前言
大家好,这里是符华~
之前写了一篇 go excelize库封装导入导出 的博客,然后那篇博客还挖了个坑,结果这个坑差点就填不上了🤣还好经过我的不懈努力,总算是把坑给填上了。。。
挖坑
上一篇文章中,我们实现了:通用的导入,普通导出、动态列导出、隔行背景色、自适应行高。这篇文章一开始就列出来要实现哪些功能,然后在结尾处,我还说会弄完那几个未完成的功能。结果我后面开发的时候,才发现,这有个别功能不简单啊,搞了我好久没做出来(死活实现不出来,我想着要不算了。。坑了就坑了😣)。

其实多个sheet、基于map导出这两个我都很早就实现了,然后因为我一直做不出复杂表头,纵向合并这个功能也就没去动手实现。复杂表头 这块我点名批评,太难搞了,我按照之前的想法死活实现不了😣。也不知道是哪里有问题,看起来思路是对的,但实现效果就是还差点。差点死心放弃了。。
好在前几天,不知道为什么,突然开窍,想到了其他办法,一试,果然可以,就是这样的!然后后面的合并单元格也自然而然地做出来了!!之前就不该死磕一开始那个有问题的方式😂😂。
实现
废话不多说(已经说了挺多废话了),我们直接来看本篇要实现哪些东西:
- 多个sheet导出
- 基于map导出
- 多级表头、树形结构表头导出
- 横向合并单元格导出
- 纵向合并单元格导出
多个sheet导出
咱们先从简单的开始,由简入难
// 测试结构体
type Test struct {
Id string `excel:"name:用户账号;"`
Name string `excel:"name:用户姓名;"`
Email string `excel:"name:用户邮箱;width:25;"`
Com string `excel:"name:所属公司;"`
Dept bool `excel:"name:所在部门;replace:false_超级管理员,true_普通用户;"`
RoleName string `excel:"name:角色名称;replace:1_超级管理员,2_普通用户;"`
Remark int `excel:"name:备注;replace:1_超级管理员,2_普通用户;width:40;"`
}
// 要导出的列表
var testList = []Test{
{"fuhua", "符华", "fuhua@123.com", "太虚剑派", false, "1", 1},
{"baiye", "白夜", "baiye@123.com", "天命科技有限公司", false, "2", 1},
{"chiling", "炽翎", "chiling@123.com", "太虚剑派", false, "2", 2},
{"yunmo", "云墨", "yunmo@123.com", "太虚剑派", false, "1", 2},
{"yuelun", "月轮", "yuelun@123.com", "天命科技有限公司", false, "1", 1},
{"xunyu", "迅羽",
"xunyu@123.com哈哈哈哈哈哈哈哈这里是最大行高测试哈哈哈哈哈哈哈哈这11111111111里是最大行高测试哈哈哈哈哈哈哈哈这里是最大行高测试",
"天命科技有限公司", true, "2",
124},
}
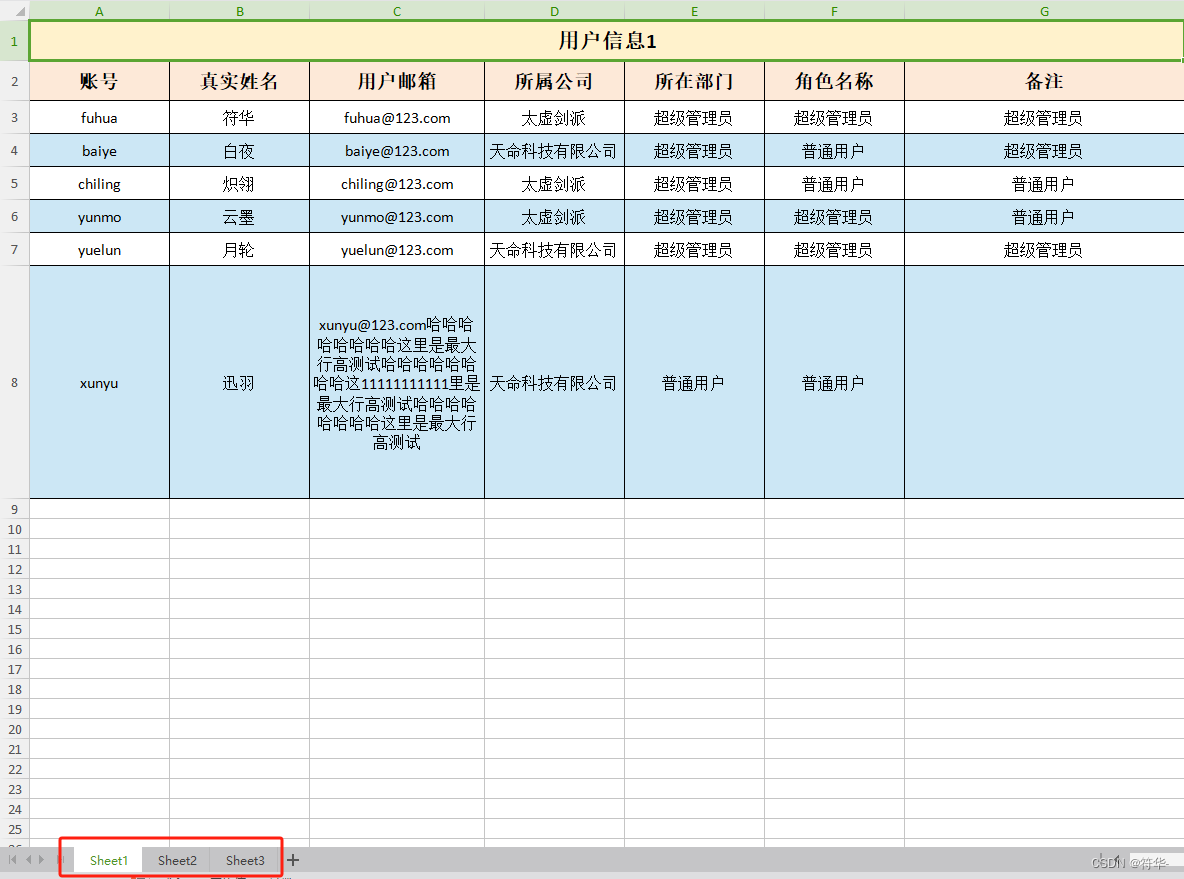
// 多个sheet导出
func ExportSheets() {
// 获取导出的数据
changeHead := map[string]string{"Id": "账号", "Name": "真实姓名"}
// 多个sheet导出
e := model.ExcelInit()
for i := 0; i < 3; i++ {
sheet := "Sheet" + fmt.Sprintf("%d", i+1)
title := "用户信息" + fmt.Sprintf("%d", i+1)
fmt.Println(sheet)
// 其实就是相当于普通sheet导出,只不过是每个sheet分别传对应的数据过去
err := excel.ExportExcel(sheet, title, "", true, false, testList, changeHead, e)
if err != nil {
fmt.Println(err)
return
}
}
e.F.Path = "C:\\Users\\Administrator\\Desktop\\多个sheet导出.xlsx"
if err := e.F.Save(); err != nil {
fmt.Println(err)
return
}
}
实现效果:
基于map导出
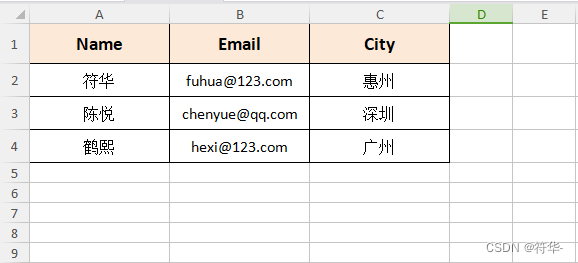
// 基于map的导出
func ExportMap() {
// 表头
header := []string{"Name", "Age", "City"}
// map数据
data := []map[string]interface{}{
