1.AlexNet概述
论文原文:ImageNet Classification with Deep Convolutional Neural Networks
在LeNet提出后,卷积神经网络在计算机视觉和机器学习领域中很有名气。但卷积神经网络并没有主导这些领域。这是因为虽然LeNet在小数据集上取得了很好的效果,但是在更大、更真实的数据集上训练卷积神经网络的性能和可行性还有待研究。事实上,在上世纪90年代初到2012年之间的大部分时间里,神经网络往往被其他机器学习方法超越,如支持向量机(support vector machines)。
虽然上世纪90年代就有了一些神经网络加速卡,但仅靠它们还不足以开发出有大量参数的深层多通道多层卷积神经网络。此外,当时的数据集仍然相对较小。除了这些障碍,训练神经网络的一些关键技巧仍然缺失,包括启发式参数初始化、随机梯度下降的变体、非挤压激活函数和有效的正则化技术。
2012年,AlexNet横空出世。它首次证明了深度卷积神经网络学习到的特征可以超越手工设计的特征。它一举打破了计算机视觉研究的现状。 AlexNet使用了8层卷积神经网络,并以很大的优势赢得了2012年ImageNet图像识别挑战赛。
AlexNet和LeNet的设计理念非常相似,但也存在显著差异。
-
AlexNet比相对较小的LeNet5要深得多。AlexNet由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层。
-
AlexNet使用ReLU而不是sigmoid作为其激活函数。ReLU 能够在保持计算速度的同时,有效地解决了梯度消失问题,从而使得训练更加高效
-
局部响应归一化(Local response nomalization,LRN)。后来发现没什么用。
-
在全连接层使用了dropout用于正则化
-
分布式训练。在当时GPU性能并不高,内存比较小,AlexNet在使用GPU进行训练时,可将卷积层和全连接层分别放到不同的GPU上进行并行计算,从而大大加快了训练速度。
整个网络结构图如下,网络结构被切割为两部分,每个GPU单独计算一半的通道数,其中会互相通信两次。输入尺寸是227,224是论文中写错了。

当然从现在的计算资源来看,AlexNet是一个非常简单的神经网络,已经不再需要分到2个GPU上并行计算了,于是网络结构可以简化如下

2.网络结构详解
1.输入层。227 × 227 × 3,三通道RGB图像
2.C1
- 卷积。96个11×11×3的卷积核,padding = 0,stride = 4。特征图尺寸为((227-11)/4)+1=55,得到输出55×55×96的特征图
- ReLU激活
- 最大池化。核大小为3×3,padding = 0,stride = 2,特征图尺寸为((55-3)/2)+1=27,得到输出27×27×96的特征图
3.C2
- 卷积。256个5×5×96的卷积核,padding = 2,stride = 1。特征图尺寸为((27-5+2×2)/1)+1=27,得到输出27×27×256的特征图
- ReLU激活
- 最大池化。核大小为3×3,padding = 0,stride = 2,特征图尺寸为((27-3)/2)+1=13,得到输出13×13×256的特征图
4.C3
- 卷积。384个3×3×256的卷积核,padding = 1,stride = 1。特征图尺寸为((13-3+2×1)/1)+1=13,得到输出13×13×384的特征图
- ReLU激活
5.C4
- 卷积。384个3×3×384的卷积核,padding = 1,stride = 1。特征图尺寸为((13-3+2×1)/1)+1=13,得到输出13×13×384的特征图
- ReLU激活
6.C5
- 卷积。256个3×3×384的卷积核,padding = 1,stride = 1。特征图尺寸为((13-3+2×1)/1)+1=13,得到输出13×13×256的特征图
- ReLU激活
- 最大池化。核大小为3×3,padding = 0,stride = 2,特征图尺寸为((13-3)/2)+1=6,得到输出6×6×256的特征图
7.全连接层FC6
- 全局平均池化然后展平。
- 全连接,6×6×256–>>1×1×4096,并使用Dropout,随机50%神经元弃用
- ReLU激活
8.全连接层FC7
- 全连接,1×1×4096–>>1×1×4096,并使用Dropout,随机50%神经元弃用
- ReLU激活
9.全连接层FC8
全连接,1×1×4096–>>1×1×1000。1000是ImageNet1000个分类类别
3.AlexNet实现CIFAR-10分类
1.读取数据集
CIFAR-10数据集是32*32尺寸的,但AlexNet网络结构是针对ImageNet大尺寸设计的,但ImageNet数据集作为简单实践的话又太大了。这里直接简单的将图片拉大,但实际上这并不是一个好的操作,这里只是简单实践,毕竟AlexNet现在并不常使用。
# 数据预处理
transform = transforms.Compose([
transforms.Resize((224, 224)), # AlexNet接受224x224的输入
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
# 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./dataset', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10(root='./dataset', train=False, download=True, transform=transform)
# 数据加载器
train_dataloader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=64, shuffle=False)这个归一化的数据来源于ImageNet数据集百万张统计得到,通常可以作为一般数据集的归一化标准。当然也可以针对自己数据集重新计算均值和标准差用于归一化。
2.搭建AlexNet
dropout默认是0.5的概率,用于全连接之间
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
# 打印模型结构
model = AlexNet().to(device)
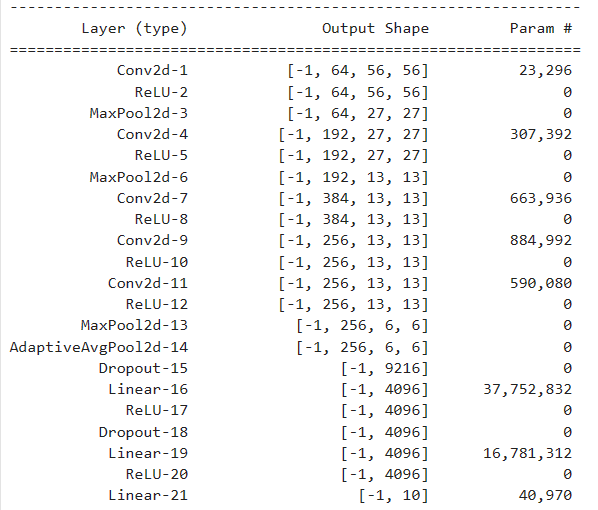
summary(model, (3, 227, 227))
3.使用GPU
device = 'cuda' if torch.cuda.is_available() else 'cpu'4.模型训练
def train(model, lr, epochs, train_dataloader, device, save_path):
# 将模型放入GPU
model = model.to(device)
# 使用交叉熵损失函数
loss_fn = nn.CrossEntropyLoss().to(device)
# SGD
optimizer = torch.optim.SGD(model.parameters(), lr=lr, weight_decay=5e-4, momentum=0.9)
# 记录训练与验证数据
train_losses = []
train_accuracies = []
# 开始迭代
for epoch in range(epochs):
# 切换训练模式
model.train()
# 记录变量
train_loss = 0.0
correct_train = 0
total_train = 0
# 读取训练数据并使用 tqdm 显示进度条
for i, (inputs, targets) in tqdm(enumerate(train_dataloader), total=len(train_dataloader), desc=f"Epoch {epoch+1}/{epochs}", unit='batch'):
# 训练数据移入GPU
inputs = inputs.to(device)
targets = targets.to(device)
# 模型预测
outputs = model(inputs)
# 计算损失
loss = loss_fn(outputs, targets)
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 使用优化器优化参数
optimizer.step()
# 记录损失
train_loss += loss.item()
# 计算训练正确个数
_, predicted = torch.max(outputs, 1)
total_train += targets.size(0)
correct_train += (predicted == targets).sum().item()
# 计算训练正确率并记录
train_loss /= len(train_dataloader)
train_accuracy = correct_train / total_train
train_losses.append(train_loss)
train_accuracies.append(train_accuracy)
# 输出训练信息
print(f"Epoch [{epoch + 1}/{epochs}] - Train Loss: {train_loss:.4f}, Train Acc: {train_accuracy:.4f}")
# 绘制损失和正确率曲线
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(range(epochs), train_losses, label='Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(range(epochs), train_accuracies, label='Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.tight_layout()
plt.show()
torch.save(model.state_dict(), save_path)model = AlexNet(num_classes=10) # 十分类
lr = 0.01
epochs = 10
save_path = './modelWeight/AlexNet_CIFAR10'
train(model,lr,epochs,train_dataloader,device,save_path)

