这个是继上一篇文章 “Elasticsearch:Serarch tutorial - 使用 Python 进行搜索 (一)” 的续篇。在今天的文章中,我们接着来完成如何进行分页及过滤。
分页 - pagination
应用程序处理大量结果通常是不切实际的。 因此,API 和 Web 服务使用分页控件来允许应用程序请求小块或页面的结果。
你可能已经注意到,Elasticsearch 默认情况下不会返回超过 10 个结果。 可以在搜索请求中给出可选的大小参数来更改此最大值。 以下示例要求最多返回 5 个搜索结果:
results = es.search(
query={
'multi_match': {
'query': query,
'fields': ['name', 'summary', 'content'],
}
}, size=5
)要访问结果的其他页面,请使用 from_ 参数,该参数指示从完整结果列表中的位置开始(因为 from 是 Python 中的保留关键字,所以使用 from_ )。
下一个示例检索第二页 5 个结果:
results = es.search(
query={
'multi_match': {
'query': query,
'fields': ['name', 'summary', 'content'],
}
}, size=5, from_=5
)让我们将 size 和 from_ 合并到 app.py 中的 handle_search() 端点中:
@app.post('/')
def handle_search():
query = request.form.get('query', '')
from_ = request.form.get('from_', type=int, default=0)
results = es.search(
query={
'multi_match': {
'query': query,
'fields': ['name', 'summary', 'content'],
}
}, size=5, from_=from_
)
return render_template('index.html', results=results['hits']['hits'],
query=query, from_=from_,
total=results['hits']['total']['value'])此处页面大小现已硬编码为 5(你可以随意使用您喜欢的任何其他数字)。 假定 from_ 参数作为提交表单中的附加字段给出,但该字段被认为是可选的,不存在时默认为 0。
