK那张PPT的升级版本,只不过细节上做了完善。
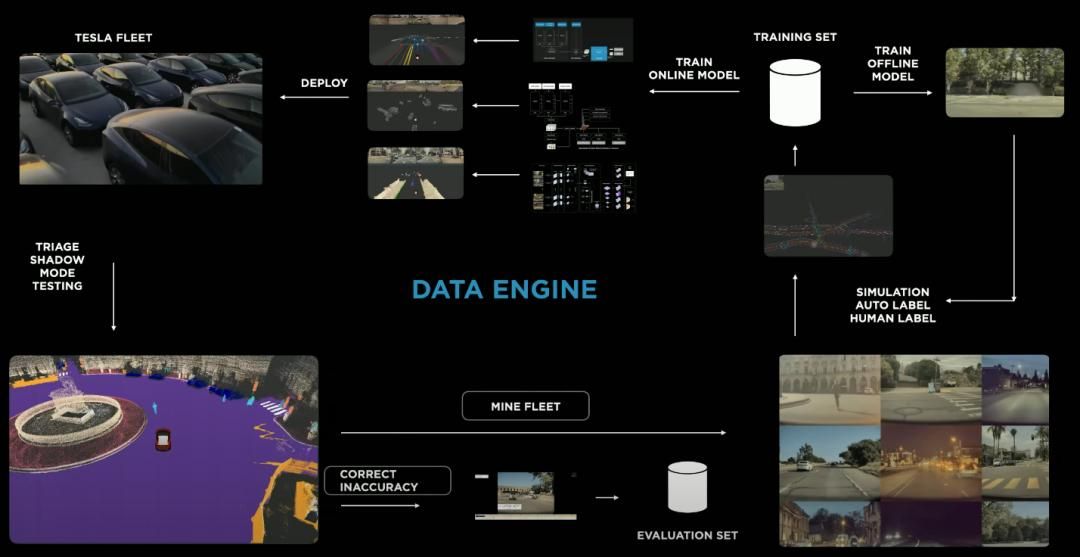
Date Engine的中文名是数据引擎,简单来说,就是将车辆行驶过程中获取的数据,通过一系列标注、模型训练,最终将模型部署回车上,让车驾驶得更好。
特斯拉不断产生数据、训练数据的前几年,其他车企、自动驾驶公司观望者多,跟进者少,车企很少像今天这样大谈「数据闭环」,直到2021年8月。
这年,特斯拉AI Day提出了「BEV+Transformer」的技术路线,让自动驾驶从业者为之一振。原本的2D检测面临遮挡等Corner Case难以穷尽的问题,至此有了更有效的解题思路。
李东旻告诉HiEV,那场发布会后不久,不少国内的自动驾驶行业人士在国际出行变得方便后,前往海外对特斯拉的车进行了体验,「觉得真的很震撼,从关注到相信,开始想尝试。」
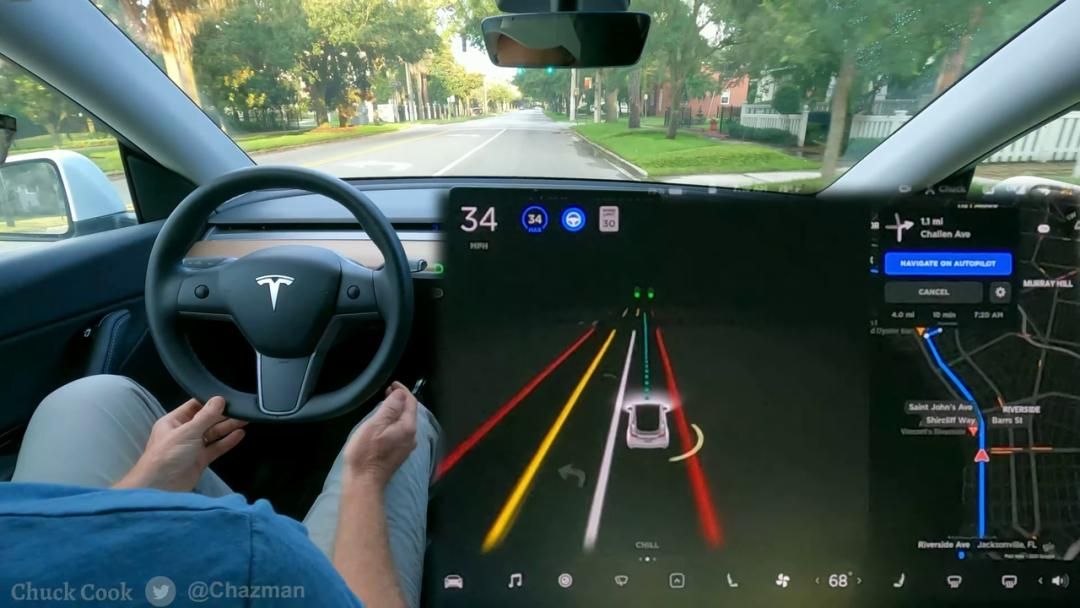
2022年初,主机厂开始频频谈及数据闭环的方案,到下半年,车企搭建「数据闭环」能力的意愿愈加迫切,一些车企甚至有跳过预研直接上马的想法。
跳过预研,风险点在于感知、规控这一端,是否和另一端的数据闭环形成了很好的衔接。
正常来说,车企需要一边保证量产,另一边进行预研。对于数据闭环,车企需要搞清楚自车产生的感知、规控的数据规格、质量,能否很好地匹配另外一端的数据闭环。
不过,在智驾上车已成必然的当下,留给车企的时间不多了。
一些车企发现,要实现高阶智驾,只有「数据闭环」这华山一条路,再加上特斯拉已经打造了样板间,所以有车企甚至敢于跨过预研,直接推进研发。
二、车企、供应商争相进场
做数据闭环,一个代表是新能源车的龙头、智驾起步较晚的比亚迪。
2023年中,比亚迪智驾负责人韩冰公布了一组数据,「目前已形成一支300多辆车的研发车队,已经积累150PB以上的数据,且每天新增数据1PB。」
这一信息表明,比亚迪正处于「数据闭环」的启动阶段。
数据闭环分为两种,一种是靠研发采集车。小鹏、华为在起步阶段,均是靠这种方式获取数据。
另一种是通过量产车获取数据,这是在数据规模上来后的主流方式。

比亚迪采取前一种方式。
「1PB除以300辆车,意味着一辆车每天可以搜集3TB多的数据,在行业中属于正常水平。通过研发采集车收集数据,是做数据闭环启动阶段的最好方式,也是必经的方式。」李东旻告诉HiEV。
另一个代表,是最紧密跟随特斯拉的小鹏汽车,也是业内公认的自动驾驶第一梯队玩家。这家公司把数据闭环分为四个环节:数据收集、标注、训练和部署。
