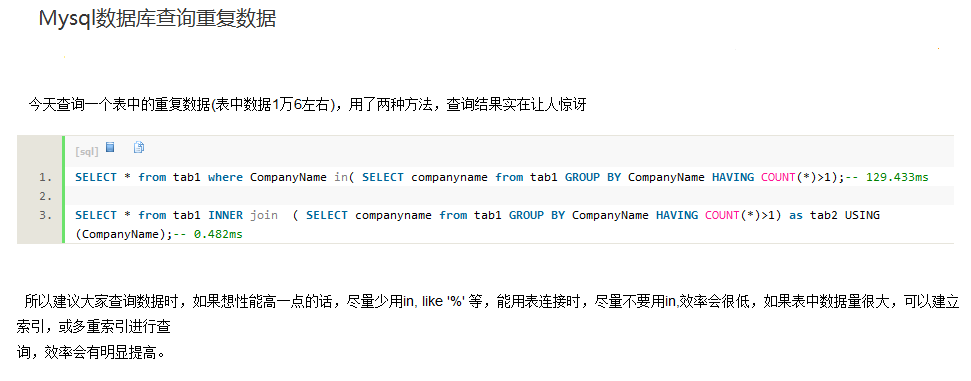
| 1 2 3 4 |
|
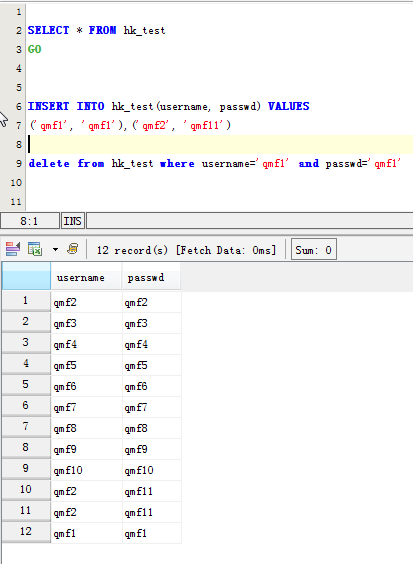
MySQL里查询表里的重复数据记录:
先查看重复的原始数据:
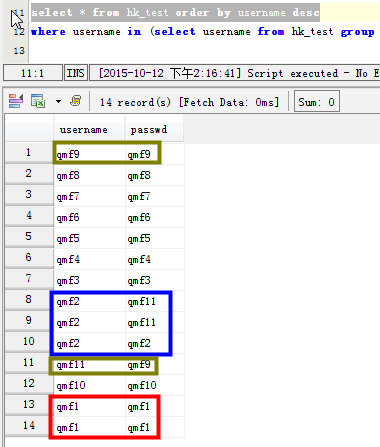
场景一:列出username字段有重读的数据
| 1 2 3 |
|
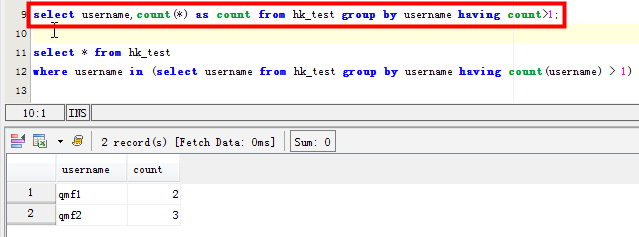
这种方法只是统计了该字段重复对应的具体的个数
场景二:列出username字段重复记录的具体指:
| 1 2 3 4 5 |
|

解决方法:

| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
|
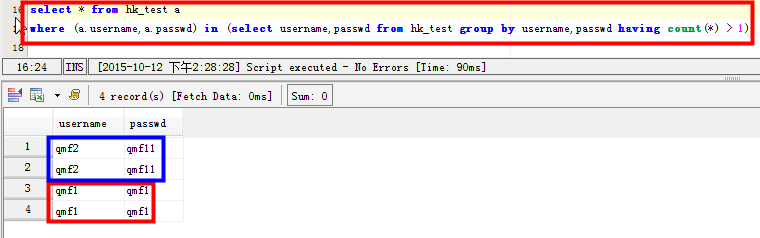
场景三:查看两个字段都重复的记录:比如username和passwd两个字段都有重复的记录:
| 1 2 |
|
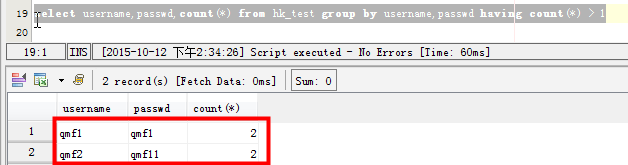
场景四:查询表中多个字段同时重复的记录:
| 1 |
|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 |
|
查找mysql数据表中重复记录
mysql数据库中的数据越来越多,当然排除不了重复的数据,在维护数据的时候突然想到要把多余的数据给删减掉,剩下有价值的数据。
以下sql语句可以实现查找出一个表中的所有重复的记录.
select user_name,count(*) as count from user_table group by user_name having count>1;
参数说明:
user_name为要查找的重复字段.
count用来判断大于一的才是重复的.
user_table为要查找的表名.
group by用来分组
having用来过滤.
把参数换成自己数据表的相应字段参数,可以先在Phpmyadmin里面或者Navicat里面去运行,看看有哪些数据重复了,然后在数据库里面删除掉,也可以直接将SQL语句放到后台读取新闻的页面里面读取出来,完善成查询重复数据的列表,有重复的可以直接删除。
缺点:这种方法的缺点就是当你的数据库里面的数据量很大的时候,效率很低,我用的是Navicat测试的,数据量不大,效率很高,当然,网站还有其它查询数据重复的SQL语句,举一反三,大家好好研究研究,找到一个适合自己网站的查询语句。
![【算法每日一练]-dfs bfs(保姆级教程 篇8 )#01迷宫 #血色先锋队 #求先序排列 #取数游戏 #数的划分](https://img-blog.csdnimg.cn/direct/b9dd8791346b497db2e12195a5584b04.png)
![[Android]RadioButton控件](https://img-blog.csdnimg.cn/3327391eaf3b49b58456e262120fcac3.png)