{"Name": "符华", "Email": "fuhua@123.com", "City": "惠州"},
{"Name": "陈悦", "Email": "chenyue@qq.com", "City": "深圳"},
{"Name": "鹤熙", "Email": "hexi@123.com", "City": "广州"},
}
f, err := excel.MapExport(header, data, "Sheet1", "", false)
if err != nil {
fmt.Println("导出失败", err)
return
}
// 保存文件
err = f.SaveAs("C:\\Users\\Administrator\\Desktop\\map导出.xlsx")
if err != nil {
fmt.Println(err)
return
}
fmt.Println("Excel文件已成功导出")
}
map数据导出,构建数据内容,不能用之前这个 normalBuildDataRow 函数构建,需要重新写构建实现。不过构建map数据比构建结构体数据要简单,结构体数据需要反射,map直接遍历就行。
// MapExport map导出
func MapExport(heads interface{}, list []map[string]interface{}, sheet, title string, isGhbj bool) (file *excelize.File, err error) {
e, lastRowHead, endColName, dataRow, err := buildCustomHeader(heads, sheet, title)
if err != nil {
return nil, err
}
// 构建数据行
for _, rowData := range list {
startCol := fmt.Sprintf("A%d", dataRow)
endCol := fmt.Sprintf("%s%d", endColName, dataRow)
row := make([]interface{}, 0)
for _, v := range lastRowHead {
if val, ok := rowData[v]; ok {
row = append(row, val)
}
}
if isGhbj && dataRow%2 == 0 {
_ = e.F.SetCellStyle(sheet, startCol, endCol, e.ContentStyle2)
} else {
_ = e.F.SetCellStyle(sheet, startCol, endCol, e.ContentStyle1)
}
_ = e.F.SetRowHeight(sheet, dataRow, float64(25)) // 默认行高25
if err := e.F.SetSheetRow(sheet, fmt.Sprintf("A%d", dataRow), &row); err != nil {
return nil, err
}
dataRow++
}
return e.F, nil
}
buildCustomHeader 这个函数,是用来构建表头的,简单表头、复杂表头都可以构建。往下看就知道了。
实现效果:
复杂表头:多级表头、树形结构表头导出
重点来了,多级表头,按照我之前的想法是:根据表头层级结构,递归表头,计数每级表头有多少个子级,按照子级的数量去合并上级。
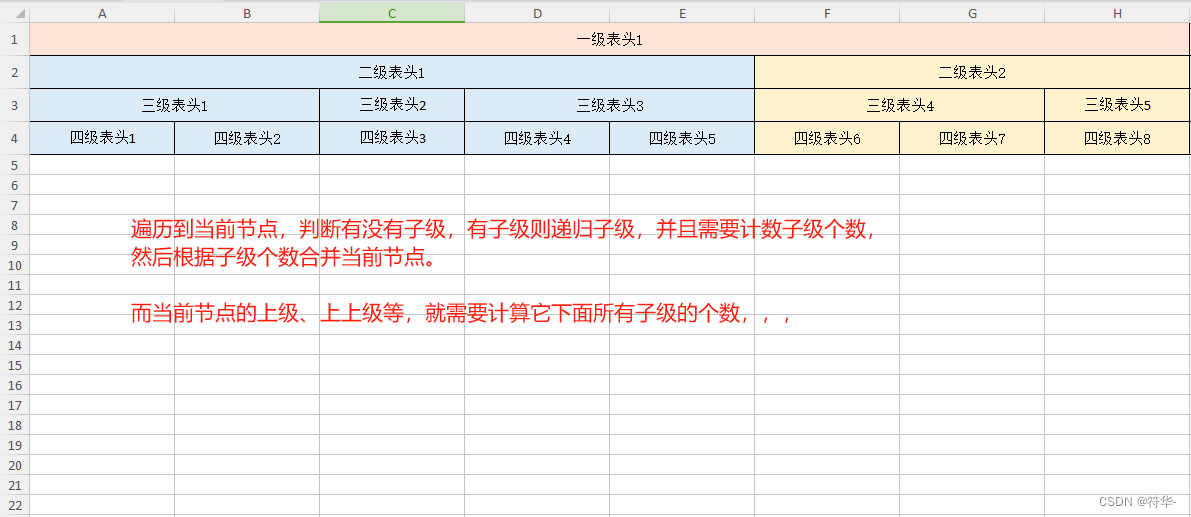
按照这个方法,我是试了又试,合并的单元格总是还差一点,给我搞得没脾气了。。。
后面我突然想到,复杂表头的重点难道不是横向合并单元格吗?!数据行的内容填充肯定是按照最后一级的表头来填充的,最后一级有几列,那数据行就有几列,都是对应的。 而最后一级以上的表头,都是按照相同内容合并的! 那我的表头数据,是不是就不用是树形结构或层级结构? 每级表头只需要按照最后一级表头的数量进行填充就行,相同就相同呗,反正会被合并。
觉得我上面说得绕,那直接看表头数据就明白了:

这种表头数据结构是有顺序的,必须按照从上往下顺序存储。
也就是说,从一级表头开始到二级、三级…最后一级,每一级表头必须按从上往下顺序存储,最后一级表头必须放在数组最后。
并且每一级表头的列数必须一致,所有表头的列数必须以最后一级表头的列数为准,如果列不够填相同的内容即可,后续会将相同的内容的列合并。

构建表头时,如果是相同内容,就会合并。这个方法比较麻烦的一点是,假如表头数据是动态的,比如是从数据库查出来的,那要处理成这种格式,还挺麻烦的应该🤐。
// 复杂表头导出
func ExportTree() {
// map导出
/*header := [][]string{
{"一级表头1", "一级表头1", "一级表头1", "一级表头1", "一级表头1", "一级表头1", "一级表头1", "一级表头1", "一级表头2", "一级表头2", "一级表头2", "一级表头2"},
