二十四、三向比较(C++20)
1. “太空飞船”(spaceship)运算符
C++20标准新引入了一个名为“太空飞船”(spaceship)的运算符 <=>,它是一个三向比较运算符。<=> 之所以被称为“太空飞船”运算符是因为 <=> 让著名的Perl语言专家兰德尔·L.施瓦茨想起1971年的一款电子游戏《星际迷航》中的太空飞船。读者应该也看出来了,<=> 并不是 C++20首创的,实际上Perl、PHP、Ruby等语言早已支持了三向比较运算符,C++是后来的学习者。
顾名思义,三向比较就是在形如 lhs <=> rhs 的表达式中,两个比较的操作数 lhs 和 rhs 通过 <=> 比较可能产生3种结果,该结果可以和0比较,小于0、等于0或者大于0分别对应 lhs < rhs、lhs == rhs 和 lhs > rhs。举例来说:
bool b = 7 <=> 11 < 0; // b == true
请注意,运算符<=>的返回值只能与0和自身类型来比较,如果同其他数值比较,编译器会报错:
bool b = 7 <=> 11 < 100; // 编译失败,<=> 的结果不能与除 0 以外的数值比较
2. 三向比较的返回类型
可以看出 <=> 的返回结果并不是一个普通类型,根据标准三向比较会返回3种类型,分别为 std::strong_ordering、std::weak_ordering 以及 std::partial_ordering,而这3种类型又会分为有3~4种最终结果,下面就来一一介绍它们。
1. std::strong_ordering
std::strong_ordering 类型有3种比较结果,分别为 std::strong_ordering::less、std::strong_ordering::equal 以及 std::strong_ordering::greater。表达式 lhs <=> rhs 分别表示 lhs < rhs、lhs == rhs 以及 lhs > rhs。std::strong_ordering 类型的结果强调的是 strong 的含义,表达的是一种可替换性,简单来说,若 lhs == rhs,那么在任何情况下 rhs 和 lhs 都可以相互替换,也就是 fx(lhs) == fx(rhs)。
对于基本类型中的int类型,三向比较返回的是std::strong_ordering,例如:
std::cout << typeid(decltype(7 <=> 11)).name();
用MSVC编译运行以上代码,会在输出窗口显示 class std::strong_ordering,刻意使用 MSVC 是因为它的 typeid(x).name() 可以输出友好可读的类型名称。对于有复杂结构的类型,std::strong_ordering 要求其数据成员和基类的三向比较结果都为 std::strong_ordering。例如:
#include <compare>
struct B
{
int a;
long b;
auto operator <=> (const B&) const = default;
};
struct D : B
{
short c;
auto operator <=> (const D&) const = default;
};
D x1, x2;
std::cout << typeid(decltype(x1 <=> x2)).name();
上面这段代码用 MSVC 编译运行会输出 class std::strong_ordering。请注意,默认情况下自定义类型是不存在三向比较运算符函数的,需要用户显式默认声明,比如在结构体 B 和 D 中声明 auto operator <=> (const B&) const = default; 和 auto operator <=> (const D&) const = default;。对结构体 B 而言,由于 int 和 long 的比较结果都是 std::strong_ordering,因此结构体 B 的三向比较结果也是 std::strong_ordering。同理,对于结构体 D,其基类和成员的比较结果是 std::strong_ordering,D 的三向比较结果同样是 std::strong_ordering。另外,明确运算符的返回类型,使用 std::strong_ordering 替换 auto 也是没问题的。
2. std::weak_ordering
std::weak_ordering 类型也有3种比较结果,分别为 std::weak_ordering::less、std::weak_ordering::equivalent 以及 std::weak_ordering::greater。std::weak_ordering 的含义正好与 std::strong_ordering 相对,表达的是不可替换性。即若有 lhs == rhs,则 rhs 和 lhs 不可以相互替换,也就是 fx(lhs) != fx(rhs)。这种情况在基础类型中并没有,但是它常常发生在用户自定义类中,比如一个大小写不敏感的字符串类:
#include <compare>
#include <string>
#include <iostream>
int ci_compare(const char* s1, const char* s2)
{
while (tolower(*s1) == tolower(*s2++)) {
if (*s1++ == '\0') {
return 0;
}
}
return tolower(*s1) - tolower(*--s2);
}
class CIString {
public:
CIString(const char *s) : str_(s) {}
std::weak_ordering operator<=>(const CIString& b) const {
return ci_compare(str_.c_str(), b.str_.c_str()) <=> 0;
}
private:
std::string str_;
};
int main()
{
CIString s1{ "HELLO" }, s2{"hello"};
std::cout << (s1 <=> s2 == 0); // 输出为true
}
以上代码实现了一个简单的大小写不敏感的字符串类,它对于 s1 和 s2 的比较结果是 std::weak_ordering::equivalent,表示两个操作数是等价的,但是它们不是相等的也不能相互替换。
当 std::weak_ordering 和 std::strong_ordering 同时出现在基类和数据成员的类型中时,该类型的三向比较结果是 std::weak_ordering,例如:
struct D : B
{
CIString c{""};
auto operator <=> (const D&) const = default;
};
D w1, w2;
std::cout << typeid(decltype(w1 <=> w2)).name();
用 MSVC 编译运行上面这段代码会输出 class std::weak_ordering,因为 D 中的数据成员 CIString 的三向比较结果为 std::weak_ordering。请注意,如果显式声明默认三向比较运算符函数为 std::strong_ordering operator <=> (const D&) const = default;,那么一定会遭遇到一个编译错误。
3. std::partial_ordering
std::partial_ordering 类型有4种比较结果,分别为 std::partial_ordering::less、std::partial_ordering::equivalent、std::partial_ordering::greater 以及 std::partial_ordering::unordered。std::partial_ordering 约束力比 std::weak_ordering 更弱,它可以接受当 lhs == rhs 时 rhs 和 lhs 不能相互替换,同时它还能给出第四个结果 std::partial_ordering::unordered,表示进行比较的两个操作数没有关系。比如基础类型中的浮点数:
std::cout << typeid(decltype(7.7 <=> 11.1)).name();
用 MSVC 编译运行以上代码会输出 class std::partial_ordering。之所以会输出 class std::partial_ordering 而不是 std::strong_ordering,是因为浮点的集合中存在一个特殊的 NaN,它和其他浮点数值是没关系的:
std::cout << ((0.0 / 0.0 <=> 1.0) == std::partial_ordering::unordered);
这段代码编译输出的结果为 true。当 std::weak_ordering 和 std::partial_ordering 同时出现在基类和数据成员的类型中时,该类型的三向比较结果是 std::partial_ordering,例如:
struct D : B
{
CIString c{""};
float u;
auto operator <=> (const D&) const = default;
};
D w1, w2;
std::cout << typeid(decltype(w1 <=> w2)).name();
用 MSVC 编译运行以上代码会输出 class std::partial_ordering,因为 D 中的数据成员 u 的三向比较结果为 std::partial_ordering。同样,显式声明为其他返回类型也会让编译器报错。
在 C++20 的标准库中有一个模板元函数 std::common_comparison_category,它可以帮助我们在一个类型合集中判断出最终三向比较的结果类型。当类型合集中存在不支持三向比较的类型时,该模板元函数返回 void。
再次强调一下,std::strong_ordering、std::weak_ordering 和 std::partial_ordering 只能与 0 和类型自身比较。深究其原因,是这3个类只实现了参数类型为自身类型和 nullptr_t 的比较运算符函数。
3. 对基础类型的支持
-
对两个算术类型的操作数进行一般算术转换,然后进行比较。其中整型的比较结果为
std::strong_ordering,浮点型的比较结果为std::partial_ordering。例如7 <=> 11.1中,整型7会转换为浮点类型,然后再进行比较,最终结果为std::partial_ordering类型。 -
对于无作用域枚举类型和整型操作数,枚举类型会转换为整型再进行比较,无作用域枚举类型无法与浮点类型比较:
enum color {
red
};
auto r = red <=> 11; //编译成功
auto r = red <=> 11.1; //编译失败
- 对两个相同枚举类型的操作数比较结果,如果枚举类型不同,则无法编译。
- 对于其中一个操作数为
bool类型的情况,另一个操作数必须也是bool类型,否则无法编译。比较结果为std::strong_ordering。 - 不支持作比较的两个操作数为数组的情况,会导致编译出错,例如:
int arr1[5];
int arr2[5];
auto r = arr1 <=> arr2; // 编译失败
- 对于其中一个操作数为指针类型的情况,需要另一个操作数是同样类型的指针,或者是可以转换为相同类型的指针,比如数组到指针的转换、派生类指针到基类指针的转换等,最终比较结果为
std::strong_ordering:
char arr1[5];
char arr2[5];
char* ptr = arr2;
auto r = ptr <=> arr1;
上面的代码可以编译成功。若将代码中的 arr1 改写为 int arr1[5],则无法编译,因为 int [5] 无法转换为 char *。如果将 char * ptr = arr2; 修改为 void * ptr = arr2;,代码就可以编译成功了。
4. 自动生成的比较运算符函数
标准库中提供了一个名为 std::rel_ops 的命名空间,在用户自定义类型已经提供了 == 运算符函数和 < 运算符函数的情况下,帮助用户实现其他4种运算符函数,包括 !=、>、<= 和 >=,例如:
#include <string>
#include <utility>
class CIString2 {
public:
CIString2(const char* s) : str_(s) {}
bool operator < (const CIString2& b) const {
return ci_compare(str_.c_str(), b.str_.c_str()) < 0;
}
private:
std::string str_;
};
using namespace std::rel_ops;
CIString2 s1{ "hello" }, s2{ "world" };
bool r = s1 >= s2;
不过因为 C++20 标准有了三向比较运算符的关系,所以不推荐上面这种做法了。C++20 标准规定,如果用户为自定义类型声明了三向比较运算符,那么编译器会为其自动生成 <、>、<= 和 >= 这4种运算符函数。对于 CIString 我们可以直接使用这4种运算符函数:
CIString s1{ "hello" }, s2{ "world" };
bool r = s1 >= s2;
那么这里就会产生一个疑问,很明显三向比较运算符能表达两个操作数是相等或者等价的含义,为什么标准只允许自动生成4种运算符函数,却不能自动生成 == 和 != 这两个运算符函数呢?实际上这里存在一个严重的性能问题。在 C++20 标准拟定三向比较的早期,是允许通过三向比较自动生成6个比较运算符函数的,而三向比较的结果类型也不是3种而是5种,多出来的两种分别是 std::strong_equality 和 std::weak_equality。但是在提案文档 p1190 中提出了一个严重的性能问题。简单来说,假设有一个结构体:
struct S {
std::vector<std::string> names;
auto operator<=>(const S &) const = default;
};
它的三向比较运算符的默认实现这样的:
template<typename T>
std::strong_ordering operator<=>(const std::vector<T>& lhs, const std::vector<T> & rhs)
{
size_t min_size = min(lhs.size(), rhs.size());
for (size_t i = 0; i != min_size; ++i) {
if (auto const cmp = std::compare_3way(lhs[i], rhs[i]); cmp != 0)
{
return cmp;
}
}
return lhs.size() <=> rhs.size();
}
这个实现对于 < 和 > 这样的运算符函数没有问题,因为需要比较容器中的每个元素。但是 == 运算符就显得十分低效,对于 == 运算符高效的做法是先比较容器中的元素数量是否相等,如果元素数量不同,则直接返回 false:
template<typename T>
bool operator==(const std::vector<T>& lhs, const std::vector<T>& rhs)
{
const size_t size = lhs.size();
if (size != rhs.size()) {
return false;
}
for (size_t i = 0; i != size; ++i) {
if (lhs[i] != rhs[i]) {
return false;
}
}
return true;
}
想象一下,如果标准允许用三向比较的算法自动生成 == 运算符函数会发生什么事情,很多旧代码升级编译环境后会发现运行效率下降了,尤其是在容器中元素数量众多且每个元素数据量庞大的情况下。很少有程序员会注意到三向比较算法的细节,导致这个性能问题难以排查。
基于这种考虑,C++ 委员会修改了原来的三向比较提案,规定声明三向比较运算符函数只能够自动生成4种比较运算符函数。由于不需要负责判断是否相等,因此 std::strong_equality 和 std::weak_equality 也退出了历史舞台。对于 == 和 != 两种比较运算符函数,只需要多声明一个 == 运算符函数,!= 运算符函数会根据前者自动生成:
class CIString {
public:
CIString(const char* s) : str_(s) {}
std::weak_ordering operator<=>(const CIString& b) const {
return ci_compare(str_.c_str(), b.str_.c_str()) <=> 0;
}
bool operator == (const CIString& b) const {
return ci_compare(str_.c_str(), b.str_.c_str()) == 0;
}
private:
std::string str_;
};
CIString s1{ "hello" }, s2{ "world" };
bool r1 = s1 >= s2; // 调用operator<=>
bool r2 = s1 == s2; // 调用operator ==
5. 兼容旧代码
现在 C++20 标准已经推荐使用 <=> 和 == 运算符自动生成其他比较运算符函数,而使用 <、== 以及 std::rel_ops 生成其他比较运算符函数则会因为 std::rel_ops 已经不被推荐使用而被编译器警告。
那么对于老代码,我们是否需要去实现一套 <=> 和 == 运算符函数呢?其实大可不必,C++ 委员会在裁决这项修改的时候已经考虑到老代码的维护成本,所以做了兼容性处理,即在用户自定义类型中,实现了 <、== 运算符函数的数据成员类型,在该类型的三向比较中将自动生成合适的比较代码。比如:
#include <compare>
#include <iostream>
struct Legacy {
int n;
bool operator==(const Legacy& rhs) const
{
return n == rhs.n;
}
bool operator<(const Legacy& rhs) const
{
return n < rhs.n;
}
};
struct TreeWay {
Legacy m;
std::strong_ordering operator<=>(const TreeWay &) const = default;
};
int main()
{
TreeWay t1, t2;
bool r = t1 < t2;
}
在上面的代码中,结构体 TreeWay 的三向比较操作会调用结构体 Legacy 中的 < 和 == 运算符来完成,其代码类似于:
struct TreeWay {
Legacy m;
std::strong_ordering operator<=>(const TreeWay& rhs) const {
if (m < rhs.m) return std::strong_ordering::less;
if (m == rhs.m) return std::strong_ordering::equal;
return std::strong_ordering::greater;
}
};
需要注意的是,这里 operator<=> 必须显式声明返回类型为 std::strong_ordering,使用 auto 是无法通过编译的。
总结
