目录
- 什么是Lambda
- lambda表达式的类型及实现方式
- 类型
- 语法
- 常用函数式接口
- Customer
- 函数式编程在Stream中的应用
- 总结
- 参考资料
什么是Lambda
Lambda 表达式是 JDK8 的一个新特性,可以取代大部分的匿名内部类,写出更优雅的Java代码。
Lambda 表达式描述了一个代码块(或者叫匿名方法),可以将其作为参数传递给构造方法或者普通方法以便后续执行。如:
() -> System.out.println("hello");
() 为 Lambda 表达式的参数列表(允许没有参数),-> 标识这串代码为 Lambda 表达式(也就是说,看到 -> 就知道这是 Lambda),System.out.println("hello") 就是执行的代码,将“hello”打印到标准输出流。
以Runnable接口为例,原来我们创建一个线程并启动它是这样的:
public class Test {
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("hello");
}
}).start();
}
}
如果用 Lambda 表达式只需要这样写:
public class Test {
public static void main(String[] args) {
new Thread(() -> System.out.println("hello")).start();
}
}
两者对比就可以看出代码的优雅程度。
我们看Runnable接口源码:
@FunctionalInterface
public interface Runnable {
public abstract void run();
}
其中@FunctionalInterface注解是个标记注解,说明通过 @FunctionalInterface 标记的接口可以通过 Lambda 表达式创建实例。@FunctionalInterface修饰函数式接口的,要求接口中的抽象方法只有一个,有多个抽象方法编译将报错。但由于该注解是个标记注解,加不加@FunctionalInterface对于接口是不是函数式接口没有影响,即不加该注解的接口也可以作为函数式编程使用。
lambda表达式的类型及实现方式
类型
public interface Comparator<T> {
int compare(T o1, T o2);
}
public interface Runnable {
void run();
}
public interface Callable<V> {
V call() throws Exception;
}
上面三个接口都只有一个抽象方法,但是三个方法的签名都不一样,这要求Lambda表达式与实现接口的方法签名要一致。下面用函数描述符来表示上述三个方法的签名,箭头前面是方法的入参类型,后面是返回类型。
-
compare:
(T, T) -> int两个泛型T类型的入参,返回int类型
Lambda表达式:
(User u1, User u2) -> u1.getAge - u2.getAge -
run:
() -> void无入参,无返回值
Lambda表达式:
() -> { System.out.println("hello"); } -
call:
() -> V无入参,返回一个泛型V类型的对象
Lambda表达式:
() -> new User() //不需要用括号环绕返回值为单行方法调用。‘
语法
Lambda表达式由三部分组成:
- 参数列表
- 箭头
- 主体
有两种风格,分别是:
-
表达式-风格
(parameters) -> expression -
块-风格
(parameters) -> { statements; }
常用函数式接口
java.util.function包中定义了一些常见的函数式接口:
Function,接受一个输入参数,返回一个结果。参数与返回值的类型可以不同,我们之前的map方法内的lambda就是表示这个函数式接口的;Consumer,接受一个输入参数并且无返回的操作。比如我们针对数据流的每一个元素进行打印,就可以用基于Consumer的lambda;Supplier,无需输入参数,只返回结果。看接口名就知道是发挥了对象工厂的作用;Predicate,接受一个输入参数,返回一个布尔值结果。比如我们在对数据流中的元素进行筛选的时候,就可以用基于Predicate的Lambda;
Customer
如果我们想要将公共的部分抽取出来,发现都比较零散,还不如不抽取,但是不抽取代码又存在大量重复的代码不符合我的风格。于是我便可以使用 Consumer 接口。
如下是个例子(参考的https://xie.infoq.cn/article/047263a6c694daa5d65295b25)
B b = this.baseMapper.selectOne(queryWrapper);
if (b != null) {
String status = b.getStatus();
if (Objects.equals(Constants.STATUS_ING, status)){
return "处理中";
} else if (Objects.equals(Constants.STATUS_SUCCESS, status)){
return "处理成功";
}
//失败的操作
//请求第三方接口并解析响应结果
......
if (ReturnInfoEnum.SUCCESS.getCode().equals(parse.getCode())) {
......
//更新B表操作
bb.setStatus(Constants.STATUS_ING);
mapper.updateById(bb);
//更新A表的状态
a.setStatus(Constants.STATUS_ING);
aMapper.updateById(a);
}
} else {
//请求第三方接口并解析响应结果
......
if (ReturnInfoEnum.SUCCESS.getCode().equals(parse.getCode())) {
......