{"二级表头1", "二级表头1", "二级表头1", "二级表头1", "二级表头1", "二级表头2", "二级表头2", "二级表头2", "二级表头3", "二级表头3", "二级表头3", "二级表头3"},
{"三级表头1", "三级表头1", "三级表头2", "三级表头3", "三级表头3", "三级表头4", "三级表头4", "三级表头5", "三级表头6", "三级表头6", "三级表头6", "三级表头7"},
{"四级表头1", "四级表头2", "四级表头3", "四级表头4", "四级表头5", "四级表头6", "四级表头7", "四级表头8", "四级表头9", "四级表头10", "四级表头11", "四级表头12"},
}
var data = []map[string]interface{}{
{"四级表头1": "1", "四级表头2": "1", "四级表头3": "1", "四级表头4": "4", "四级表头5": "5", "四级表头6": "6", "四级表头7": "7", "四级表头8": "8", "四级表头9": "9", "四级表头10": "10", "四级表头11": "11", "四级表头12": "12"},
{"四级表头1": "11", "四级表头2": "22", "四级表头3": "33", "四级表头4": "44", "四级表头5": "55", "四级表头6": "66", "四级表头7": "77", "四级表头8": "88", "四级表头9": "99", "四级表头10": "100", "四级表头11": "111", "四级表头12": "122"},
{"四级表头1": "111", "四级表头2": "222", "四级表头3": "333", "四级表头4": "444", "四级表头5": "555", "四级表头6": "666", "四级表头7": "777", "四级表头8": "888", "四级表头9": "999", "四级表头10": "1000", "四级表头11": "1111", "四级表头12": "1222"},
}
f, err := excel.MapExport(header, data, "Sheet1", "这里是标题", false)
// 合并表头单元格
// 没有title时,表头从第一行开始合并startRowNum=1;
// 有title时,表头从第二行开始合并,startRowNum=2;
// endRowNum=6,表示内容行开始不再需要合并
excel.HorizontalMerge(f, "Sheet1", 2, 6)*/
// 结构体导出(自定义表头)
header := [][]string{
{"基本信息", "基本信息", "基本信息", "基本信息", "基本信息", "其他信息", "其他信息"},
{"用户信息", "用户信息", "用户信息", "部门信息", "部门信息", "角色信息", "备注"},
{"用户信息", "用户信息", "用户信息", "所属公司", "所在部门", "角色信息", "备注"},
{"用户账号", "用户姓名", "用户邮箱", "所属公司", "所在部门", "角色名称", "备注"},
}
var data = []Test{
{"云墨", "云墨", "云墨", "太虚剑派", false, "1", 1},
{"fuhua", "炽翎", "炽翎", "炽翎", false, "1", 1},
{"月轮", "月轮", "yuelun@123.com", "yuelun@123.com", true, "2", 2},
{"admin", "admin", "admin", "admin", false, "1", 2},
{"符华", "符华", "admin@123.com", "天命科技有限公司", false, "1", 1},
{"chenyue", "chenyue", "chenyue@123.com", "天命科技有限公司", true, "2", 124},
{"鹤熙", "鹤熙", "鹤熙", "天命科技有限公司", true, "2", 124},
}
f, err := excel.CustomHeaderExport("Sheet1", "这里是标题", true, header, data)
if err != nil {
panic(err)
}
// 合并表头单元格
excel.HorizontalMerge(f, "Sheet1", 2, 5)
// 纵向合并数据行内容
excel.VerticalMerge(f, "Sheet1", 1, nil)
// 保存文件
err = f.SaveAs("C:\\Users\\Administrator\\Desktop\\复杂表头导出.xlsx")