本章介绍了 C++20 新增的三向比较特性,该特性的引入为实现比较运算提供了方便。我们只需要实现 == 和 <=> 两个运算符函数,剩下的4个运算符函数就可以交给编译器自动生成了。虽说 std::rel_ops 在实现了 == 和 < 两个运算符函数以后也能自动提供剩下的4个运算符函数,但显然用三向比较更加便捷。另外,三向比较提供的3种结果类型也是 std::rel_ops 无法媲美的。进一步来说,由于三向比较的出现,std::rel_ops 在 C++20 中已经不被推荐使用了。最后,C++ 委员会没有忘记兼容性问题,这让三向比较能够通过运算符函数 < 和 == 来自动生成。
二十五、线程局部存储(C++11)
1. 操作系统和编译器对线程局部存储的支持
线程局部存储是指对象内存在线程开始后分配,线程结束时回收且每个线程有该对象自己的实例,简单地说,线程局部存储的对象都是独立于各个线程的。实际上,这并不是一个新鲜的概念,虽然 C++ 一直没有在语言层面支持它,但是很早之前操作系统就有办法支持线程局部存储了。
由于线程本身是操作系统中的概念,因此线程局部存储这个功能是离不开操作系统支持的。而不同的操作系统对线程局部存储的实现也不同,以至于使用的系统 API 也有区别,这里主要以 Windows 和 Linux 为例介绍它们使用线程局部存储的方法。
在 Windows 中可以通过调用 API 函数 TlsAlloc 来分配一个未使用的线程局部存储槽索引(TLS slot index),这个索引实际上是 Windows 内部线程环境块(TEB)中线程局部存储数组的索引。通过 API 函数 TlsGetValue 与 TlsSetValue 可以获取和设置线程局部存储数组对应于索引元素的值。API 函数 TlsFree 用于释放线程局部存储槽索引。
Linux 使用了 pthreads(POSIX threads)作为线程接口,在 pthreads 中我们可以调用 pthread_key_create 与 pthread_key_delete 创建与删除一个类型为 pthread_key_t 的键。利用这个键可以使用 pthread_setspecific 函数设置线程相关的内存数据,当然,我们随后还能够通过 pthread_getspecific 函数获取之前设置的内存数据。
在 C++11 标准确定之前,各个编译器也用了自定义的方法支持线程局部存储。比如 gcc 和 clang 添加了关键字 __thread 来声明线程局部存储变量,而 Visual Studio C++ 则是使用 __declspec(thread)。虽然它们都有各自的方法声明线程局部存储变量,但是其使用范围和规则却存在一些区别,这种情况增加了 C++ 的学习成本,也是 C++ 标准委员会不愿意看到的。于是在 C++11 标准中正式添加了新的 thread_local 说明符来声明线程局部存储变量。
2. thread_local 说明符
thread_local 说明符可以用来声明线程生命周期的对象,它能与 static 或 extern 结合,分别指定内部或外部链接,不过额外的 static 并不影响对象的生命周期。换句话说,static 并不影响其线程局部存储的属性:
struct X {
thread_local static int i;
};
thread_local X a;
int main()
{
thread_local X b;
}
从上面的代码可以看出,声明一个线程局部存储变量相当简单,只需要在普通变量声明上添加 thread_local 说明符。被 thread_local 声明的变量在行为上非常像静态变量,只不过多了线程属性,当然这也是线程局部存储能出现在我们的视野中的一个关键原因,它能够解决全局变量或者静态变量在多线程操作中存在的问题,一个典型的例子就是 errno。
errno 通常用于存储程序当中上一次发生的错误,早期它是一个静态变量,由于当时大多数程序是单线程的,因此没有任何问题。但是到了多线程时代,这种 errno 就不能满足需求了。设想一下,一个多线程程序的线程A在某个时刻刚刚调用过一个函数,正准备获取其错误码,也正是这个时刻,另外一个线程B在执行了某个函数后修改了这个错误码,那么线程A接下来获取的错误码自然不会是它真正想要的那个。这种线程间的竞争关系破坏了 errno 的准确性,导致不可确定的结果。为了规避由此产生的不确定性,POSIX 将 errno 重新定义为线程独立的变量,为了实现这个定义就需要用到线程局部存储,直到 C++11 之前,errno 都是一个静态变量,而从 C++11 开始 errno 被修改为一个线程局部存储变量。
在了解了线程局部存储的意义之后,让我们回头仔细阅读其定义,会发现线程局部存储只是定义了对象的生命周期,而没有定义可访问性。也就是说,我们可以获取线程局部存储变量的地址并将其传递给其他线程,并且其他线程可以在其生命周期内自由使用变量。不过这样做除了用于诊断功能以外没有实际意义,而且其危险性过大,一旦没有掌握好目标线程的声明周期,就很可能导致内存访问异常,造成未定义的程序行为,通常情况下是程序崩溃。
值得注意的是,使用取地址运算符 & 取到的线程局部存储变量的地址是运行时被计算出来的,它不是一个常量,也就是说无法和 constexpr 结合:
static int sv;
thread_local int tv;
int main()
{
constexpr int *sp = &sv; // 编译成功,sv的地址在编译时确定
constexpr int *tp = &tv; // 编译失败,tv的地址在运行时确定
}
在上面的代码中,由于 sv 是一个静态变量,因此在编译时可以获取其内存常量地址,并赋值到常量表达式 sp。但是 tv 则不同,它在线程创建时才可能确定内存地址,所以这里会产生编译错误。
最后来说明一下线程局部存储对象的初始化和销毁。在同一个线程中,一个线程局部存储对象只会初始化一次,即使在某个函数中被多次调用。这一点和单线程程序中的静态对象非常相似。相对应的,对象的销毁也只会发生一次,通常发生在线程退出的时刻。下面来看一个例子:
#include <iostream>
#include <string>
#include <thread>
#include <mutex>
std::mutex g_out_lock;
struct RefCount {
RefCount(const char* f) : i(0), func(f) {
std::lock_guard<std::mutex> lock(g_out_lock);
std::cout << std::this_thread::get_id()
<< "|" << func
<< " : ctor i(" << i << ")" << std::endl;
}
~RefCount() {
std::lock_guard<std::mutex> lock(g_out_lock);
std::cout << std::this_thread::get_id()
<< "|" << func
<< " : dtor i(" << i << ")" << std::endl;
}
void inc()
{
std::lock_guard<std::mutex> lock(g_out_lock);
std::cout << std::this_thread::get_id()
<< "|" << func
<< " : ref count add 1 to i(" << i << ")" << std::endl;
i++;
}
int i;
std::string func;
};
RefCount *lp_ptr = nullptr;
void foo(const char* f)
{
std::string func(f);
thread_local RefCount tv(func.append("#foo").c_str());
tv.inc();
}
void bar(const char* f)
{
std::string func(f);
thread_local RefCount tv(func.append("#bar").c_str());
tv.inc();
}
void threadfunc1()
{
const char* func = "threadfunc1";
foo(func);
foo(func);
foo(func);
}
void threadfunc2()
{
const char* func = "threadfunc2";
foo(func);
foo(func);
foo(func);
}
void threadfunc3()
{
const char* func = "threadfunc3";
foo(func);
bar(func);
bar(func);
}
int main()
{
std::thread t1(threadfunc1);
std::thread t2(threadfunc2);
std::thread t3(threadfunc3);
t1.join();
t2.join();
t3.join();
}
上面的代码并发3个工作线程,前两个线程 threadfunc1 和 threadfunc2 分别调用了3次 foo 函数。而第三个线程 threadfunc3 调用了1次 foo 函数和2次 bar 函数。其中 foo 和 bar 函数的功能相似,它们分别声明并初始化了一个线程局部存储对象 tv,并调用其自增函数 inc,而 inc 函数会递增对象成员变量 i。为了保证输出的日志不会受到线程竞争的干扰,在输出之前加了互斥锁。下面是在Windows上的运行结果:
27300|threadfunc1#foo : ctor i(0)
27300|threadfunc1#foo : ref count add 1 to i(0)
27300|threadfunc1#foo : ref count add 1 to i(1)
27300|threadfunc1#foo : ref count add 1 to i(2)
25308|threadfunc3#foo : ctor i(0)
25308|threadfunc3#foo : ref count add 1 to i(0)
25308|threadfunc3#bar : ctor i(0)
25308|threadfunc3#bar : ref count add 1 to i(0)
25308|threadfunc3#bar : ref count add 1 to i(1)
10272|threadfunc2#foo : ctor i(0)
10272|threadfunc2#foo : ref count add 1 to i(0)
10272|threadfunc2#foo : ref count add 1 to i(1)
10272|threadfunc2#foo : ref count add 1 to i(2)
27300|threadfunc1#foo : dtor i(3)
25308|threadfunc3#bar : dtor i(2)
25308|threadfunc3#foo : dtor i(1)
10272|threadfunc2#foo : dtor i(3)
从结果可以看出,线程 threadfunc1 和 threadfunc2 分别只调用了一次构造和析构函数,而且引用计数的递增也不会互相干扰,也就是说两个线程中线程局部存储对象是独立存在的。对于线程 threadfunc3,它进行了两次线程局部存储对象的构造和析构,这两次分别对应 foo 和 bar 函数里的线程局部存储对象 tv。可以发现,虽然这两个对象具有相同的对象名,但是由于不在同一个函数中,因此也应该认为是相同线程中不同的线程局部存储对象,它们的引用计数的递增同样不会相互干扰。
总结
多线程已经成为现代程序应用中不可缺少的技术环节,但是在 C++11 标准出现之前,C++ 语言标准对多线程的支持是不完善的,无法创建线程局部存储对象就是其中的一个缺陷。幸好 C++11 的推出挽救了这种尴尬的局面。本章中介绍的 thread_local 说明符终于让 C++ 在语言层面统一了声明线程局部存储对象的方法。当然,想要透彻地理解线程局部存储,只是学习 thread_local 说明符的内容是不够的,还需要深入操作系统层面,探究系统处理线程局部存储的方法。
二十六、扩展的 inline 说明符(C++17)
1. 定义非常量静态成员变量的问题
在C++17标准之前,定义类的非常量静态成员变量是一件让人头痛的事情,因为变量的声明和定义必须分开进行,比如:
#include <iostream>
#include <string>
class X {
public:
static std::string text;
};
std::string X::text{ "hello" };
int main()
{
X::text += " world";
std::cout << X::text << std::endl;
}
在这里 static std::string text 是静态成员变量的声明,std::string X::text{ "hello" } 是静态成员变量的定义和初始化。为了保证代码能够顺利地编译,我们必须保证静态成员变量的定义有且只有一份,稍有不慎就会引发错误,比较常见的错误是为了方便将静态成员变量的定义放在头文件中:
#ifndef X_H
#define X_H
class X {
public:
static std::string text;
};
std::string X::text{ "hello" };
#endif
将上面的代码包含到多个 CPP 文件中会引发一个链接错误,因为 include 是单纯的宏替换,所以会存在多份 X::text 的定义导致链接失败。对于一些字面量类型,比如整型、浮点类型等,这种情况有所缓解,至少对于它们而言常量静态成员变量是可以一边声明一边定义的:
#include <iostream>
#include <string>
class X {
public:
static const int num{ 5 };
};
int main()
{
std::cout << X::num << std::endl;
}
不过有得有失,虽然常量性能让它们方便地声明和定义,但却丢失了修改变量的能力。对于std::string这种非字面量类型,这种方法是无能为力的。
2. 使用 inline 说明符
为了解决上面这些问题,C++17标准中增强了inline说明符的能力,它允许我们内联定义静态变量,例如:
#include <iostream>
#include <string>
class X {
public:
inline static std::string text{"hello"};
};
int main()
{
X::text += " world";
std::cout << X::text << std::endl;
}
上面的代码可以成功编译和运行,而且即使将类X的定义作为头文件包含在多个CPP中也不会有任何问题。在这种情况下,编译器会在类X的定义首次出现时对内联静态成员变量进行定义和初始化。
总结
本章介绍的 inline 说明符的扩展特性解决了 C++ 中定义静态成员变量烦琐且容易出错的问题,它让编译器能够聪明地选择首次出现的变量进行定义和初始化。这种能力也正是 inline 说明符的提案文档中的第一段话所提到的:“inline 说明符可以应用于变量以及函数。声明为 inline 的变量与函数具有相同的语义:它们一方面可以在多个翻译单元中定义,另一方面又必须在每个使用它们的翻译单元中定义,并且程序的行为就像是同一个变量。”
二十七、常量表达式(C++11~C++20)
1. 常量的不确定性
在C++11标准以前,我们没有一种方法能够有效地要求一个变量或者函数在编译阶段就计算出结果。由于无法确保在编译阶段得出结果,导致很多看起来合理的代码却引来编译错误。这些场景主要集中在需要编译阶段就确定的值语法中,比如case语句、数组长度、枚举成员的值以及非类型的模板参数。让我们先看一看这些场景的代码:
const int index0 = 0;
#define index1 1
// case语句
int argc = 1;
switch (argc) {
case index0:
std::cout << "index0" << std::endl;
break;
case index1:
std::cout << "index1" << std::endl;
break;
default:
std::cout << "none" << std::endl;
}
const int x_size = 5 + 8;
#define y_size 6 + 7
// 数组长度
char buffer[x_size][y_size] = { 0 };
// 枚举成员
enum {
enum_index0 = index0,
enum_index1 = index1
};
std::tuple<int, char> tp = std::make_tuple(4, '3');
// 非类型的模板参数
int x1 = std::get<index0>(tp);
char x2 = std::get<index1>(tp);
在上面的代码中,const定义的常量和宏都能在要求编译阶段确定值的语句中使用。其中宏在编译之前的预处理阶段就被替换为定义的文字。而对于const定义的常量,上面这种情况下编译器能在编译阶段确定它们的值,并在case语句以及数组长度等语句中使用。
让人遗憾的是上面这些方法并不可靠。首先,C++程序员应该尽量少使用宏,因为预处理器对于宏只是简单的字符替换,完全没有类型检查,而且宏使用不当出现的错误难以排查。其次,对const定义的常量可能是一个运行时常量,这种情况下是无法在case语句以及数组长度等语句中使用的。
让我们稍微修改一下上面的代码:
int get_index0()
{
return 0;
}
int get_index1()
{
return 1;
}
int get_x_size()
{
return 5 + 8;
}
int get_y_size()
{
return 6 + 7;
}
const int index0 = get_index0();
#define index1 get_index1()
switch (argc)
{
case index0:
std::cout << "index0" << std::endl;
break;
case index1:
std::cout << "index1" << std::endl;
break;
default:
std::cout << "none" << std::endl;
}
const int x_size = get_x_size();
#define y_size get_y_size()
char buffer[x_size][y_size] = { 0 };
enum {
enum_index0 = index0,
enum_index1 = index1,
};
std::tuple<int, char> tp = std::make_tuple(4, '3');
int x1 = std::get<index0>(tp);
char x2 = std::get<index1>(tp);
我们这里做的修改仅仅是将宏定义为一个函数调用以及用一个函数将const变量进行初始化,但是编译这段代码时会发现已经无法通过编译了。因为,无论是宏定义的函数调用,还是通过函数返回值初始化const变量都是在运行时确定的。
像上面这种尴尬的情况不仅可能出现在我们的代码中,实际上标准库中也有这样的情况,其中<limits>就是一个典型的例子。在C语言中存在头文件<limits.h>,在这个头文件中用宏定义了各种整型类型的最大值和最小值,比如:
#define UCHAR_MAX 0xff // unsigned char类型的最大值
我们可以用这些宏代替数字,让代码有更好的可读性。这其中就包括要求编译阶段必须确定值的语句,例如定义一个数组:
char buffer[UCHAR_MAX] = { 0 };