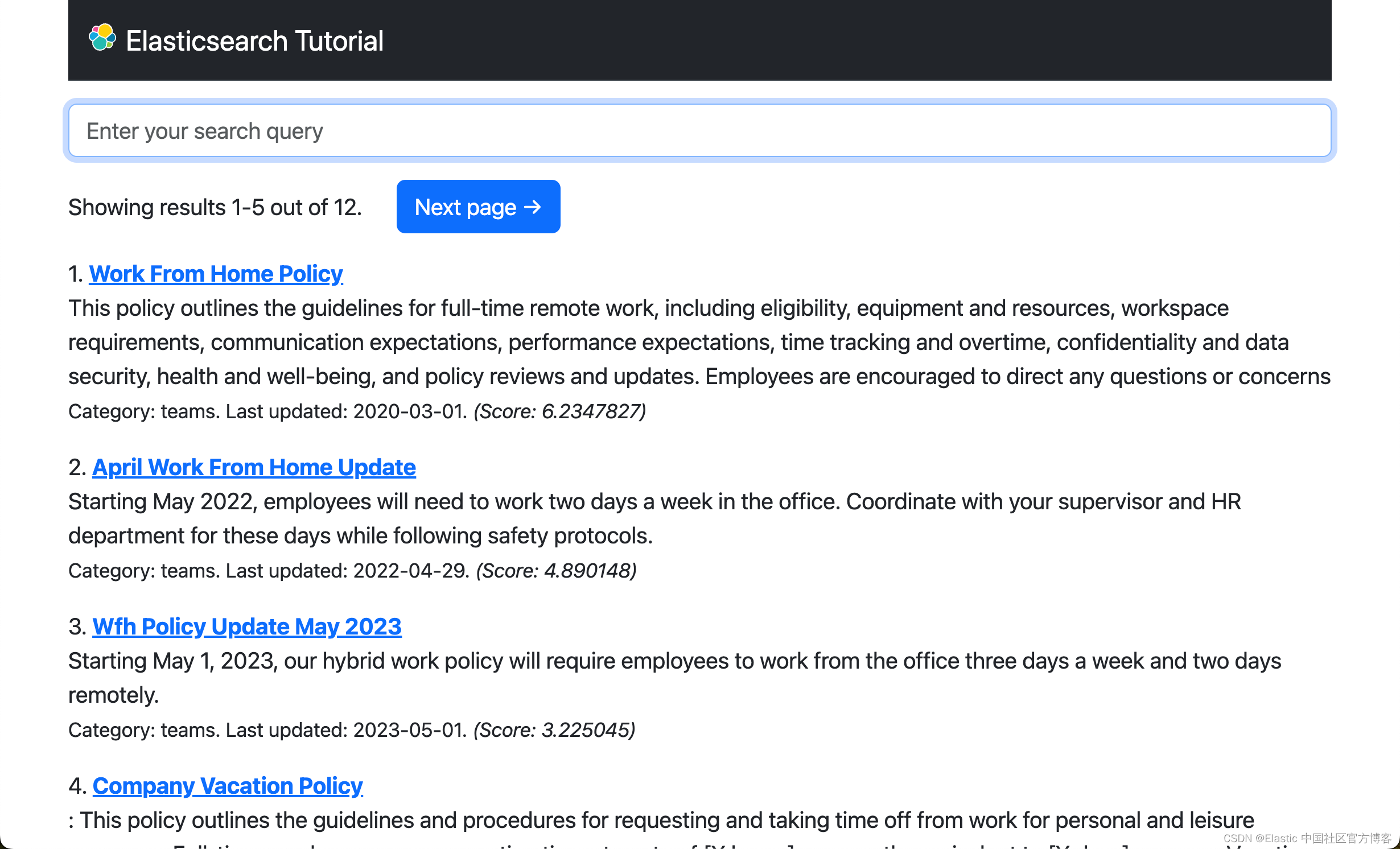
index.html 中可用的搜索表单没有 from_ 字段,因此常规搜索将始终从第一个结果开始。 该模板显示有关所显示结果范围以及总数的信息。 以下是使用模板表达式完成此操作的方法:
<div class="col-sm-auto my-auto">
Showing results {{ from_ + 1 }}-{{ from_ + results|length }} out of {{ total }}.
</div>该模板还包括显示分页按钮以在结果列表中向前或向后移动的逻辑。 这是 “Previous results” 按钮的实现:
{% if from_ > 0 %}
<div class="col-sm-auto my-auto">
<a href="javascript:history.back(1)" class="btn btn-primary">← Previous page</a>
</div>
{% endif %}
正如您所看到的,只有当 from_ 大于零时,“Previous page” 按钮才会呈现到页面。 该按钮的实现使用浏览器的历史 API 来返回一页。
“Next page” 按钮有一个更有趣的实现:
{% if from_ + results|length < total %}
<div class="col-sm-auto my-auto">
<form method="POST">
<input type="hidden" name="query" value="{{ query }}">
<input type="hidden" name="from_" value="{{ from_ + results|length }}">
<button type="submit" class="btn btn-primary">Next page →</button>
</form>
</div>
{% endif %}该按钮实际上并不是一个独立的按钮,而是一个完整的表单,除了按钮之外还有两个隐藏字段。 该表单与主搜索表单类似,但包含可选的 from_ 字段,调整为指向下一页结果。 单击此按钮时,Flask 应用程序将从该备用表单接收搜索请求,该表单使用相同的文本查询,但使用非零的 from_ 值。
通过这种小而巧妙的分页实现,你将能够浏览多页结果。