if err != nil {
fmt.Println(err)
return
}
fmt.Println("Excel文件已生成")
}
CustomHeaderExport 函数:
// CustomHeaderExport 自定义表头导出
func CustomHeaderExport(sheet, title string, isGhbj bool, heads interface{}, list interface{}) (file *excelize.File, err error) {
e, _, endColName, dataRow, err := buildCustomHeader(heads, sheet, title)
if err != nil {
return
}
dataValue := reflect.ValueOf(list)
// 判断数据的类型
if dataValue.Kind() != reflect.Slice {
err = errors.New("invalid data type")
return
}
// 构造数据行
err = normalBuildDataRow(e, sheet, endColName, "", dataRow, isGhbj, false, dataValue)
return e.F, err
}
构建自定义表头:
// 构建自定义复杂表头
func buildCustomHeader(heads interface{}, sheet, title string) (*model.Excel, []string, string, int, error) {
rowsHead := [][]string{} // 存储多行表头
lastRowHead := []string{} // 最后一行表头
// 类型断言,判断是单行表头还是多行表头
switch heads.(type) {
case []string: // 单行表头
lastRowHead = heads.([]string)
case [][]string: // 复杂表头
// 复杂表头规定:从一级表头开始到二级、三级...最后一级,每一级表头必须按从上往下顺序存储,最后一级表头必须放在数组最后
// 每一级表头的列数必须一致,也就是说所有表头的列数必须以最后一级表头的列数为准,如果列不够填相同的内容即可,后续会将相同的内容的列合并。
// 例如下面这组数据,有四级表头,最后一级有6列,所以一、二、三级表头也需要有6列。然后每一行相同内容的列会合并。
/*header := [][]string{
{"一级表头1", "一级表头1", "一级表头1", "一级表头1", "一级表头2", "一级表头2"},
{"二级表头1", "二级表头1", "二级表头2", "二级表头2", "二级表头3", "二级表头3"},
{"三级表头1", "三级表头1", "三级表头2", "三级表头2", "三级表头3", "三级表头4"},
{"四级表头1", "四级表头2", "四级表头3", "四级表头4", "四级表头5", "四级表头6"},
}*/
rowsHead = heads.([][]string)
lastRowHead = rowsHead[len(rowsHead)-1] // 在多行表头中,获取最后一行表头
default:
return nil, nil, "", 0, errors.New("表头格式错误")
}
e := model.ExcelInit()
index, _ := e.F.GetSheetIndex(sheet)
if index < 0 { // 如果sheet名称不存在
e.F.NewSheet(sheet)
}
endColName := GetExcelColumnName(len(lastRowHead)) // 根据列数生成 Excel 列名
dataRow := 0 // 数据行开始的行号,有title时,默认为3(1 为title行,2 为表头行,3 开始就是数据行,包括了3),无title时默认为2(1 为表头行 2 开始就是数据行,包括了2)
if len(rowsHead) > 0 {
headRowNum := 1 // 第一行表头行号
if title != "" {
dataRow = 1
headRowNum = 2 // 有标题是,为2
buildTitle(e, sheet, title, endColName) // 构建标题
}
// 当有多行表头时,数据行号就是 表头数量+1,
dataRow = dataRow + len(rowsHead) + 1
for i, items := range rowsHead {
err := buildHeader(e, sheet, endColName, i+headRowNum, &items) // 构建表头
if err != nil {
fmt.Println(err)
return nil, nil, "", 0, err