代码编译起来没有任何障碍。但是正如上文中提到的,C++程序员应该尽量避开宏。标准库为我们提供了一个<limits>,使用它同样能获得unsigned char类型的最大值:
std::numeric_limits<unsigned char>::max()
但是,如果想用它来声明数组的大小是无法编译成功的:
char buffer[std::numeric_limits<unsigned char>::max()] = {0};
原因和之前讨论过的一样,std::numeric_limits<unsigned char>::max()函数的返回值必须在运行时计算。
为了解决以上常量无法确定的问题,C++标准委员会决定在C++11标准中定义一个新的关键字constexpr,它能够有效地定义常量表达式,并且达到类型安全、可移植、方便库和嵌入式系统开发的目的。
2. constexpr 值
constexpr值即常量表达式值,是一个用constexpr说明符声明的变量或者数据成员,它要求该值必须在编译期计算。另外,常量表达式值必须被常量表达式初始化。定义常量表达式值的方法非常简单,例如:
constexpr int x = 42;
char buffer[x] = { 0 };
以上代码定义了一个常量表达式值x,并将其初始化为42,然后用x作为数组长度定义了数组buffer。从这段代码来看,constexpr和const是没有区别的,我们将关键字替换为const同样能达到目的:
const int x = 42;
char buffer[x] = { 0 };
从结果来看确实如此,在使用常量表达式初始化的情况下constexpr和const拥有相同的作用。但是const并没有确保编译期常量的特性,所以在下面的代码中,它们会有不同的表现:
int x1 = 42;
const int x2 = x1; // 定义和初始化成功
char buffer[x2] = { 0 }; // 编译失败,x2无法作为数组长度
在上面这段代码中,虽然x2初始化编译成功,但是编译器并不一定把它作为一个编译期需要确定的值,所以在声明buffer的时候会编译错误。注意,这里我说的是不一定,因为并没有人规定编译期应该怎么处理这种情况。比如在GCC中,这段代码可以编译成功,但是MSVC和CLang则会编译失败。如果把const替换为constexpr,会有不同的情况发生:
int x1 = 42;
constexpr int x2 = x1; // 编译失败,x2无法用x1初始化
char buffer[x2] = { 0 };
修改后,编译器编译第二句代码的时候就会报错,因为常量表达式值必须由常量表达式初始化,而x1并不是常量,明确地违反了constexpr的规则,编译器自然就会报错。可以看出,constexpr是一个加强版的const,它不仅要求常量表达式是常量,并且要求是一个编译阶段就能够确定其值的常量。
3. constexpr 函数
constexpr不仅能用来定义常量表达式值,还能定义一个常量表达式函数,即constexpr函数,常量表达式函数的返回值可以在编译阶段就计算出来。不过在定义常量表示函数的时候,我们会遇到更多的约束规则(在C++14和后续的标准中对这些规则有所放宽)。
- 函数必须返回一个值,所以它的返回值类型不能是
void。 - 函数体必须只有一条语句:
return expr,其中expr必须也是一个常量表达式。如果函数有形参,则将形参替换到expr中后,expr仍然必须是一个常量表达式。 - 函数使用之前必须有定义。
- 函数必须用
constexpr声明。
让我们来看一看下面这个例子:
constexpr int max_unsigned_char()
{
return 0xff;
}
constexpr int square(int x)
{
return x * x;
}
constexpr int abs(int x)
{
return x > 0 ? x : -x;
}
int main()
{
char buffer1[max_unsigned_char()] = { 0 };
char buffer2[square(5)] = { 0 };
char buffer3[abs(-8)] = { 0 };
}
上面的代码定义了3个常量表达式函数,由于它们的返回值能够在编译期计算出来,因此可以直接将这些函数的返回值使用在数组长度的定义上。需要注意的是square和abs两个函数,它们接受一个形参x,当x确定为一个常量时(这里分别是5和−8),其常量表达式函数也就成立了。我们通过abs可以发现一个小技巧,由于标准规定函数体中只能有一个表达式return expr,因此是无法使用if语句的,幸运的是用条件表达式也能完成类似的效果。
接着让我们看一看反例:
constexpr void foo()
{
}
constexpr int next(int x)
{
return ++x;
}
int g()
{
return 42;
}
constexpr int f()
{
return g();
}
constexpr int max_unsigned_char2();
enum {
max_uchar = max_unsigned_char2()
}
constexpr int abs2(int x)
{
if (x > 0) {
return x;
} else {
return -x;
}
}
constexpr int sum(int x)
{
int result = 0;
while (x > 0)
{
result += x--;
}
return result;
}
以上constexpr函数都会编译失败。其中函数foo的返回值不能为void,next函数体中的++x和f中的g()都不是一个常量表达式,函数max_unsigned_char2只有声明没有定义,函数abs2和sum不能有多条语句。我们注意到abs2中if语句可以用条件表达式替换,可是sum函数这样的循环结构有办法替换为单语句吗?答案是可以的,我们可以使用递归来完成循环的操作,现在就来重写sum函数:
constexpr int sum(int x)
{
return x > 0 ? x + sum(x - 1) : 0;
}
以上函数比较容易理解,当x大于0时,将x和sum(x−1)相加,直到sum的参数为0。由于这里sum本身被声明为常量表达式函数,因此整个返回语句也是一个常量表达式,遵守了常量表达式的规则。于是我们能通过递归调用sum函数完成循环计算的任务。有趣的是,在刚开始提出常量表达式函数的时候,有些C++专家认为这种函数不应该支持递归调用,但是最终标准还是确定支持了递归调用。
需要强调一点的是,虽然常量表达式函数的返回值可以在编译期计算出来,但是这个行为并不是确定的。例如,当带形参的常量表达式函数接受了一个非常量实参时,常量表达式函数可能会退化为普通函数:
constexpr int square(int x)
{
return x * x;
}
int x = 5;
std::cout << square(x);
这里由于x不是一个常量,因此square的返回值也可能无法在编译期确定,但是它依然能成功编译运行,因为该函数退化成了一个普通函数。这种退化机制对于程序员来说是非常友好的,它意味着我们不用为了同时满足编译期和运行期计算而定义两个相似的函数。另外,这里也存在着不确定性,因为GCC依然能在编译阶段计算square的结果,但是MSVC和CLang则不行。
有了常量表达式函数的支持,C++标准对STL也做了一些改进,比如在<limits>中增加了constexpr声明,正因如此下面的代码也可以顺利编译成功了:
char buffer[std::numeric_limits<unsigned char>::max()] = { 0 };
4. constexpr 构造函数
constexpr可以声明基础类型从而获得常量表达式值,除此之外constexpr还能够声明用户自定义类型,例如:
struct X {
int x1;
};
constexpr X x = { 1 };
char buffer[x.x1] = { 0 };
class X {
public:
X() : x1(5) {}
int get() const
{
return x1;
}
private:
int x1;
};
constexpr X x; // 编译失败,X不是字面类型
char buffer[x.get()] = { 0 }; // 编译失败,x.get()无法在编译阶段计算
以上代码自定义了一个结构体X,并且使用constexpr声明和初始化了变量x。到目前为止一切顺利,不过有时候我们并不希望成员变量被暴露出来,于是修改了X的结构:
经过修改的代码不能通过编译了,因为constexpr说明符不能用来声明这样的自定义类型。解决上述问题的方法很简单,只需要用constexpr声明X类的构造函数,也就是声明一个常量表达式构造函数,当然这个构造函数也有一些规则需要遵循。
- 构造函数必须用
constexpr声明。 - 构造函数初始化列表中必须是常量表达式。
- 构造函数的函数体必须为空(这一点基于构造函数没有返回值,所以不存在
return expr)。
根据以上规则让我们改写类X:
class X {
public:
constexpr X() : x1(5) {}
constexpr X(int i) : x1(i) {}
constexpr int get() const
{
return x1;
}
private:
int x1;
};
constexpr X x;
char buffer[x.get()] = { 0 };
上面这段代码只是简单地给构造函数和get函数添加了constexpr说明符就可以编译成功,因为它们本身都符合常量表达式构造函数和常量表达式函数的要求,我们称这样的类为字面量类类型(literal class type)。其实代码中constexpr int get() const 的 const 有点多余,因为在C++11中,constexpr会自动给函数带上const属性。请注意,常量表达式构造函数拥有和常量表达式函数相同的退化特性,当它的实参不是常量表达式的时候,构造函数可以退化为普通构造函数,当然,这么做的前提是类型的声明对象不能为常量表达式值:
int i = 8;
constexpr X x(i); // 编译失败,不能使用constexpr声明
X y(i); // 编译成功
由于i不是一个常量,因此X的常量表达式构造函数退化为普通构造函数,这时对象x不能用constexpr声明,否则编译失败。
最后需要强调的是,使用constexpr声明自定义类型的变量,必须确保这个自定义类型的析构函数是平凡的,否则也是无法通过编译的。平凡析构函数必须满足下面3个条件:
- 自定义类型中不能有用户自定义的析构函数。
- 析构函数不能是虚函数。
- 基类和成员的析构函数必须都是平凡的。
5. 对浮点的支持
在constexpr说明符被引入之前,C++程序员经常使用enum hack来促使编译器在编译阶段计算常量表达式的值。但是因为enum只能操作整型,所以一直无法完成对于浮点类型的编译期计算。constexpr说明符则不同,它支持声明浮点类型的常量表达式值,而且标准还规定其精度必须至少和运行时的精度相同,例如:
constexpr double sum(double x)
{
return x > 0 ? x + sum(x - 1) : 0;
}
constexpr double x = sum(5);
6. C++14 标准对常量表达式函数的增强
C++11标准对常量表达式函数的要求可以说是非常的严格,这一点影响该特性的实用性。幸好这个问题在C++14中得到了非常巨大的改善,C++14标准对常量表达式函数的改进如下。
- 函数体允许声明变量,除了没有初始化、
static和thread_local变量。 - 函数允许出现
if和switch语句,不能使用go语句。 - 函数允许所有的循环语句,包括
for、while、do-while。 - 函数可以修改生命周期和常量表达式相同的对象。
- 函数的返回值可以声明为
void。 constexpr声明的成员函数不再具有const属性。
因为这些改进的发布,在C++11中无法成功编译的常量表达式函数,在C++14中可以编译成功了:
constexpr int abs(int x)
{
if (x > 0) {
return x;
} else {
return -x;
}
}
constexpr int sum(int x)
{
int result = 0;
while (x > 0)
{
result += x--;
}
return result;
}
char buffer1[sum(5)] = { 0 };
char buffer2[abs(-5)] = { 0 };
以上代码中的abs和sum函数相比于前面使用条件表达式和递归方法实现的函数更加容易阅读和理解了。看到这里读者是否会有一些兴奋,但是别急,后面还有好戏:
constexpr int next(int x)
{
return ++x;
}
char buffer[next(5)] = { 0 };
这里我们惊喜地发现,原来由于++x不是常量表达式,因此无法编译通过的问题也消失了,这就是基于第4点规则。需要强调的是,对于常量表达式函数的增强同样也会影响常量表达式构造函数:
#include <iostream>
class X {
public:
constexpr X() : x1(5) {}
constexpr X(int i) : x1(0)
{
if (i > 0) {
x1 = 5;
}
else {
x1 = 8;
}
}
constexpr void set(int i)
{
x1 = i;
}
constexpr int get() const
{
return x1;
}
private:
int x1;
};
constexpr X make_x()
{
X x;
x.set(42);
return x;
}
int main()
{
constexpr X x1(-1);
constexpr X x2 = make_x();
constexpr int a1 = x1.get();
constexpr int a2 = x2.get();
std::cout << a1 << std::endl;
std::cout << a2 << std::endl;
}
请注意,main函数里的4个变量x1、x2、a1和a2都有constexpr声明,也就是说它们都是编译期必须确定的值。有了这个前提条件,我们再来分析这段代码的神奇之处。首先对于常量表达式构造函数,我们发现可以在其函数体内使用if语句并且对x1进行赋值操作了。可以看到返回类型为void的set函数也被声明为constexpr了,这也意味着该函数能够运用在constexpr声明的函数体内,make_x函数就是利用了这个特性。根据规则4和规则6,set函数也能成功地修改x1的值了。让我们来看一看GCC生成的中间代码:
main ()
{
int D.39319;
{
const struct X x1;
const struct X x2;
const int a1;
const int a2;
try
{
x1.x1 = 8;
x2.x1 = 42;
a1 = 8;
a2 = 42;
_1 = std::basic_ostream<char>::operator<< (&cout, 8);
std::basic_ostream<char>::operator<< (_1, endl);
_2 = std::basic_ostream<char>::operator<< (&cout, 42);
std::basic_ostream<char>::operator<< (_2, endl);
}
finally
{
x1 = {CLOBBER};
x2 = {CLOBBER};
}
}
D.39319 = 0;
return D.39319;
}
从上面的中间代码可以清楚地看到,编译器直接给x1.x1、x2.x1、a1、a2进行了赋值,并没有运行时的计算操作。
最后需要指出的是,C++14标准除了在常量表达式函数特性方面做了增强,也在标准库方面做了增强,包括 <complex>、<chrono>、<array>、<initializer_list>、<utility> 和 <tuple>。对于标准库的增强细节这里就不做介绍了,大家可以直接参阅STL源代码。
7. constexpr lambdas 表达式
从C++17开始,lambda表达式在条件允许的情况下都会隐式声明为constexpr。这里所说的条件,即是上一节中提到的常量表达式函数的规则,本节里就不再重复论述。结合lambda的这个新特性,先看一个简单的例子:
constexpr int foo()
{
return []() { return 58; }();
}
auto get_size = [](int i) { return i * 2; };
char buffer1[foo()] = { 0 };
char buffer2[get_size(5)] = { 0 };
可以看到,以上代码定义的是一个“普通”的lambda表达式,但是在 C++17标准中,这些“普通”的lambda表达式却可以用在常量表达式函数和数组长度中,可见该lambda表达式的结果在编译阶段已经计算出来了。实际上这里的[](int i) { return i * 2; }相当于:
class GetSize {
public:
constexpr int operator() (int i) const {
return i * 2;
}
};
当lambda表达式不满足constexpr的条件时,lambda表达式也不会出现编译错误,它会作为运行时lambda表达式存在:
// 情况1
int i = 5;
auto get_size = [](int i) { return i * 2; };
char buffer1[get_size(i)] = { 0 }; // 编译失败,get_size需要运行时调用
int a1 = get_size(i);
// 情况2
auto get_count = []() {
static int x = 5;
return x;
};
int a2 = get_count();
以上代码中情况1和常量表达式函数相同,get_size可能会退化为运行时lambda表达式对象。当这种情况发生的时候,get_size的返回值不再具有作为数组长度的能力,但是运行时调用get_size对象还是没有问题的。GCC在这种情况下依然能够在编译阶段求出get_size的值,MSVC和CLang则不行。对于情况2,由于static变量的存在,lambda表达式对象get_count不可能在编译期运算,因此它最终会在运行时计算。
值得注意的是,我们也可以强制要求lambda表达式是一个常量表达式,用constexpr去声明它即可。这样做的好处是可以检查lambda表达式是否有可能是一个常量表达式,如果不能则会编译报错,例如:
auto get_size = [](int i) constexpr -> int { return i * 2; };
char buffer2[get_size(5)] = { 0 };
auto get_count = []() constexpr -> int {
static int x = 5; // 编译失败,x是一个static变量
return x;
};
int a2 = get_count();
8. constexpr 的内联属性
在C++17标准中,constexpr声明静态成员变量时,也被赋予了该变量的内联属性,例如:
class X {
public:
static constexpr int num{ 5 };
};
以上代码在C++17中等同于:
class X {
public:
inline static constexpr int num{ 5 };
};
那么问题来了,自C++11标准推行以来static constexpr int num{ 5 }这种用法就一直存在了,那么同样的代码在C++11和C++17中究竟又有什么区别呢?