过滤 - Filters
许多应用程序需要让用户能够自定义查询,以补充搜索查询本身的功能。 在本章中,你将学习过滤,这是一种技术,可以指定仅对满足给定条件的索引中包含的文档子集执行搜索查询。
布尔查询简介
在实现过滤器之前,你必须了解复合查询是如何在 Elasticsearch 中实现的。
复合查询允许应用程序组合两个或多个单独的查询,以便它们一起执行,并在适当的情况下返回一组组合结果。 在 Elasticsearch 中创建复合查询的标准方法是使用布尔查询。
布尔查询充当两个或多个单独查询或子句的包装器。 有四种不同的方式来组合查询:
- bool.must:子句必须匹配。 如果给出多个子句,则所有子句都必须匹配(类似于 AND 逻辑运算)。
- bool.should:当不带 must 使用时,至少一个子句应该匹配(类似于 OR 逻辑运算)。 当与 must 结合使用时,每个匹配子句都会提高文档的相关性得分。
- bool.filter:只有与子句匹配的文档才被视为搜索结果候选。
- bool.must_not:只有与子句不匹配的文档才被视为搜索结果候选。
有关布尔查询的更多描述,请参阅文章 “开始使用 Elasticsearch (2)”。
正如你可能从上面猜到的那样,布尔查询涉及相当多的复杂性,并且可以通过多种方式使用。 在本章中,你将学习如何将前面章节中实现的多重匹配全文搜索子句与将结果限制为一类文档的过滤器相结合。 回想一下,本教程使用的数据集包含一个 category 字段,可以设置为 sharepoint、teams 或 github。
向查询添加过滤器
当前在教程应用程序中实现的多重匹配查询使用以下结构:
{
'multi_match': {
'query': "query text here",
'fields': ['name', 'summary', 'content'],
}
}
要添加将此搜索限制为特定类别的过滤器,必须按如下方式扩展查询:
{
'bool': {
'must': [{
'multi_match': {
'query': "query text here",
'fields': ['name', 'summary', 'content'],
}
}],
'filter': [{
'term': {
'category.keyword': {
'value': "category to filter"
}
}
}]
}
}让我们详细看看该查询中的新组件。