//插入B表操作
bb.setStatus(Constants.STATUS_ING);
mapper.insert(bb);
//更新A表的状态
a.setStatus(Constants.STATUS_ING);
aMapper.updateById(a);
}
}
这个方法若使用普通的方法抽象就比较费劲,那么用Customer就可以抽象为如下的样子
B b = this.baseMapper.selectOne(queryWrapper);
if (b != null) {
String status = b.getStatus();
if (Objects.equals(Constants.STATUS_ING, status)){
return "处理中";
} else if (Objects.equals(Constants.STATUS_SUCCESS, status)){
return "处理成功";
}
//失败的操作
getResponse(dto, response, s -> mapper.insert(s));
} else {
getResponse(dto, response, s -> mapper.updateById(s));
}
public void getResponse(DTO dto, Response response, Consumer<B> consumer){
//请求第三方接口并解析响应结果
......
if (ReturnInfoEnum.SUCCESS.getCode().equals(parse.getCode())) {
......
bb.setStatus(Constants.STATUS_ING);
consumer.accept(bb);
//更新A表的状态
a.setStatus(Constants.STATUS_ING);
aMapper.updateById(a);
}
}
这样抽象之后,代码就很简洁,而且易读性强。
Supplier若在业务中使用其实就是在对象工厂中使用,但是感觉多此一举,Supplier真正的用武之地是对一个复杂操作返回结果进行包装。Predicate也是同样。
函数式编程在Stream中的应用
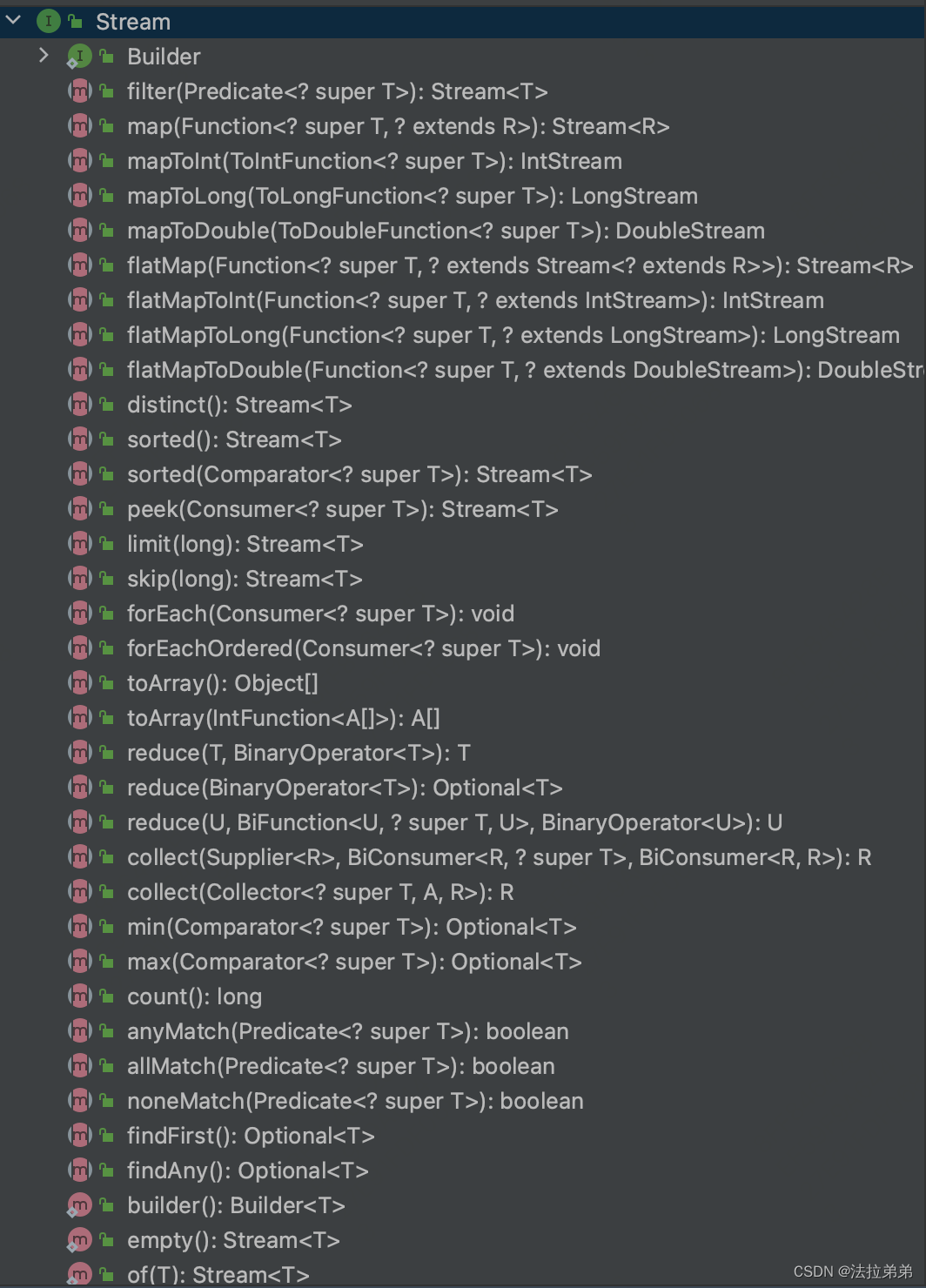
以上是Stream的api,可以看到,api的入参大量使用了函数式编程。其中,这些操作可以分为两类:中间操作(Intermediate Operations)和终止操作(Terminal Operations)。 中间操作是对 Stream 进行转换的操作,它们返回一个新的 Stream。以下对一些常见的中间操作进行解释:
filter(Predicate):过滤 Stream 中满足条件的元素
map(Function<T, R>):将 Stream 中的元素转换为另一种类型
flatMap(Function<T, Stream>):将 Stream 中的元素转换为其他 Stream,然后将这些 Stream 合并为一个 Stream
distinct():去除 Stream 中的重复元素
sorted():对 Stream 中的元素进行排序,可以传入自定义的 Comparator终止操作是对 Stream 进行最终处理的操作,它们返回一个结果或产生一个副作用。以下是一些常见的终止操作:
forEach(Consumer):对 Stream 中的每个元素执行操作