class X {
public:
static constexpr int num{ 5 };
};
代码中,num是只有声明没有定义的,虽然我们可以通过 std::cout << X::num << std::endl 输出其结果,但这实际上是编 译器的一个小把戏,它将 X::num 直接替换为了5。如果将输出语句修改 为 std::cout << &X::num << std::endl,那么链接器会明确报 告 X::num 缺少定义。但是从 C++17 开始情况发生了变化,static constexpr int num{5} 既是声明也是定义,所以在 C++17 标准中 std::cout << &X::num << std::endl 可以顺利编译链接,并且输出 正确的结果。值得注意的是,对于编译器而言为 X::num 产生定义并不 是必需的,如果代码只是引用了 X::num 的值,那么编译器完全可以使 用直接替换为值的技巧。只有当代码中引用到变量指针的时候,编译器 才会为其生成定义。
9. if constexpr
if constexpr (C++17 标准提出的一个非常有用的特性,可以用 于编写紧凑的模板代码,让代码能够根据编译时的条件进行实例化。这 里有两点需要特别注意。
1.if constexpr的条件必须是编译期能确定结果的常量表达式。
2.条件结果一旦确定,编译器将只编译符合条件的代码块。
由此可见,该特性只有在使用模板的时候才具有实际意义,若是用在普通函数上,效果会非常尴尬,比如:
void check1(int i)
{
if constexpr (i > 0) { // 编译失败,不是常量表达式
std::cout << "i > 0" << std::endl;
}
else {
std::cout << "i <= 0" << std::endl;
}
}
void check2()
{
if constexpr (sizeof(int) > sizeof(char)) {
std::cout << "sizeof(int) > sizeof(char)" << std::endl;
}
else {
std::cout << "sizeof(int) <= sizeof(char)" << std::endl;
}
}
对于函数check1,由于if constexpr的条件不是一个常量表达式,因此无法编译通过。而对于函数check2,这里的代码最后会被编 译器省略为:
void check2()
{
std::cout << "sizeof(int) > sizeof(char)" << std::endl;
}
但是当if constexpr运用于模板时,情况将非常不同。来看下面的例子:
#include <iostream>
template<class T> bool is_same_value(T a, T b)
{
return a == b;
}
template<> bool is_same_value<double>(double a, double b)
{
if (std::abs(a - b) < 0.0001) {
return true;
}
else {
return false;
}
}
int main()
{
double x = 0.1 + 0.1 + 0.1 - 0.3;
std::cout << std::boolalpha;
std::cout << "is_same_value(5, 5) : " << is_same_value(5, 5) << std::endl;
std::cout << "x == 0.0 : " << (x == 0.) << std::endl;
std::cout << "is_same_value(x, 0.) : " << is_same_value(x, 0.) << std::endl;
}
计算结果如下:
is_same_value(5, 5) : true
x == 0.0 : false
is_same_value(x, 0.) : true
我们知道浮点数的比较和整数是不同的,通常情况下它们的差小于 某个阈值就认为两个浮点数相等。我们把is_same_value写成函数模 板,并且对double类型进行特化。这里如果使用if constexpr表达 式,代码会简化很多而且更加容易理解,让我们看一看简化后的代码:
#include <type_traits>
template<class T> bool is_same_value(T a, T b)
{
if constexpr (std::is_same<T, double>::value) {
if (std::abs(a - b) < 0.0001) {
return true;
}
else {
return false;
}
}
else {
return a == b;
}
}
在上面这段代码中,直接使用if constexpr判断模板参数是否 为double,如果条件成立,则使用double的比较方式;否则使用普通 的比较方式,代码变得简单明了。再次强调,这里的选择是编译期做出 的,一旦确定了条件,那么就只有被选择的代码块才会被编译;另外的 代码块则会被忽略。说到这里,需要提醒读者注意这样一种陷阱:
#include <iostream>
#include <type_traits>
template<class T> auto minus(T a, T b)
{
if constexpr (std::is_same<T, double>::value) {
if (std::abs(a - b) < 0.0001) {
return 0.;
}
else {
return a - b;
}
}
else {
return static_cast<int>(a - b);
}
}
int main()
{
std::cout << minus(5.6, 5.11) << std::endl;
std::cout << minus(5.60002, 5.600011) << std::endl;
std::cout << minus(6, 5) << std::endl;
}
以上是一个带精度限制的减法函数,当参数类型为double且计算 结果小于0.0001的时候,我们就可以认为计算结果为0。当参数类型为 整型时,则不用对精度做任何限制。上面的代码编译运行没有任何问 题,因为编译器根据不同的类型选择不同的分支进行编译。但是如果修改一下上面的代码,结果可能就很难预料了:
template<class T> auto minus(T a, T b)
{
if constexpr (std::is_same<T, double>::value) {
if (std::abs(a - b) < 0.0001) {
return 0.;
}
else {
return a - b;
}
}
return static_cast<int>(a - b);
}
上面的代码删除了else关键词而直接将else代码块提取出来,不过 根据以往运行时if的经验,它并不会影响代码运行的逻辑。遗憾的是, 这种写法有可能导致编译失败,因为它可能会导致函数有多个不同的返 回类型。当实参为整型时一切正常,编译器会忽略if的代码块,直接编译return static_cast<int>(a − b),这样返回类型只有int一种。 但是当实参类型为double的时候,情况发生了变化。if的代码块会被 正常地编译,代码块内部的返回结果类型为double,而代码块外部的 return static_cast<int>(a − b)同样会照常编译,这次的返回类 型为int。编译器遇到了两个不同的返回类型,只能报错。
和运行时if的另一个不同点:if constexpr不支持短路规则。这 在程序编写时往往也能成为一个陷阱:
#include <iostream>
#include <string>
#include <type_traits>
template<class T> auto any2i(T t)
{
if constexpr (std::is_same<T, std::string>::value && T::npos == -1) {
return atoi(t.c_str());
}
else {
return t;
}
}
int main()
{
std::cout << any2i(std::string("6")) << std::endl;
std::cout << any2i(6) << std::endl;
}
上面的代码很好理解,函数模板any2i的实参如果是一个std::string,那么它肯定满足std::is_same<T, std::string>::value && T::npos == -1的条件,所以编译器会编 译if分支的代码。如果实参类型是一个int,那么std::is_same<T, std::string>::value会返回false,根据短路规则,if代码块不会 被编译,而是编译else代码块的内容。一切看起来是那么简单直接,但 是编译过后会发现,代码std::cout << any2i(std:: string("6")) << std::endl顺利地编译成功,std::cout << any2i(6) << std::endl则会编译失败,因为if constexpr不支持短 路规则。当函数实参为int时,std::is_same<T, std::string>::value和T::npos == -1都会被编译,由于 int::npos显然是一个非法的表达式,因此会造成编译失败。这里正确 的写法是通过嵌套if constexpr来替换上面的操作:
template<class T> auto any2i(T t)
{
if constexpr (std::is_same<T, std::string>::value) {
if constexpr(T::npos == -1) {
return atoi(t.c_str());
}
}
else {
return t;
}
}
10. 允许 constexpr 虚函数
在C++20标准之前,虚函数是不允许声明为constexpr的。看似有 道理的规则其实并不合理,因为虚函数很多时候可能是无状态的,这种 情况下它是有条件作为常量表达式被优化的,比如下面这个函数:
struct X
{
virtual int f() const { return 1; }
};
int main() {
X x;
int i = x.f();
}
上面的代码会先执行X::f函数,然后将结果赋值给i,它的 GIMPLE中间的代码如下:
main ()
{
int D.2137;
{
struct X x;
int i;
try
{
_1 = &_ZTV1X + 16;
x._vptr.X = _1;
i = X::f (&x); // 注意此处赋值
}
finally
{
x = {CLOBBER};
}
}
D.2137 = 0;
return D.2137;
}
X::f (const struct X * const this)
{
int D.2139;
D.2139 = 1;
return D.2139;
}
观察上面的两份代码,虽然X::f是一个虚函数,但是它非常适合作 为常量表达式进行优化。这样一来,int i = x.f();可以被优化 为int i = 1;,减少一次函数的调用过程。可惜在C++17标准中不允 许我们这么做,直到C++20标准明确允许在常量表达式中使用虚函数, 所以上面的代码可以修改为:
struct X
{
constexpr virtual int f() const { return 1; }
};
int main() {
constexpr X x;
int i = x.f();
}
它的中间代码也会优化为:
main ()
{
int D.2138;
{
const struct X x;
int i;
try
{
_1 = &_ZTV1X + 16;
x._vptr.X = _1;
i = 1; // 注意此处赋值
}
finally
{
x = {CLOBBER};
}
}
D.2138 = 0;
return D.2138;
}
从中间代码中可以看到,i被直接赋值为1,在此之前并没有调 用X::f函数。另外值得一提的是,constexpr的虚函数在继承重写上并 没有其他特殊的要求,constexpr的虚函数可以覆盖重写普通虚函数, 普通虚函数也可以覆盖重写constexpr的虚函数,例如:
struct X1
{
virtual int f() const = 0;
};
struct X2: public X1
{
constexpr virtual int f() const { return 2; }
};
struct X3: public X2
{
virtual int f() const { return 3; }
};
struct X4: public X3
{
constexpr virtual int f() const { return 4; }
};
constexpr int (X1::*pf)() const = &X1::f;
constexpr X2 x2;
static_assert( x2.f() == 2 );
static_assert( (x2.*pf)() == 2 );
constexpr X1 const& r2 = x2;
static_assert( r2.f() == 2 );
static_assert( (r2.*pf)() == 2 );
constexpr X1 const* p2 = &x2;
static_assert( p2->f() == 2 );
static_assert( (p2->*pf)() == 2 );
constexpr X4 x4;
static_assert( x4.f() == 4 );
static_assert( (x4.*pf)() == 4 );
constexpr X1 const& r4 = x4;
static_assert( r4.f() == 4 );
static_assert( (r4.*pf)() == 4 );
constexpr X1 const* p4 = &x4;
static_assert( p4->f() == 4 );
static_assert( (p4->*pf)() == 4 );
最后要说明的是,我在验证这条规则时,GCC无论在C++17还是 C++20 标准中都可以顺利编译通过,而Clang在C++17中会给出 constexpr无法用于虚函数的错误提示。
11. 允许在 constexpr 函数中出现 Try-catch
在C++20标准以前Try-catch是不能出现在constexpr函数中的,例如:
constexpr int f(int x)
{
try { return x + 1; }
catch (…) { return 0; }
}
不过似乎编译器对此规则的态度都十分友好,当我们用C++17标准 去编译这份代码时,编译器会编译成功并给出一个友好的警告,说明这 条特性需要使用C++20标准。C++20标准允许Try-catch存在于 constexpr函数,但是throw语句依旧是被禁止的,所以try语句是不能 抛出异常的,这也就意味着catch永远不会执行。实际上,当函数被评 估为常量表达式的时候Try-catch是没有任何作用的。
12. 允许在 constexpr 中进行平凡的默认初始化
从C++20开始,标准允许在constexpr中进行平凡的默认初始化,这样进一步减少constexpr的特殊性。例如:
struct X {
bool val;
};
void f() {
X x;
}
f();
上面的代码非常简单,在任何环境下都可以顺利编译。不过如果将函数f改为:
constexpr void f() {
X x;
}
那么在C++17标准的编译环境就会报错,提示x没有初始化,它需 要用户提供一个构造函数。当然这个问题在C++17标准中也很容易解 决,例如修改X为:
struct X {