首先,multi_match 查询已移至 bool.must 子句内。 bool.must 子句通常是定义基本查询的地方。 请注意,must 接受要搜索的查询列表,因此这允许在需要时组合多个基本级查询。
过滤是在 bool.filter 部分中使用新的查询类型(term 查询)实现的。 对过滤器使用 match 或 multi_match 查询并不是一个好主意,因为这些是全文搜索查询。 为了过滤的目的,查询必须为每个文档返回绝对正确或错误的答案,而不是像匹配查询那样返回相关性分数。
Term 查询对给定字段中的值执行精确搜索。 这种类型的查询对于搜索标识符、标签、标记或本例中的类别很有用。
此查询不适用于为全文搜索建立索引的字段。 字符串字段被分配为默认的 text 类型,并在索引之前对其内容进行分析并分成单独的单词。 Elasticsearch 为字符串字段分配了辅助类型的 keyword 字段,该关键字将字段内容作为一个整体进行索引,使它们更适合使用术语(term)查询进行过滤。 通过在查询的过滤器部分中使用 category.keyword 的字段名称,将使用该字段的 keyword 类型变体,而不是默认的 text 变体。
更多有关 text 及 keyword 之间的区别,请详细阅读文章 “Elasticsearch:Text vs. Keyword - 它们之间的差异以及它们的行为方式”。
指定过滤器
在实现过滤查询之前,需要添加一种方式供最终用户输入所需的过滤器。 本教程中实现的解决方案将在搜索查询的文本中查找 “category:<category-name>” 模式。 让我们向 add.py 添加一个名为 extract_filters() 的函数来查找过滤器表达式:
def extract_filters(query):
filter_regex = r'category:([^\s]+)\s*'
m = re.search(filter_regex, query)
if m is None:
return {}, query # no filters
filters = {
'filter': [{
'term': {
'category.keyword': {
'value': m.group(1)
}
}
}]
}
query = re.sub(filter_regex, '', query).strip()
return filters, query
该函数接受用户输入的查询,并返回一个元组,其中包含在查询中找到的过滤器以及删除过滤器后修改后的查询。 为了查找过滤模式,它使用正则表达式。 如果需要,该功能可以通过附加过滤器进行扩展。
