前言
前面文章讲述了线程的部分基本知识,这篇是对线程的深入学习,包含线程池,实现框架等。
1.学习如何使用Executor框架创建线程池。
2.并发工具类如CountDownLatch、CyclicBarrier等。
3.线程安全和并发集合:
4.学习如何使用Java提供的线程安全的集合类,如ConcurrentHashMap、CopyOnWriteArrayList等。
原子类和CAS操作:
线程池
1.介绍
线程池简单来讲就是管理线程的一个池子。
- 它帮助我们管理线程,避免增加线程和销毁线程的资源损耗,因为线程其实也是一个对象,创建线程需要经过类的加载,销毁一个对象,需要走GC的回收流程,都是需要资源开销的。
- 提高响应速度,如果任务到达,直接从线程池拿一个线程肯定比自己重新创建线程要快的多。
- 重复利用,线程用完了,再放回池子,可以达到重复利用的效果,节省资源。
2.常见线程池
主要有四种,都是通过工具类execute创建出来的
- newFixedThreadPool(固定数目线程的线程池)(方法ExecutorService newFixedThreadPool = Executors.newFixedThreadPool(4);):创建一个固定数目的线程池,每当提交一个任务就创建一个工作线程,如果工作线程数量达到线程池的初始最大,则将提交的线程放入到池队列中。newFixedTheadPool是一个典型优秀的线程池,它具有线程池提高程序效率和节省创建时所消耗的开销的特点,但是在空闲的时候,即使没有可运行的任务,也不会释放工作线程,会占用一定的资源。
- newCachedThreadPool(可缓存线程的线程池)(方法ExecutorService newCachedThreadPool = Executors.newCachedThreadPool();):创建一个可缓存的线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收的线程,则创建一个新线程。类型特点是工作线程创建的数量几乎没有限制(最大为Integer.Max_VALUE ),这样可以灵活添加线程。如果长时间没有往线程线程池中提交任务,即工作线程空闲了指定的时间(默认1分钟),则该线程自动终止,终止后如果你又提交了新任务,则线程池重新创建一个工作线程。在使用newCachedTheadPool时,一定要控制任务的数量,否则由于大量的线程同时运行,很有可能造成系统瘫痪。
- newSingleThreadExecutor(单线程的线程池)(方法ExecutorService newSingleThreadExecutor = Executors.newSingleThreadExecutor();):创建一个单线程化的Exexcutor,即只创建唯一的工作者线程来执行任务,它只会有唯一的工作线程来执行任务,保证所有的任务按照指定的顺序执行,如果这个线程异常,会有其他的线程来取代它,保证顺利执行,单线程最大的特点是可以保证顺序的执行各个任务,并且在给定的任意时间不会有多个线程是活动的。
- newScheduledThredPool (定时及周期执行的线程池)(方法ScheduledExecutorService newScheduledThreadPool = Executors.newScheduledThreadPool(4);):创建一个定长的线程池,而且支持定时的以及周期性的任务延迟,例如5秒延迟这样。
3.四种常见线程池原理
- newFixedThreadPool:
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory
threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}
线程池特点:
- 核心线程数和最大线程数一样
- 没有所谓的非空闲时间,即keepAliveTime为0
- 阻塞队列为无界队列LinkedBlockingQuenu,可能会导致OOM