}
}
} else {
dataRow, _ = buildTitleHeader(e, sheet, title, endColName, &lastRowHead) // 构建标题和表头
}
e.F.SetColWidth(sheet, "A", endColName, float64(20)) // 设置列宽
return e, lastRowHead, endColName, dataRow, nil
}
构建标题和表头:
// 构建标题
func buildTitle(e *model.Excel, sheet, title, endColName string) (dataRow int) {
dataRow = 2 // 开始的数据行号,默认为1表示一定有一行表头,数据行从第二行开始
// 标题默认在第一行
if title != "" {
dataRow = 3 // 为3表示有一行标题和一行表头,数据行从第三行开始
e.F.SetCellValue(sheet, "A1", title)
e.F.MergeCell(sheet, "A1", endColName+"1") // 合并标题单元格
e.F.SetCellStyle(sheet, "A1", endColName+"1", e.TitleStyle)
e.F.SetRowHeight(sheet, 1, float64(30)) // 第一行行高
}
return
}
// 构建表头:headerRowNum 当前表头行行号
func buildHeader(e *model.Excel, sheet, endColName string, headerRowNum int, heads *[]string) (err error) {
row := fmt.Sprintf("%d", headerRowNum)
e.F.SetRowHeight(sheet, headerRowNum, float64(30))
e.F.SetCellStyle(sheet, "A"+row, endColName+row, e.HeadStyle)
return e.F.SetSheetRow(sheet, "A"+row, heads)
}
// 构建标题和表头:headerRowNum 当前表头行行号
func buildTitleHeader(e *model.Excel, sheet, title, endColName string, heads *[]string) (dataRow int, err error) {
dataRow = buildTitle(e, sheet, title, endColName) // 构建标题,获取第一行数据所在的行号
// dataRow-1:表头行所在的行号
err = buildHeader(e, sheet, endColName, dataRow-1, heads)
return
}
效果:
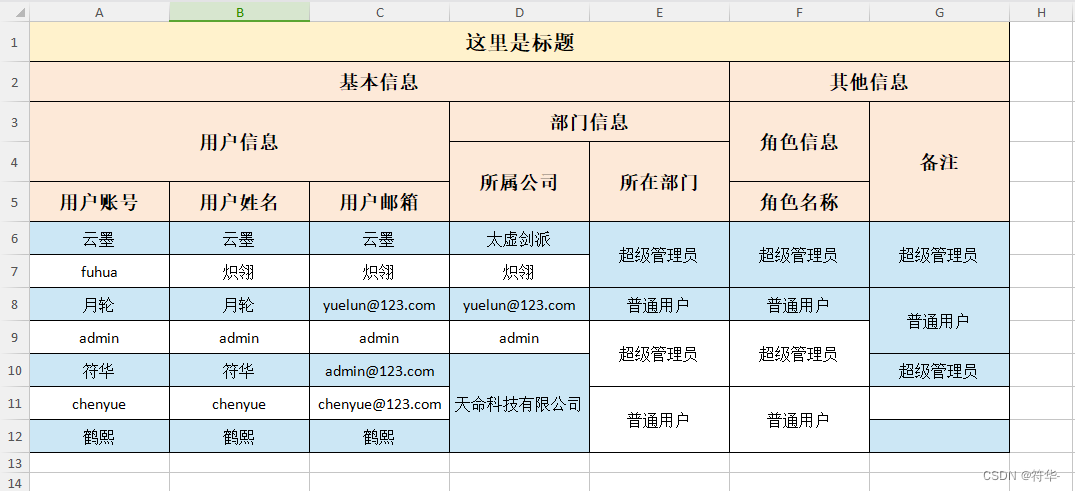
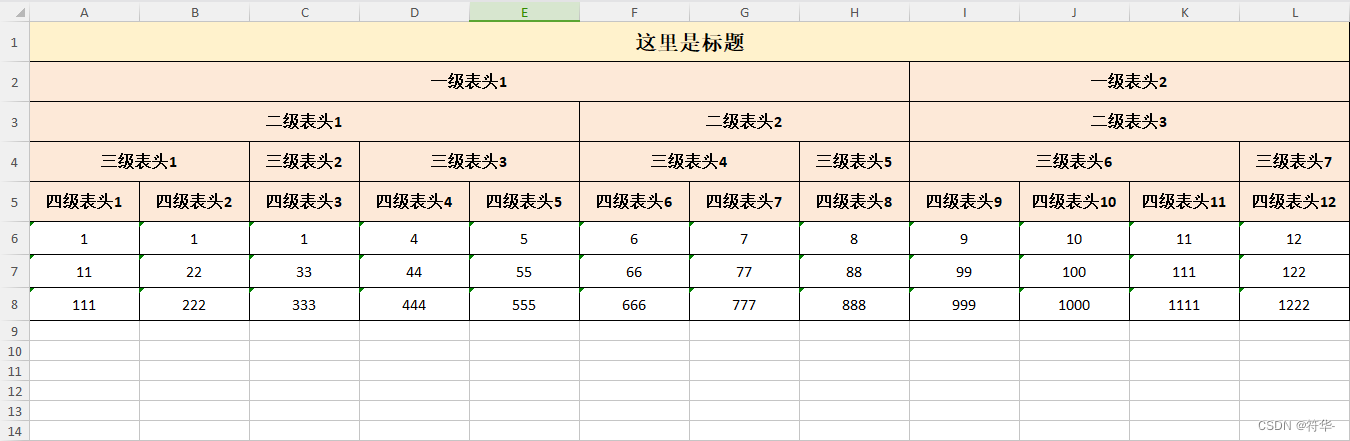
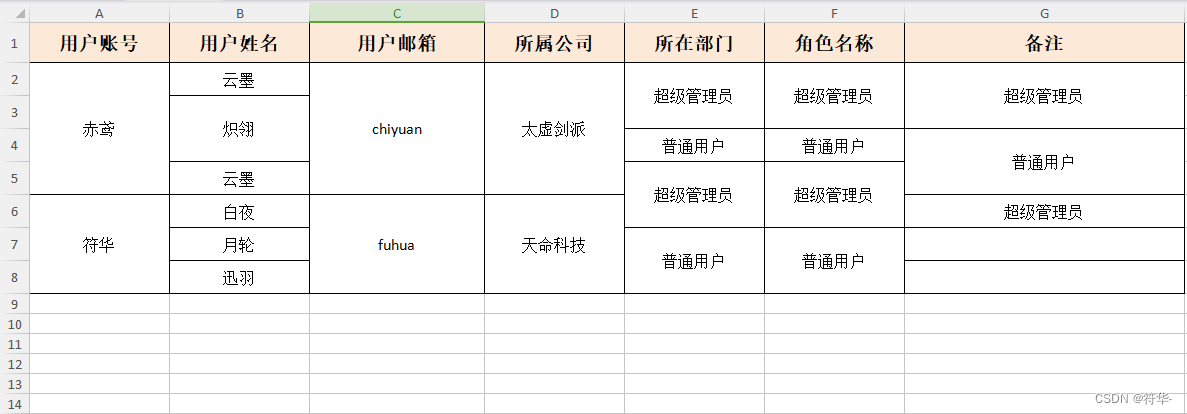
横向合并单元格
上面的复杂表头,就是用到了横向合并。
// 横向合并单元格导出
func ExportHorizontal() {
// 结构体数据导出
var data = []Test{
{"云墨", "云墨", "云墨", "太虚剑派", false, "1", 1}, // A2:C2 , E2:G2
{"fuhua", "炽翎", "炽翎", "炽翎", false, "1", 1}, // B3:D3 , E2:G2
{"月轮", "月轮", "yuelun@123.com", "yuelun@123.com", true, "2", 2}, // A4:B4 , C4:D4 , E4:G4
{"admin", "admin", "admin", "admin", false, "1", 2}, // A5:D5 , E5:F5
{"符华", "符华", "admin@123.com", "天命科技有限公司", false, "1", 1}, // A6:B6 , E6:G6
{"chenyue", "chenyue", "chenyue@123.com", "天命科技有限公司", true, "2", 124}, // A7:B7 , E7:F7
{"鹤熙", "鹤熙", "鹤熙", "天命科技有限公司", true, "2", 124}, // A8:C8 , E8:F8
}
f, err := excel.NormalDynamicExport("Sheet1", "", "", false, false, data, nil)
// map数据导出
/*header := []string{"账号", "姓名", "部门", "角色", "备注"}