2022年1024科技日,小鹏披露在近10万辆的小鹏车型上部署了超过300个触发器,形成了一个「全闭环、自成长的AI和数据体系」。
数据闭环的魅力在于,当这近10万辆车形成了数据闭环,就有了和特斯拉100万辆车掰手腕的底气。

原小鹏自动驾驶副总裁吴新宙曾表示,城市场景数据量并不是一个限制因素,只要可以闭环,由10万辆提供数据已经足够,一百辆车和一万辆有非常大的差别,但10万辆和100万辆的差别不会太大。
如今,小鹏的自动驾驶进展放在车企中妥妥地第一梯队,其数据闭环能力自然也水涨船高,位居前列。
如何评价数据闭环的水平高低,李东旻给了我们三个指标:
- 有效回传的量有多大;
不是卖的车越多,数据回传的量就越大。过去很多车受制于电子电气架构,回传能力相对欠缺。而那些基于域控架构的车,数据闭环的质量会高出很多。
- OTA的能力有多强;
在数据闭环中,OTA的频率越高,进化速度越快,也意味着数据闭环的能力越强。
- 城市NOA开城数量;
数据闭环最终是服务于车辆的智驾功能,从数据闭环的结果看,城市NOA的城市数量越多,意味着数据闭环的能力越强。
目前,比较难以精准统计小鹏的数据回传规模和OTA频次,只能从城市NOA这一维度来侧面得出结论,随着小鹏Xmart OS 4.4.0的推送,在无图城市NOA这项比拼中,这家公司的数据闭环能力已经占据头号位。
比亚迪、小鹏之外,还有一类较早看清趋势的供应商,比如李东旻所在的觉非科技,从公司成立第一天起,就是瞄准数据闭环而来。
据HiEV了解,以李东旻为主导的觉非科技的管理团队,过去曾打造了用户量过亿的导航软件,而导航软件就是一个典型的数据闭环案例。从低频逐渐变为高频,尤其是引入了实时路况这样的大数据之后,不断地与导航软件之间形成循环流动。
觉非的数据闭环架构,包含车端的感知、地图引擎、感知定位,以及制图工具链、轻地图等,通过数据反馈、OTA/API的方式完成整个闭环。
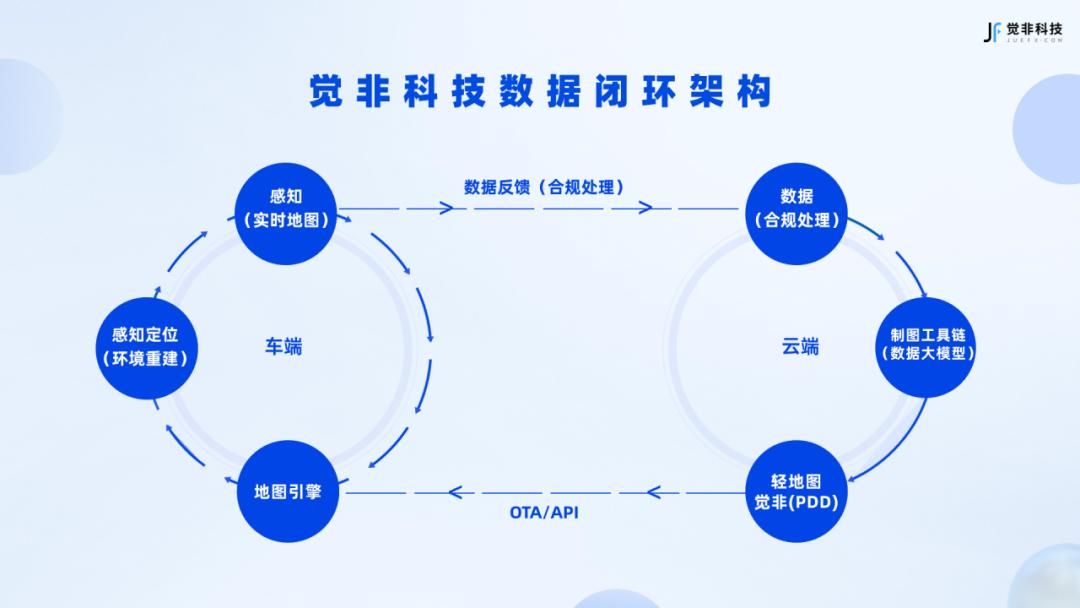
这套数据闭环流程中还融合了三类系统:
- 车的眼睛:摄像头、激光雷达、毫米波雷达、4D毫米波雷达;
- 车的小脑:位置姿态、RTK、差分定位、轮速、惯性导航;
- 记忆系统:地图引擎、记忆泊车、记忆行车;
主机厂想要采用觉非科技的数据闭环方案,大致有两种方式:一种是搭载觉非基于地平线、英伟达芯片打造的数据闭环方案;另一种是搭载其研发的域控制器。
近日,觉非科技宣布已与多家头部主机厂达成量产定点合作,围绕轻地图与数据闭环服务的量产车型将在今年正式交付。据HiEV了解,此次合作的头部主机厂中,就有新能源车的销量巨头。
