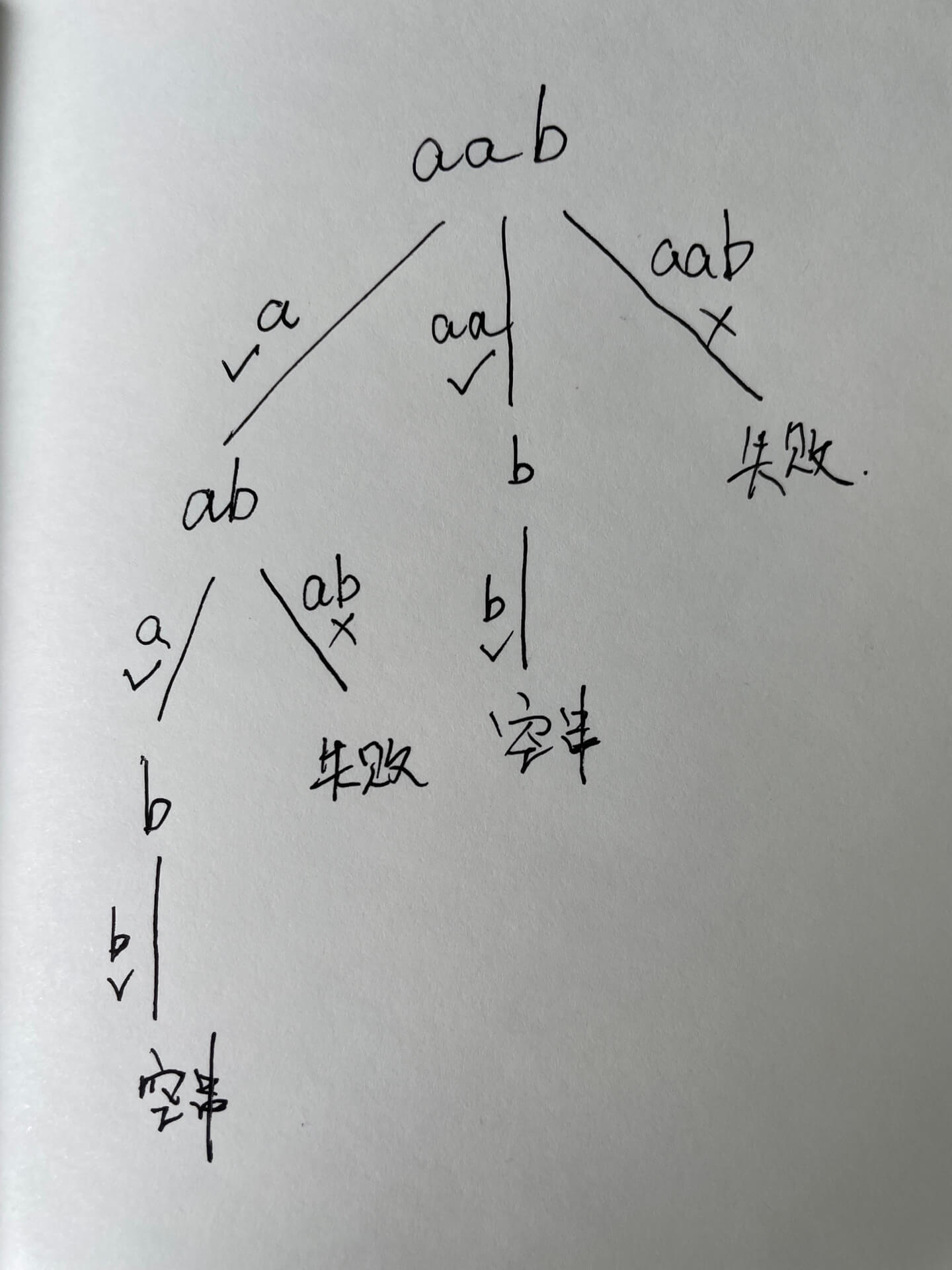
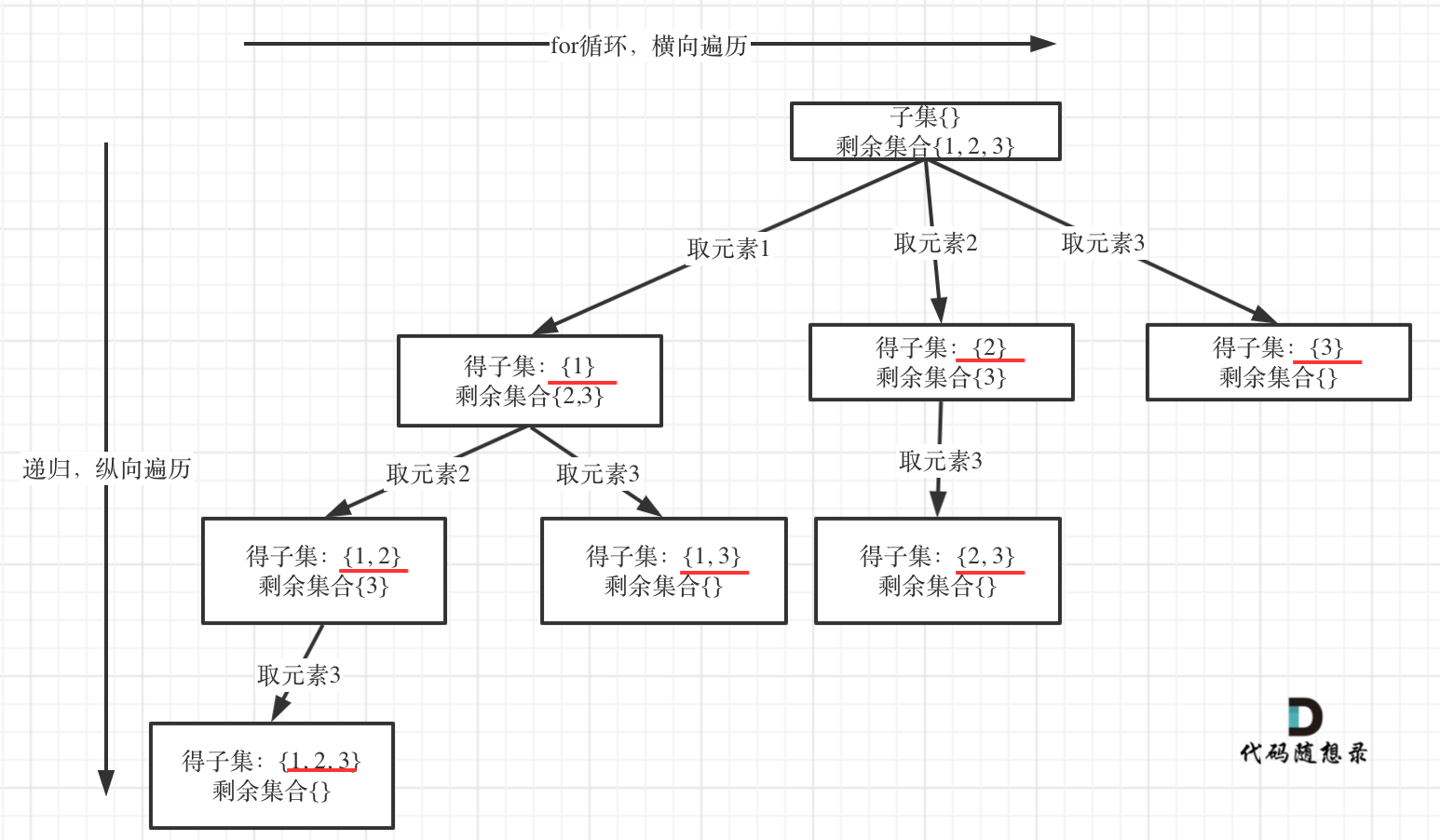
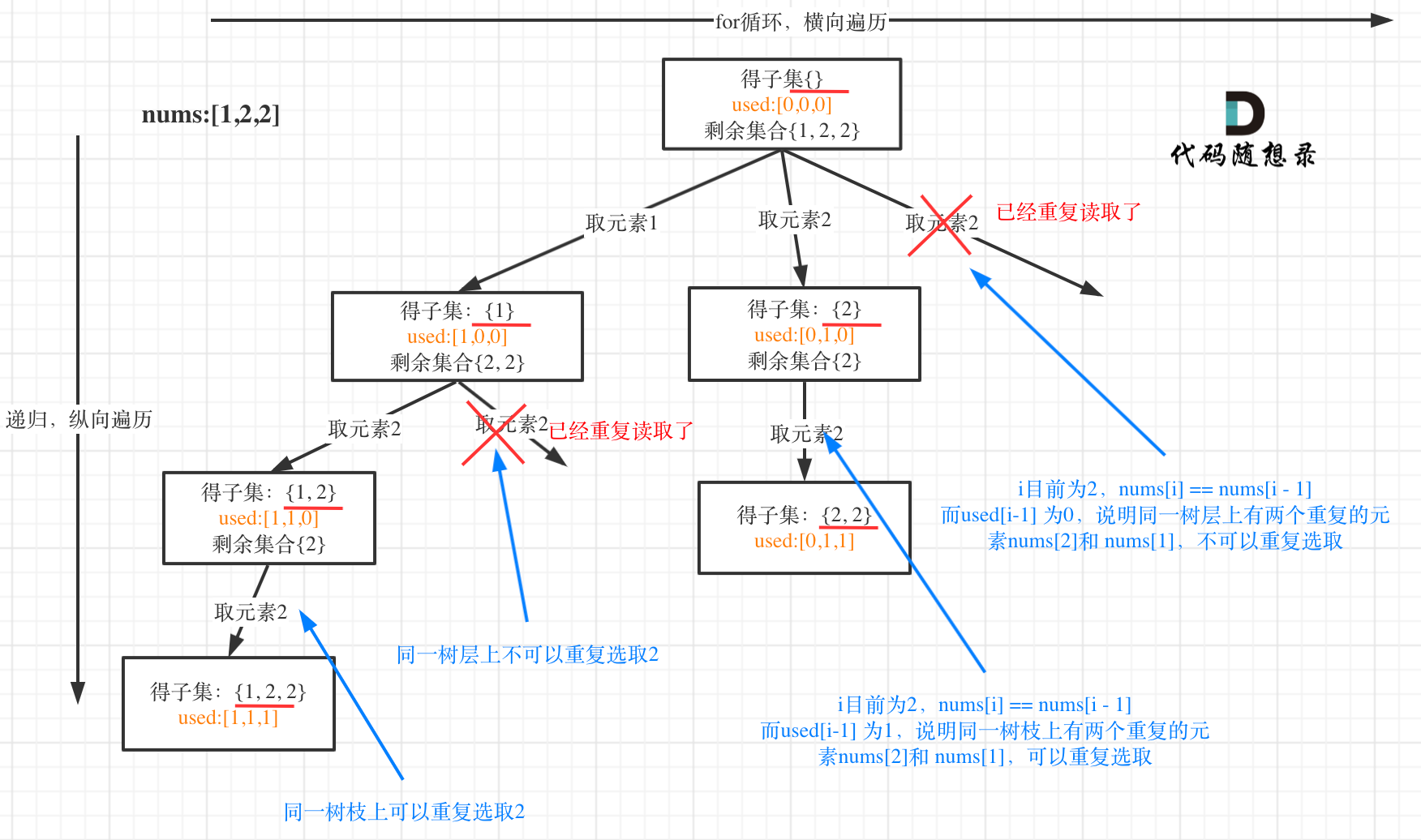
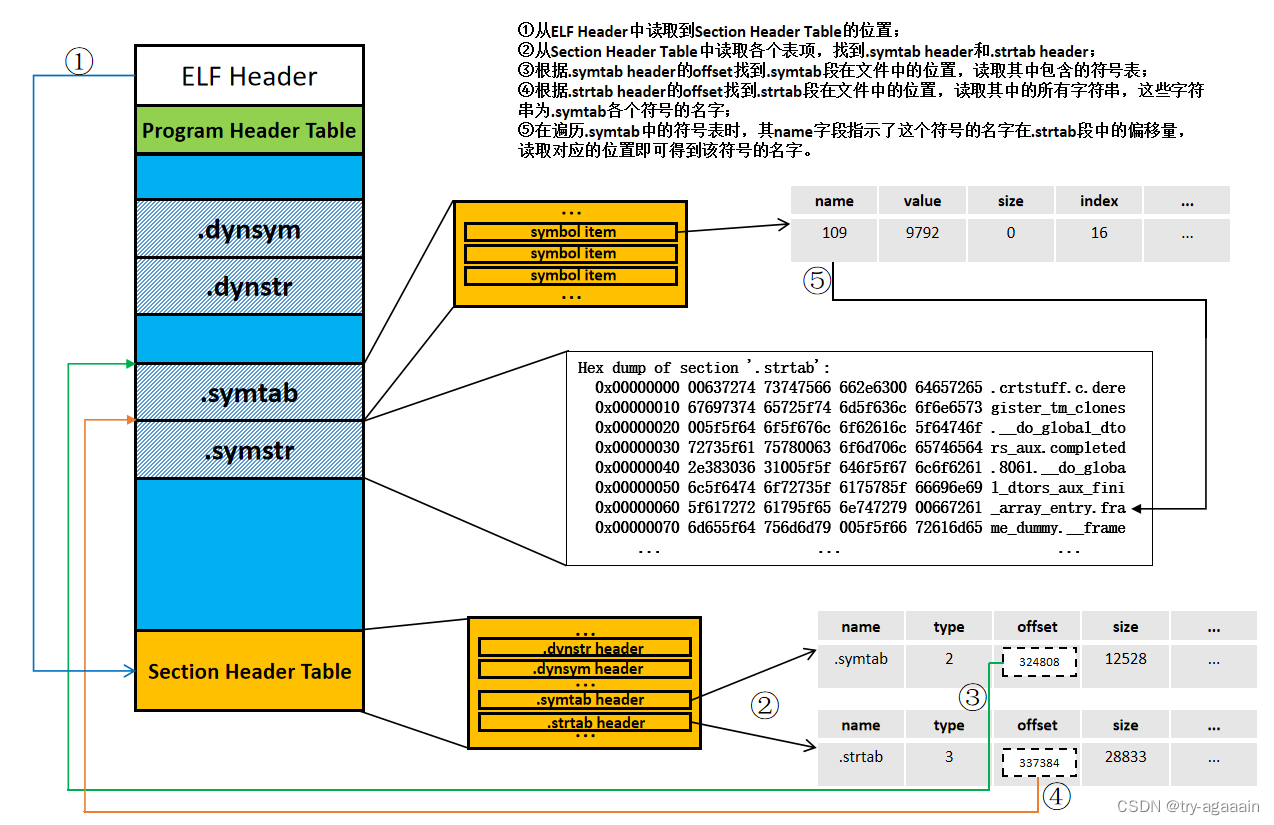
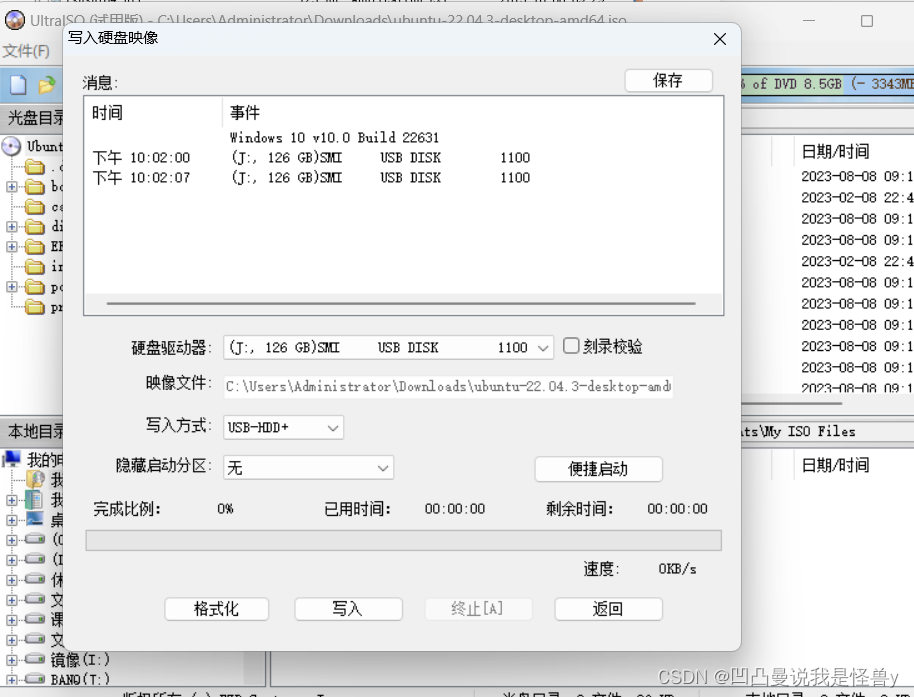
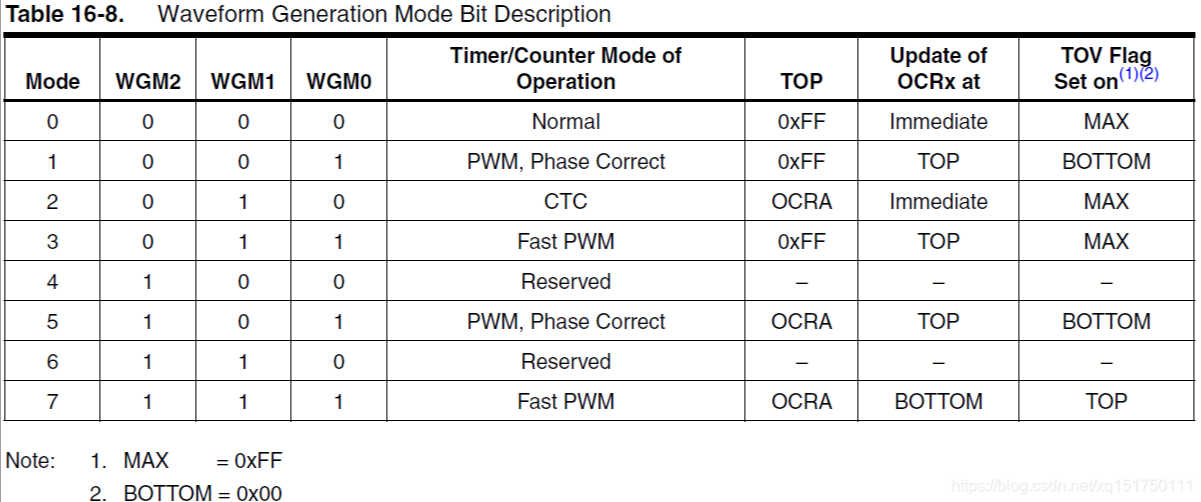
抽象成回溯树,树枝上是每次从头部穷举切分出的子串,节点上是待切分的剩余字符串 【从头开始每次往后加一】
class Solution :
def partition ( self, s: str ) - > List[ List[ str ] ] :
result = [ ]
self. backtrack( s, 0 , [ ] , result)
return result
def backtrack ( self, s, start, temp_list, result) :
if start == len ( s) :
result. append( temp_list[ : ] )
return