bool val = false;
};
13. 允许在 constexpr 中更改联合类型的有效成员
在C++20标准之前对constexpr的另外一个限制就是禁止更改联合类型的有效成员,例如:
union Foo {
int i;
float f;
};
constexpr int use() {
Foo foo{};
foo.i = 3;
foo.f = 1.2f; // C++20之前编译失败
return 1;
}
在上面的代码中,foo是一个联合类型对象,foo.i = 3;首次确定 了有效成员为i,这没有问题,接下来代码foo.f = 1.2f;改变有效成 员为f,这就违反了标准中关于不能更改联合类型的有效成员的规则, 所以导致编译失败。现在C++20标准已经删除了这条规则,以上代码可 以编译成功。实际编译过程中,只有Clang会在C++17标准中对以上代 码报错,而GCC和MSVC均能用C++17和C++20标准编译成功。 C++20标准对constexpr做了很多修改,除了上面提到的修改以 外,还修改了一些并不常用的地方,包括允许dynamic_cast和typeid 出现在常量表达式中;允许在constexpr函数使用未经评估的内联汇 编。这些修改都没有需要详细介绍的特别之处,有兴趣的读者可以自己 写点实验代码测试一下。
14. 使用 consteval 声明立即函数
前面我们曾提到过,constexpr声明函数时并不依赖常量表达式上 下文环境,在非常量表达式的环境中,函数可以表现为普通函数。不过 有时候,我们希望确保函数在编译期就执行计算,对于无法在编译期执 行计算的情况则让编译器直接报错。于是在C++20标准中出现了一个新 的概念——立即函数,该函数需要使用consteval说明符来声明:
consteval int sqr(int n) {
return n*n;
}
constexpr int r = sqr(100); // 编译成功
int x = 100;
int r2 = sqr(x); // 编译失败
在上面的代码中sqr(100);是一个常量表达式上下文环境,可以编 译成功。相反,因为sqr(x);中的x是可变量,不能作为常量表达式, 所以编译器抛出错误。要让代码成功编译,只需要给x加上const即 可。需要注意的是,如果一个立即函数在另外一个立即函数中被调用, 则函数定义时的上下文环境不必是一个常量表达式,例如:
consteval int sqrsqr(int n) {
return sqr(sqr(n));
}
sqrsqr是否能编译成功取决于如何调用,如果调用时处于一个常量表达式环境,那么就能通过编译:
int y = sqrsqr(100);
反之则编译失败:
int y = sqrsqr(x);
lambda表达式也可以使用consteval说明符:
auto sqr = [](int n) consteval { return n * n; };
int r = sqr(100);
auto f = sqr; // 编译失败,尝试获取立即函数的函数地址
15. 使用 constinit 检查常量初始化
在C++中有一种典型的错误叫作“Static Initialization Order Fiasco”, 指的是因为静态初始化顺序错误导致的问题。因为这种错误往往发生在 main函数之前,所以比较难以排查。举一个典型的例子,假设有两个静 态对象x和y分别存在于两个不同的源文件中。其中一个对象x的构造函 数依赖于对象y。没错,就是这样,现在我们有50%的可能性会出错, 因为我们没有办法控制哪个对象先构造。如果对象x在y之前构造,那么 就会引发一个未定义的结果。为了避免这种问题的发生,我们通常希望 使用常量初始化程序去初始化静态变量。不幸的是,常量初始化的规则 很复杂,需要一种方法帮助我们完成检查工作,当不符合常量初始化程 序的时候可以在编译阶段报错。于是在C++20标准中引入了新的 constinit说明符。
正如上文所描述的constinit说明符主要用于具有静态存储持续时 间的变量声明上,它要求变量具有常量初始化程序。首先,constinit 说明符作用的对象是必须具有静态存储持续时间的,比如:
constinit int x = 11; // 编译成功,全局变量具有静态存储持续
int main() {
constinit static int y = 42; // 编译成功,静态变量具有静态存储持续
constinit int z = 7; // 编译失败,局部变量是动态分配的
}
其次,constinit要求变量具有常量初始化程序:
const char* f() { return "hello"; }
constexpr const char* g() { return "cpp"; }
constinit const char* str1 = f(); // 编译错误,f()不是一个常量初始化程序
constinit const char* str2 = g(); // 编译成功
constinit还能用于非初始化声明,以告知编译器thread_local变量已被初始化:
extern thread_local constinit int x;
int f() { return x; }
最后值得一提的是,虽然constinit说明符一直在强调常量初始化,但是初始化的对象并不要求具有常量属性。
16. 判断常量求值环境
std::is_constant_evaluated是C++20新加入标准库的函数,它 用于检查当前表达式是否是一个常量求值环境,如果在一个明显常量求 值的表达式中,则返回true;否则返回false。该函数包含 在<type_traits>头文件中,虽然看上去像是一个标准库实现的函数, 但实际上调用的是编译器内置函数:
constexpr inline bool is_constant_evaluated() noexcept
{
return __builtin_is_constant_evaluated();
}
该函数通常会用于代码优化中,比如在确定为常量求值的环境时, 使用constexpr能够接受的算法,让数值在编译阶段就得出结果。而对 于其他环境则采用运行时计算结果的方法。提案文档中提供了一个很好 的例子:
#include <cmath>
#include <type_traits>
constexpr double power(double b, int x) {
if (std::is_constant_evaluated() && x >= 0) {
double r = 1.0, p = b;
unsigned u = (unsigned)x;
while (u != 0) {
if (u & 1) r *= p;
u /= 2;
p *= p;
}
return r;
} else {
return std::pow(b, (double)x);
}
}
int main()
{
constexpr double kilo = power(10.0, 3); // 常量求值
int n = 3;
double mucho = power(10.0, n); // 非常量求值
return 0;
}
在上面的代码中,power函数根 据std::is_constant_evaluated()和x >= 0的结果选择不同的实现 方式。其中,kilo = power(10.0, 3);是一个常量求值,所以 std::is_constant_evaluated() && x >= 0返回true,编译器在 编译阶段求出结果。反之,mucho = power(10.0, n)则需要调 用std::pow在运行时求值。让我们通过中间代码看一看编译器具体做了什么:
main ()
{
int D.25877;
{
const double kilo;
int n;
double mucho;
kilo = 1.0e+3; // 直接赋值
n = 3;
mucho = power (1.0e+1, n); // 运行时计算
D.25877 = 0;
return D.25877;
}
D.25877 = 0;
return D.25877;
}
power (double b, int x)
{
bool retval.0;
bool iftmp.1;
double D.25892;
{
_1 = std::is_constant_evaluated ();
if (_1 != 0) goto <D.25883>; else goto <D.25881>;
<D.25883>:
if (x >= 0) goto <D.25884>; else goto <D.25881>;
<D.25884>:
iftmp.1 = 1;
goto <D.25882>;
<D.25881>:
iftmp.1 = 0;
<D.25882>:
retval.0 = iftmp.1;
if (retval.0 != 0) goto <D.25885>; else goto <D.25886>;
<D.25885>:
{
double r;
double p;
unsigned int u;
r = 1.0e+0;
p = b;
u = (unsigned int) x;
<D.25887>:
if (u == 0) goto <D.24379>; else goto <D.25888>;
<D.25888>:
_2 = u & 1;
if (_2 != 0) goto <D.25889>; else goto <D.25890>;
<D.25889>:
r = r * p;
goto <D.25891>;
<D.25890>:
<D.25891>:
u = u / 2;
p = p * p;
goto <D.25887>;
<D.24379>:
D.25892 = r;
// predicted unlikely by early return (on trees) predictor.
return D.25892;
}
<D.25886>:
_3 = (double) x;
D.25892 = pow (b, _3);
return D.25892;
}
}
std::is_constant_evaluated ()
{
bool D.25894;
try
{
D.25894 = 0;
return D.25894;
}
catch
{
<<<eh_must_not_throw (terminate)>>>
}
}
观察上面的中间代码,首先让我们注意到的就是main函数中kilo 和mucho赋值形式的不同。正如我们刚才讨论的那样,对于kilo的结果 编译器在编译期已经计算完成,所以这里是直接为1.0e+3,而对于 mucho则需要调用std::power函数。接着,我们可以观察 std::is_constant_evaluated()这个函数的实现,很明显编译器让 它直接返回0(也就是false),在代码中实现的power函数虽然 有std::is_constant_evaluated()结果为true时的算法实现,但是 却永远不会被调用。因为当std::is_constant_evaluated()为true 时,编译器计算了函数结果;反之函数会交给std::power计算结果。
在了解了std::is_constant_evaluated()的用途之后,我们还需要弄清楚何为明显常量求值。只有弄清楚这个概念,才可能合理运 用std::is_constant_evaluated()函数。明显常量求值在标准文档中列举了下面几个类别。
1.常量表达式,这个类别包括很多种情况,比如数组长度、case 表达式、非类型模板实参等。
2.if constexpr语句中的条件。
3.constexpr变量的初始化程序。
4.立即函数调用。
5.约束概念表达式。
6.可在常量表达式中使用或具有常量初始化的变量初始化程序。
下面我们通过几个标准文档中的例子来体会以上规则:
template<bool> struct X {};
X<std::is_constant_evaluated()> x; // 非类型模板实参,函数返回true,最终类型为 X<true>
int y;
constexpr int f() {
const int n = std::is_constant_evaluated() ? 13 : 17; // n是13
int m = std::is_constant_evaluated() ? 13 : 17; // m可能是13或者17,取决于函数环境
char arr[n] = {}; // char[13]
return m + sizeof(arr);
}
int p = f(); // m是13;p结果如下26
int q = p + f(); // m是17;q结果如下56
上面的代码中需要解释的是int p = f();和int q = p + f(); 的区别,对于前者,std::is_constant_evaluated() == true时p 一定是一个恒定值,它是明显常量求值,所以p的结果是26。相 反,std::is_constant_evaluated() == true时,q的结果会依 赖p,所以明显常量求值的结论显然不成立,需要采 用std::is_constant_evaluated() == false的方案,于是f()函数 中的m为17,最终q的求值结果是56。另外,如果这里的p初始化改变 为const int p = f();,那么f()函数 中的m为13,q的求值结果也会 改变为52。
最后需要注意的是,如果当判断是否为明显常量求值时存在多个条 件,那么编译器会试探std::is_constant_evaluated()两种情况求值,比如:
int y;
const int a = std::is_constant_evaluated() ? y : 1; // 函数返回false,a运行时初始化为1
const int b = std::is_constant_evaluated() ? 2 : y; // 函数返回true,b编译时初始化为2
当对a求值时,编译器试探std::is_constant_evaluated() == true的情况,发现y会改变a的值,所以最后选择 std::is_constant_evaluated() == false;当对b求值时,编译器 同样试探std::is_constant_evaluated() == true的情况,发现b 的结果恒定为2,于是直接在编译时完成初始化。
二十八、确定的表达式求值顺序(C++17)
1. 表达式求值顺序的不确定性
在C++语言之父本贾尼·斯特劳斯特卢普的作品《C++程序设计语言(第4版)》中有一段这样的代码:
void f2() {
std::string s = "but I have heard it works even if you don't believe in it";
s.replace(0, 4, "").replace(s.find("even"), 4, "only").replace(s.find(" don't"), 6, "");
assert(s == "I have heard it works only if you believe in it"); // OK
}
这段代码的本意是描述std::string成员函数replace的用法,但 令人意想不到的是,在C++17之前它隐含着一个很大的问题,该问题的 根源是表达式求值顺序。具体来说,是指一个表达式中的子表达式的求 值顺序,而这个顺序在C++17之前是没有具体说明的,所以编译器可以 以任何顺序对子表达式进行求值。比如说foo(a, b, c),这里的 foo、a、b和c的求值顺序是没有确定的。回到上面的替换函数,如果 这里的执行顺序为:
1. replace(0, 4, "")
2. tmp1 = find("even")
3. replace(tmp1, 4, "only")
4. tmp2 = find(" don't")
5. replace(tmp2, 6, "")
那结果肯定是“I have heard it works only if you believe in it”,没有任何问题。但是由于没有对表达式求值顺序的严格规定,因此其求值顺序可能会变成:
1. tmp1 = find("even")
2. tmp2 = find(" don't")
3. replace(0, 4, "")
4. replace(tmp1, 4, "only")
5. replace(tmp2, 6, "")
相应的结果就不是那么正确了,我们会得到“I have heard it works evenonlyyoudonieve in it”。
为了证实这种问题发生的可能性,我找到了两个版本的GCC编译运 行上面的代码,在最新GCC中可以得到期望的字符串,其中间代码 GIMPLE也很好地描述了编译后表达式求值的顺序:
_1 = std::__cxx11::basic_string<char>::replace (&s, 0, 4, "");
_2 = std::__cxx11::basic_string<char>::find (&s, "even", 0);
_3 = std::__cxx11::basic_string<char>::replace (_1, _2, 4, "only");
_4 = std::__cxx11::basic_string<char>::find (&s, " don\'t", 0);
std::__cxx11::basic_string<char>::replace (_3, _4, 6, "");
但是在使用GCC5.4的时候,出现了“I have heard it works evenonlyyou donieve in it”的结果,查看GIMPLE以后会发现其表达式求值顺序发生了变化:
D.22309 = std::__cxx11::basic_string<char>::find (&s, " don\'t", 0);
D.22310 = std::__cxx11::basic_string<char>::find (&s, "even", 0);
D.22311 = std::__cxx11::basic_string<char>::replace (&s, 0, 4, "");
D.22312 = std::__cxx11::basic_string<char>::replace (D.22311, D.22310, 4, "only");
std::__cxx11::basic_string<char>::replace (D.22312, D.22309, 6, "");
除了上述的例子之外,我们常用的<<操作符也面临同样的问题:
std::cout << f() << g() << h();
虽然我们认为上面的表达式应该按照f()、g()、h()顺序对表达式求值,但是编译器对此并不买单,在它看来这个顺序可以是任意的。
2. 表达式求值顺序详解
从C++17开始,函数表达式一定会在函数的参数之前求值。也就是 说在foo(a, b, c)中,foo一定会在a、b和c之前求值。但是请注意, 参数之间的求值顺序依然没有确定,也就是说a、b和c谁先求值还是没 有规定。对于这一点我和读者应该是同样的吃惊,因为从提案文档上看 来,有充分的理由说明从左往右进行参数列表的表达式求值的可行性。 我想一个可能的原因是求值顺序的改变影响到代码的优化路径,比如内 行决策和寄存器分配方式,对于编译器实现来说也是不小的挑战吧。不 过既然标准已经这么定下来了,我们就应该去适应标准。在函数的参数 列表中,尽可能少地修改共享的对象,否则会很难确认实参的真实值。
对于后缀表达式和移位操作符而言,表达式求值总是从左往右,比 如:
E1[E2]
E1.E2
E1.*E2
E1->*E2
E1<<E2
E1>>E2
在上面的表达式中,子表达式求值E1总是优先于E2。而对于赋值表 达式,这个顺序又正好相反,它的表达式求值总是从右往左,比如:
E1=E2
E1+=E2
E1-=E2
E1*=E2
E1/=E2
…
在上面的表达式中,子表达式求值E2总是优先于E1。这里虽然只列 出了几种赋值表达式的形式,但实际上对于E1@=E2这种形式的表达式 (其中@可以为+、−、*、/、%等)E2早于E1求值总是成立的。
对于new表达式,C++17也做了规定。对于:
new T(E)
这里new表达式的内存分配总是优先于T构造函数中参数E的求值。 最后C++17还明确了一条规则:涉及重载运算符的表达式的求值顺序应 由与之相应的内置运算符的求值顺序确定,而不是函数调用的顺序规 则。
在经过C++17标准一系列对于表达式求值顺序的改善之后,《C++程序设计语言》中的那段代码就可以确保最终获得的字符串为:“I have heard it works only if you believe in it”。
二十九、字面量优化(C++11~C++17)
1. 十六进制浮点字面量
从C++11开始,标准库中引入了std::hexfloat和 std::defaultfloat来修改浮点输入和输出的默认格式化,其中 std::hexfloat可以将浮点数格式化为十六进制的字符串, 而std::defaultfloat可以将格式还原到十进制,以输出为例:
#include <iostream>
int main()
{
double float_array[]{ 5.875, 1000, 0.117 };
for (auto elem : float_array) {
std::cout << std::hexfloat << elem
<< " = " << std::defaultfloat << elem << std::endl;
}
}
上面的代码分别使用std::hexfloat和std::defaultfloat格式化输出了数组x里的元素,输出结果如下:
0x1.780000p+2 = 5.875
0x1.f40000p+9 = 1000
0x1.df3b64p-4 = 0.117
这里有必要简单说明一下十六进制浮点数的表示方法,以 0x1.f40000p+9为例:其中 0x1.f4是一个十六进制的有效数, p+9是一个以2为底数,9为指数的幂。其中底数一定为2,指数使用的是十进制。也就是说 0x1.f40000p+9可以表示为: 0x1.f4 * 2^9。
虽然C++11已经具备了在输入输出的时候将浮点数格式化为十六进制的能力,但遗憾的是我们并不能在源代码中使用十六进制浮点字面量来表示一个浮点数。幸运的是,这个问题在C++17标准中得到了解决:
#include <iostream>
int main()
{
double float_array[]{ 0x1.7p+2, 0x1.f4p+9, 0x1.df3b64p-4 };
for (auto elem : float_array) {
std::cout << std::hexfloat << elem
<< " = " << std::defaultfloat << elem << std::endl;
}
}
使用十六进制浮点字面量的优势显而易见,它可以更加精准地表示浮点数。例如,IEEE-754标准最小的单精度值很容易写为0x1.0p−126。当然了,十六进制浮点字面量的劣势也很明显,它不便于代码的阅读理解。总之,我们在C++17中可以根据实际需求选择浮点数的表示方法,当需要精确表示某个浮点数的时候可以采用十六进制浮点字面量,其他情况使用十进制浮点字面量即可。
2. 二进制整数字面量
在C++14标准中定义了二进制整数字面量,正如十六进制(0x,0X)和八进制(0)都有固定前缀一样,二进制整数字面量也有前缀0b和0B。实际上GCC的扩展早已支持了二进制整数字面量,只不过到了C++14才作为标准引入:
auto x = 0b11001101L + 0xcdl + 077LL + 42;
std::cout << "x = " << x << ", sizeof(x) = " << sizeof(x) << std::endl;
除了添加二进制整数字面量以外,C++14标准还增加了一个用单引号作为整数分隔符的特性,目的是让比较长的整数阅读起来更加容易。单引号整数分隔符对于十进制、八进制、十六进制、二进制整数都是有效的,比如:
constexpr int x = 123'456;
static_assert(x == 0x1e'240);
static_assert(x == 036'11'00);
static_assert(x == 0b11'110'001'001'000'000);
值得注意的是,由于单引号在过去有用于界定字符的功能,因此这种改变可能会引起一些代码的兼容性问题,比如:
#include <iostream>
#define M(x, …) __VA_ARGS__
int x[2] = { M(1'2,3'4) };
int main()
{
std::cout << "x[0] = "<< x[0] << ", x[1] = " << x[1] << std::endl;
}
上面的代码在C++11和C++14标准下编译运行的结果不同,在C++11标准下输出结果为x[0] = 0, x[1] = 0,而在C++14标准下输出结果为x[0] = 34, x[1] = 0。这个现象很容易解释,在C++11中1'2,3'4是一个参数,所以__VA_ARGS__为空,而在C++14中它是两个参数12和34,所以__VA_ARGS__为34。虽然会引起一点兼容性问题,但是读者不必过于担心,上面这种代码很少会出现在真实的项目中,大部分情况下我们还是可以放心地将编程环境升级到C++14或者更高标准的,只不过如果真的出现了编译错误,不妨留意一下是不是这个问题造成的。
4. 原生字符串字面量
过去想在C++中嵌入一段带格式和特殊符号的字符串是一件非常令人头痛的事情,比如在程序中嵌入一份HTML代码,我们不得不写成这样:
char hello_world_html[] =
"<!DOCTYPE html>\r\n"
"<html lang = \"en\">\r\n"
" <head>\r\n"
" <meta charset = \"utf-8\">\r\n"
" <meta name = \"viewport\" content = \"width=device-width, initialscale=1, user-scalable=yes\">\r\n"
" <title>Hello World!</title>\r\n"
" </head>\r\n"
" <body>\r\n"
" Hello World!\r\n"
" </body>\r\n"
"</html>\r\n";
可以看到上面代码里的字符串非常难以阅读和维护,这是因为它包含的大量转义字符影响了阅读的流畅性。为了解决这种问题,C++11标准引入原生字符串字面量的概念。
原生字符串字面量并不是一个新的概念,比如在Python中已经支持在字符串之前加R来声明原生字符串字面量了。使用原生字符串字面量的代码会在编译的时候被编译器直接使用,也就是说保留了字符串里的格式和特殊字符,同时它也会忽略转移字符,概括起来就是所见即所得。
声明原生字符串字面量的语法很简单,即prefix R"delimiter(raw_characters)delimiter",这其中prefix和delimiter是可选部分,我们可以忽略它们,所以最简单的原生字符串字面量声明是R"(raw_characters)"。以上面的HTML字符串为例:
char hello_world_html[] = R"(<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1,
user-scalable=yes">
<title>Hello World!</title>
</head>
<body>
Hello World!
</body>
</html>
)";
从上面的代码可以看到,原生字符串中不需要\r\n,也不需要对引号使用转义字符,编译后字符串的内容和格式与代码里的一模一样。读者在这里可能会有一个疑问,如果在声明的字符串内部有一个字符组合正好是)",这样原生字符串不就会被截断了吗?没错,如果出现这样的情况,编译会出错。不过,我们也不必担心这种情况,C++11标准已经考虑到了这个问题,所以有了delimiter(分隔符)这个元素。delimiter可以是由除括号、反斜杠和空格以外的任何源字符构成的字符序列,长度至多为16个字符。通过添加delimiter可以改变编译器对原生字符串字面量范围的判定,从而顺利编译带有)"的字符串,例如:
char hello_world_html[] = R"cpp(<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1,
user-scalable=yes">
<title>Hello World!</title>
</head>
<body>
"(Hello World!)"
< / body >
< / html>
)cpp";
在上面的代码中,字符串虽然包含"(Hello World!)"这个比较特殊的子字符串,但是因为我们添加了cpp这个分隔符,所以编译器能正确地获取字符串的真实范围,从而顺利地通过编译。
C++11标准除了让我们能够定义char类型的原生字符串字面量外,对于wchar_t、char8_t(C++20标准开始)、char16_t和char32_t类型的原生字符串字面量也有支持。要支持这4种字符类型,就需要用到另外一个可选元素prefix了。这里的prefix实际上是声明4个类型字符串的前缀L、u、U和u8。
char8_t utf8[] = u8R"(你好世界)"; // C++20标准开始
char16_t utf16[] = uR"(你好世界)";
char32_t utf32[] = UR"(你好世界)";
wchar_t wstr[] = LR"(你好世界)";
最后,关于原生字符串字面量的连接规则实际上和普通字符串字面量是一样的,唯一需要注意的是,原生字符串字面量除了能连接原生字符串字面量以外,还能连接普通字符串字面量。
5. 用户自定义字面量
在C++11标准中新引入了一个用户自定义字面量的概念,程序员可以通过自定义后缀将整数、浮点数、字符和字符串转化为特定的对象。这个特性往往用在需要大量声明某个类型对象的场景中,它能够减少一些重复类型的书写,避免代码冗余。一个典型的例子就是不同单位对象的互相操作,比如长度、重量、时间等,举个例子:
#include <iostream>
template<int scale, char ... unit_char>
struct LengthUnit {
constexpr static int value = scale;
constexpr static char unit_str[sizeof...(unit_char) + 1] = { unit_char..., '\0' };
};
template<class T>
class LengthWithUnit {
public:
LengthWithUnit() : length_unit_(0) {}
LengthWithUnit(unsigned long long length) : length_unit_(length * T::value) {}
template<class U>
LengthWithUnit<std::conditional_t<(T::value > U::value), U, T>> operator+(const LengthWithUnit<U> &rhs)
{
using unit_type = std::conditional_t<(T::value > U::value), U, T>;
return LengthWithUnit<unit_type>((length_unit_ + rhs.get_length()) / unit_type::value);
}
unsigned long long get_length() const { return length_unit_; }
constexpr static const char* get_unit_str() { return T::unit_str; }