var data = []map[string]interface{}{
{"账号": "符华", "姓名": "符华", "部门": "符华", "角色": "太虚剑派", "备注": "太虚剑派"}, // A2:C2 , D2:E2
{"账号": "云墨", "姓名": "云墨", "部门": "太虚剑派", "角色": "太虚剑派", "备注": "太虚剑派"}, // A3:B3 , C3:E3
{"账号": "月轮", "姓名": "月轮", "部门": "天命科技有限公司", "角色": "天命科技有限公司", "备注": "太虚剑派"}, // A4:B4 , C4:D4
{"账号": "鹤熙", "姓名": "天命科技有限公司", "部门": "天命科技有限公司", "角色": "鹤熙", "备注": "鹤熙"}, // B5:C5 , D5:E5
}
f, err := excel.MapExport(header, data, "Sheet1", "", false)*/
if err != nil {
fmt.Println(err)
return
}
// 横向合并单元格:没有标题只有一行表头,所以内容从第二行开始合并 startRowNum=2
excel.HorizontalMerge(f, "Sheet1", 2, -1) // endRowNum = -1,表示全部每一行都需要合并
//excel.HorizontalMerge(f, "Sheet1", 2, 6) // endRowNum = 6,表示第6行开始,后面的行不进行合并(包括第6行)
// 保存文件
err = f.SaveAs("C:\\Users\\Administrator\\Desktop\\横向合并导出.xlsx")
if err != nil {
fmt.Println(err)
return
}
fmt.Println("Excel文件已生成")
}
横向合并规定了开始合并的行号、结束合并的行号:
- startRowNum:开始合并的行号,注意是行号,不是索引,最小从1开始,
- endRowNum:结束合并的行号,最小从1开始。从endRowNum开始,包括endRowNum这一行不进行合并;不需要停止合并的话传 -1。
endRowNum = -1,表示全部的行只要有相同内容,都需要合并;
endRowNum = 6,表示第6行开始,后面的行不进行合并(包括第6行)。
// 横向合并单元格:startRowNum(开始合并的行号,注意是行号从1开始,不是索引)endRowNum(停止合并的行号,从1开始,从endRowNum开始,包括这一行不进行合并;不需要停止合并的话传-1)
func HorizontalMerge(f *excelize.File, sheet string, startRowNum, endRowNum int) {
// startRowNum:比如第一行是标题,第二行是表头,所以从第三行开始合并,startRowNum = 3
rows, _ := f.GetRows(sheet) // 获取sheet的所有行,包括 标题、表头行(如果有标题和表头的话)
// row 行号,从1开始
for row := 1; row <= len(rows); row++ {
if row < startRowNum { // 如果当前行号,小于开始合并的行号,则跳过
continue
}
if endRowNum > 0 && row >= endRowNum { // 如果当前行号,大于等于结束合并的行号,退出合并
break
}
prevValue := "" // 上一单元格的值
mergeStartCol := 0 // 开始合并的单元格列索引
cols := rows[row-1] // 当前行的列数据(当前行每个单元格的数据)
// 遍历单元格时,判断当前单元格和上一单元格的值是否相同,相同继续,不同则判断合并,并且将当前单元格的值和索引,赋值给对应的变量。
/** 比如:a,b,b,b,c,c 这六个单元格的值,
第一个值 a != "",进入判断, i-mergeStartCol = 0-0,不进行合并,prevValue=a,mergeStartCol=0
第二个值 b != a,进入判断,i-mergeStartCol = 1-0,不进行合并,prevValue=b,mergeStartCol=1
第三、四个值 不进入 cellValue != prevValue 的判断,i分别为2、3
第五个值 c != b,进入判断,i-mergeStartCol = 4-1,合并 B1:D1,prevValue=c,mergeStartCol=4
第六个值不进入 cellValue != prevValue 的判断,也结束了for循环,会在 len(cols)-mergeStartCol > 0 这个判断里面进行合并
*/
for i, col := range cols {
cellValue := col // 当前单元格的值