为了更好地理解此功能的工作原理,请启动 Python 会话(确保首先激活虚拟环境)并运行以下代码:
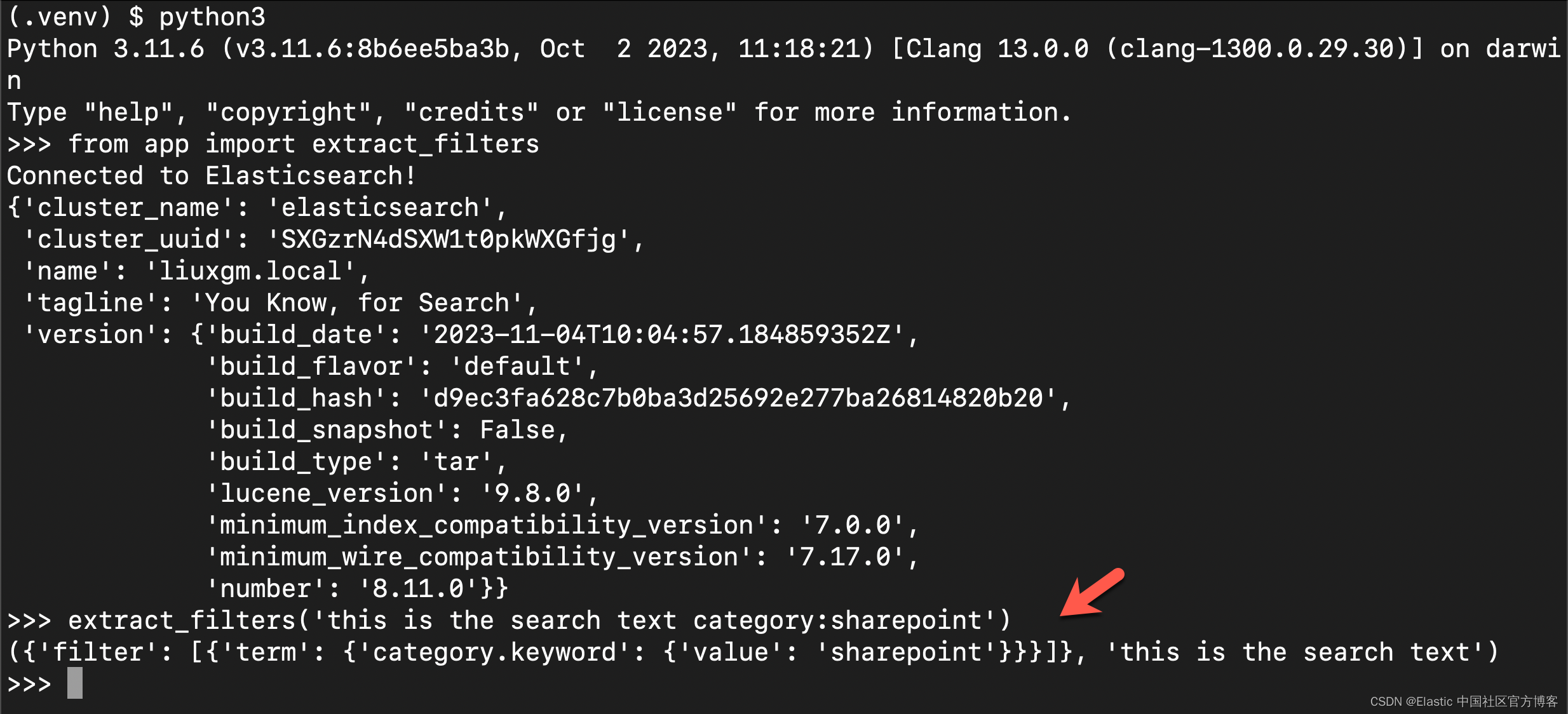
实施过滤搜索
剩下要做的就是更改 handle_search() 函数以发送更新的查询,该查询将全文搜索表达式与过滤器(如果用户给出了过滤器)组合在一起。 以下是该函数的新版本:
@app.post('/')
def handle_search():
query = request.form.get('query', '')
filters, parsed_query = extract_filters(query)
from_ = request.form.get('from_', type=int, default=0)
results = es.search(
query={
'bool': {
'must': {
'multi_match': {
'query': parsed_query,
'fields': ['name', 'summary', 'content'],
}
},
**filters
}
}, size=5, from_=from_
)
return render_template('index.html', results=results['hits']['hits'],
query=query, from_=from_,
total=results['hits']['total']['value'])查询现已更改为发送 bool 表达式,并且搜索表达式已移至其下方的 must 部分内。 extract_filters() 函数以需要发送到 Elasticsearch 的形式返回查询的过滤器部分,因此它也被插入到查询字典中的顶级 bool 键下。
尝试搜索查询(例如 work from home Category:sharepoint)以查看如何仅返回给定类别 (category) 的文档。
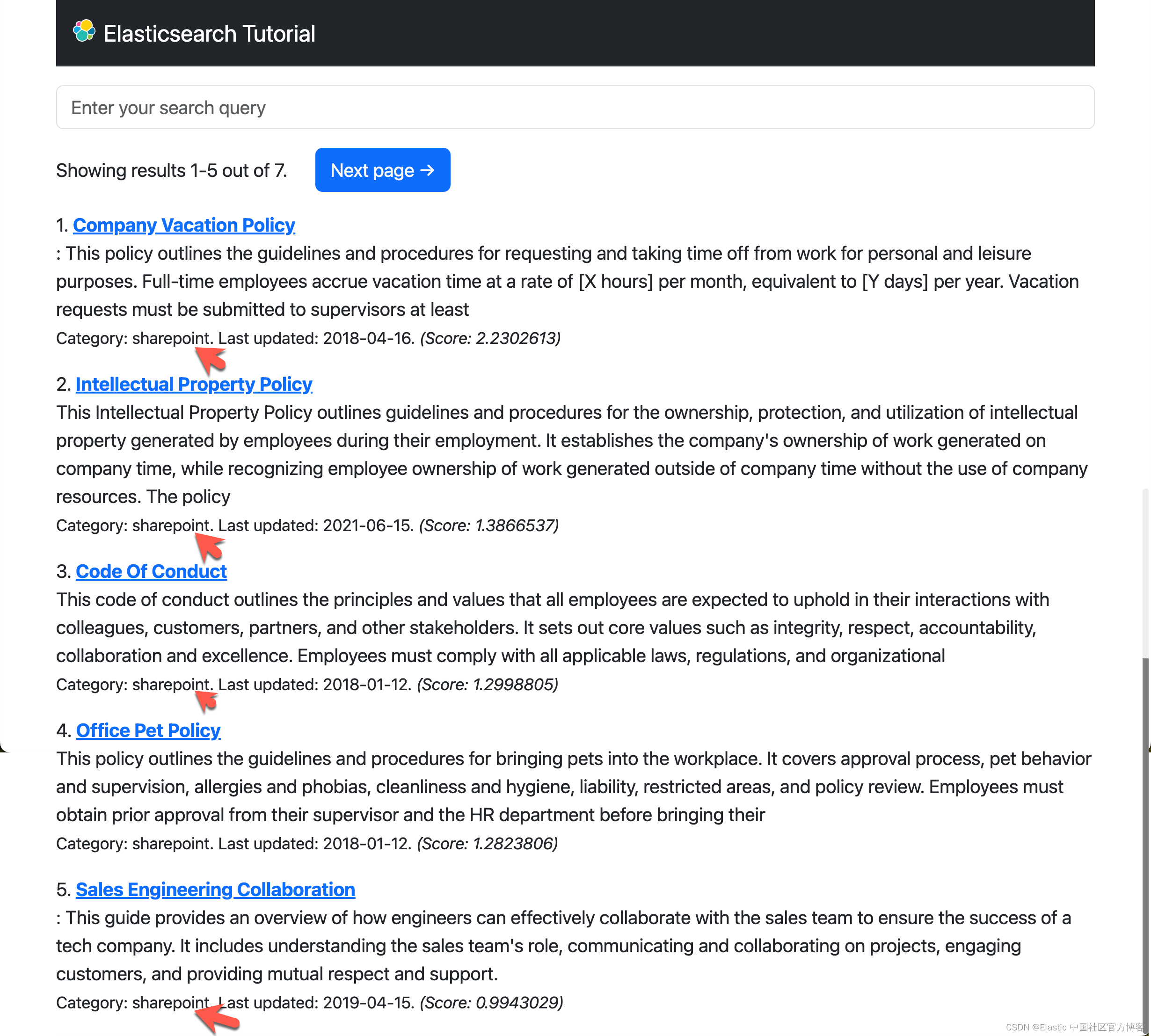
从上面的结果中,我们可以看出来所有的文档的 Category 都是 sharepoint。
Match-all 查询
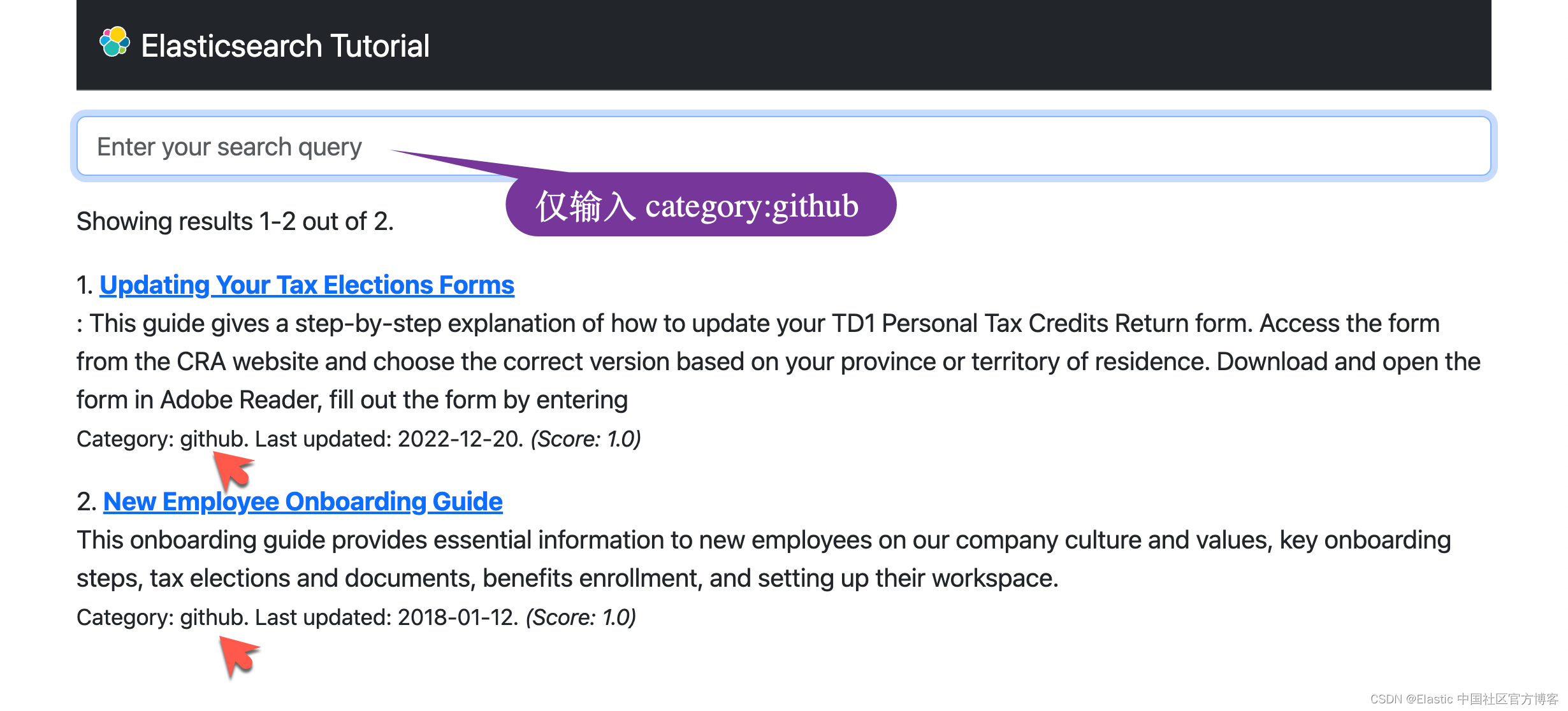
在转到新主题之前,请尝试在搜索查询文本字段中仅输入过滤器,例如 category:github。 不幸的是,这不会返回任何结果,但在这种情况下的预期行为是接收与请求的类别匹配的所有结果。