private:
unsigned long long length_unit_;
};
template<class T>
std::ostream& operator<< (std::ostream& out, const LengthWithUnit<T> &unit)
{
out << unit.get_length() / T::value << LengthWithUnit<T>::get_unit_str();
return out;
}
using MMUnit = LengthUnit<1, 'm', 'm'>;
using CMUnit = LengthUnit<10, 'c', 'm'>;
using DMUnit = LengthUnit<100, 'd', 'm'>;
using MUnit = LengthUnit<1000, 'm'>;
using KMUnit = LengthUnit<1000000, 'k', 'm'>;
using LengthWithMMUnit = LengthWithUnit<MMUnit>;
using LengthWithCMUnit = LengthWithUnit<CMUnit>;
using LengthWithDMUnit = LengthWithUnit<DMUnit>;
using LengthWithMUnit = LengthWithUnit<MUnit>;
using LengthWithKMUnit = LengthWithUnit<KMUnit>;
int main()
{
auto total_length = LengthWithCMUnit(1) + LengthWithMUnit(2) + LengthWithMMUnit(4);
std::cout << total_length;
}
上面的代码定义了两个类模板,一个是长度单位LengthUnit,另外一个是带单位的长度LengthWithUnit,然后基于这两个类模板生成了毫米、厘米、分米、米和千米单位类以及它们对应的带单位的长度类。为了不同单位的数据相加,我们在类模板LengthWithUnit中重载了加号运算符,函数中总是会将较大的单位转换到较小的单位进行求和,比如千米和厘米相加得到的结果单位为厘米。最后,我们在main函数中对不同单位的对象求和并且输出求和结果。类模板的编写用到了一些模板元编程的知识,我们暂时可以忽略它们,现在需要关注的是main函数里的代码。我们发现每增加一个求和的操作数就需要重复写一个类型LengthWithXXUnit,当操作数很多的时候代码会变得很长,难以阅读和维护。当遇到这种情况的时候,我们可以考虑使用用户自定义字面量来简化代码,比如:
LengthWithMMUnit operator "" _mm(unsigned long long length)
{
return LengthWithMMUnit(length);
}
LengthWithCMUnit operator "" _cm(unsigned long long length)
{
return LengthWithCMUnit(length);
}
LengthWithDMUnit operator "" _dm(unsigned long long length)
{
return LengthWithDMUnit(length);
}
LengthWithMUnit operator "" _m(unsigned long long length)
{
return LengthWithMUnit(length);
}
LengthWithKMUnit operator "" _km(unsigned long long length)
{
return LengthWithKMUnit(length);
}
int main()
{
auto total_length = 1_cm + 2_m + 4_mm;
std::cout << total_length;
}
上面的代码定义了5个字面量运算符函数,这些函数返回不同单位的长度对象,分别对应于毫米、厘米、分米、米和千米。字面量运算符函数的函数名会作为后缀应用于字面量。在main函数中,我们可以看到现在的代码省略了LengthWithXXUnit的类型声明,取而代之的是一个整型的字面量紧跟着一个以下画线开头的后缀 _cm、_m 或者 _mm。在这里编译器会根据字面量的后缀去查找对应的字面量运算符函数,并根据函数形式对字面量做相应处理后调用该函数,如果编译器没有找到任何对应的函数,则会报错。所以这里的 1_cm、2_m 和 4_mm 分别等于调用了 LengthWithCMUnit(1)、LengthWithMUnit(2) 和 LengthWithMMUnit(4)。
接下来让我们看一看字面量运算符函数的语法规则,字面量运算符函数的语法和其他运算符函数一样都是由返回类型、operator关键字、标识符以及函数形参组成的:
retrun_type operator "" identifier (params)
值得注意的是在C++11的标准中,双引号和紧跟的标识符中间必须有空格,不过这个规则在C++14标准中被去除。在C++14标准中,标识符不但可以紧跟在双引号后,而且还能使用C++的保留字作为标识符。标准中还建议用户定义的字面量运算符函数的标识符应该以下画线开始,把没有下画线开始的标识符保留给标准库使用。虽然标准并没有强制规定自定义的字面量运算符函数标识符必须以下画线开始,但是我们还是应该尽量遵循标准的建议。这一点编译器也会提示我们,如果使用了非下画线开始的标识符,它会给出明确的警告信息。
上文曾提到,用户自定义字面量支持整数、浮点数、字符和字符串4种类型。虽然它们都通过字面量运算符函数来定义,但是对于不同的类型字面量运算符函数,语法在参数上有略微的区别。
对于整数字面量运算符函数有3种不同的形参类型unsigned long long、const char *以及形参为空。其中unsigned long long和const char *比较简单,编译器会将整数字面量转换为对应的无符号long long类型或者常量字符串类型,然后将其作为参数传递给运算符函数。而对于无参数的情况则使用了模板参数,形如operator "" identifier<char...c>(),这个稍微复杂一些,我们在后面的例子中详细介绍。
对于浮点数字面量运算符函数也有3种形参类型long double、const char *以及形参为空。和整数字面量运算符函数相比,除了将unsigned long long换成了long double,没有其他的区别。
对于字符串字面量运算符函数目前只有一种形参类型列表const char * str, size_t len。其中str为字符串字面量的具体内容,len是字符串字面量的长度。
对于字符字面量运算符函数也只有一种形参类型char,参数内容为字符字面量本身:
#include <string>
unsigned long long operator "" _w1(unsigned long long n)
{
return n;
}
const char * operator "" _w2(const char *str)
{
return str;
}
unsigned long long operator "" _w3(long double n)
{
return n;
}
std::string operator "" _w4(const char* str, size_t len)
{
return str;
}
char operator "" _w5(char n)
{
return n;
}
unsigned long long operator ""if(unsigned long long n)
{
return n;
}
int main()
{
auto x1 = 123_w1;
auto x2_1 = 123_w2;
auto x2_2 = 12.3_w2;
auto x3 = 12.3_w3;
auto x4 = "hello world"_w4;
auto x5 = 'a'_w5;
auto x6 = 123if;
}
在上面的代码中,根据字面量运算符函数的语法规则,后缀 _w1 和 _w2 可以用于整数,后缀 _w3 和 _w2 可以用于浮点数,而 _w4 和 _w5 分别用于字符串和字符。请注意最后一个 if 后缀,它必须用支持C++14标准的编译器才能编译成功。这个后缀有两点比较特殊,首先它使用保留关键字 if 作为后缀,其次它没有用下画线开头。前者能够这么做是因为C++14标准中字面量运算符函数双引号后紧跟的标识符允许使用保留字,而对于后者支持C++11标准的编译器通常允许这么做,只是会给出警告。
最后来看一下字面量运算符函数使用模板参数的情况,在这种情况下函数本身没有任何形参,字面量的内容通过可变模板参数列表 <char...> 传到函数
#include <string>
template <char... c>
std::string operator "" _w()
{
std::string str;
(void)(std::initializer_list<char>{ (str.push_back(c), '\0') ... });
return str;
}
int main()
{
auto x = 123_w;
auto y = 12.3_w;
}
上面这段代码展示了一个使用可变参数模板的字面量运算符函数,该函数通过声明数组展开参数包的技巧将char类型的模板参数 push_back 到 str 中。实际上,通常情况下很少会用到这种形式的字面量运算符函数,从易用性和可读性的角度来说它都不是一个好的选择,所以我建议还是采用上面提到的那些带有形参的字面量运算符函数。
三十、alignas和alignof(C++11 C++17)
1. 不可忽视的数据对齐问题
C++11中新增了alignof和alignas两个关键字,其中alignof运算符可以用于获取类型的对齐字节长度,alignas说明符可以用来改变类型的默认对齐字节长度。这两个关键字的出现解决了长期以来C++标准中无法对数据对齐进行处理的问题。
在详细介绍这两个关键字之前,我们先来看一看下面这段代码:
#include <iostream>
struct A
{
char a1;
int a2;
double a3;
};
struct B
{
short b1;
bool b2;
double b3;
};
int main()
{
std::cout << "sizeof(A::a1) + sizeof(A::a2) + sizeof(A::a3) = "
<< sizeof(A::a1) + sizeof(A::a2) + sizeof(A::a3) << std::endl;
std::cout << "sizeof(B::b1) + sizeof(B::b2) + sizeof(B::b3) = "
<< sizeof(B::b1) + sizeof(B::b2) + sizeof(B::b3) << std::endl;
std::cout << "sizeof(A) = " << sizeof(A) << std::endl;
std::cout << "sizeof(B) = " << sizeof(B) << std::endl;
}
编译运行这段代码会得到以下结果:
sizeof(A::a1) + sizeof(A::a2) + sizeof(A::a3) = 13
sizeof(B::b1) + sizeof(B::b2) + sizeof(B::b3) = 11
sizeof(A) = 16
sizeof(B) = 16
奇怪的事情发生了,A 和 B 两个类的成员变量的数据长度之和分别为13字节和11字节,与它们本身的数据长度16字节不同。对比这两个类,它们在成员变量数据长度之和上明明不同,却在类整体数据长度上相同。有经验的程序员应该一眼就能看出其中的原因。实际上,一个类型的属性除了其数据长度,还有一个重要的属性——数据对齐的字节长度。
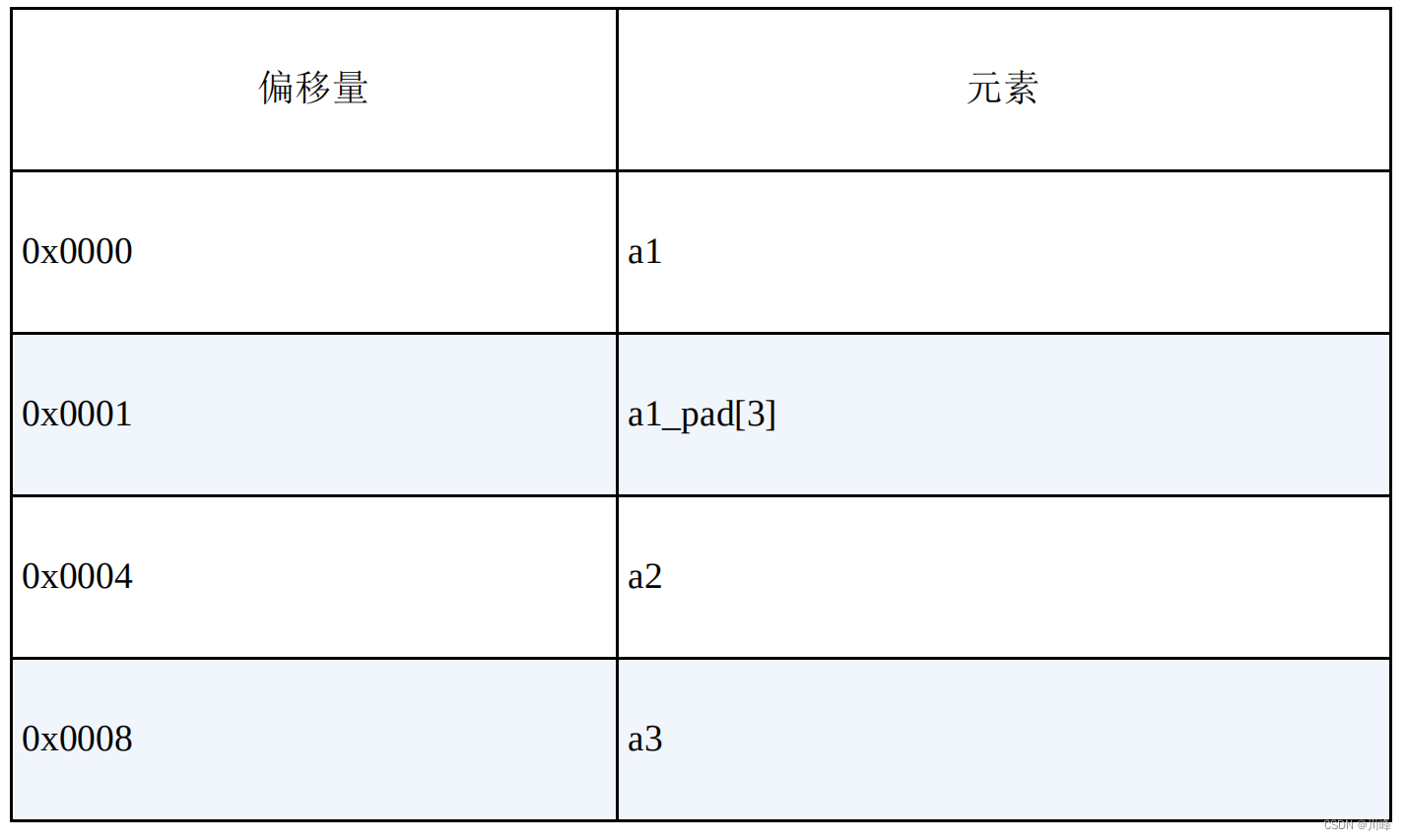
在上面的代码中,char 以1字节对齐,short 以2字节对齐,int 以4字节对齐,double 以8字节对齐,所以它们的实际数据结构应该是这样的:
struct A
{
char a1;
char a1_pad[3];
int a2;
double a3;
};
内存布局如表所示。
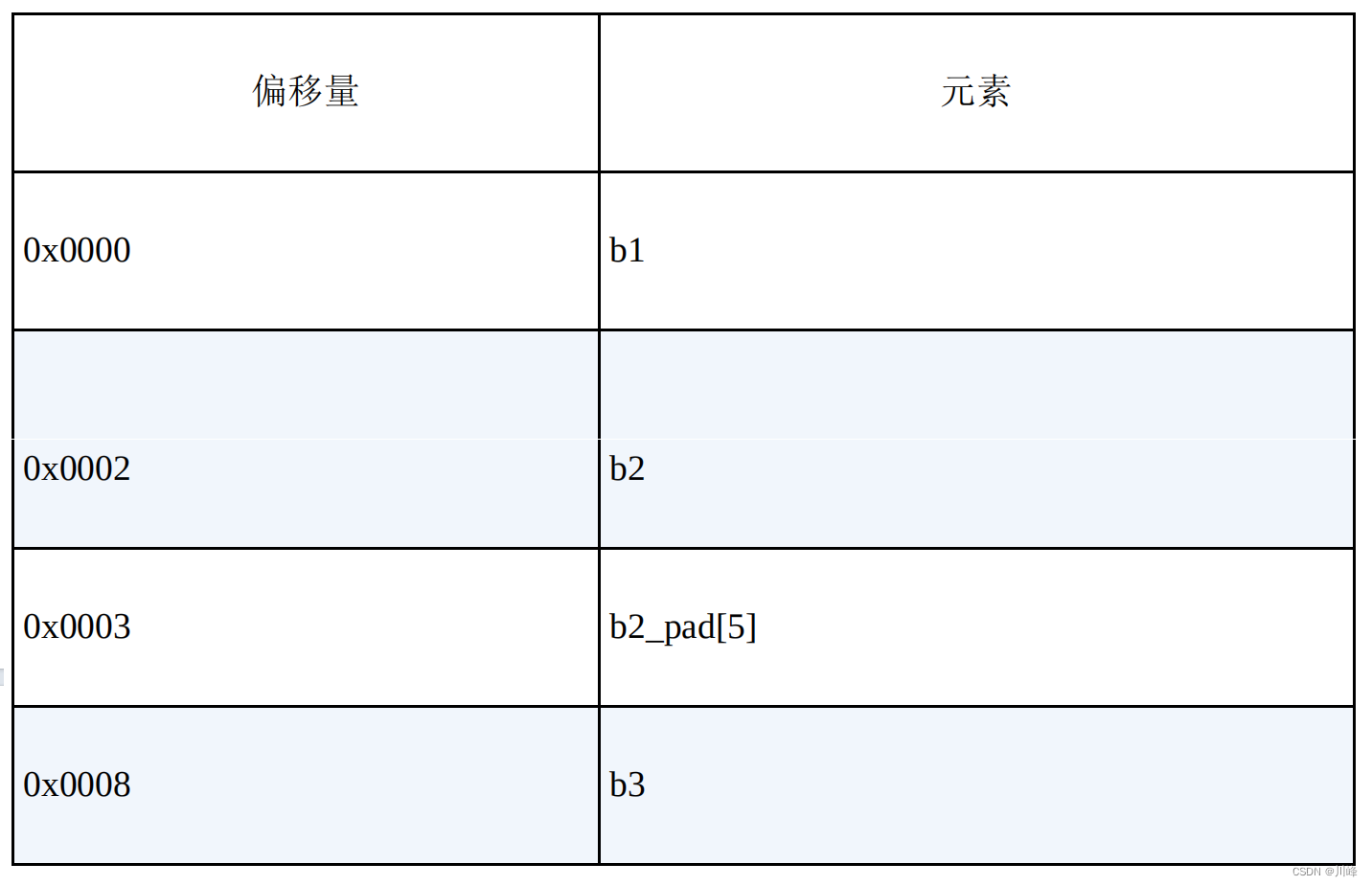
struct B
{
short b1;
bool b2;
char b2_pad[5];
double b3;
};
内存布局如表所示。
通过上述示例应该能够对数据对齐有比较直观的理解了。但是为什么我们需要数据对齐呢?原因说起来很简单,就是硬件需要。首当其冲的就是CPU了,CPU对数据对齐有着迫切的需求,一个好的对齐字节长度可以让CPU运行起来更加轻松快速。反过来说,不好的对齐字节长度则会让CPU运行速度减慢,甚至抛出错误。通常来说所谓好的对齐长度和CPU访问数据总线的宽度有关系,比如CPU访问32位宽度的数据总线,就会期待数据是按照32位对齐,也就是4字节。这样CPU读取4字节的数据只需要对总线访问一次,但是如果要访问的数据并没有按照4字节对齐,那么CPU需要访问数据总线两次,运算速度自然也就减慢了。另外,对于数据对齐问题引发错误的情况(Alignment Fault),通常会发生在ARM架构的计算机上。当然除了CPU之外,还有其他硬件也需要数据对齐,比如通过DMA访问硬盘,就会要求内存必须是4K对齐的。总的来说,配合现代编译器和CPU架构,可以让程序获得令人难以置信的性能,但这种良好的性能取决于某些编程实践,其中一种编程实践是正确的数据对齐。
2. C++11标准之前控制数据对齐的方法
在C++11标准之前我们没有一个标准方法来设定数据的对齐字节长度,只能依靠一些编程技巧和各种编译器自身提供的扩展功能来达到这一目的。
首先让我们来看一看如何获得类型的对齐字节长度。在alignof运算符被引入之前,程序员常用offsetof来间接实现alignof的功能,其中一种实现方法如下:
#define ALIGNOF(type, result) \
struct type##_alignof_trick{ char c; type member; }; \
result = offsetof(type##_alignof_trick, member)
int x1 = 0;
ALIGNOF(int, x1);
以上代码用宏定义了一个结构体,其中用type定义了成员变量member,然后用offsetof获取member的偏移量,从而获取指定类型的对齐字节长度。该方法运用在大部分类型上没有问题,不过还是有些例外,比如函数指针类型:
int x1 = 0;
ALIGNOF(void(*)(), x1); // 无法编译通过
当然了,我们可以用typedef来解决这个问题:
int x1 = 0;
typedef void (*f)();
ALIGNOF(f, x1);
实际上我们还有第二种更好的方案:
template<class T> struct alignof_trick { char c; T member; };
#define ALIGNOF(type) offsetof(alignof_trick<type>, member)
auto x1 = ALIGNOF(int);
auto x2 = ALIGNOF(void(*)());
上面的代码利用模板来构造结构体,这一点显然优于用宏构造。因为它不仅可以处理函数指针类型,还能够在表达式中构造结构体,从而让 ALIGNOF 写在表达式当中,这也让它更接近 alignof 运算符的用法。
除用一些小技巧获取类型对齐字节长度之外,很多编译器还提供了一些扩展方法帮助我们获得类型的对齐字节长度,以MSVC和GCC为例,它们分别可以通过扩展关键字 __alignof 和 __alignof__ 来获取数据类型的对齐字节长度:
// MSVC
auto x1 = __alignof(int);