// 如果当前单元格的值和上一个单元格的值不相等
if cellValue != prevValue {
// 当前单元格的列索引 - 开始合并的单元格列索引 大于1,则进行合并
if i-mergeStartCol > 1 {
// 获取开始合并的单元格
startCell := GetExcelColumnName(mergeStartCol+1) + fmt.Sprintf("%d", row)
// 获取结束合并的单元格
endCell := GetExcelColumnName(i) + fmt.Sprintf("%d", row)
//fmt.Print(startCell, ":", endCell, ",")
f.MergeCell(sheet, startCell, endCell)
}
prevValue = cellValue
mergeStartCol = i
}
}
// 如果最后一个值和上一个值不同,则肯定会合并前面的单元格;如果最后一个值和上一个值相同,则会在这个判断里面进行合并
if len(cols)-mergeStartCol > 0 {
startCell := GetExcelColumnName(mergeStartCol+1) + fmt.Sprintf("%d", row)
endCell := GetExcelColumnName(len(cols)) + fmt.Sprintf("%d", row)
//fmt.Println(startCell, ":", endCell)
f.MergeCell(sheet, startCell, endCell)
}
}
}
效果:
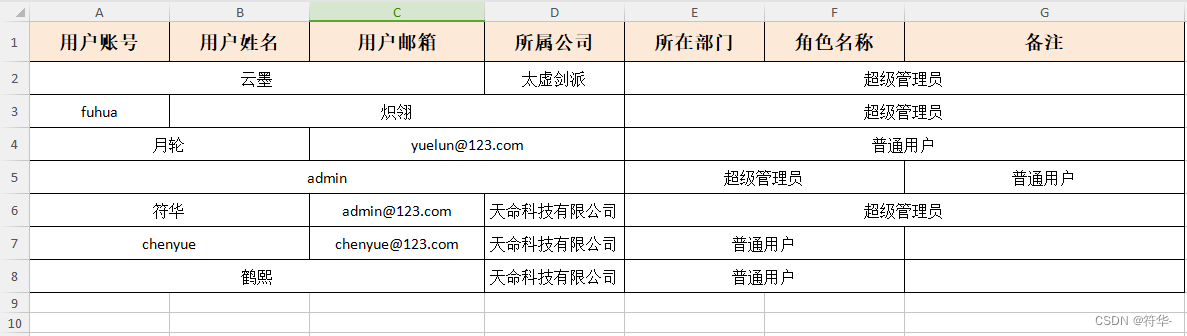
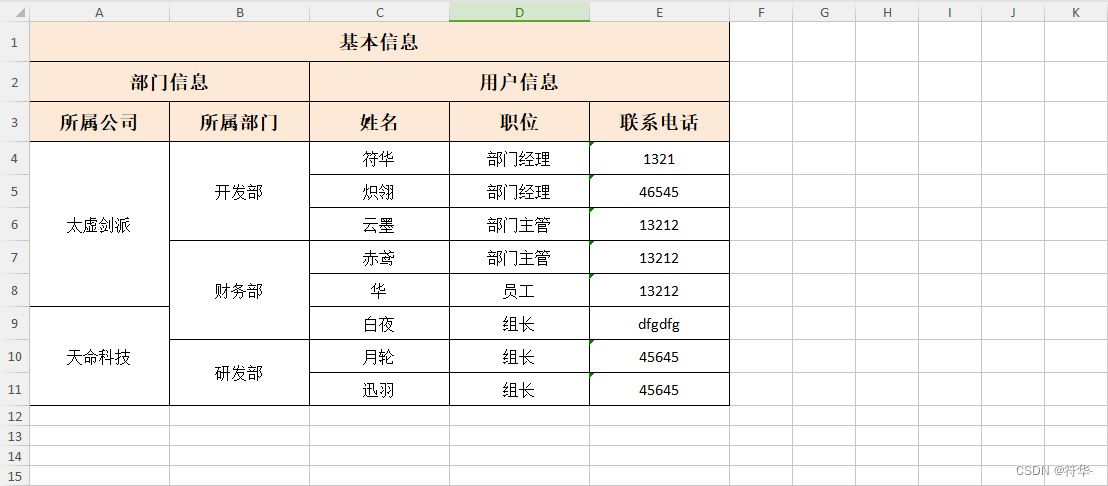
纵向合并单元格
实现方式和横向合并一个道理,只不过横向合并是 从行到列 ,纵向合并是 从列到行 。
// 纵向合并单元格导出
func ExportVertical() {
// map数据
//header := []string{"所属公司", "所属部门", "姓名", "职位", "联系电话"}
header := [][]string{
{"基本信息", "基本信息", "基本信息", "基本信息", "基本信息"},
{"部门信息", "部门信息", "用户信息", "用户信息", "用户信息"},
{"所属公司", "所属部门", "姓名", "职位", "联系电话"},
}
var data = []map[string]interface{}{
{"所属公司": "太虚剑派", "所属部门": "开发部", "姓名": "符华", "职位": "部门经理", "联系电话": "1321"},
{"所属公司": "太虚剑派", "所属部门": "开发部", "姓名": "炽翎", "职位": "部门经理", "联系电话": "46545"},
{"所属公司": "太虚剑派", "所属部门": "开发部", "姓名": "云墨", "职位": "部门主管", "联系电话": "13212"},
{"所属公司": "太虚剑派", "所属部门": "财务部", "姓名": "赤鸢", "职位": "部门主管", "联系电话": "13212"},
{"所属公司": "太虚剑派", "所属部门": "财务部", "姓名": "华", "职位": "员工", "联系电话": "13212"},
{"所属公司": "天命科技", "所属部门": "财务部", "姓名": "白夜", "职位": "组长", "联系电话": "dfgdfg"},
{"所属公司": "天命科技", "所属部门": "研发部", "姓名": "月轮", "职位": "组长", "联系电话": "45645"},
{"所属公司": "天命科技", "所属部门": "研发部", "姓名": "迅羽", "职位": "组长", "联系电话": "45645"},
}
f, err := excel.MapExport(header, data, "Sheet1", "", false)
if err != nil {
panic(err)
}
needColIndex := []int{1, 2} // 需要合并的列号,比如只需要合并第一列和第二列
// 横向合并表头行内容
excel.HorizontalMerge(f, "Sheet1", 1, 4)
// 纵向合并数据行内容
excel.VerticalMerge(f, "Sheet1", 0, needColIndex)
// 结构体数据导出
/*var data = []Test{
{"赤鸢", "云墨", "chiyuan", "太虚剑派", false, "1", 1},
{"赤鸢", "炽翎", "chiyuan", "太虚剑派", false, "1", 1},
{"赤鸢", "炽翎", "chiyuan", "太虚剑派", true, "2", 2},
