数据库的三大范式
设计关系数据库时,需要遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,越高的范式数据冗余度越低。
实际开发中涉及到的范式一般有三种:第一范式、第二范式、第三范式。
第一范式
如果数据库中的每一列属性都是不可分解的原子值,那么说明这个数据库满足第一范式。

这里的地址可以再分为国家和省份,因此不满足第一范式,进行改造之后如下,满足了第一范式:

第二范式
第二范式在第一范式的基础上,消除了非主属性对主属性的部分函数依赖。简单来讲,就是表中的每一列都要和主键有关,而不能只与主键的某一部分相关。
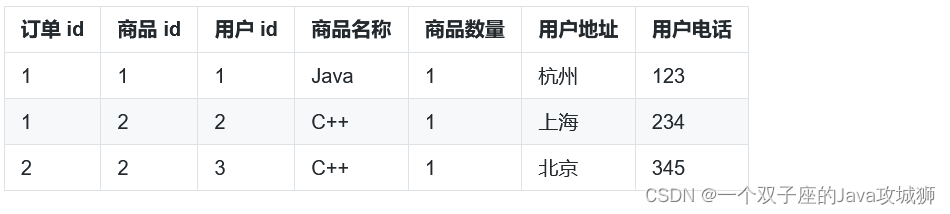 以这样一组数据为例,七个字段在业务中不可再拆分,因此满足第一范式。同一个订单会有多个商品,所以主键是订单 id 和商品 id,但是商品名称仅依赖于商品 id,不满足表中的每一列都要和主键有关,而不能只与主键的某一部分相关,因此只是第一范式。
以这样一组数据为例,七个字段在业务中不可再拆分,因此满足第一范式。同一个订单会有多个商品,所以主键是订单 id 和商品 id,但是商品名称仅依赖于商品 id,不满足表中的每一列都要和主键有关,而不能只与主键的某一部分相关,因此只是第一范式。
修改成下面两张表这样就满足了第二范式。

第三范式
第三范式在第二范式的基础上,消除了非主属性对主属性的传递函数依赖,简单来讲,就是每一列数据都和主键直接相关,而不能间接相关。
在上面的例子中,订单表中的用户 id 依赖于订单 id,但是用户地址和用户电话依赖于用户 id,形成了传递函数依赖,不满足第三范式。
要想满足第三范式,就要消除传递依赖,可以修改为下面三张表:

在实际开发过程中,三大范式也不是必须严格遵循的,根据业务需求可以对字段做适当的冗余操作。