auto x2 = __alignof(void(*)());
// GCC
auto x3 = __alignof__(int);
auto x4 = __alignof__(void(*)());
相对于获取数据对齐的功能而言,设置数据对齐就没那么幸运了,在C++11之前,我们不得不依赖编译器给我们提供的扩展功能来设置数据对齐。幸好很多编译器也提供了这样的功能,还是以MSVC和GCC为例:
// MSVC
short x1;
__declspec(align(8)) short x2;
std::cout << "x1 = " << __alignof(x1) << std::endl;
std::cout << "x2 = " << __alignof(x2) << std::endl;
// GCC
short x3;
__attribute__((aligned(8))) short x4;
std::cout << "x3 = " << __alignof__(x3) << std::endl;
std::cout << "x4 = " << __alignof__(x4) << std::endl;
上面的代码输出结果如下:
x1 = 2
x2 = 8
x3 = 2
x4 = 8
__declspec(align(8)) 和 __attribute__((aligned(8))) 分别将 x2 和 x4 两个 short 类型的对齐长度从2字节扩展到8字节。
不同的编译器需要采用不同的扩展功能来控制类型的对齐字节长度,这一点对于程序员来说很不友好。所以C++标准委员在C++11标准中新增了alignof 和 alignas 两个关键字。
3. 使用 alignof 运算符
alignof 运算符和我们前面提到的编译器扩展关键字 __alignof、__alignof__ 用法相同,都是获得类型的对齐字节长度,比如:
auto x1 = alignof(int);
auto x2 = alignof(void(*)());
int a = 0;
auto x3 = alignof(a); // *C++标准不支持这种用法
请注意上面的第4句代码,alignof 的计算对象并不是一个类型,而是一个变量。但是C++标准规定 alignof 必须是针对类型的。不过GCC扩展了这条规则,alignof 除了能接受一个类型外还能接受一个变量,用GCC编译此段代码是可以编译通过的。阅读了第4章的读者可能会想到,我们只需要结合 decltype,就能够扩展出类似这样的功能:
int a = 0;
auto x3 = alignof(decltype(a));
但实际情况是,这种做法只有在类型使用默认对齐的时候才是正确的,如果用在下面的情况中会产生错误的结果:
alignas(8) int a = 0;
auto x3 = alignof(decltype(a)); // 错误的返回4,而并非设置的8
使用MSVC的读者如果想获得变量的对齐,不妨使用编译器的扩展关键字__alignof:
alignas(8) int a = 0;
auto x3 = __alignof(a); // 返回8
另外,我们还可以通过 alignof 获得类型 std::max_align_t 的对齐字节长度,这是一个非常重要的值。C++11定义了 std::max_align_t,它是一个平凡的标准布局类型,其对齐字节长度要求至少与每个标量类型一样严格。也就是说,所有的标量类型都适应 std::max_align_t 的对齐字节长度。C++标准还规定,诸如 new 和 malloc 之类的分配函数返回的指针需要适合于任何对象,也就是说内存地址至少与 std::max_align_t 严格对齐。由于 C++标准并没有定义 std::max_align_t 对齐字节长度具体是什么样的,因此不同的平台会有不同的值,通常情况下是8字节和16字节。下面做一个小实验来验证一下刚刚的说法:
for (int i = 0; i < 100; i++) {
auto *p = new char();
auto addr = reinterpret_cast<std::uintptr_t>(p);
std::cout << addr % alignof(std::max_align_t) << std::endl;
delete p;
}
编译运行以上代码,会发现输出的都是0,也就是说即使我们分配的是1字节的内存,内存分配器也会将指针定位到与 std::max_align_t 对齐的地方。如果我们有自定义内存分配器的需要,请务必考虑到这个细节。
4. 使用 alignas 说明符
接下来看一看 alignas 说明符的用法,该说明符可以接受类型或者常量表达式。特别需要注意的是,该常量表达式计算的结果必须是一个2的幂值,否则是无法通过编译的。具体用法如下(这里采用GCC编译器,因为其 alignof 可以查看变量的对齐字节长度):
#include <iostream>
struct X
{
char a1;
int a2;
double a3;
};
struct X1
{
alignas(16) char a1;
alignas(double) int a2;
double a3;
};
struct alignas(16) X2
{
char a1;
int a2;
double a3;
};
struct alignas(16) X3
{
alignas(8) char a1;
alignas(double) int a2;
double a3;
};
struct alignas(4) X4
{
alignas(8) char a1;
alignas(double) int a2;
double a3;
};
#define COUT_ALIGN(s) std::cout << "alignof(" #s ") = " << alignof(s) << std::endl
int main()
{
X x;
X1 x1;
X2 x2;
X3 x3;
X4 x4;
alignas(4) X3 x5;
alignas(16) X4 x6;
COUT_ALIGN(x);
COUT_ALIGN(x1);
COUT_ALIGN(x2);
COUT_ALIGN(x3);
COUT_ALIGN(x4);
COUT_ALIGN(x5);
COUT_ALIGN(x6);
COUT_ALIGN(x5.a1);
COUT_ALIGN(x6.a1);
}
输出结果如下:
alignof(x) = 8
alignof(x1) = 16
alignof(x2) = 16
alignof(x3) = 16
alignof(x4) = 8
alignof(x5) = 4
alignof(x6) = 16
alignof(x5.a1) = 8
alignof(x6.a1) = 8
从上面的代码可以看出,alignas 的使用非常灵活,例子中它既可以用于结构体,也可以用于结构体的成员变量。如果将 alignas 用于结构体类型,那么该结构体整体就会以 alignas 声明的对齐字节长度进行对齐,比如在例子中,X 的类型对齐字节长度为8字节,而 X2 在使用了 alignas(16) 之后,对齐字节长度修改为了16字节。另外,如果修改结构体成员的对齐字节长度,那么结构体本身的对齐字节长度也会发生变化,因为结构体类型的对齐字节长度总是需要大于或者等于其成员变量类型的对齐字节长度。比如 X1 的成员变量 a1 类型的对齐字节长度修改为了16字节,所有 X1 类型也被修改为16字节对齐。同样的规则也适用于结构体 X3,X3 类型的对齐字节长度被指定为16字节,虽然其成员变量 a1 的类型对齐字节长度被指定为8字节,但是并不能改变 X3 类型的对齐字节长度。X4 就恰恰相反,由于 X4 指定的对齐字节长度为4字节,明显小于其成员变量类型需要的对齐字节长度的字节数,因此这里 X4 的 alignas(4) 会被忽略。最后要说明的是,结构体类型的对齐字节长度,并不能影响声明变量时变量的对齐字节长度,比如 X5、X6。不过在变量声明时指定对齐字节长度,也不影响变量内部成员变量类型的对齐字节长度,比如 x5.a1、x6.a1。上面的代码用结构体作为例子,实际上对于类也是一样的。
5. 其他关于对齐字节长度的支持
C++11标准除了提供了关键字alignof和alignas来支持对齐字节长度的控制以外,还提供了std::alignment_of、std::aligned_storage和std::aligned_union类模板型以及std::align函数模板来支持对于对齐字节长度的控制。
下面简单地介绍一下它们的用法。std::alignment_of和alignof的功能差不多,可以获取类型的对齐字节长度,例如:
std::cout << std::alignment_of<int>::value << std::endl; // 输出4
std::cout << std::alignment_of<int>() << std::endl; // 输出4
std::cout << std::alignment_of<double>::value << std::endl; // 输出8
std::cout << std::alignment_of<double>() << std::endl; // 输出8
std::aligned_storage可以用来分配一块指定对齐字节长度和大小的内存,例如:
std::aligned_storage<128, 16>::type buffer;
std::cout << sizeof(buffer) << std::endl; // 内存大小指定为128字节
std::cout << alignof(buffer) << std::endl; // 对齐字节长度指定为16字节
std::aligned_union接受一个std::size_t作为分配内存的大小,以及不定数量的类型。std::aligned_union会获取这些类型中对齐字节长度最严格的(对齐字节数最大)作为分配内存的对齐字节长度,例如:
std::aligned_union<64, double, int, char>::type buffer;
std::cout << sizeof(buffer) << std::endl; // 内存大小指定为64字节
std::cout << alignof(buffer) << std::endl; // 对齐字节长度自动选择为 double,8字节对齐
最后解释一下std::align函数模板,该函数接受一个指定大小的缓冲区空间的指针和一个对齐字节长度,返回一个该缓冲区中最近的能找到符合指定对齐字节长度的指针。通常来说,我们传入的缓冲区内存大小为预分配的缓冲区大小加上预指定对齐字节长度的字节数。下面会给出一个例子详解这个函数模板的用法,这个例子不仅说明了函数的用法,更重要的是,它证明了在CPU喜爱的对齐字节长度上做计算,CPU的工作效率会更高:
#include <iostream>
#include <memory>
#include <chrono>
static inline void *__movsb(void *d, const void *s, size_t n) {
asm volatile ("rep movsb"
: "=D" (d),
"=S" (s),
"=c" (n)
: "0" (d),
"1" (s),
"2" (n)
: "memory");
return d;
}
int main(int argc, char *argv[])
{
constexpr int align_size = 32;
constexpr int alloc_size = 10001;
constexpr int buff_size = align_size + alloc_size;
char dest[buff_size]{0};
char src[buff_size]{0};
void *dest_ori_ptr = dest;
void *src_ori_ptr = src;
size_t dest_size = sizeof(dest);
size_t src_size = sizeof(src);
char *dest_ptr = static_cast<char *>(std::align(align_size, alloc_size, dest_ori_ptr, dest_size));
char *src_ptr = static_cast<char *>(std::align(align_size, alloc_size, src_ori_ptr, src_size));
if (argc == 2 && argv[1][0] == '1') {
++dest_ptr;
++src_ptr;
}
auto start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < 10000000; i++) {
__movsb(dest_ptr, src_ptr, alloc_size - 1);
}
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> diff = end - start;
std::cout << "elapsed time = " << diff.count();
}
上面的代码用汇编语言实现了一个memcpy函数以确保复制内存函数都是通过汇编指令movsb完成的。然后我们预先分配了两个10001+32字节大小的内存作为目标缓冲区和源缓冲区。此后通过std::align找到两个缓冲区中按照32字节对齐的指针,该指针指向的内存大小至少为10001字节。最后我们用自己实现的内存复制函数进行内存复制。如果运行的时候不带任何参数,则使用32字节对齐的内存进行复制,否则用1字节对齐的内存进行内存复制,复制动作重复10000000次。在Intel(R) Core(TM) i7-7700 CPU @ 3.60GHz的机器上,两种方法的运行结果很有大差别:
./aligntest
elapsed time = 0.951485
./aligntest 1
elapsed time = 1.36937
可以看到,32字节对齐的缓冲区复制时间比1字节对齐的缓冲区复制时间整整少了0.4s有余。在性能优化上来说是非常巨大的提升。
6. C++17中使用new分配指定对齐字节长度的对象
前面曾提到过内存分配器会按照std::max_align_t的对齐字节长度分配对象的内存空间。这一点在C++17标准中发生了改变,new运算符也拥有了根据对齐字节长度分配对象的能力。这个能力是通过让new运算符接受一个std::align_val_t类型的参数来获得分配对象需要的对齐字节长度来实现的:
void* operator new(std::size_t, std::align_val_t);
void* operator new[](std::size_t, std::align_val_t);
编译器会自动从类型对齐字节长度的属性中获取这个参数并且传参,不需要额外的代码介入。例如:
#include <iostream>
union alignas(256) X
{
char a1;
int a2;
double a3;
};
int main(int argc, char *argv[])
{
X *x = new X();
std::cout << "x = " << x << std::endl;
}
通过GCC编译器将其编译为C++11和C++17两个版本,可以看到输出结果的区别:
g++ -std=c++11 test_new.cpp -o cpp11
./cpp11
x = 0x1071620
g++ -std=c++17 test_new.cpp -o cpp17
./cpp17
x = 0x1d1700
我们发现在使用C++11标准的情况下,new分配的对象指针(0x1071620)并没有按照X指定的对齐字节长度(256字节)对齐,而在使用C++17标准的情况下,new分配的对象指针(0x1d1700)正好为X指定的对齐字节长度。