发生的情况是 extract_filters() 函数返回一个元组,其中第一个元素中包含过滤器,第二个元素中包含空查询字符串。 match_all 查询接收空字符串,并返回空结果列表,因为没有任何内容与空字符串匹配。
为了解决这种特殊情况,当搜索文本为空时,可以将 multi_match 查询替换为 match_all。 下面的 handle_search() 函数版本添加了执行此操作的逻辑。 更新app.py 中的函数。
@app.post('/')
def handle_search():
query = request.form.get('query', '')
filters, parsed_query = extract_filters(query)
from_ = request.form.get('from_', type=int, default=0)
if parsed_query:
search_query = {
'must': {
'multi_match': {
'query': parsed_query,
'fields': ['name', 'summary', 'content'],
}
}
}
else:
search_query = {
'must': {
'match_all': {}
}
}
results = es.search(
query={
'bool': {
**search_query,
**filters
}
}, size=5, from_=from_
)
return render_template('index.html', results=results['hits']['hits'],
query=query, from_=from_,
total=results['hits']['total']['value'])在此版本中,你可以询问与某个类别匹配的所有文档。 请注意,所有返回的结果都具有相同的 1.0 分数,因为没有搜索词来计算分数。
 恭喜,你已完成本教程的全文搜索部分! 单击此处查看到目前为止教程搜索应用程序的状态。你可以使用如下的命令来下载代码:
恭喜,你已完成本教程的全文搜索部分! 单击此处查看到目前为止教程搜索应用程序的状态。你可以使用如下的命令来下载代码:
git clone https://github.com/liu-xiao-guo/search-tutorial-1