toArray():将 Stream 转换为数组
reduce(BinaryOperator):将 Stream 中的元素进行归约操作,如求和、求积等
collect(Collector<T, A, R>):将 Stream 转换为其他数据结构,如 List、Set、Map 等
min(Comparator) 和 max(Comparator):求 Stream 中的最小值和最大值
count():计算 Stream 中的元素个数
anyMatch(Predicate)、 allMatch(Predicate)和 noneMatch(Predicate):测试 Stream 中的元素是否满足条件
总结
总之,函数式编程应该用在抽象层次高、复用多的场景,而不是单纯业务逻辑的简单使用,所以使用之前也需要考虑代码的可维护性,不要为了使用而使用。
参考资料
https://segmentfault.com/a/1190000023747150?u_atoken=32fee544-f7cd-4df8-91ce-47d87de22668&u_asession=01BkaeBGWvPsHgIxJuFpnoNGPxJQJySVIG_gUH0Zhzyl3BspF4RLjnbbfCiqcVJce3Q_ZsrrQOL_dSA1zPPreegtsq8AL43dpOnCClYrgFm6o&u_asig=05Y3_7uvSQPfeIm07fP1vQdsj7FudfwePFM1eZA8ckEX67ToyquOZSHt9Eq1dLJNVc2ZcteDCchFNXGVEWv7Bg9exkOToHgrvdg9F4V3tl_h37OAllOeO5m6VUw3FfBfuvCzxkbE7J_MY1C7r2si7g5w-u3Ek8VtswbP6brvtqZqAsaf4GixaBYwLCG6zwc6qqksmHjM0JOodanL5-M1Qs1VR0BeJHCUjPk5wHVLCzDY_-BDXafsOvV_V2XawGnXUfPxqotRqV_sByrLqI5UuuDXcloE9fupmv8OEkmKJFEyPUpLHxH1iRKZmnjAu0Zefw&u_aref=hlmwq%2BeFAhcbCWMBRwoz8hv0WME%3D
https://xie.infoq.cn/article/047263a6c694daa5d65295b25
https://blog.51cto.com/u_16213587/7346422
https://zhuanlan.zhihu.com/p/629299261
https://mp.weixin.qq.com/s?__biz=MzUzMTA2NTU2Ng%3D%3D&chksm=fa4a5cf5cd3dd5e312c496bc67b600c4234d48f068d4b94c1924c9f5aee59b51466302ec4301&idx=2&mid=2247541572&scene=27&sn=1384374f96a83de90fc2d9625bce7707&utm_campaign=geek_search&utm_content=geek_search&utm_medium=geek_search&utm_source=geek_search&utm_term=geek_search#wechat_redirect
https://pdai.tech/md/develop/refactor/dev-refactor-if-else.html