{"赤鸢", "云墨", "chiyuan", "太虚剑派", false, "1", 2},
{"符华", "白夜", "fuhua", "天命科技", false, "1", 1},
{"符华", "月轮", "fuhua", "天命科技", true, "2", 121},
{"符华", "迅羽", "fuhua", "天命科技", true, "2", 121},
}
f, err := excel.NormalDynamicExport("Sheet1", "", "", false, false, data, nil)
if err != nil {
panic(err)
}
// 纵向合并内容单元格
excel.VerticalMerge(f, "Sheet1", 0, nil)*/
// 保存文件
err = f.SaveAs("C:\\Users\\Administrator\\Desktop\\纵向合并导出.xlsx")
if err != nil {
fmt.Println(err)
return
}
fmt.Println("Excel文件已生成")
}
纵向合并,有两参数:
headIndex :表头所在索引,一般情况下,不管表头有多少行,只要有 title 标题 headIndex都传1,无 title 标题传0 。
needColIndex :需要合并的列号,注意不是列索引,列号从1开始,如全部列有相同内容都需合并,传nil就行。
// 纵向合并单元格:headIndex 表头所在索引(一般情况下,不管表头有多少行,只要有标题headIndex都传1,无标题传0)
// needColIndex 需要合并的列号(列号从1开始,如全部列都需合并,传nil就行)
func VerticalMerge(f *excelize.File, sheet string, headIndex int, needColIndex []int) {
rows, _ := f.GetRows(sheet) // 获取sheet的所以行,包括 标题、表头行(如果有标题和表头的话)
// 遍历每一列
for colIndex := 1; colIndex <= len(rows[headIndex]); colIndex++ {
if len(needColIndex) > 0 && !model.IsContain(needColIndex, colIndex) {
continue
}
startRow := headIndex + 1 // 开始合并的行号
endRow := headIndex + 1 // 结束结束的行号
prevValue := rows[headIndex][colIndex-1]
// 遍历每一行
for rowIndex := headIndex; rowIndex < len(rows); rowIndex++ {
row := rows[rowIndex]
// 因为获取rows时,会忽略空单元格,如果存在空单元格,那每一行的列数并不是相同的,所以需要判断列号是否大于当前行的列数
if colIndex <= len(row) {
// 判断当前单元格的值和上一个单元格的值是否相同
if row[colIndex-1] == prevValue {
endRow = rowIndex + 1 // 相同,则更新结束合并的行号
} else {
if startRow != endRow {
colName := GetExcelColumnName(colIndex)
f.MergeCell(sheet, colName+fmt.Sprintf("%d", startRow), colName+fmt.Sprintf("%d", endRow))
}
startRow = rowIndex + 1
endRow = rowIndex + 1
prevValue = row[colIndex-1]
}
}
}
// 处理最后一组相同内容的单元格
if startRow != endRow {
colName := GetExcelColumnName(colIndex)
f.MergeCell(sheet, colName+fmt.Sprintf("%d", startRow), colName+fmt.Sprintf("%d", endRow))
}
}
}
效果:
最后
好歹是把坑给填上了😂😁
除了上面说的几个复杂导出,其实还有一个很重要的导出,那就是用模板导出。然而 excelize 库并不支持类似Java easypoi 的模板指令,这么看来 excelize 库好像不支持用模板导出?得想其他办法实现这个功能,所以下一篇我们来讲讲Go中如何用excel模板导出excel表格。
后续等功能都实现得差不多了,测试完了没什么问题了,我会放出完整代码。
如果大家觉得本篇文章或专栏对你有所帮助或者觉得写得还可以的话,欢迎大家多多给博主 点赞 加 关注 支持一下哦😘你动动手指就是对我莫大的鼓励🥰