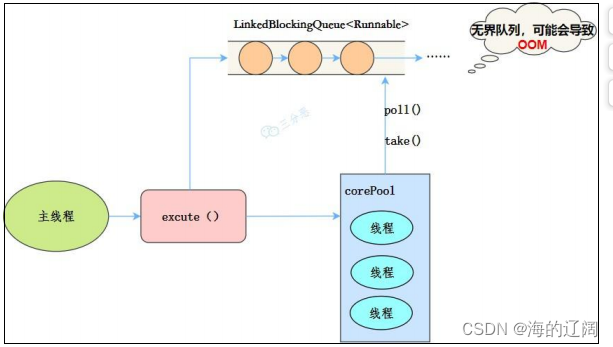
工作流程:
- 提交任务
- 如果任务数小于核心线程,就创建核心线程添加任务。
- 如果线程数等于核心线程,那就把任务放进LinkBlockingQueue中阻塞队列中
- 如果线程任务执行完成,去阻塞队列中获取任务,继续执行。
使用场景:
FixedThreadPool:适用于处理Cpu密集型的任务,确保CPU在长期被保护的情况下,尽可能少的分配线程,即使用执行长期的任务。
- NewCachedThreadPool
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory){
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
(BlockingQueue<Runnable>) new SynchronizedQueue<Runnable>(),threadFactory);
}
线程池特点:
- 核心线程数为0
- 最大线程数为Integer.MAX_VALUE,可能会导致OOM
- 阻塞队列是SynchronizedQueue
- 非核心线程存活默认一分钟
当提交任务的速度大于处理任务速度时候,每次提交一个任务,就必然会创建一个新线程。极端情况下会创建过多的线程,耗尽CPU资源。由于空闲的60秒的线程就会被终止,长时间保持空闲的线程CachedThreadPool不会占用任何线程。
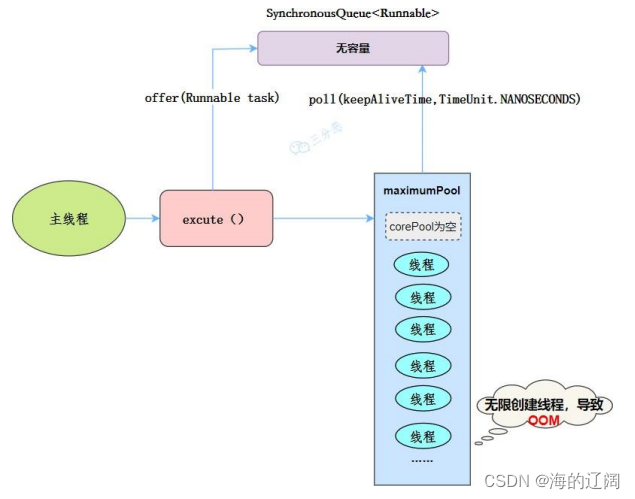
工作流程:
- 提交任务
- 因为没有核心线程,自己加到Synchronizedqueue队列中
- 判断是否有空闲线程,有就取出来执行, 没有就创建一个新线程。
- 执行完的线程还可以存活60s,如果在这期间获得任务,可以继续活下去,或者销毁
适用场景为并发量大的大量短期任务。
- NewSingleThreadPool
public static ExecutorService newSingleThreadPool(ThreadFactory threadFactory){
return Executors.newSingleThreadExecutor(threadFactory);
}
线程池特点:
- 最大线程数为1
- 核心线程数也为1
- 阻塞队列也是LinkedBlockingQueue队列,可以会导致OOM的keepaliveTime为0
工作流程:
- 提交任务
- 判断线程池是否有一条线程存在,如果没有则新建线程执行任务
- 如果有,加入到阻塞队列中
- 当前的唯一线程,从队列中取任务,执行完一个取一个
适用场景:适用执行串行的任务场景,一个接一个的执行
- newSceduledThreadPool
public ScheduledThreadPoolExecutor(int corePoolSize)
{ super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
线程池特点:
- 最大线程数是Integer.MAx_VALUE,也有OOM风险
- 阻塞队列是DelayedWorkQueue
- keepAliveTime为0
- scheduleAtFixedRate():按某种速率周期执行
- scheduleWithFixedDelay():再某个延迟后执行
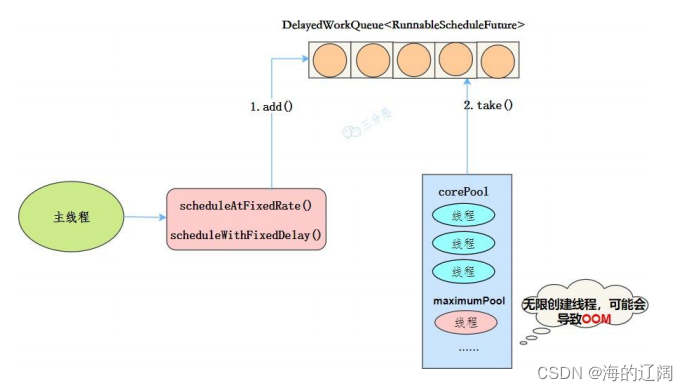
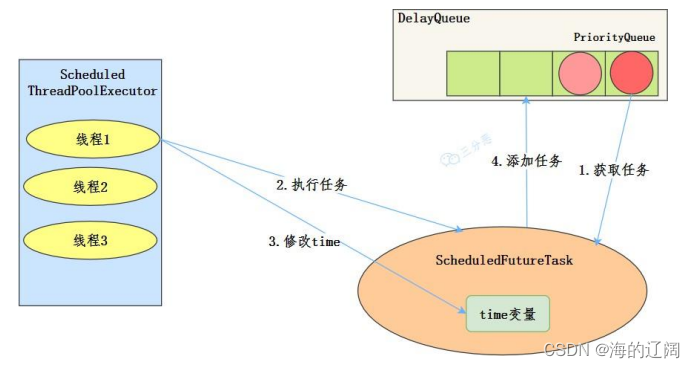
工作机制:
- 线程中DelayQueue中获取已到期的ScheduleFutureTask(DelayQueue.task())。到期任务是指ScheduleFutureTask的time大于当前时间。
- 线程执行ScheduleFutureTask
- 线程修改ScheduleFutureTask变量time下次要执行的时间