小鹏和觉非科技,代表了数据闭环的两类玩家,那些尚未建立「数据闭环」能力的车企,无论学小鹏,还是与觉非科技这样的公司合作,都需要正视数据闭环,明白这项能力究竟在比拼什么。
三、「数据闭环」拼的是流程和工程化
数据闭环,本质是由数据去训练软件算法,推动软件算法不断优化升级的过程。
早期,自动驾驶开发者让数据训练感知、规控等小模型,同步还延展至云端训练大模型,更加注重「数据」驱动。随着数据规模的不断增加,行业如今更加注重的「闭环」,数据的消费方又是数据的生产方。
前文介绍了比亚迪通过研发采集车获取数据的方式,这种方式的好处是数据密度、数据质量都很高。
以研发采集车为例,一辆车每天采集的数据,大概在2T到4T之间。单个摄像头一秒钟能采集20-30M的数据,10V的方案,一秒钟采集300M,一天有效采集8小时的话,300台车获取的将是PB级别的数据。
但是上述方法对数据覆盖率的问题是无法解决的,数据闭环真正的比拼其实要靠量产车。
前不久,蔚来汽车公开了一组数据,10000辆蔚来汽车的轨迹,基本上把全上海进行了覆盖。蔚来提出了一个叫「群体智能」的新词。群体智能的背后,是靠量产车实现了数据闭环。
与研发采集车不同,量产车的数据闭环,不再是把硬盘卸下来,将数据拷出去,而是要在量产车上,通过一个安全合规的通道,然后上传到云端,来完成数据的存储、分发、训练,处理完之后再通过OTA的方式下发到量产车上。
量产车的优势在于覆盖比较广,难点在于,闭环的流程和工程化,而工程化,其实正是觉非科技这类本土自动驾驶公司所具备的优势。
据李东旻介绍,觉非科技在算法层面具备工程化壁垒,从早期的激光雷达方案,到后来的纯视觉方案,觉非科技通过提供多传感器融合计算的量产交付,以及将自家的软件解决方案提供给主机厂做智能驾驶域控,目前已实现了对多个主机厂多款车型的定点交付,并计划在今年继续扩大合作范围。
2023年其实有一个很明显的现象,搭载高阶智驾的车陡然增多。在这年的广州车展上,几款新发布的明星新能源车上,基本上标配激光雷达、大算力芯片和全场景智能驾驶。
这些带有大算力的高阶智驾车型渗透率提升,会让自车产生大量的数据,也就是让车企成为数据闭环的生产方,同时也是数据的消费方,车企们今天已经抵达「数据闭环」舞台中心。
作为消费者,看到的是城市NOA,具备城市NOA功能,将会极大地影响消费者的购买决策。
作为自动驾驶从业者,会发现实现城市NOA的唯一路径便是数据闭环,在「华山一条路上」,可以慢,可以错,但唯独不能不上山,否则就会被遗忘在山脚下。