for i in range ( start, len ( s) ) :
if self. huiwenchuan( s, start, i) :
temp_list. append( s[ start: i + 1 ] )
self. backtrack( s, i + 1 , temp_list, result)
temp_list. pop( )
def huiwenchuan ( self, s, start1, end1) :
start = start1
end = end1
while start < end:
if s[ start] != s[ end] :
return False
start += 1
end -= 1
return True
那么既然是无序,取过的元素不会重复取,写回溯算法的时候,for就要从startIndex开始,而不是从0开始!
class Solution :
def subsets ( self, nums: List[ int ] ) - > List[ List[ int ] ] :
result = [ ]
result. append( [ ] )
self. backtrack( nums, [ ] , 0 , result)
return result
def backtrack ( self, nums, temp_list, start_index, result) :
if len ( temp_list) >= 1 :
result. append( temp_list[ : ] )
for i in range ( start_index, len ( nums) ) :
temp_list. append( nums[ i] )
self. backtrack( nums, temp_list, i + 1 , result)
temp_list. pop( )
class Solution :
def subsetsWithDup ( self, nums: List[ int ] ) - > List[ List[ int ] ] :
result = [ ]
result. append( [ ] )
nums. sort( )
self. backtrack( nums, [ ] , 0 , result)
return result
def backtrack ( self, nums, temp_list, start_index, result) :
if len ( temp_list) >= 1 :
if temp_list not in result:
result. append( temp_list[ : ] )
for i in range ( start_index, len ( nums) ) :
temp_list. append( nums[ i] )
self. backtrack( nums, temp_list, i + 1 , result)
temp_list. pop( )
class Solution :
def subsetsWithDup ( self, nums) :
result = [ ]
path = [ ]
nums. sort( )
self. backtracking( nums, 0 , path, result)
return result
def backtracking ( self, nums, startIndex, path, result) :
result. append( path[ : ] )
uset = set ( )
for i in range ( startIndex, len ( nums) ) :
if nums[ i] in uset:
continue
uset. add( nums[ i] )
path. append( nums[ i] )
self. backtracking( nums, i + 1 , path, result)
path. pop( )
class Solution :
def subsetsWithDup ( self, nums) :
result = [ ]
path = [ ]
used = [ False ] * len ( nums)
nums. sort( )
self. backtracking( nums, 0 , used, path, result)
return result
def backtracking ( self, nums, startIndex, used, path, result) :
result. append( path[ : ] )
for i in range ( startIndex, len ( nums) ) :
if i > 0 and nums[ i] == nums[ i - 1 ] and not used[ i - 1 ] :
continue
path. append( nums[ i] )
used[ i] = True
self. backtracking( nums, i + 1 , used, path, result)
used[ i] = False
path. pop( )