- 线程把这个修改time之后的ScheduledFutureTask放回DelayQueue中(DelayQueue.add())。
使用场景:
周期性执行任务的场景,需要限制最大的线程数量的场景。
4.线程池7大参数
线程池有7大参数重点关注:corePoolSize、maximumPoolSize,keepAliveTime、unit、workQueud、threadFactory、handler
- corePoolSize(核心线程数):指核心线程数大小,用来初始化线程池中的核心线程数,当线程池中线程数小于corePoolSize,系统默认是添加一个任务才创建线程池,当线程数=corePoolSize时候,任务会追加到workQueue中。
- maximunPoolSize(最大线程数):等于非核心线程数和核心线程数相加,当线程池中核心线程都处于执行状态,有新任务时候,1.当工作队列未满,新请求的任务加入到工作队列。2.工作队列已满,则会创建新线程,最大数会受到maximumPoolSize的限制。
- keepAliveTime(非核心线程存活时间):当线程数大于核心线程数时候,空闲线程在等待新任务时候最大的时间,如果超过还没有请求就会被销毁。
- unit(非核心线程存活单位):是指空闲线程存活时间的单位。keepAliveTime的计量单位。枚举类型TimeUnit类。
- workQueue(线程工作队列):
- ArrayBlockingQueue FIFO有界阻塞队列基于数组的有界阻塞队列,特点FIFO(先进先出)。 当线程池中已经存在最大数量的线程时候,再请求新的任务,这时就会将任务加入工作队列的队尾,一旦有空闲线程,就会取出队头执行任务。因为是基于数组的有界阻塞队列,所以可以避免系统资源的耗尽。
那么如果出现有界队列已满,最大数量的所有线程都处于执行状态,这时又有新的任务请求,怎么办呢? 这时候会采用Handler拒绝策略
2.LinkedBlockingQueue FIFO无限队列 基于链表的无界阻塞队列,默认最大容量Integer.MAX_VALUE( ),可认为是无限队列,特点FIFO。
关于maximumPoolSize参数在工作队列为LinkedBlockingQueue时候,是否起作用这个问题,我们需要视情况而定!
情况①:如果指定了工作队列大小,比如core=2,max=3,workQueue=2,任务数task=5,这种情况的最大线程数量的限制是有效的。
情况②:如果工作队列大小默认,这时maximumPoolSize不起作用,因为新请求的任务一直可以加到队列中。
3.PriorityBlockingQueue VIP 优先级无界阻塞队列,前面两种工作队列特点都是FIFO,而优先级阻塞队列可以通过参数Comparator实现对任务进行排序,不按照FIFO执行。
4、SynchronousQueue不缓存任务的阻塞队列 不缓存任务的阻塞队列,它实际上不是真正的队列,因为它没有提供存储任务的空间。生产者一个任务请求到来,会直接执行,也就是说这种队列在消费者充足的情况下更加适合。因为这种队列没有存储能力,所以只有当另一个线程(消费者)准备好工作,put(入队)和take(出队)方法才不会是阻塞状态。
以上四种工作队列,跟线程池结合就是一种生产者-消费者
设计模式。生产者把新任务加入工作队列,消费者从队列取出任务消费,BlockingQueue可以使用任意数量的生产者和消费者,这样实现了解耦,简化了设计。
原文链接:https://blog.csdn.net/ZGL_cyy/article/details/118230264
- threadFactory(线程工厂):创建一新线程使用的工厂,可以用来设定线程名,是否为daemon等。
守护线程(daemon Thread)再java中主要分为两类,:用户线程,守护线程