这里只训练了10个epoch,也没有使用验证集调参,仅仅是简单实践而已。可以看到损失还在不断降低,还没收敛。
5.模型测试
def test(model, test_dataloader, device, model_path):
# 将模型设置为评估模式
model.eval()
# 将模型移动到指定设备上
model.to(device)
# 从给定路径加载模型的状态字典
model.load_state_dict(torch.load(model_path))
correct_test = 0
total_test = 0
# 不计算梯度
with torch.no_grad():
# 遍历测试数据加载器
for inputs, targets in test_dataloader:
# 将输入数据和标签移动到指定设备上
inputs = inputs.to(device)
targets = targets.to(device)
# 模型进行推理
outputs = model(inputs)
# 获取预测结果中的最大值
_, predicted = torch.max(outputs, 1)
total_test += targets.size(0)
# 统计预测正确的数量
correct_test += (predicted == targets).sum().item()
# 计算并打印测试数据的准确率
test_accuracy = correct_test / total_test
print(f"Accuracy on Test: {test_accuracy:.4f}")
return test_accuracymodel_path = './modelWeight/AlexNet_CIFAR10'
test(model, test_dataloader, device, save_path)![]()
6.使用Pytorch自带的AlexNet
Pytorch有官方实现的AlexNet以及它在ImageNet上预训练好的权重,如果数据集的分类类别都在ImageNet中存在,而且想快速训练,可以使用预训练好的权重。地址:alexnet — Torchvision main documentation (pytorch.org)
此外还需要修改最后一层全连接层的输出数目
from torchvision import models
# 初始化预训练的AlexNet模型
modelPre = models.alexnet(weights=models.AlexNet_Weights.DEFAULT)
num_ftrs = modelPre.classifier[6].in_features
modelPre.classifier[6] = nn.Linear(num_ftrs, 10) # CIFAR-10有10个类别
modelPre = modelPre.to(device)
summary(modelPre, (3, 227, 227)).DEFAULT就是使用默认最新最好的预训练权重,直接指定weights=models.AlexNet_Weights.IMAGENET1K_V1也是一样的,因为AlexNet在pytroch中只有一个权重,其他模型会有多个版本权重可以在官方文档中看。
如果只想使用他的模型而不使用预训练权重,直接不设定这个参数就可以了。
可以看到除了多了个全局平均池化,其他都和我们自己写的是一样的。因为AlexNet出来的时候并没有全局平均池化这个操作,不过现在在过度卷积和全连接都是这么做的。
lr = 0.01
epochs = 10
save_path = './modelWeight/AlexNetPreTrain_CIFAR10'
train(modelPre,lr,epochs,train_dataloader,device,save_path)可以看到收敛更快

lr = 0.01
epochs = 10
save_path = './modelWeight/AlexNetPreTrain_CIFAR10'
train(modelPre,lr,epochs,train_dataloader,device,save_path) ![]()