所谓守护是指再程序运行中提供的一种通用服务的线程,比如垃圾回收线程,并且这种线程并不属于线程中不可获缺的部分,因此所有的非守护线程结束的时候,程序也就终止了, 同时也会杀死进程中所有的守护线程,反而言之就是存在非守护线程那么程序就不会终止。用户线程和守护线程两者几乎没有区别,唯一的不同之处就在于虚拟机的离开:如果用户线程已经全部退出运行了,只剩下守护线程存在了,虚拟机也就退出了。
因为没有了被守护者,守护线程也就没有工作可做了,也就没有继续运行程序的必要了。
将线程转换为守护线程可以通过调用Thread对象的setDaemon(true)方法来实现。在使用守护线程时需要注意一下几点:
(1)thread.setDaemon(true)必须在thread.start()之前设置,否则会跑出一个IllegalThreadStateException异常。你不能把正在运行的常规线程设置为守护线程。
(2) 在Daemon线程中产生的新线程也是Daemon的。
(3) 守护线程应该永远不去访问固有资源,如文件、数据库,因为它会在任何时候甚至在一个操作的中间发生中断。
- handler(饱和拒绝策略):corePoolSize、 workQueue、 maximumPoolSize都不可用的时候执行的饱和策略。
- 策略1:ThreadPoolExecutor.AbortPolicy(默认)拒绝执行(理解系统瘫痪了)
在默认的处理策略。该处理在拒绝时抛出RejectedExecutionException,拒绝执行。 - 策略2:ThreadPoolExecutor.CallerRunsPolicy调用 execute 方法的线程本身运行任务(谁叫你来的找谁去)
调用 execute 方法的线程本身运行任务。这提供了一个简单的反馈控制机制,可以降低新任务提交的速度。
- 策略1:ThreadPoolExecutor.AbortPolicy(默认)拒绝执行(理解系统瘫痪了)
- 策略3:ThreadPoolExecutor.DiscardOldestPolicy执行程序未关闭,则删除工作队列头部的任务(队里加个塞)
如果执行程序未关闭,则删除工作队列头部的任务,然后重试执行(可能再次失败,导致重复执行) - 策略4 :ThreadPoolExecutor.DiscardPolicy无法执行的任务被简单地删除(改天再来)
无法执行的任务被简单地删除,将会丢弃当前任务,通过源码可以看出,该策略不会执行任务操作。
7.任务性质
可分为:CPU密集型任务,IO密集型任务,混合型任务
任务的执行时长。
任务是否有依赖——依赖其他系统资源,如数据库连接等。
CPU密集型任务
尽量使用较小的线程池,一般为CPU核心数+1。
因为CPU密集型任务使得CPU使用率很高,若开过多的线程数,只能增加上下文切换的次数,因此会带来额外的开销。
IO密集型任务
可以使用稍大的线程池,一般为2CPU核心数+1。
因为IO操作不占用CPU,不要让CPU闲下来,应加大线程数量,因此可以让CPU在等待IO的时候去处理别的任务,充分利用CPU时间。
混合型任务
可以将任务分成IO密集型和CPU密集型任务,然后分别用不同的线程池去处理。
只要分完之后两个任务的执行时间相差不大,那么就会比串行执行来的高效。
因为如果划分之后两个任务执行时间相差甚远,那么先执行完的任务就要等后执行完的任务,最终的时间仍然取决于后执行完的任务,而且还要加上任务拆分与合并的开销,得不偿失
依赖其他资源
如某个任务依赖数据库的连接返回的结果,这时候等待的时间越长,则CPU空闲的时间越长,那么线程数量应设置得越大,才能更好的利用CPU。
借鉴别人的文章 对线程池大小的估算公式:
最佳线程数目 = ((线程等待时间+线程CPU时间)/线程CPU时间 ) CPU数目
比如平均每个线程CPU运行时间为0.5s,而线程等待时间(非CPU运行时间,比如IO)为1.5s,CPU核心数为8,那么根据上面这个公式估算得到:((0.5+1.5)/0.5)*8=32。
可以出一个结论:
线程等待时间所占比例越高,需要越多线程。线程CPU时间所占比例越高,需要越少线程。
原文链接:https://blog.csdn.net/ZGL_cyy/article/details/118230264